Chrome + Python 抓取动态网页内容
用Python实现常规的静态网页抓取时,往往是用urllib2来获取整个HTML页面,然后从HTML文件中逐字查找对应的关键字。如下所示:
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1" up=urllib2.urlopen(url)#打开目标页面,存入变量up cont=up.read()#从up中读入该HTML文件 key1='<a href="http'#设置关键字1
key2="target"#设置关键字2 pa=cont.find(key1)#找出关键字1的位置
pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找) urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据) print urlx
但是,在动态页面中,所显示的内容往往不是通过HTML页面呈现的,而是通过调用js等方式从数据库中得到数据,回显到网页上。以发改委网站上的“备案信息”(http://beian.hndrc.gov.cn/)为例,要抓取此页面中的某些备案项目。例如“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”。
那么,在浏览器中打开此页面:
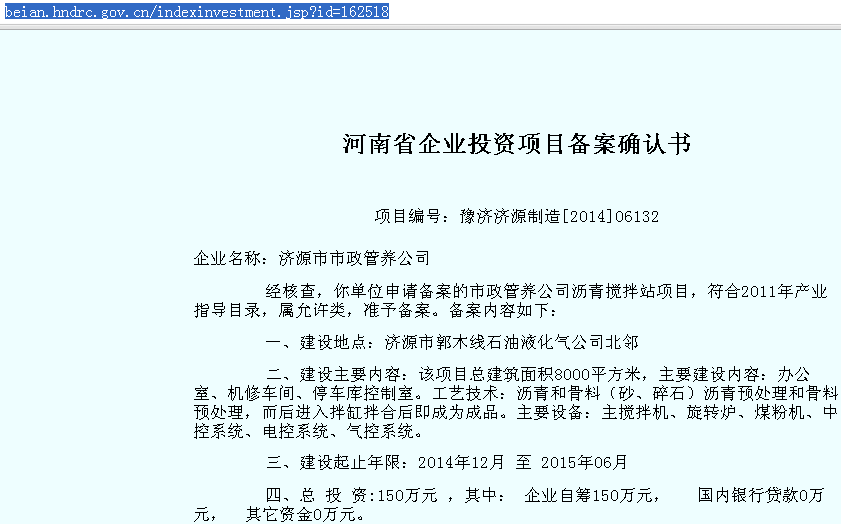
相关信息都显示的很全了,但是如果按照之前的办法:
up=urllib2.urlopen(url) cont=up.read()
就抓取不到上述内容了。
我们查看一下这个页面对应的源码:

由源码可以看出,这个《备案确认书》属于“填空”形式的,HTML提供文字模板,js根据不同的id提供不同的变量,“填入”到文字模板中,形成了一个具体的《备案确认书》。所以单纯抓取此HTML,只能得到一些文字模板,而无法得到具体内容。
那么,该如何找到那些具体内容呢?可以利用Chrome的“开发者工具”来寻找谁是真正的内容提供者。
打开Chrome浏览器,按下键盘F12即可呼出此工具。如下图:
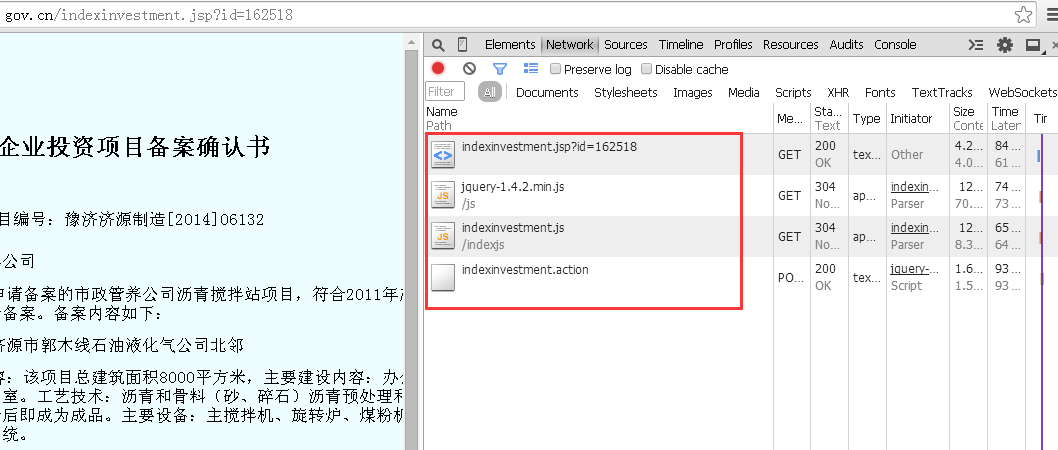
此时选中“Network”标签,在地址栏中输入此页面“http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518”,浏览器会分析出此次响应的全过程,而红框内的文件,就是此次响应中,浏览器和web后端的所有通信。
因为要获得不同企业对应的不同信息,那么浏览器发送给服务器的请求里面一定会有一个和当前企业id有关的参数。
那么,参数是多少呢?URL上有,是“jsp?id=162518”,问号表示要调用参数,后面跟的是id号即是被调用的参数。而通过对这几个文件的分析,很显然,企业信息存在于“indexinvestment.action”文件中。
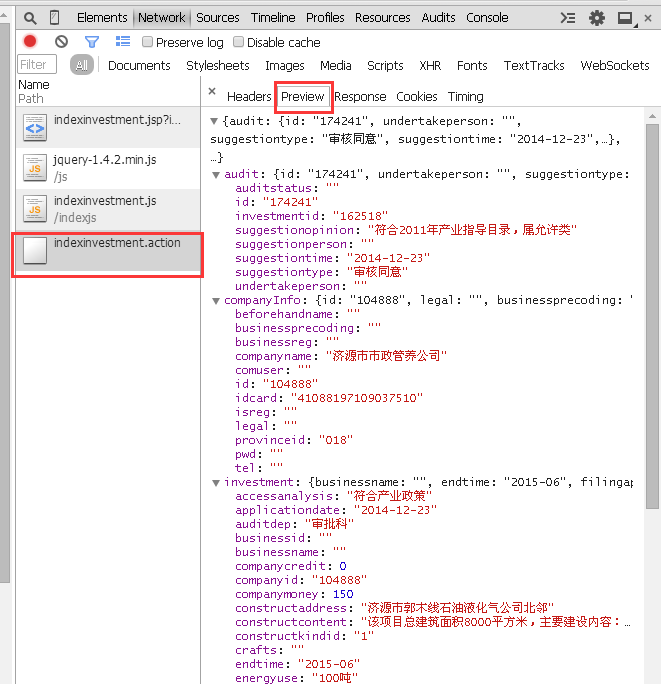
然而,双击打开此文件并不能获得企业信息,而是一堆代码。因为没有对应的参数为它指明要显示第几号的信息。如图:

那么,应该如何将参数传递给它呢?这时我们仍旧看F12窗口:
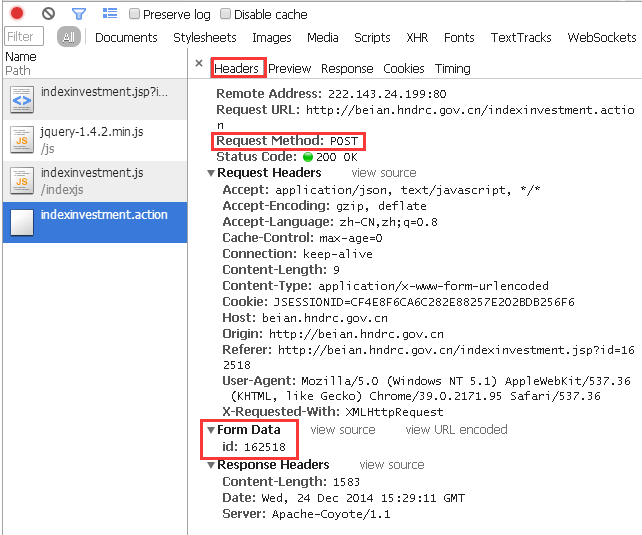
“Header”一栏中明确地显示出了此次响应的过程:
对目标URL,用POST的方式,传递了一个id为162518的参数。
我们先手工操作一下。js是如何调用参数的呢?对,上面说过:问号+变量名+等号+变量对应的数字。也就是说,向“http://beian.hndrc.gov.cn/indexinvestment.action”这个页面提交id为162518的参数时,应该在URL后面加上
“?id=162518”,即
“http://beian.hndrc.gov.cn/indexinvestment.action?id=162518”。
我们把这个URL粘贴到浏览器中来看:

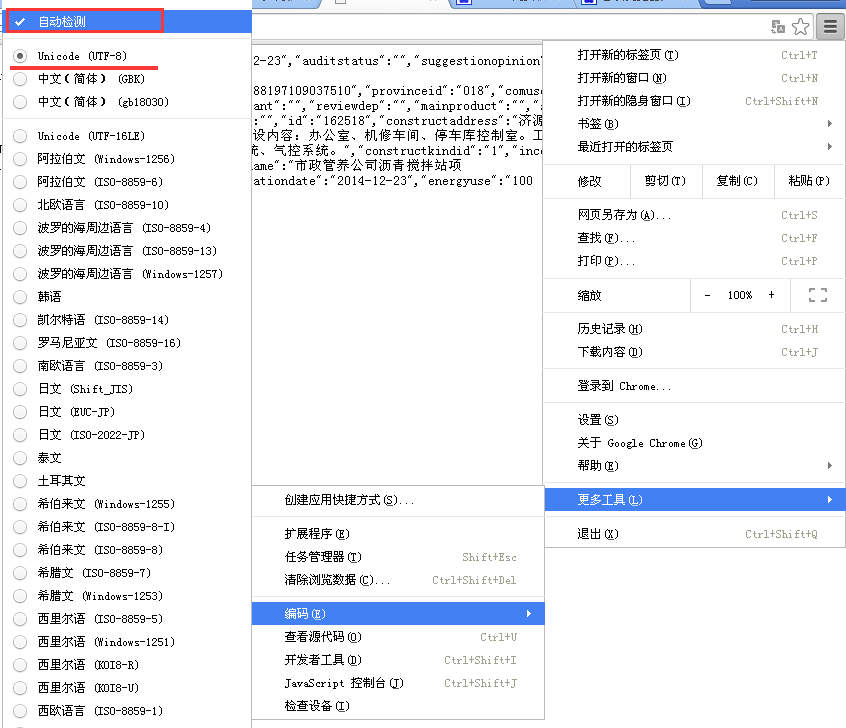
似乎有了点内容,可是都是乱码啊,怎么破?熟悉的朋友可能一眼就看出来,这是编码的问题。是因为响应回来的内容与浏览器默认的编码方式不同。只需要在Chrome右上角菜单——更多工具——编码——“自动检测”即可。(其实这是UTF-8的编码,而Chrome默认的是中文简体)。如下图:
好了,真正的信息源已经被挖出,剩下的就是用Python处理这些页面上的字符串,然后剪切、拼接,重新组成新的《项目备案书》了。
再然后使用for、while等循环,批量获取这些《备案书》。
正如“不论是静态网页,动态网页,模拟登陆等,都要先分析、搞懂逻辑,再去写代码”所说,编程语言只是一个工具,重要的是解决问题的思路。有了思路,再寻找趁手的工具去解决,就OK了。
Chrome + Python 抓取动态网页内容的更多相关文章
- python抓取动态验证码,具体第几帧数的位置静态图片
一.代码+注解 import os from PIL import Image import requests import io def save_img(): headers = { 'User- ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- python 多线程抓取动态数据
利用多线程动态抓取数据,网上也有不少教程,但发现过于繁杂,就不能精简再精简?! 不多解释,直接上代码,基本上还是很好懂的. #!/usr/bin/env python # coding=utf-8 i ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- 用python抓取智联招聘信息并存入excel
用python抓取智联招聘信息并存入excel tags:python 智联招聘导出excel 引言:前一阵子是人们俗称的金三银四,跳槽的小朋友很多,我觉得每个人都应该给自己做一下规划,根据自己的进步 ...
- selenium抓取动态网页数据
1.selenium抓取动态网页数据基础介绍 1.1 什么是AJAX AJAX(Asynchronouse JavaScript And XML:异步JavaScript和XML)通过在后台与服务器进 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
随机推荐
- 图片定位 css
原文发布时间为:2009-07-14 -- 来源于本人的百度文章 [由搬家工具导入] 原图片:http://cache.soso.com/wenwen/i/w_icon.gif 从这图片定位几张图片出 ...
- 基址重定位表&.reloc节区
第16-17章 - 基址重定位表&.reloc节区 @date: 2016/11/31 @author: dlive 0x01 PE重定位 若加载的是DLL.SYS文件,且在ImageBase ...
- mac与linux服务器之间使用ssh互通有无
1. 在mac上没有找到好用的shell图形界面的软件,但也是有办法的,使用ssh公钥达到互相有无目的 2.场景是mac连A(linux,以下简称A)服务器 3.登陆mac shell ,按comma ...
- COFF - 中间文件格式解析
http://www.cnblogs.com/weikanzong/p/5296739.html
- windows内核实现的34个关键问题
http://book.kongfz.com/237217/670391178/#bookComm
- Scut游戏服务器引擎6.0.5.2发布
1. 增加C#脚本中能引用多个C#脚本文件的支持2. 修正Web应用程序中使用C#脚本解析不到Bin目录的问题
- hdu1003(C++)解法1
#include<iostream>using namespace std;int Maxsum(int*a, int n);int main(){ int T,n,i,j,count=0 ...
- 手动编译高速扫描器MasScan
常见的端口扫描器有NMAP,ZMAP,superScan等,我们使用后各有千秋,ZMAP号称44分钟扫全球ip,那么有没有比ZMAP更快的端口扫描器呢,今天我们来研究下masscan,这款扫描器号称3 ...
- VirtualBox导入XXXX.vdi时报错
virtualbox导入vdi文件时出现以下的问题: 解决方法: windows+R,输入cmd,进入virtualbox的安装文件夹(或者在硬盘中直接进入virtualbox的安装文件夹.在任务栏里 ...
- 【前端阅读】——《程序员思维修炼》摘记&读后感&思维导图
前言:这是一本介绍如何用脑的书,并从思维的角度(以程序员为例),介绍如何从新手成为专家.作者带领着读者(我)共同经历一次有关认知科学.神经学.学习和行为理论的旅程,探索人类大脑令人 惊奇的工作的机制, ...