Hadoop- Wordcount程序原理及代码实现
如果对Hadoop- MapReduce分布式计算框架原理还不熟悉的可以先了解一下它,因为本文的wordcount程序实现就是MapReduce分而治之最经典的一个范例。
单词计数(wordcount)主要步骤:
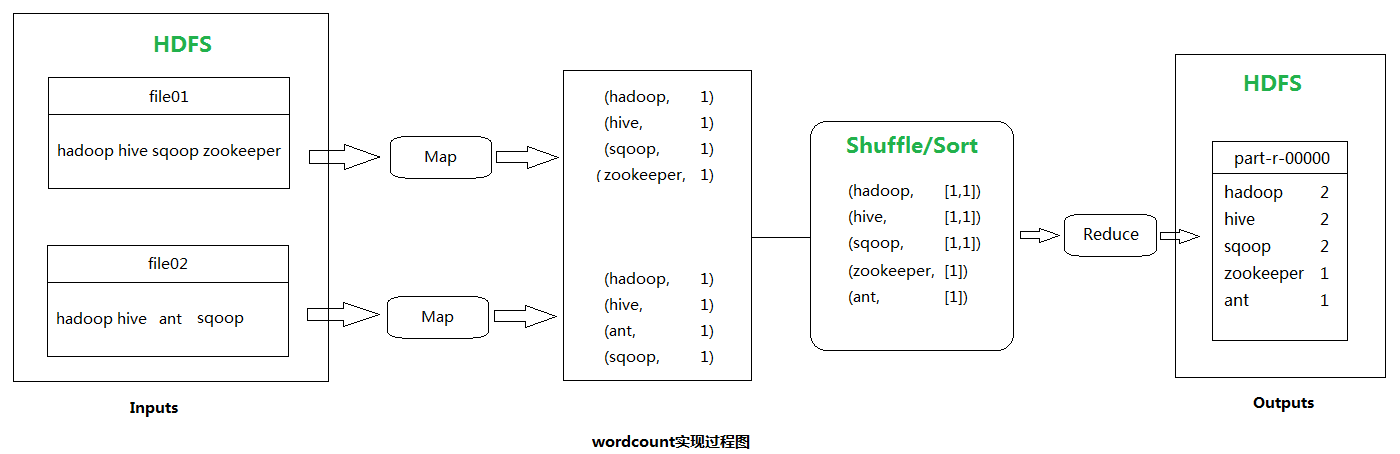
代码实现:
理解了原理,那么就从一个Job开始,从分Map任务和Reduce任务开始。用户编写的程序分为三个部分:Mapper,Reducer,Driver。
Mapper的输入数据和输出数据是KV对的形式(KV的类型可自定义),Mapper的业务逻辑是写在map()方法中,map()方法(maptask进程)对每一个<k,v>调用一次
Reducer的输入数据类型对应Mapper的输出数据类型,也是KV。Reducer的业务逻辑写在reduce()方法中,Reduce()方法对每一组相同的<k,v>组调用一次。
用户的Mapper和Reduce都要继承各自的父类。
整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。
1.设定Map任务:
package cn.Rz_Lee.hadoop.com.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /**
* Created by Rz_Lee on 2017/8/14.
* KEYIN:默认情况下是mr框架所读到的一行文本的偏移量,Long
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
*
* VALUE:默认情况下是mr框架所读到的一行文本内容,String,同上用Text
*
*KEYOUT:是用户自定义逻辑处理写成之后输出数据中的key,在此是单词,String,同上,用Text
*VALUEOUT:是用户自定义逻辑处理写成之后输出数据中的value,在此处是单词总次数,Integer,同上,用IntWritale
*
*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
/**
* map阶段的业务逻辑就写在自定义的map()方法中
* maptask会对每一行输入数据调用一次我们自定义的map()方法
* @param key
* @param value
* @param context 输出内容
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将maptask传给我们的文本内容先转换成String
String line = value.toString();
//根据空格将一行切分成单词
String[] words = line.split(" "); //将单词输出为<单词,1>
for(String word:words)
{
//将单词作为key,将次数1作为value,以便于后续的数据分发,可以根据单词分发经便于相同单词会到相同的reduce task
context.write(new Text(word),new IntWritable(1));
}
}
}
2.设定Reduce任务:
package cn.Rz_Lee.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /**KEYIN,VALUEIN 对应mapper输出的KEYOUT,VALUEOUT类型对应
*
* KYEOUT,VALUEOUT 是自定义reduce逻辑处理结果的输出数据类型
* KYEOUT是单词
* VALUE是总次数
* Created by Rz_Lee on 2017/8/14.
*/
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
/**
*
* @param key 是一组相同单词KV对的key,如<hi,1>,<hi,1>
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable value:values)
{
count+=value.get();
}
context.write(key,new IntWritable(count));
}
}
3.wordcount程序的操作类,提交运行mr程序的yarn客户端:
package cn.Rz_Lee.hadoop.com..mr.wordcount; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**相当于一个yarn集群的客户端
* 需要在此封装我们的mr程序相关运行参数,指定jar包
* 最后提交给yarn
* Created by Rz_Lee on 2017/8/14.
*/
public class WordCountDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
/*conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname","srv01");*/ /*job.setJar("/usr/hadoop/wc.jar");*/
//指定本程序的jar包所在的本地路径
job.setJarByClass(WordCountDriver.class); //指定本业务job使用的mapper/reducer业务类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class); //指定mapper输出数据的KV类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class); //指定最终输出的数据的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1])); //将job中配置的相关参数,以及job所用的java类所在的jar包,提交给yarn去运行
/*job.submit();*/
boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
}
}
4.把wordcount项目导成jar包,上传到HDFS,运行 hadoop jar wordcount.jar 包.类名 /源文件路径 /输出数据文件夹
在yarn上面运行: yarn jar wordcount.jar 包.类名 /源文件路径 /输出数据文件夹
打开浏览器输入:yarn节点的IP:8088 ,在网页上可以看见整个Job的运行情况。
Hadoop- Wordcount程序原理及代码实现的更多相关文章
- 4、wordcount程序原理剖析及Spark架构原理
一.wordcount程序原理深度剖析 二.Spark架构原理 1.
- hadoop wordcount程序缺陷
在wordcount 程序的main函数中,没有读取运行环境中的各种参数的值,全靠hadoop系统的默认参数跑起来,这样做是有风险的,最突出的就是OOM错误. 自己在刚刚学习hadoop编程时,就是模 ...
- Hadoop WordCount程序
一.把所有Hadoop的依赖jar包导入buildpath,不用一个一个调,都导一遍就可以,因为是一个工程,所以覆盖是没有问题的 二.写wordcount程序 1.工程目录结构如下: 2.写mappe ...
- 大数据之路week07--day03(Hadoop深入理解,JAVA代码编写WordCount程序,以及扩展升级)
什么是MapReduce 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查并且数出有多少张是黑桃. MapReduce方法则是: 1.给在座的所有玩家中分配这摞牌 2.让每个玩家数自己手中的牌有几 ...
- Hadoop学习笔记(1):WordCount程序的实现与总结
开篇语: 这几天开始学习Hadoop,花费了整整一天终于把伪分布式给搭好了,激动之情无法言表······ 搭好环境之后,按着书本的代码,实现了这个被誉为Hadoop中的HelloWorld的程序--W ...
- Hadoop入门程序WordCount的执行过程
首先编写WordCount.java源文件,分别通过map和reduce方法统计文本中每个单词出现的次数,然后按照字母的顺序排列输出, Map过程首先是多个map并行提取多个句子里面的单词然后分别列出 ...
- Hadoop入门实践之从WordCount程序说起
这段时间需要学习Hadoop了,以前一直听说Hadoop,但是从来没有研究过,这几天粗略看完了<Hadoop实战>这本书,对Hadoop编程有了大致的了解.接下来就是多看多写了.以Hado ...
- hadoop学习笔记——用python写wordcount程序
尝试着用3台虚拟机搭建了伪分布式系统,完整的搭建步骤等熟悉了整个分布式框架之后再写,今天写一下用python写wordcount程序(MapReduce任务)的具体步骤. MapReduce任务以来H ...
- 020_自己编写的wordcount程序在hadoop上面运行,不使用插件hadoop-eclipse-plugin-1.2.1.jar
1.Eclipse中无插件运行MP程序 1)在Eclipse中编写MapReduce程序 2)打包成jar包 3)使用FTP工具,上传jar到hadoop 集群环境 4)运行 2.具体步骤 说明:该程 ...
随机推荐
- centos6.5下载
1.64位系统 http://mirrors.163.com/centos/6.5/isos/x86_64/CentOS-6.5-x86_64-bin-DVD1.iso http://mirrors. ...
- VueJS构造器:new Vue({})
构造器 每个 Vue.js 应用都是通过构造函数 Vue 创建一个 Vue 的根实例来启动的: var vm = new Vue({ // 选项 }) 属性与方法 每个 Vue 实例都会代理其 dat ...
- 关于iOS Tabbar的一些设置
事实上iOS Tabbar的可定制性很高,我们没有必要反复造轮子,以下是笔者收集的一些tabbar的经常使用设置.希望对大家有所帮助. 设置tabbar选中颜色 iOS7设置例如以下: [self.t ...
- 关于cocos2d-x 和安卓之间的相互调用
近期在研究cocos2d游戏移植安卓须要调用非常多方法.所以在研究之中写下它们之间相互调用 首先,cocos2d调用安卓 在一个.h文件里加入头文件 #include <jni.h> #i ...
- 常见的CPU訪问引起的内存保护问题为什么仅仅用event_122上报 - 举例2
还有一个样例.通过以下的log看,CPU在訪问reserved的地址0x53611EFD.非法訪问时该地址会在L1D内存控制器的L1DMPFSR寄存器中记录. ** FATAL EXCEPTION N ...
- Android Camera API2中采用CameraMetadata用于从APP到HAL的参数交互
前沿: 在全新的Camera API2架构下,常常会有人疑问再也看不到熟悉的SetParameter/Paramters等相关的身影,取而代之的是一种全新的CameraMetadata结构的出现,他不 ...
- linux 跟踪工具
strace工具,进程诊断.排错.跟踪系统调用和信号量 每行输出都是一个系统调用,包括函数和返回值. strace是Linux环境下的一款程序调试工具,用来监察一个应用程序所使用的系统调用及它所接收的 ...
- 全命令行手写MapReduce并且打包运行
主要要讲的有3个 java中的package是干啥的? 工作了好几年的都一定真正理解java里面的package关键字,这里在写MapReduce需要进行打包的时候突然发现命令行下打包运行居然不会了, ...
- linux下的显示有中国农历的日历ccal
1.linux下的显示有中国农历的日历ccal
- .net调用存储过程详解(转载)
本文的数据库用的是sql server 连接字符串 string conn = ConfigurationManager.ConnectionStrings["NorthwindConnec ...