爬虫练习四:爬取b站番剧字幕
由于个人经常在空闲时间在b站看些小视频欢乐一下,这次就想到了爬取b站视频的弹幕。
这里就以番剧《我的妹妹不可能那么可爱》第一季为例,抓取这一番剧每一话对应的弹幕。
1. 分析页面
这部番剧的第一季就有15话,所以我们首先需要找到每一话对应的url,然后再去爬取每一话的弹幕。
1.1 找到每一话对应的url
打开番剧的首页,可以看到每一话的信息就展示在图中位置。
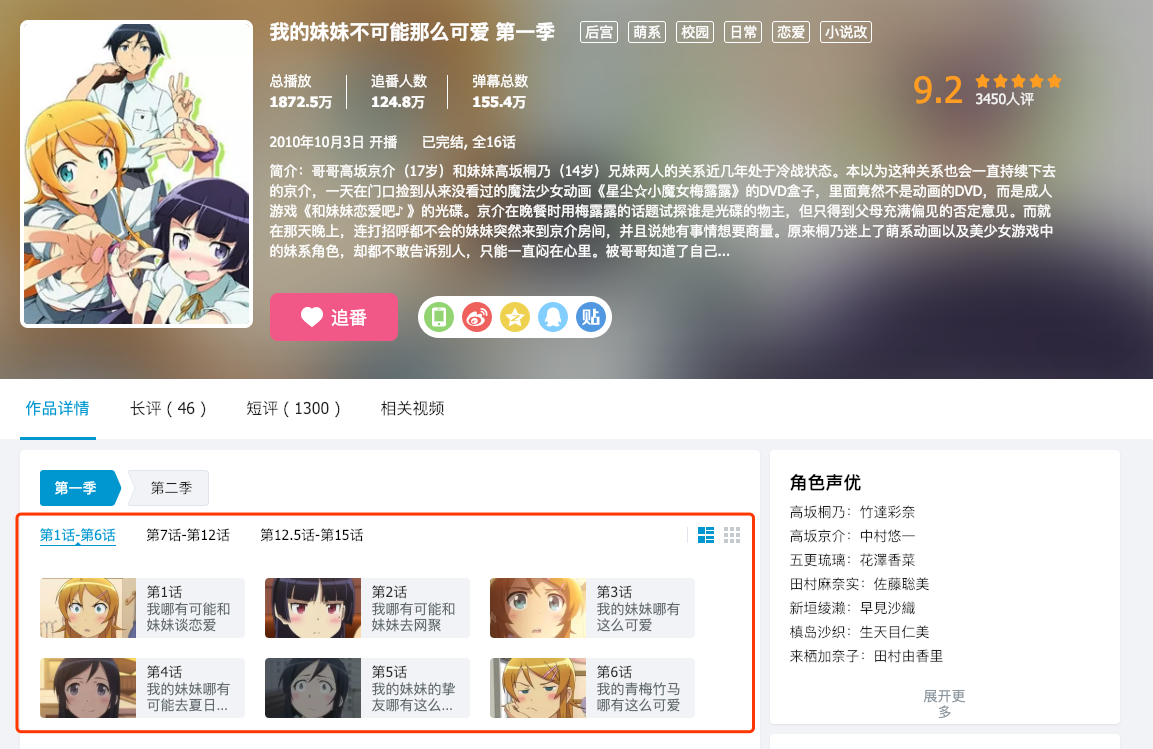
照惯例,我们首先对当前请求网页返回的数据进行查看,发现请求该url返回的只有一点简略的番剧信息,根本没有每一话的信息。
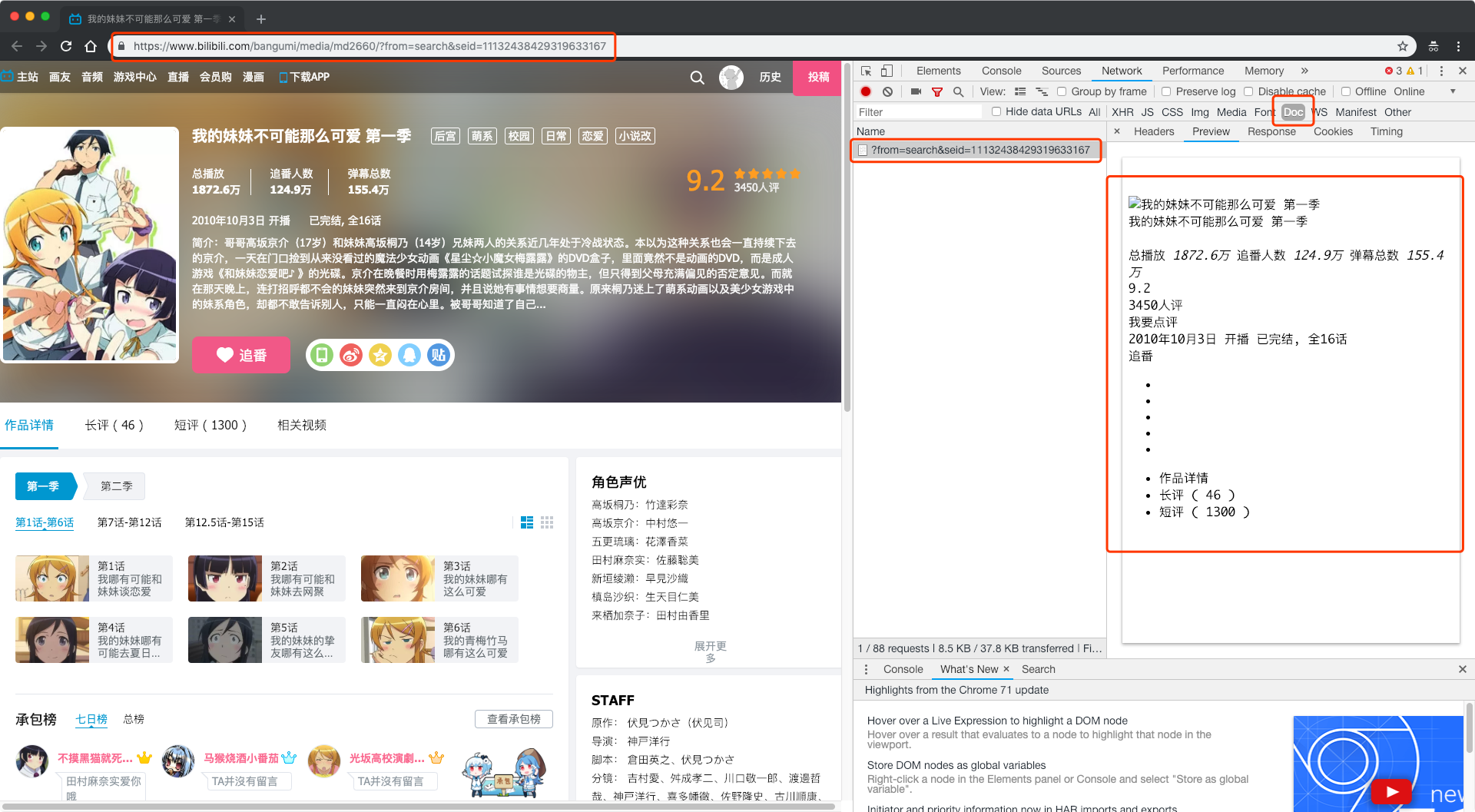
但是我们在浏览器中又确实能够看到每一话的信息,所以推测,这些信息应该是通过AJAX异步加载方式获取到的。接下来我们就查看“XHR”标签内的网络请求。
当前这一网页中XHR标签内的网络请求并不多,最简单的方法就是每一个网络请求都查看一番。但是我们可以发现,这里的每个网络请求看起来都有一定的命名规则,像info/nav/review/recommend这些,似乎都很容易理解。我们发现其中有一个请求命名为'section?season_id=...',那就先看它了。
(对于异步加载的网页,相比于随机命名,规范命名有助于程序员进行高效开发和维护。所以我们从网络请求的命名入手,一定程度上能够提高找到对应数据来源的速度和准确度)
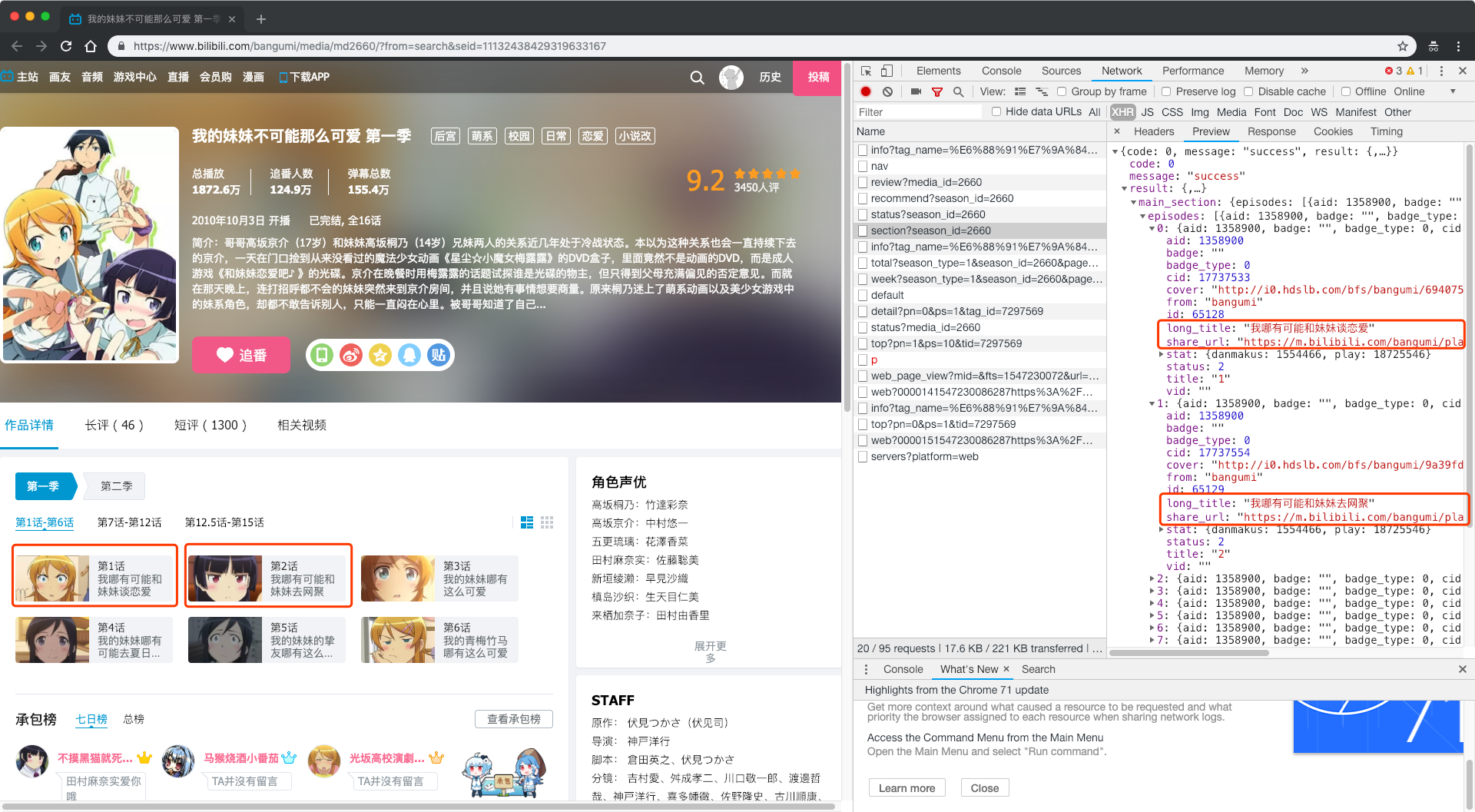
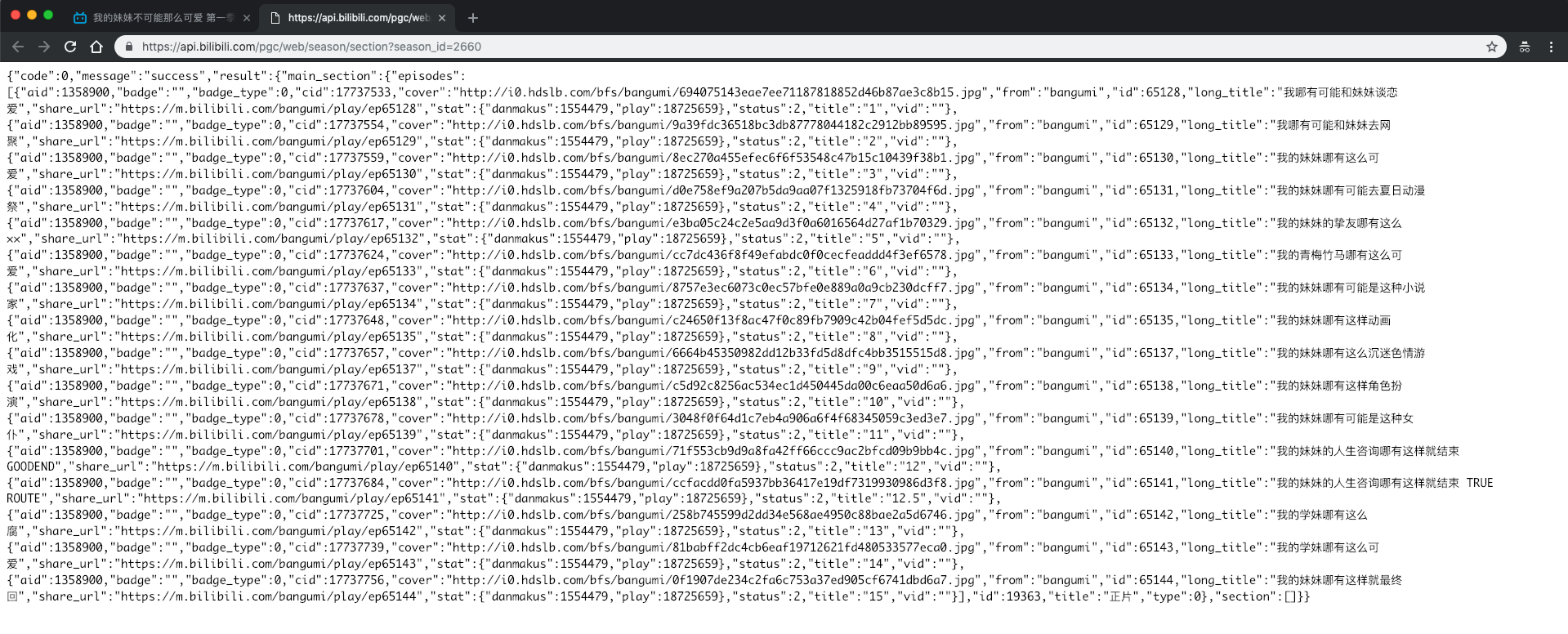
点击Preview一看,这个网络请求返回的是一个json文件,而内容恰好能够对应到这个番剧每一话的信息,打开这个请求的网页也确实发现了每一话的名称、url等信息。
那么我们就已经找到了这部番剧每一话的播放地址url。
1.2 找到当前视频对应的弹幕来源
以第一话为例,我们打开第一话的url。毫无悬念的是,请求当前url的返回信息里并没有弹幕信息。
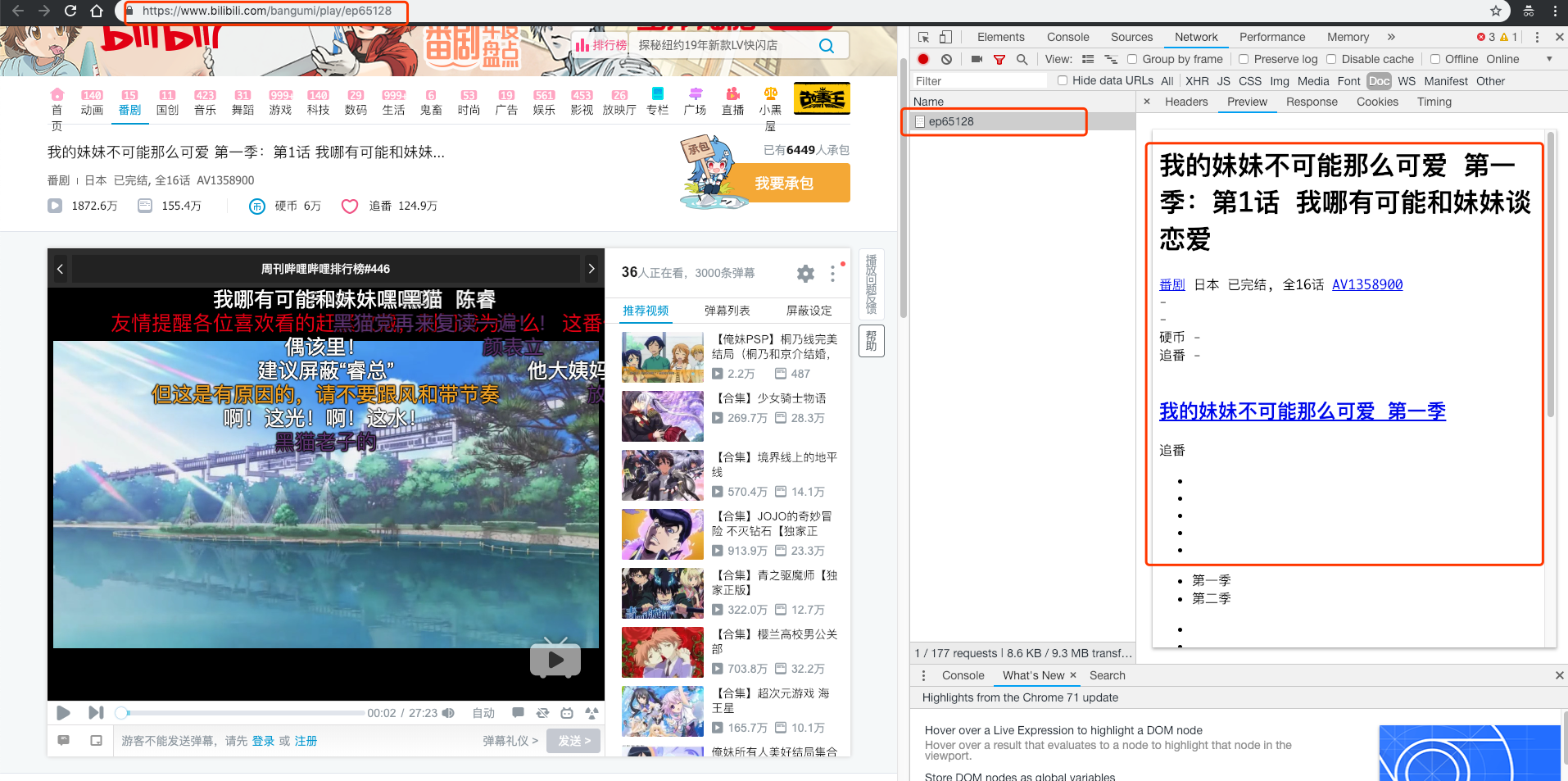
所以我们继续查看"XHR"标签。这时候,问题来了,"XHR"标签内少说也有好几十个网络请求,它们的命名好像也不是很清晰,那我们岂不是要把每个网络请求都查看一遍才能找到弹幕对应的来源。

这里要介绍一个小技巧:不管当前页面有多少个网络请求,不管这些数量繁多的网络请求是为了反爬虫还是为了页面复杂功能的实现,我们只需要记住一个宗旨:程序员是不会舍得把资源过多浪费在无关紧要的地方的。
所以这里我们将各个请求按Size进行倒叙排列,从上往下尝试几次就可以发现,弹幕是来源于这个url的:https://api.bilibili.com/x/v1/dm/list.so?oid=17737533
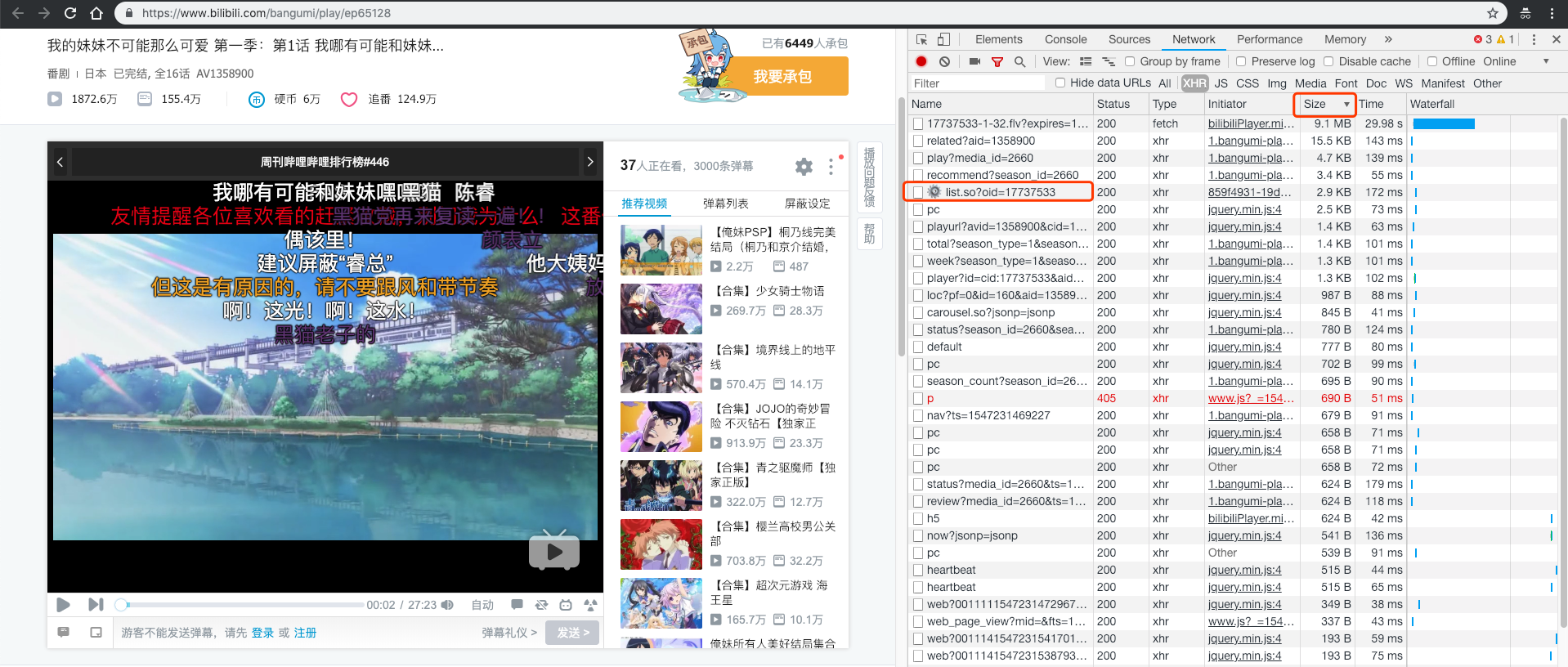
而通过查看这个网络请求的headers信息可以发现,弹幕是通过请求接口获取的,请求参数是17737533,它是这个视频的编号。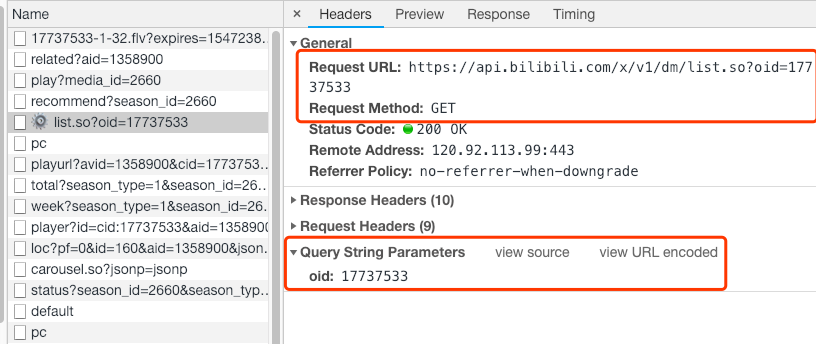
但是,当前视频的url里面明明是ep65128,这两个参数是很明显对不上的。
既然加载弹幕的请求是访问主url后才会继续的,那么通过访问主url就肯定能拿到对应的视频编号,然后加载弹幕的请求才可以通过这个编号进行加载弹幕。
那我们接下来就分析当前页面的源代码,搜索17737533,它属于cid字段。现在我们就找到了每个视频请求弹幕时它所对应的编号。

(回头查看时发现,cid这个参数在1.1中通过'section?season_id=...'也可以获取到)
1.3 抓取流程
1)通过番剧首页获取每一话对应的url和cid编号
'根据1.2,其实cid参数可以从两个地方获取到。这里我们就用简单的方法,直接在'section?season_id=...'中获取。
2)将cid编号放入“https://api.bilibili.com/x/v1/dm/list.so?oid=”后,构建url,保存每一话的弹幕信息。
2. 代码实现
import requests
from bs4 import BeautifulSoup
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
}
# 通过番剧首页获取每一话对应的cid编号,存入section_sid
def get_cid(index_url):
try:
index_response = requests.get(index_url, headers=header)
index_json = index_response.json() # 返回一个json文件
section_cid = []
for each in index_json['result']['main_section']['episodes']:
section_cid.append({
'title': each['long_title'],
'cid': each['cid'],
'id': each['id'],
'url': each['share_url']
})
except:
print('index pass')
return section_cid
# 通过cid编号获取这一话的所有弹幕信息
def get_danmu(cid):
try:
danmu_response = requests.get('https://api.bilibili.com/x/v1/dm/list.so?oid='+str(cid), headers=header)
danmu_soup = BeautifulSoup(danmu_response.content, 'lxml')
for each in danmu_soup.findAll('d'):
danmu_info = each['p'].split(",")
danmu_detail.append({
'cid': cid, # 弹幕对应视频cid
'danmu': each.get_text(), # 弹幕内容
'time': danmu_info[0], # 弹幕出现时间(秒)
'type': danmu_info[1], # 弹幕模式
'size': danmu_info[2], # 字号
'color': danmu_info[3], # 颜色
'timestamp': danmu_info[4], # 时间戳
'pool': danmu_info[5], # 弹幕池
'sender': danmu_info[6], # 发送者ID
'row': danmu_info[7] # 弹幕rowID,用于“历史弹幕”功能
})
print(cid, 'done')
except:
print(cid, 'pass')
danmu_detail = [] # 所有弹幕存入danmu_detail
section_cid = get_cid(index_url)
[get_danmu(each_section['cid']) for each_section in section_cid]
爬虫练习四:爬取b站番剧字幕的更多相关文章
- Python 网络爬虫实战:爬取 B站《全职高手》20万条评论数据
本周我们的目标是:B站(哔哩哔哩弹幕网 https://www.bilibili.com )视频评论数据. 我们都知道,B站有很多号称“镇站之宝”的视频,拥有着数量极其恐怖的评论和弹幕.所以这次我们的 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- python 爬虫入门案例----爬取某站上海租房图片
前言 对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSou ...
- <爬虫>用正则爬取B站首页图片
import re import requests headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) Apple ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- scrapy进阶(CrawlSpider爬虫__爬取整站小说)
# -*- coding: utf-8 -*- import scrapy,re from scrapy.linkextractors import LinkExtractor from scrapy ...
- 爬虫---爬取b站小视频
前面通过python爬虫爬取过图片,文字,今天我们一起爬取下b站的小视频,其实呢,测试过程中需要用到视频文件,找了几个网站下载,都需要会员什么的,直接写一篇爬虫爬取视频~~~ 分析b站小视频 1.进入 ...
- 爬虫之爬取B站视频及破解知乎登录方法(进阶)
今日内容概要 爬虫思路之破解知乎登录 爬虫思路之破解红薯网小说 爬取b站视频 Xpath选择器 MongoDB数据库 爬取b站视频 """ 爬取大的视频网站资源的时候,一 ...
随机推荐
- djangoAdmin组件
定制后台页面功能 from django.contrib import admin from app import models # Register your models here. class ...
- 洛谷 P4137 Rmq Problem / mex
https://www.luogu.org/problemnew/show/P4137 只会log^2的带修主席树.. 看了题解,发现有高妙的一个log做法:权值线段树上,设数i对应的值ma[i]为数 ...
- 096 Unique Binary Search Trees 不同的二叉查找树
给出 n,问由 1...n 为节点组成的不同的二叉查找树有多少种?例如,给出 n = 3,则有 5 种不同形态的二叉查找树: 1 3 3 2 1 ...
- Hadoop工作流引擎之Azkaban与Oozie对比(四)
Azkaban是什么?(一) Azkaban的功能特点(二) Azkaban的架构(三) 不多说,直接上干货! http://www.cnblogs.com/zlslch/category/93883 ...
- 移动端meta的使用
伴随着web app的不断火热,移动端可以说是未来的大趋势了,下面是常用的一下meta <!-- 声明文档使用的字符编码 --> <meta charset='utf-8'> ...
- Linux-软件安装(一) —— jdk/tomact 安装(普通安装)
Linux-软件安装(一) -- jdk/tomact 安装(普通安装) 1. 可使用 FinalShell 上传至 Linux 服务器 2. 解压 cd /usr/local #解压命令 tar - ...
- JS权威指南-概述学习
<script src="/javascripts/application.js" type="text/javascript" charset=&quo ...
- MFC程序添加快捷键
[问题提出] 有的程序需要自定义组合键完成一定功能,如何实现? [解决方法] RegisterHotKey函数原型及说明: BOOL RegisterHotKey( H ...
- uvm_reg_field——寄存器模型(二)
uvm_reg_field是最基本寄存器单元. typedef class uvm_reg_cbs; //----------------------------------------------- ...
- C# 语言 类
++++String类+++++黑色小扳手 - 属性紫色立方体 - 方法 ***字符串.Length - 字符串长度,返回int类型 字符串.TrimStart() - 去掉前空格字符串.TrimEn ...