Python3爬取起点中文网阅读量信息,解决文字反爬~~~附源代码
起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf
通过浏览器的“检查”显示的是“□”,但是可以在网页源代码中找到映射后的数字
正则爬的是网页源代码,xpath是默认utf-8解析网页数据,用xpath爬出来的也是方框,因此只能使用正则匹配爬取关键数字信息
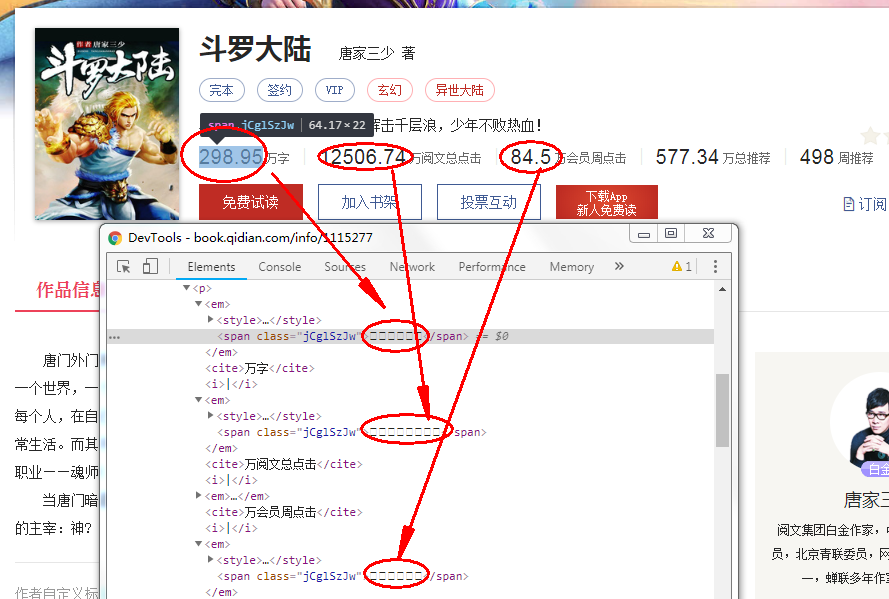

本例以小说《斗罗大陆》为例 https://book.qidian.com/info/1115277,爬取阅读量等数字信息
爬取思路:
1. 使用正则匹配爬取出网页源代码中的被设置反爬的数字信息(这里只能使用正则匹配)
2. 寻找数字的映射关系
2.1 爬取出网页中的字体文件地址,并下载这个文件
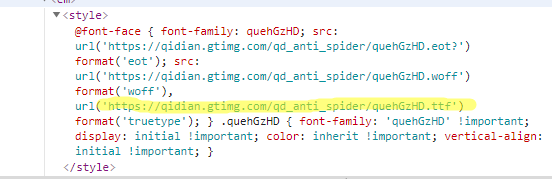
2.2 使用软件FontCreator(请度娘自行下载)打开文件,可以看到英文和数字的对应关系,写入字典
在本例中是按照习惯对应的(有可能有的文件自定义是打乱的)

#在fontcreator中查看此ttf文件中英文单词与阿拉伯数字的映射关系,写入字典
python_font_relation = {
'one':1,
'two':2,
'three':3,
'four':4,
'five':5,
'six':6,
'seven':7,
'eight':8,
'nine':9,
'zero':0,
'period':'.'
}
2.3 在python中安装fontTools包,网页源代码中的数字与英文单词的对应关系
def get_font(url):
"""
获取源代码中数字信息与英文单词之间的映射关系
:param url: <str> 网页源代码中的字体地址
:return: <dict> 网页字体映射关系
"""
time.sleep(1)
response = requests.get(url)
font = TTFont(BytesIO(response.content))
web_font_relation = font.getBestCmap()
font.close()
return web_font_relation
结果是:

3. 通过2.2与2.3 可以看出来解码需要两步:
第一步:将正则匹配出来的6位数字先转换成英文单词
第二步:将英文单词转换成阿拉伯数字
然后就ok啦

源代码:
1. 正则匹配没有展开讲,自行度娘吧
2. 有一些简单的数据处理工作,细心点一步一步来,实在不行就每次都输出看一下
"""
起点中文网,在“数字”上设置了文字反爬,使用了自定义的文字文件ttf
浏览器渲染不出来,但是可以在网页源代码中找到映射后的数字
正则爬的是网页源代码 xpath是默认utf-8解析网页数据;网页源代码有数据,使用浏览器"检查"是方框,用xpath爬出来的也是方框
以小说《斗罗大陆》为例 https://book.qidian.com/info/1115277
"""
import requests, time, re, pprint
from fontTools.ttLib import TTFont
from io import BytesIO
from lxml import etree #此代码使用bs和xpath均无法爬出,需使用正则匹配
#selector = etree.HTML(html_data.text)
#word1 = selector.xpath('//div[2]/div[6]/div[1]/div[2]/p[3]/em[1]/span/text()') def get_font(url):
"""
获取源代码中数字信息与英文单词之间的映射关系
:param url: <str> 网页源代码中的字体地址
:return: <dict> 网页字体映射关系
"""
time.sleep(1)
response = requests.get(url)
font = TTFont(BytesIO(response.content))
web_font_relation = font.getBestCmap()
font.close()
return web_font_relation #在fontcreator中查看此ttf文件中英文单词与阿拉伯数字的映射关系,写入字典
python_font_relation = {
'one':1,
'two':2,
'three':3,
'four':4,
'five':5,
'six':6,
'seven':7,
'eight':8,
'nine':9,
'zero':0,
'period':'.'
} def get_html_info(url):
"""
解析网页,获取文字文件的地址和需要解码的数字信息
:param url: <str> 需要解析的网页地址
:return: <str> 文字文件ttf的地址
<list> 反爬的数字,一维列表
"""
headers = {
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
html_data = requests.get(url, headers=headers)
# 获取网页的文字ttf文件的地址
url_ttf_pattern = re.compile('<style>(.*?)\s*</style>',re.S)
fonturl = re.findall(url_ttf_pattern,html_data.text)[0]
url_ttf = re.search('woff.*?url.*?\'(.+?)\'.*?truetype', fonturl).group(1) # 获取所有反爬的数字
word_pattern = re.compile('</style><span.*?>(.*?)</span>', re.S)#制定正则匹配规则,匹配所有<span>标签中的内容
numberlist = re.findall(word_pattern, html_data.text) return url_ttf,numberlist def get_encode_font(numberlist):
"""
把源代码中的数字信息进行2次解码
:param numberlist: <list> 需要解码的一维数字信息
:return:
"""
data = []
for i in numberlist:
fanpa_data = ''
index_i = numberlist.index(i)
words = i.split(';')
#print('words:',words)
for k in range(0,len(words)-1):
words[k] = words[k].strip('&#')
#print(words[k])
words[k] = str(python_font_relation[web_font_relation[int(words[k])]])
#print(words[k])
fanpa_data += words[k]
#print(fanpa_data)
data.append(fanpa_data)
print(data[0],'万字')
print(data[1], '万阅文总点击')
print(data[2], '万会员周点击')
print(data[3], '万总推荐')
print(data[4], '万周推荐')
# return data """程序主入口"""
if __name__=='__main__':
url = 'https://book.qidian.com/info/1115277' # 选取某一小说
get_html_info(url)
web_font_relation = get_font(get_html_info(url)[0])
pprint.pprint(web_font_relation)#格式化打印网页文字映射关系
get_encode_font(get_html_info(url)[1])
Python3爬取起点中文网阅读量信息,解决文字反爬~~~附源代码的更多相关文章
- 爬虫简单之二---使用进程爬取起点中文网的六万多也页小说的名字,作者,等一些基本信息,并存入csv中
爬虫简单之二---使用进程爬取起点中文网的六万多也页小说的名字,作者,等一些基本信息,并存入csv中 准备使用的环境和库Python3.6 + requests + bs4 + csv + multi ...
- Python3爬取起猫眼电影实时票房信息,解决文字反爬~~~附源代码
上文解决了起点中文网部分数字反爬的信息,详细链接https://www.cnblogs.com/aby321/p/10214123.html 本文研究另一种文字反爬的机制——猫眼电影实时票房反爬 虽然 ...
- 零基础爬虫----python爬取豆瓣电影top250的信息(转)
今天利用xpath写了一个小爬虫,比较适合一些爬虫新手来学习.话不多说,开始今天的正题,我会利用一个案例来介绍下xpath如何对网页进行解析的,以及如何对信息进行提取的. python环境:pytho ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- 使用python爬取MedSci上的期刊信息
使用python爬取medsci上的期刊信息,通过设定条件,然后获取相应的期刊的的影响因子排名,期刊名称,英文全称和影响因子.主要过程如下: 首先,通过分析网站http://www.medsci.cn ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- 利用xpath爬取招聘网的招聘信息
爬取招聘网的招聘信息: import json import random import time import pymongo import re import pandas as pd impor ...
- 亚马逊商品页面的简单爬取 --Pyhon网络爬虫与信息获取
1.亚马逊商品页面链接地址(本次要爬取的页面url) https://www.amazon.cn/dp/B07BSLQ65P/ 2.代码部分 import requestsurl = "ht ...
- 第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息
第三百三十四节,web爬虫讲解2—Scrapy框架爬虫—Scrapy爬取百度新闻,爬取Ajax动态生成的信息 crapy爬取百度新闻,爬取Ajax动态生成的信息,抓取百度新闻首页的新闻rul地址 有多 ...
随机推荐
- Python3基础(3)集合、文件操作、字符转编码、函数、全局/局部变量、递归、函数式编程、高阶函数
---------------个人学习笔记--------------- ----------------本文作者吴疆-------------- ------点击此处链接至博客园原文------ 1 ...
- SpringMVC07SelfException 自定义异常
1.配置web.xml文件 <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3// ...
- Centos 6.5 添加PHP5.6-7.1的源
centOS6.5 安装后 自带的源中php是5.3版本的,对与php一些常用的框架而言 ,已经不能满足需求了: 使用下面的源 就可以更新到php7.1版本了. # rpm -Uvh http://r ...
- 解决WinSCP连接虚拟机
其实虚拟机你也可以将它形象化,认为它就是一台电脑,只是这个电脑在你的内存中,所以,一般电脑所具有的的功能虚拟机一样拥有,它也可以当成一台独立的个体哦. 针对很多使用WinSCP连接不上虚拟机的问题,这 ...
- 实现简单Restful API
1. 首选我们通过 http://start.spring.io/ 网址生成一个基础spring boot 项目,截图配置如下: 点击 generate Project 按钮生成并下载基础项目 2. ...
- hibernate课程 初探单表映射2-5 session详解(上)
1 本章目的:获得session的两种方式: openSession 和 getCurrentSession 2 两种session的使用方法 1openSession可以直接写,getCurrent ...
- hibernate课程 初探单表映射1-3 hibernate简介
1 hibernate定义: Java领域一项开源的orm框架技术: hibernate对jdbc进行轻量级的封装. hibernate 作为持久层存在.就是通过对象关系映射把项目中的对象持久化到数据 ...
- 面向对象(OOP)二
一.“魔术”函数 - 自动调用 魔术方法 在面向对象有一些特别的方法,无需特别定义,已自动具备某些功能,例如构造函数__construt,这些方法统称魔术方法,在日后的编程中,可以使用这些方法的特性设 ...
- javascript之常用正则表达式
一.校验数字的表达式 1 数字:^[0-9]*$ 2 n位的数字:^\d{n}$ 3 至少n位的数字:^\d{n,}$ 4 m-n位的数字:^\d{m,n}$ 5 零和非零开头的数字:^(0|[1-9 ...
- 【迷你微信】基于MINA、Hibernate、Spring、Protobuf的即时聊天系统:6.技术简介之Protobuf
欢迎阅读我的开源项目<迷你微信>服务器与<迷你微信>客户端 protocolbuffer(以下简称Protobuf)是google 的一种数据交换的格式,它独立于语言,独立于平 ...