c++再探string之eager-copy、COW和SSO方案
在牛客网上看到一题字符串拷贝相关的题目,深入挖掘了下才发现原来C++中string的实现还是有好几种优化方法的。
原始题目是这样的:
关于代码输出正确的结果是()(Linux g++ 环境下编译运行)
int main(int argc, char *argv[])
{
string a="hello world";
string b=a;
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
string c=b;
c="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
a="";
if (a.c_str()==b.c_str())
{
cout<<"true"<<endl;
}
else cout<<"false"<<endl;
return 0;
}
这段程序的输出结果和编译器有关,在老版本(5.x之前)的GCC上,输出是true true false,而在VS上输出是false false false。这是由于不同STL标准库对string的实现方法不同导致的。
简而言之,目前各种STL实现中,对string的实现有两种不同的优化策略,即COW(Copy On Write)和SSO(Small String Optimization)。string也是一个类,类的拷贝操作有两种策略——深拷贝及浅拷贝。我们自己写的类默认情况下都是浅拷贝的,可以理解为指针的复制,要实现深拷贝需要重载赋值操作符或拷贝构造函数。不过对于string来说,大部分情况下我们用赋值操作是想实现深拷贝的,故所有实现中string的拷贝均为深拷贝。
最简单的深拷贝就是直接new一个对象,然后把数据复制一遍,不过这样做效率很低,STL中对此进行了优化,基本策略就是上面提到的COW和SSO。
我们先以COW为例分析一下std::string
对std::string的感性认识
- string类中有一个私有成员,其实是一个char*,记录从堆上分 配内存的地址,其在构造时分配内存,在析构时释放内存
- 因为是从堆上分配内存,所以string类在维护这块内存上是格外小心的
- string类在返回这块内存地址时,只返回const char*,也就是只读的
- 成员函数:const char* c_str() const;
- 如果要写,则只能通过string提供的方法进行数据的改写。
对std::string的理性认识
- Q1. Copy-On-Write的原理是什么?
Copy-On-Write一定使用了“引用计数”,必然有一个变量类似于RefCnt
当第一个string对象str1构造时,string的构造函数会根据传入的参数从堆上分配内存
当有其它string对象复制str1时,这个RefCnt会自动加1
当有对象析构时,这个计数会减1;直到最后一个对象析构时,RefCnt为0,此时,程序才会真正的释放这块从堆上分配的内存
Q1.1 RefCnt该存在在哪里呢?
如果存放在string类中,那么每个string的实例都各自拥有自己的RefCnt,根本不能共有一个 RefCnt
如果是声明成全局变量,或是静态成员,那就是所有的string类共享一个了,这也不行
- Q2. string类在什么情况下才共享内存的?
根据常理和逻辑,发生复制的时候
1)以一个对象构造自己(复制构造函数) 只需要在string类的拷贝构造函数中做点处理,让其引用计数累加
2)以一个对象赋值(重载赋值运算符)
- Q3. string类在什么情况下触发写时才拷贝?
在共享同一块内存的类发生内容改变时,才会发生Copy-On-Write
比如string类的 []、=、+=、+、操作符赋值,还有一些string类中诸如insert、replace、append等成员函数
- Q4. Copy-On-Write时,发生了什么?
- 引用计数RefCnt 大于1,表示这个内存是被共享的
if ( --RefCnt>0 )
{
char* tmp = (char*) malloc(strlen(_Ptr)+1);
strcpy(tmp, _Ptr);
_Ptr = tmp;
}
- Q5. Copy-On-Write的具体实现是怎么样的?
- h1、h2、h3共享同一块内存, w1、w2共享同一块内存
- 如何产生这两个引用计数呢?
string h1 = “hello”;
string h2= h1;
string h3;
h3 = h2; string w1 = “world”;
string w2(“”);
w2=w1;
copy-on-write的具体实现分析
- String类创建的对象的内存是在堆上动态分配的,既然共享内存的各个对象指向的是同一个内存区,那我们就在这块共享内存上多分配一点空间来存放这个引用计数RefCnt
- 这样一来,所有共享一块内存区的对象都有同样的一个引用计数
解决方案分析
当为string对象分配内存时,我们要多分配一个空间用来存放这个引用计数的值,只要发生拷贝构造或赋值时,这个内存的值就会加1。而在内容修改时,string类为查看这个引用计数是否大于1,如果refcnt大于1,表示有人在共享这块内存,那么自己需要先做一份拷贝,然后把引用计数减去1,再把数据拷贝过来。
根据以上分析,我们可以试着写一下cow的代码 :
class String
{
public:
String()
: _pstr(new char[5]())
{
_pstr += 4;
initRefcount();
} String(const char * pstr)
: _pstr(new char[strlen(pstr) + 5]())
{
_pstr += 4;
initRefcount();
strcpy(_pstr, pstr);
} String(const String & rhs)
: _pstr(rhs._pstr)
{
increaseRefcount();
} String & operator=(const String & rhs)
{
if(this != & rhs) // 自复制
{
release(); //回收左操作数的空间
_pstr = rhs._pstr; // 进行浅拷贝
increaseRefcount();
}
return *this;
} ~String() {
release();
} size_t refcount() const { return *((int *)(_pstr - 4));} size_t size() const { return strlen(_pstr); } const char * c_str() const { return _pstr; } //问题: 下标访问运算符不能区分读操作和写操作
char & operator[](size_t idx)
{
if(idx < size())
{
if(refcount() > 1)
{// 进行深拷贝
decreaseRefcount();
char * tmp = new char[size() + 5]();
tmp += 4;
strcpy(tmp, _pstr);
_pstr = tmp;
initRefcount();
}
return _pstr[idx];
} else {
static char nullchar = '\0';
return nullchar;
}
} const char & operator[](size_t idx) const
{
cout << "const char & operator[](size_t) const " << endl;
return _pstr[idx];
} private:
void initRefcount()
{ *((int*)(_pstr - 4)) = 1; } void increaseRefcount()
{ ++*((int *)(_pstr - 4)); } void decreaseRefcount()
{ --*((int *)(_pstr - 4)); } void release() {
decreaseRefcount();
if(refcount() == 0)
{
delete [] (_pstr - 4);
cout << ">> delete heap data!" << endl;
}
} friend std::ostream & operator<<(std::ostream & os, const String & rhs); private:
char * _pstr;
}; std::ostream & operator<<(std::ostream & os, const String & rhs)
{
os << rhs._pstr;
return os;
} int main(void)
{
String s1;
String s2(s1);
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "s1's refcount = " << s1.refcount() << endl; String s3 = "hello,world";
String s4(s3); cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; String s5 = "hello,shenzheng";
cout << "s5 = " << s5 << endl;
s5 = s4;
cout << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行写操作之后:" << endl;
s5[0] = 'X';
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行读操作: " << endl;
cout << "s3[0] = " << s3[0] << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; const String s6("hello");
cout << s6[0] << endl; return 0;
}
事实上,上面的代码还是由缺陷的,[ ]运算符不能区分读操作或者写操作。
为了解决这个问题,可以使用代理类来实现:
1、 重载operator=和operator<<
#include <stdio.h>
#include <string.h>
#include <iostream>
using std::cout;
using std::endl; class String
{
class CharProxy
{
public:
CharProxy(size_t idx, String & self)
: _idx(idx)
, _self(self)
{} CharProxy & operator=(const char & ch); friend std::ostream & operator<<(std::ostream & os, const CharProxy & rhs);
private:
size_t _idx;
String & _self;
}; friend std::ostream & operator<<(std::ostream & os, const CharProxy & rhs);
public:
String()
: _pstr(new char[5]())
{
_pstr += 4;
initRefcount();
} String(const char * pstr)
: _pstr(new char[strlen(pstr) + 5]())
{
_pstr += 4;
initRefcount();
strcpy(_pstr, pstr);
} //代码本身就能解释自己 --> 自解释
String(const String & rhs)
: _pstr(rhs._pstr) //浅拷贝
{
increaseRefcount();
} String & operator=(const String & rhs)
{
if(this != & rhs) // 自复制
{
release(); //回收左操作数的空间
_pstr = rhs._pstr; // 进行浅拷贝
increaseRefcount();
}
return *this;
} ~String() {
release();
} size_t refcount() const { return *((int *)(_pstr - 4));} size_t size() const { return strlen(_pstr); } const char * c_str() const { return _pstr; } //自定义类型
CharProxy operator[](size_t idx)
{
return CharProxy(idx, *this);
}
#if 0
//问题: 下标访问运算符不能区分读操作和写操作
char & operator[](size_t idx)
{
if(idx < size())
{
if(refcount() > 1)
{// 进行深拷贝
decreaseRefcount();
char * tmp = new char[size() + 5]();
tmp += 4;
strcpy(tmp, _pstr);
_pstr = tmp;
initRefcount();
}
return _pstr[idx];
} else {
static char nullchar = '\0';
return nullchar;
}
}
#endif const char & operator[](size_t idx) const
{
cout << "const char & operator[](size_t) const " << endl;
return _pstr[idx];
} private:
void initRefcount()
{ *((int*)(_pstr - 4)) = 1; } void increaseRefcount()
{ ++*((int *)(_pstr - 4)); } void decreaseRefcount()
{ --*((int *)(_pstr - 4)); } void release() {
decreaseRefcount();
if(refcount() == 0)
{
delete [] (_pstr - 4);
cout << ">> delete heap data!" << endl;
}
} friend std::ostream & operator<<(std::ostream & os, const String & rhs); private:
char * _pstr;
}; //执行写(修改)操作
String::CharProxy & String::CharProxy::operator=(const char & ch)
{
if(_idx < _self.size())
{
if(_self.refcount() > 1)
{
char * tmp = new char[_self.size() + 5]();
tmp += 4;
strcpy(tmp, _self._pstr);
_self.decreaseRefcount();
_self._pstr = tmp;
_self.initRefcount();
}
_self._pstr[_idx] = ch;//执行修改
}
return *this;
} //执行读操作
std::ostream & operator<<(std::ostream & os, const String::CharProxy & rhs)
{
os << rhs._self._pstr[rhs._idx];
return os;
} std::ostream & operator<<(std::ostream & os, const String & rhs)
{
os << rhs._pstr;
return os;
} int main(void)
{
String s1;
String s2(s1);
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "s1's refcount = " << s1.refcount() << endl; String s3 = "hello,world";
String s4(s3); cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; String s5 = "hello,shenzheng";
cout << "s5 = " << s5 << endl;
s5 = s4;
cout << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行写操作之后:" << endl;
s5[0] = 'X';//char& --> 内置类型
//CharProxy cp = ch;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行读操作: " << endl;
cout << "s3[0] = " << s3[0] << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; const String s6("hello");
cout << s6[0] << endl; return 0;
}
2、代理模式:借助自定义嵌套类Char,可以不用重载operator<<和operator=
#include <stdio.h>
#include <string.h>
#include <iostream>
using std::cout;
using std::endl; class String
{
//设计模式之代理模式
class CharProxy
{
public:
CharProxy(size_t idx, String & self)
: _idx(idx)
, _self(self)
{} CharProxy & operator=(const char & ch); //执行读操作
operator char()
{
cout << "operator char()" << endl;
return _self._pstr[_idx];
} private:
size_t _idx;
String & _self;
}; public:
String()
: _pstr(new char[5]())
{
_pstr += 4;
initRefcount();
} String(const char * pstr)
: _pstr(new char[strlen(pstr) + 5]())
{
_pstr += 4;
initRefcount();
strcpy(_pstr, pstr);
} //代码本身就能解释自己 --> 自解释
String(const String & rhs)
: _pstr(rhs._pstr) //浅拷贝
{
increaseRefcount();
} String & operator=(const String & rhs)
{
if(this != & rhs) // 自复制
{
release(); //回收左操作数的空间
_pstr = rhs._pstr; // 进行浅拷贝
increaseRefcount();
}
return *this;
} ~String() {
release();
} size_t refcount() const { return *((int *)(_pstr - 4));} size_t size() const { return strlen(_pstr); } const char * c_str() const { return _pstr; } //自定义类型
CharProxy operator[](size_t idx)
{
return CharProxy(idx, *this);
}
#if 0
//问题: 下标访问运算符不能区分读操作和写操作
char & operator[](size_t idx)
{
if(idx < size())
{
if(refcount() > 1)
{// 进行深拷贝
decreaseRefcount();
char * tmp = new char[size() + 5]();
tmp += 4;
strcpy(tmp, _pstr);
_pstr = tmp;
initRefcount();
}
return _pstr[idx];
} else {
static char nullchar = '\0';
return nullchar;
}
}
#endif const char & operator[](size_t idx) const
{
cout << "const char & operator[](size_t) const " << endl;
return _pstr[idx];
} private:
void initRefcount()
{ *((int*)(_pstr - 4)) = 1; } void increaseRefcount()
{ ++*((int *)(_pstr - 4)); } void decreaseRefcount()
{ --*((int *)(_pstr - 4)); } void release() {
decreaseRefcount();
if(refcount() == 0)
{
delete [] (_pstr - 4);
cout << ">> delete heap data!" << endl;
}
} friend std::ostream & operator<<(std::ostream & os, const String & rhs); private:
char * _pstr;
}; //执行写(修改)操作
String::CharProxy & String::CharProxy::operator=(const char & ch)
{
if(_idx < _self.size())
{
if(_self.refcount() > 1)
{
char * tmp = new char[_self.size() + 5]();
tmp += 4;
strcpy(tmp, _self._pstr);
_self.decreaseRefcount();
_self._pstr = tmp;
_self.initRefcount();
}
_self._pstr[_idx] = ch;//执行修改
}
return *this;
} std::ostream & operator<<(std::ostream & os, const String & rhs)
{
os << rhs._pstr;
return os;
} int main(void)
{
String s1;
String s2(s1);
cout << "s1 = " << s1 << endl;
cout << "s2 = " << s2 << endl;
cout << "s1's refcount = " << s1.refcount() << endl; String s3 = "hello,world";
String s4(s3); cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; String s5 = "hello,shenzheng";
cout << "s5 = " << s5 << endl;
s5 = s4;
cout << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行写操作之后:" << endl;
s5[0] = 'X';//char& --> 内置类型
//CharProxy cp = ch;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; cout << "执行读操作: " << endl;
cout << "s3[0] = " << s3[0] << endl;
cout << "s5 = " << s5 << endl;
cout << "s3 = " << s3 << endl;
cout << "s4 = " << s4 << endl;
cout << "s5's refcount = " << s5.refcount() << endl;
cout << "s3's refcount = " << s3.refcount() << endl;
printf("s5's address = %p\n", s5.c_str());
printf("s3's address = %p\n", s3.c_str());
printf("s4's address = %p\n", s4.c_str());
cout << endl; const String s6("hello");
cout << s6[0] << endl; return 0;
}
运行结果:
s1=
s2=
s1.refcount=
s3=helloworld
s4=helloworld
s1.refcount=
s3.address=0x16b9054
s4.address=0x16b9054 s5 = Xelloworldjeiqjeiqoej
>>delete heap data1 s5=helloworld
s3=helloworld
s4=helloworld
s3.refcount =
s5.address=0x16b9054
s3.address=0x16b9054
s4.address=0x16b9054 执行读操作
operator char()
s3[] = h
s5 = helloworld
s3 = helloworld
s4 = helloworld
s5.refcount =
s3.refcount =
s3.address=0x16b9054
s4.address=0x16b9054 const char operator[](size_t)const
h
s6'address=0x7ffffdcdce40
>>delete heap data1
>>delete heap data1
>>delete heap data1
cthon@zrw:~/c++/$ vim cowstring1.cc
cthon@zrw:~/c++/$ g++ cowstring1.cc
cthon@zrw:~/c++/$ ./a.out
s1=
s2=
s1.refcount=
s3=helloworld
s4=helloworld
s1.refcount=
s3.address=0xb18054
s4.address=0xb18054 s5 = Xelloworldjeiqjeiqoej
>>delete heap data1 s5=helloworld
s3=helloworld
s4=helloworld
s3.refcount =
s5.address=0xb18054
s3.address=0xb18054
s4.address=0xb18054//这里s3/s4/s5指向同一个内存空间,发现没,这就是cow的妙用 执行读操作
operator char()
s3[] = h
s5 = helloworld
s3 = helloworld
s4 = helloworld
s5.refcount =
s3.refcount =
s3.address=0xb18054
s4.address=0xb18054 const char operator[](size_t)const
h
s6'address=0x7ffe8bbeadc0
>>delete heap data1
>>delete heap data1
>>delete heap data1
那么实际的COW时怎么实现的呢,带着疑问,我们看下面:
Scott Meyers在《Effective STL》[3]第15条提到std::string有很多实现方式,归纳起来有三类,而每类又有多种变化。
1、无特殊处理(eager copy),采用类似std::vector的数据结构。现在很少采用这种方式。
2、Copy-on-write(COW),g++的std::string一直采用这种方式,不过慢慢被SSO取代。
3、短字符串优化(SSO),利用string对象本身的空间来存储短字符串。VisualC++2010、clang libc、linux gnu5.x之后都采用的这种方式。
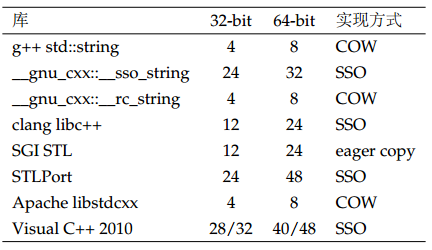
VC++的std::string的大小跟编译模式有关,表中的小的数字时release编译,大的数字是debug编译。因此debug和release不能混用。除此以外,其他库的string大小是固定的。
这几种实现方式都要保存三种数据:1、字符串本身(char*),2、字符串长度(size),3、字符串容量(capacity).
直接拷贝(eager copy)
类似std::vector的“三指针结构”:
class string
{
public :
const _pointer data() const{ return start; }
iterator begin(){ return start; }
iterator end(){ return finish; }
size_type size() const{ return finish - start; }
size_type capacity()const{ return end_of_storage -start; } private:
char* start;
char* finish;
char* end_of_storage;
}
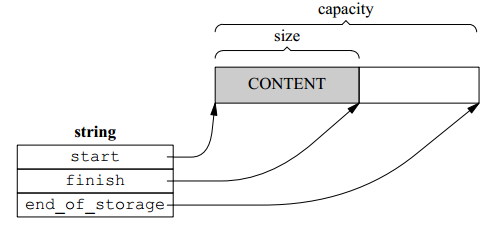
对象的大小是3个指针,在32位系统中是12字节,64位系统中是24字节。
Eager copy string 的另一种实现方式是把后两个成员变量替换成整数,表示字符串的长度和容量:
class string
{
public :
const _pointer data() const{ return start; }
iterator begin(){ return start; }
iterator end(){ return finish; }
size_type size() const{ return size_; }
size_type capacity()const{ return capacity; } private:
char* start;
size_t size_;
size_t capacity;
}
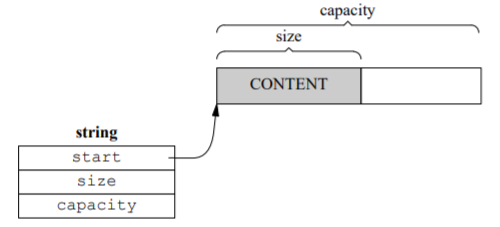
这种做法并没有多大改变,因为size_t和char*是一样大的。但是我们通常用不到单个几百兆字节的字符串,那么可以在改变以下长度和容量的类型(从64bit整数改成32bit整数)。
class string
{
private:
char* start;
size_t size_;
size_t capacity;
}
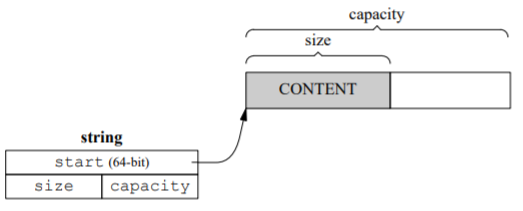
新的string结构在64位系统中是16字节。
COW写时复制(copy-on-write)
所谓COW就是指,复制的时候不立即申请新的空间,而是把这一过程延迟到写操作的时候,因为在这之前,二者的数据是完全相同的,无需复制。这其实是一种广泛采用的通用优化策略,它的核心思想是懒惰处理多个实体的资源请求,在多个实体之间共享某些资源,直到有实体需要对资源进行修改时,才真正为该实体分配私有的资源。
string对象里只放一个指针:
class string
{
sturuct
{
size_t size_;
size_t capacity;
size_t refcount;
char* data[1];//变量长度
}
char* start;
} ;
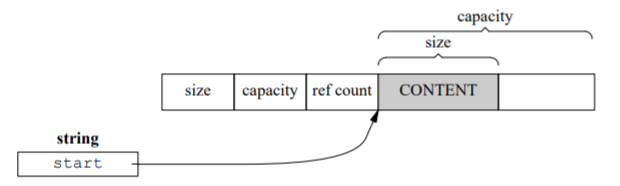
COW的操作复杂度,卡被字符串是O(1),但拷贝之后第一次operator[]有可能是O(N)。
优点
1. 一方面减少了分配(和复制)大量资源带来的瞬间延迟(注意仅仅是latency,但实际上该延迟被分摊到后续的操作中,其累积耗时很可能比一次统一处理的延迟要高,造成throughput下降是有可能的)
2. 另一方面减少不必要的资源分配。(例如在fork的例子中,并不是所有的页面都需要复制,比如父进程的代码段(.code)和只读数据(.rodata)段,由于不允许修改,根本就无需复制。而如果fork后面紧跟exec的话,之前的地址空间都会废弃,花大力气的分配和复制只是徒劳无功。)
实现机制
COW的实现依赖于引用计数(reference count, rc),初始时rc=1,每次赋值复制时rc++,当修改时,如果rc>1,需要申请新的空间并复制一份原来的数据,并且rc--,当rc==0时,释放原内存。
不过,实际的stringCOW实现中,对于什么是”写操作”的认定和我们的直觉是不同的,考虑以下代码:
string a = "Hello";
string b = a;
cout << b[] << endl;
以上代码显然没有修改string b的内容,此时似乎a和b是可以共享一块内存的,然而由于string的operator[]和at()会返回某个字符的引用,此时无法准确的判断程序是否修改了string的内容,为了保证COW实现的正确性,string只得统统认定operator[]和at()具有修改的“语义”。
这就导致string的COW实现存在诸多弊端(除了上述原因外,还有线程安全的问题,可进一步阅读文末参考资料),因此只有老版本的GCC编译器和少数一些其他编译器使用了此方式,VS、Clang++、GCC 5.x等编译器均放弃了COW策略,转为使用SSO策略。
SSO 短字符串优化(short-string-optimization)
string对象比前两个都打,因为有本地缓冲区。
class string
{
char* start;
size_t size; static const int KlocalSize = 15; union
{
char buf[klocalSize+1];
size_t capacity;
}data;
};
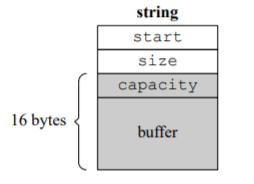
如果字符串比较短(通常设为15个字节以内),那么直接存放在对象的buf里。start指向data.buf。
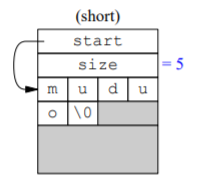
如果字符串超过15个字节,那么就编程eager copy 2的结构,start指向堆上分配的空间。
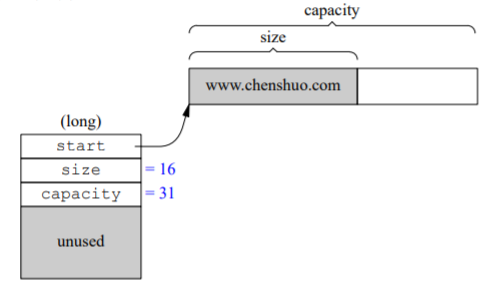
短字符串优化的实现方式不止一种,主要区别是把那三个指针/整数中的哪一 个与本地缓冲重合。例如《Effective STL》[3] 第 15 条展现的“实现 D” 是将 buffer 与 start 指针重合,这正是 Visual C++ 的做法。而 STLPort 的 string 是将 buffer 与 end_of_storage 指针重合。
SSO string 在 64-bit 中有一个小小的优化空间:如果允许字符串 max_size() 不大 于 4G 的话,我们可以用 32-bit 整数来表示长度和容量,这样同样是 32 字节的 string 对象,local buffer 可以增大至 19 字节。
class sso_string // optimized for 64-bit
{
char* start;
uint32_t size;
static const int kLocalSize = sizeof(void*) == 8 ? 19 : 15;
union
{
char buffer[kLocalSize+1];
uint32_t capacity;
} data;
};
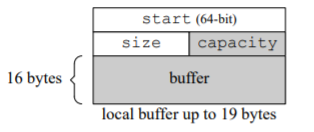
llvm/clang/libc++ 采用了与众不同的 SSO 实现,空间利用率最高,local buffer 几乎与三个指针/整数完全重合,在 64-bit 上对象大小是 24 字节,本地缓冲区可达 22 字节。
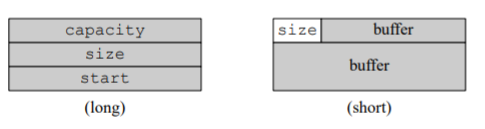
它用一个 bit 来区分是长字符还是短字符,然后用位操作和掩码 (mask) 来取重 叠部分的数据,因此实现是 SSO 里最复杂的。
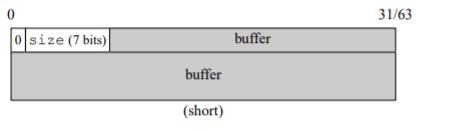
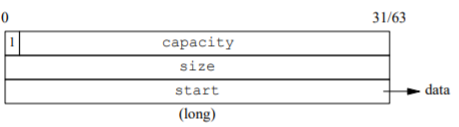
实现机制
SSO策略中,拷贝均使用立即复制内存的方法,也就是深拷贝的基本定义,其优化在于,当字符串较短时,直接将其数据存在栈中,而不去堆中动态申请空间,这就避免了申请堆空间所需的开销。
使用以下代码来验证一下:
int main() {
string a = "aaaa";
string b = "bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb";
printf("%p ------- %p\n", &a, a.c_str());
printf("%p ------- %p\n", &b, b.c_str());
return 0;
}
某次运行的输出结果为:
1 |
0136F7D0 ------- 0136F7D4 |
可以看到,a.c_str()的地址与a、b本身的地址较为接近,他们都位于函数的栈空间中,而b.c_str()则离得较远,其位于堆中。
SSO是目前大部分主流STL库的实现方式,其优点就在于,对程序中经常用到的短字符串来说,运行效率较高。
-----------------------------------------------------------------------------------------------------------------------------------------------------
基于”共享“和”引用“计数的COW在多线程环境下必然面临线程安全的问题。那么:
std::string是线程安全的吗?
在stackoverflow上对这个问题的一个很好的回答:是又不是。
从在多线程环境下对共享的string对象进行并发操作的角度来看,std::string不是线程安全的,也不可能是线程安全的,像其他STL容器一样。
c++11之前的标准对STL容器和string的线程安全属性不做任何要求,甚至根本没有线程相关的内容。即使是引入了多线程编程模型的C++11,也不可能要求STL容器的线程安全:线程安全意味着同步,同步意味着性能损失,贸然地保证线程安全必然违背了C++的哲学:
| Don't pay for things you don't use. |
但从不同线程中操作”独立“的string对象来看,std::string必须是线程安全的。咋一看这似乎不是要求,但COW的实现使两个逻辑上独立的string对象在物理上共享同一片内存,因此必须实现逻辑层面的隔离。C++0x草案(N2960)中就有这么一段:
The C++0x draft (N2960) contains the section "data race avoidance" which basically says that library |
简单说来就是:你瞒着用户使用共享内存是可以的(比如用COW实现string),但你必须负责处理可能的竞态条件。
而COW实现中避免竞态条件的关键在于:
1. 只对引用计数进行原子增减
2. 需要修改时,先分配和复制,后将引用计数-1(当引用计数为0时负责销毁)
总结:
1、针对不同的应用负载选用不同的 string,对于短字符串,用 SSO string;对于中等长度的字符串,用 eager copy;对于长字符串,用 COW。具体分界点需要靠 profiling 来确定,选用合适的字符串可能提高 10% 的整 体性能。 从实现的复杂度上看,eager copy 是最简单的,SSO 稍微复杂一些,COW 最 难。
2、了解COW的缺陷依然可以使我们优化对string的使用:尽量避免在多个线程间false sharing同一个“物理string“,尽量避免在对string进行只读访问(如打印)时造成了不必要的内部拷贝。
说明:vs2010、clang libc++、linux gnu5都已经抛弃了COW,拥抱了SSO,facebook更是开发了自己fbstring。
fbstring简单说明:
> 很短的用SSO(0-22), 23字节表示字符串(包括’\0′), 1字节表示长度.
> 中等长度的(23-255)用eager copy, 8字节字符串指针, 8字节size, 8字节capacity.
> 很长的(>255)用COW. 8字节指针(指向的内存包括字符串和引用计数), 8字节size, 8字节capacity.
参考资料:
std::string的Copy-on-Write:不如想象中美好
C++ 工程实践(10):再探std::string
Why is COW std::string optimization still enabled in GCC 5.1?
C++ string的COW和SSO
c++再探string之eager-copy、COW和SSO方案的更多相关文章
- 8,SSO,,eager copy,COW
针对字符串不同的长度,“编译器”选择不同的优化策略:SSO, eager copy,COW,分别针对短字符串,中等长度字符串,长字符串.不过,现在(2016)的大多数编译器(gcc 4.9.1,vs2 ...
- ViewPager+Fragment再探:和TAB滑动条一起三者结合
Fragment前篇: <Android Fragment初探:静态Fragment组成Activity> ViewPager前篇: <Android ViewPager初探:让页面 ...
- [转] 请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧
这帖是用来回复高级语言虚拟机圈子里的一个问题,一道Java笔试题的. 本来因为见得太多已经吐槽无力,但这次实在忍不住了就又爆发了一把.写得太长干脆单独开了一帖. 顺带广告:对JVM感兴趣的同学们同志们 ...
- [老老实实学WCF] 第五篇 再探通信--ClientBase
老老实实学WCF 第五篇 再探通信--ClientBase 在上一篇中,我们抛开了服务引用和元数据交换,在客户端中手动添加了元数据代码,并利用通道工厂ChannelFactory<>类创 ...
- 第四节:SignalR灵魂所在Hub模型及再探聊天室样例
一. 整体介绍 本节:开始介绍SignalR另外一种通讯模型Hub(中心模型,或者叫集线器模型),它是一种RPC模式,允许客户端和服务器端各自自定义方法并且相互调用,对开发者来说相当友好. 该节包括的 ...
- 深入出不来nodejs源码-内置模块引入再探
我发现每次细看源码都能发现我之前写的一些东西是错误的,去改掉吧,又很不协调,不改吧,看着又脑阔疼…… 所以,这一节再探,是对之前一些说法的纠正,另外再缝缝补补一些新的内容. 错误在哪呢?在之前的初探中 ...
- 请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧---转
http://www.iteye.com/topic/774673 羞愧呀,不知道多少人干过,我也干过,面壁去! 这帖是用来回复高级语言虚拟机圈子里的一个问题,一道Java笔试题的. 本来因为见得太多 ...
- 【再探backbone 02】集合-Collection
前言 昨天我们一起学习了backbone的model,我个人对backbone的熟悉程度提高了,但是也发现一个严重的问题!!! 我平时压根没有用到model这块的东西,事实上我只用到了view,所以昨 ...
- 再探jQuery
再探jQuery 前言:在使用jQuery的时候发现一些知识点记得并不牢固,因此希望通过总结知识点加深对jQuery的应用,也希望和各位博友共同分享. jQuery是一个JavaScript库,它极大 ...
随机推荐
- HttpClient获取Cookie的两种方式
转载:http://blog.csdn.net/zhangbinu/article/details/72777620 一.旧版本的HttpClient获取Cookies p.s. 该方式官方已不推荐使 ...
- 使用cacheBuilder实现函数防抖
在接口中出现的相同请求重复且连续发送的情况导致一些业务BUG,需要在接口上实现防抖 使用google的cacheBuilder import com.google.common.cache.Cache ...
- vue2.0 自定义 下拉刷新和上拉加载更多(Scroller) 组件
1.下拉刷新和上拉加载更多组件 Scroller.vue <!-- 下拉刷新 上拉加载更多 组件 --> <template> <div :style="mar ...
- d3js 添加数据
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- python(31)- 模块练习
1. 小程序:根据用户输入选择可以完成以下功能: 创意文件,如果路径不存在,创建文件夹后再创建文件 能够查看当前路径 在当前目录及其所有子目录下查找文件名包含指定字符串的文件 ...
- Mysql多线程性能测试工具sysbench 安装、使用和测试
From:http://www.cnblogs.com/zhoujinyi/archive/2013/04/19/3029134.html 摘要: sysbench是一个开源的.模块化的.跨 ...
- django 运行python manage.py sqlall books 时报错 app has migration
出现这个问题的原因是版本之前的不兼容,我用的django版本是1.8.6 而 这条python manage.py sqlall books 是基于django1.0版本的. 在django1.8.6 ...
- Sublime Text3 配置设置攻略
转载:http://cloudbbs.org/forum.php?mod=viewthread&tid=3620 sublime本身功能有限,我们需要装上一些插件使其变得强大.sublime在 ...
- 宜信开源|分布式任务调度平台SIA-TASK的架构设计与运行流程
一.分布式任务调度的背景 无论是互联网应用或者企业级应用,都充斥着大量的批处理任务.我们常常需要一些任务调度系统来帮助解决问题.随着微服务化架构的逐步演进,单体架构逐渐演变为分布式.微服务架构.在此背 ...
- mysql中索引的使用
索引是加速查询的主要手段,特别对于涉及多个表的查询更是如此.本节中,将介绍索引的作用.特点,以及创建和删除索引的语法. 使用索引优化查询 索引是快速定位数据的技术,首先通过一个示例来了解其含义及作用. ...