OpenCV入门之获取验证码的单个字符(二)
在文章 OpenCV入门之获取验证码的单个字符(字符切割)中,介绍了一类验证码的处理方法,该验证码如下:
该验证码的特点是字母之间的间隔较大,很容易就能提取出其中的单个字符。接下来,笔者将会介绍如何在另一种验证码中提取单个字符的方法。
测试的验证码来源于某个账号注册的网站,如下:

笔者一共收集了346张验证码。我们可以看到,这些验证码的特点是:噪声较大,有些验证码之间的字母黏连在一起,这样的话,想要提取单个字符的难度会加大。
首先,我们按照文章 OpenCV入门之获取验证码的单个字符(字符切割)的处理方式来提取单个字符,看看效果,完整的Python
代码如下:

import os
import uuid
import cv2
def split_picture(imagepath):
# 以灰度模式读取图片
gray = cv2.imread(imagepath, 0)
# 将图片的边缘变为白色
height, width = gray.shape
for i in range(width):
gray[0, i] = 255
gray[height-1, i] = 255
for j in range(height):
gray[j, 0] = 255
gray[j, width-1] = 255
# 中值滤波
blur = cv2.medianBlur(gray, 3) #模板大小3*3
# 二值化
ret,thresh1 = cv2.threshold(blur, 200, 255, cv2.THRESH_BINARY)
# 提取单个字符
image, contours, hierarchy = cv2.findContours(thresh1, 2, 2)
for cnt in contours:
# 最小的外接矩形
x, y, w, h = cv2.boundingRect(cnt)
if x != 0 and y != 0 and w*h >= 100:
print((x,y,w,h))
# 显示图片
cv2.imwrite('E://chars/%s.jpg'%(uuid.uuid1()), thresh1[y:y+h, x:x+w])
def main():
dir = "E://verifycode"
for file in os.listdir(dir):
imagepath = dir+'/'+file
split_picture(imagepath)
main()
得到的单个字符的效果如下:
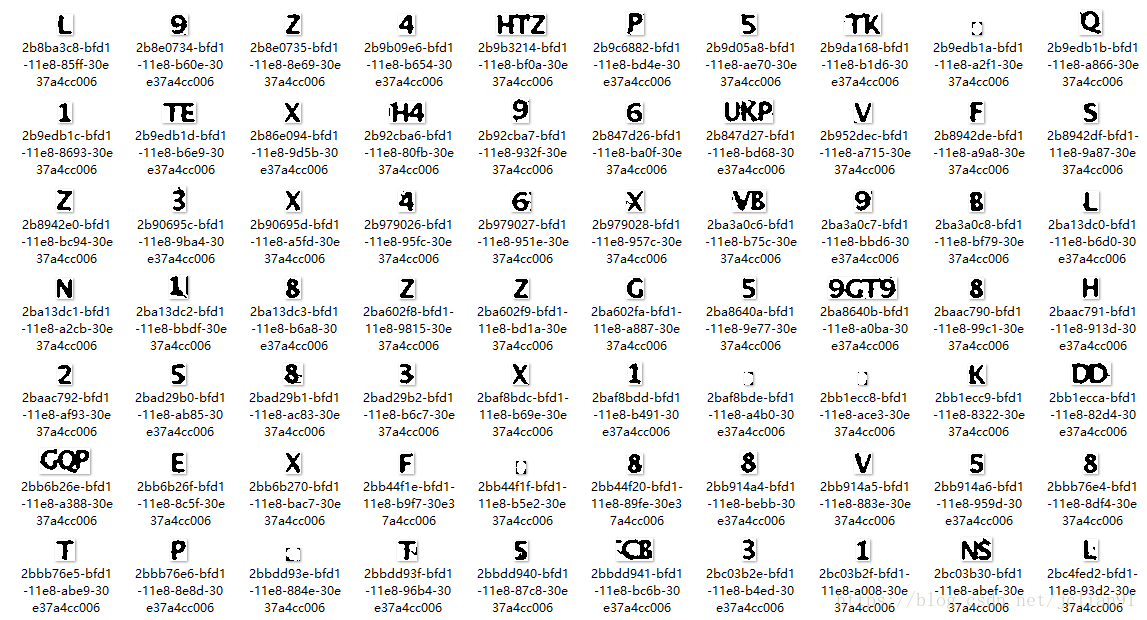
可以看到,虽然我们也能得到单个的字符,但是也产生了很多噪声图片以及黏连在一起的字符图片(以下简称黏连图片)。因此,下一步的工作是如何处理噪声图片和黏连图片。
首先我们介绍如何去掉噪声图片。观察以上的噪声图片,即中间有大片空白,角落里有部分黑色的图片,如下:

笔者选择的处理方式如下:在该图片的四个角落的像素点取值,一共是四个值,如果黑色像素的点大于等于3个,则被认为是噪声图片。处理的Python函数如下:
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
接着是黏连图片的处理,所谓黏连图片,指的是提取字符的图片中含有2个及以上字符的图片,如下:
对于黏连图片,我们很容易想到的处理方式就是均分图片,图片中含有几个字符,就将图片均分成几等分。那么,怎样才能知道图片中所含字符的数量呢?笔者暂时没有完美的处理方法,能想到的就是根据图片的宽度来决定字符的个数。根据观察,4个字符的图片宽度往往大于等于64,3个字符的图片宽度往往大于等于48,两个字符的图片往往大于等于26,因此,就把这个作为图片中含有字符数量的标准。处理黏连图片的Python代码如下:

def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
好了,有了以上处理噪声图片和黏连图片的方法,我们来试试处理后的效果,显示的图片如下:
一共是346张验证码,每个验证码4个字符,一共是1384张图片。按照这样处理方法,得到1381张图片,当然,存在极少的噪声图片(1~2张)和有些为切分的图片,如上图中用红线圈出的部分。总的来说,得到的有效单个字符的图片为1371张图片,提取的效率为99%,这无疑是极好的,达到了笔者的预期效果。
下面给出以上处理的完整的Python代码:

import os
import cv2
import uuid
def remove_edge_picture(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
corner_list = [image[0,0] < 127,
image[height-1, 0] < 127,
image[0, width-1]<127,
image[ height-1, width-1] < 127
]
if sum(corner_list) >= 3:
os.remove(imagepath)
def resplit_with_parts(imagepath, parts):
image = cv2.imread(imagepath, 0)
height, width = image.shape
# 将图片重新分裂成parts部分
step = width//parts # 步长
start = 0 # 起始位置
for _ in range(parts):
cv2.imwrite('E://chars/%s.jpg'%uuid.uuid1(), image[:, start:start+step])
start += step
os.remove(imagepath)
def resplit(imagepath):
image = cv2.imread(imagepath, 0)
height, width = image.shape
if width >= 64:
resplit_with_parts(imagepath, 4)
elif width >= 48:
resplit_with_parts(imagepath, 3)
elif width >= 26:
resplit_with_parts(imagepath, 2)
def main():
dir = 'E://chars'
for file in os.listdir(dir):
remove_edge_picture(imagepath=dir+'/'+file)
for file in os.listdir(dir):
resplit(imagepath=dir+'/'+file)
main()
今日中秋,祝大家中秋节快乐~
注意:本人现已开通两个微信公众号: 轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~
OpenCV入门之获取验证码的单个字符(二)的更多相关文章
- OpenCV入门之获取验证码的单个字符(字符切割)
介绍 在我们日常上网注册账号以及制作网络爬虫时,经常会遇到奇奇怪怪的验证码,有些容易,有些连人眼都无法辨识.于是,大牛们想到了用深度学习的方法来破解验证码,对于一般的验证码往往能出奇制胜,取得不俗 ...
- iOS 获取字符串中的单个字符
要取到单个字符,就要知道字符串的编码方式,这样才能够定位每个字符在内存中的位置.但是,iOS的字符串编码是不固定的,因此,需要设置一个统一的编码格式,将所有其他格式的字符串都转化为统一的格式,然后就可 ...
- C#获取单个字符的拼音声母
public class ConvertToPinYing { /// <summary> /// 汉字转拼音缩写 /// < ...
- OpenCV入门学习笔记
OpenCV入门学习笔记 参照OpenCV中文论坛相关文档(http://www.opencv.org.cn/) 一.简介 OpenCV(Open Source Computer Vision),开源 ...
- [验证码识别技术] 字符型验证码终结者-CNN+BLSTM+CTC
验证码识别(少样本,高精度)项目地址:https://github.com/kerlomz/captcha_trainer 1. 前言 本项目适用于Python3.6,GPU>=NVIDIA G ...
- C++学习45 流成员函数put输出单个字符 cin输入流详解 get()函数读入一个字符
在程序中一般用cout和插入运算符“<<”实现输出,cout流在内存中有相应的缓冲区.有时用户还有特殊的输出要求,例如只输出一个字符.ostream类除了提供上面介绍过的用于格式控制的成员 ...
- opencv ,亮度调整【【OpenCV入门教程之六】 创建Trackbar & 图像对比度、亮度值调整
http://blog.csdn.net/poem_qianmo/article/details/21479533 [OpenCV入门教程之六] 创建Trackbar & 图像对比度.亮度值调 ...
- php随机获取验证码
<?php $yzm = ""; for($i=0;$i<5;$i++) { $a = rand(0,9); //0-9随机数 $yzm.= $a; } echo jo ...
- android发送短信验证码并自动获取验证码填充文本框
android注册发送短信验证码并自动获取短信,截取数字验证码填充文本框. 一.接入短信平台 首先需要选择短信平台接入,这里使用的是榛子云短信平台(http://smsow.zhenzikj.com) ...
随机推荐
- 安装完Ubuntu后通过shell脚本一键安装软件
安装完Ubuntu后通过shell脚本一键安装软件 以下代码中#是单行注释 :<<! ! 是多行注释. 运行的时候需要把多行注释去掉. 比如把以下代码保存为install.sh, 那么在终 ...
- 把dotx模板的样式应用到当前文档中(不应用dotx的其他东西)
Word.Document doc = this.Application.ActiveDocument; //模板样式添加到当前文档 doc.CopyStylesFromTemplate(@" ...
- 个人对于angularjs依赖注入的理解
依赖注入(Dependency Injection,DI),作者认为本文中所有名词性的"依赖" 都可以理解为 "需要使用的资源". 对象或者函数只有以下3种获取 ...
- 我的C#跨平台之旅(二):开发最为简单的REST API
添加NuGet引用:Microsoft.AspNet.WebApi.Owin 在启动类启用WebApi: 添加一个Controller类,代码如下: 运行程序并访问:http://localhost: ...
- php Glob() 使用 查找文件:
1. 取得所有的后缀为PHP的文件(加上路径)$file=glob('D:/phpStudy/WWW/prictue/*.php');print_r($file);//如果没有指定文件夹的话就是显示出 ...
- Python之旅Day8 socket网络编程
socket网络编程 Socket是网络编程的一个抽象概念.通常我们用一个Socket表示“打开了一个网络链接”,而打开一个Socket需要知道目标计算机的IP地址和端口号,再指定协议类型即可.soc ...
- day_9内存管理
复习 '''文件处理1.操作文件的三步骤 -- 打开文件:硬盘的空间被操作系统持有 | 文件对象被应用程序持续 -- 操作文件:读写操作 -- 释放文件:释放操作系统对硬盘空间的持有 2.基础的读写 ...
- CSS常见布局问题整理
实现div的水平居中和垂直居中 多元素水平居中 实现栅格化布局 1. 实现div的水平居中和垂直居中 实现效果: 这大概是最经典的一个题目了,所以放在第一个. 方法有好多, 一一列来 主要思路其实就是 ...
- 【mysql注入】mysql注入点的技巧整合利用
[mysql注入]mysql注入点的技巧整合利用 本文转自:i春秋社区 前言: 渗透测试所遇的情况瞬息万变,以不变应万变无谓是经验与技巧的整合 简介: 如下 mysql注入点如果权限较高的话,再知道w ...
- 7.首页、bitmaputils
HomeProtocol public class HomeProtocol extends BaseProtocol<List<AppInfo>>{ // 1 把整个json ...