(转)如何用TensorLayer做目标检测的数据增强
数据增强在机器学习中的作用不言而喻。和图片分类的数据增强不同,训练目标检测模型的数据增强在对图像做处理时,还需要对图片中每个目标的坐标做相应的处理。此外,位移、裁剪等操作还有可能使得一些目标在处理后只有一小部分区域保留在原图中,这需要额外的机制来判断是否需要去掉该目标来训练模型。为此TensorLayer 1.7.0(tf>=1.4 && tl>=1.7)发布中,提供了大量关于目标检测任务的数据集下载、目标坐标处理、数据增强的API。最近的几次发布主要面向新的卷积方式(Deformable Convolution, Depthwise ...),优化Subpixel Convolution以及提供新的递归方式(ConvLSTM)等。
首先,我们下载VOC2012数据集并对类别和坐标做预处理。tl.files.load_voc_dataset函数自动下载数据集,其返回的坐标格式和Darknet一样,则[x_c, y_c, w,h],其中x_c和y_c代表一个目标的中心在图片上的位置,w和h代表该目标的宽度和高度,这4个值是其和原图高度和宽度的比例,所以这4个值的范围在0~1之间。
- import tensorlayer as tl
- ## 下载 VOC 2012 数据集
- imgs_file_list, _, _, _, classes, _, _,\
- _, objs_info_list, _ = tl.files.load_voc_dataset(dataset="")
- ## 图片标记预处理为列表形式
- ann_list = []
- for info in objs_info_list:
- ann = tl.prepro.parse_darknet_ann_str_to_list(info)
- c, b = tl.prepro.parse_darknet_ann_list_to_cls_box(ann)
- ann_list.append([c, b])
单张图片处理
我们先对一张图片做处理,以观察tl.prepro工具箱中各个API的效果。这里我们保存2号图片的原图,以供后面做比较。
- # 读取一张图片,并保存
- idx = 2 # 可自行选择图片
- image = tl.vis.read_image(imgs_file_list[idx])
- tl.vis.draw_boxes_and_labels_to_image(image, ann_list[idx][0],
- ann_list[idx][1], [], classes, True, save_name='_im_original.png')

- # 左右翻转
- im_flip, coords = tl.prepro.obj_box_left_right_flip(image,
- ann_list[idx][1], is_rescale=True, is_center=True, is_random=False)
- tl.vis.draw_boxes_and_labels_to_image(im_flip, ann_list[idx][0],
- coords, [], classes, True, save_name='_im_flip.png')

- # 位移
- im_shfit, clas, coords = tl.prepro.obj_box_shift(image, ann_list[idx][0],
- ann_list[idx][1], wrg=0.1, hrg=0.1,
- is_rescale=True, is_center=True, is_random=False)
- tl.vis.draw_boxes_and_labels_to_image(im_shfit, clas, coords, [],
- classes, True, save_name='_im_shift.png')
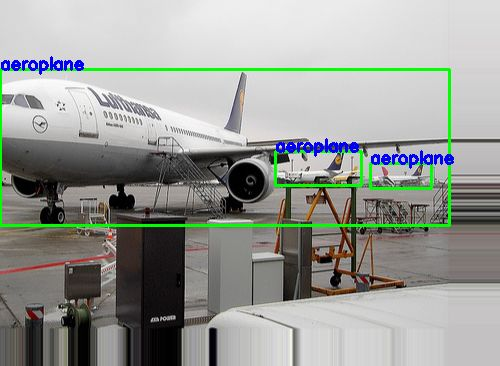
- # 高宽缩放
- im_zoom, clas, coords = tl.prepro.obj_box_zoom(image, ann_list[idx][0],
- ann_list[idx][1], zoom_range=(1.3, 0.7),
- is_rescale=True, is_center=True, is_random=False)
- tl.vis.draw_boxes_and_labels_to_image(im_zoom, clas, coords, [],
- classes, True, save_name='_im_zoom.png')

从缩放的图片中,我们可以看到一架飞机由于大部分区域被移到图像之外了,只剩下机头的一小部分,所以这个目标被去除了。tl.prepro工具箱中关于目标检测的API往往有thresh_wh和thresh_wh2两个阀值,thresh_wh表示在处理图像之后,若一个目标的宽或高和图片本身宽高的比例小于这个值,则去除该目标;thresh_wh2表示在处理图像之后,若一个目标的宽高或高宽比例小于这个值,则去除该目标。大家可以根据特定开发任务来设置这两个值,作者建议在常规情况下使用默认值。
- # 调整图片大小
- im_resize, coords = tl.prepro.obj_box_imresize(image,
- coords=ann_list[idx][1], size=[300, 200], is_rescale=True)
- tl.vis.draw_boxes_and_labels_to_image(im_resize, ann_list[idx][0],
- coords, [], classes, True, save_name='_im_resize.png')

多线程处理
实际训练模型时,我们可能会使用多线程方法来对一个batch的图片做随机的数据增强。这时,tl.prepro工具箱的API中is_random全部设为True。
- import tensorlayer as tl
- import random
- batch_size = 64
- im_size = [416, 416] # 输出图的大小
- n_data = len(imgs_file_list)
- jitter = 0.2
- def _data_pre_aug_fn(data):
- im, ann = data
- clas, coords = ann
- ## 随机改变图片亮度、对比度和饱和度
- im = tl.prepro.illumination(im, gamma=(0.5, 1.5),
- contrast=(0.5, 1.5), saturation=(0.5, 1.5), is_random=True)
- ## 随机左右翻转
- im, coords = tl.prepro.obj_box_left_right_flip(im, coords,
- is_rescale=True, is_center=True, is_random=True)
- ## 随机调整大小并裁剪出指定大小的图片,这同时达到了随机缩放的效果
- tmp0 = random.randint(1, int(im_size[0]*jitter))
- tmp1 = random.randint(1, int(im_size[1]*jitter))
- im, coords = tl.prepro.obj_box_imresize(im, coords,
- [im_size[0]+tmp0, im_size[1]+tmp1], is_rescale=True,
- interp='bicubic')
- im, clas, coords = tl.prepro.obj_box_crop(im, clas, coords,
- wrg=im_size[1], hrg=im_size[0], is_rescale=True,
- is_center=True, is_random=True)
- ## 把数值范围从 [0, 255] 转到 [-1, 1] (可选)
- im = im / 127.5 - 1
- return im, [clas, coords]
- # 随机读取一个batch的图片及其标记
- idexs = tl.utils.get_random_int(min=0, max=n_data-1, number=batch_size)
- b_im_path = [imgs_file_list[i] for i in idexs]
- b_images = tl.prepro.threading_data(b_im_path, fn=tl.vis.read_image)
- b_ann = [ann_list[i] for i in idexs]
- # 多线程处理
- data = tl.prepro.threading_data([_ for _ in zip(b_images, b_ann)],
- _data_pre_aug_fn)
- b_images2 = [d[0] for d in data]
- b_ann = [d[1] for d in data]
- # 保存每一组图片以供体会
- for i in range(len(b_images)):
- tl.vis.draw_boxes_and_labels_to_image(b_images[i],
- ann_list[idexs[i]][0], ann_list[idexs[i]][1], [],
- classes, True, save_name='_bbox_vis_%d_original.png' % i)
- tl.vis.draw_boxes_and_labels_to_image((b_images2[i]+1)*127.5,
- b_ann[i][0], b_ann[i][1], [], classes, True,
- save_name='_bbox_vis_%d.png' % i)
最后,我们得到64组处理前和处理后的图片,下面列出2组图片以供参考。
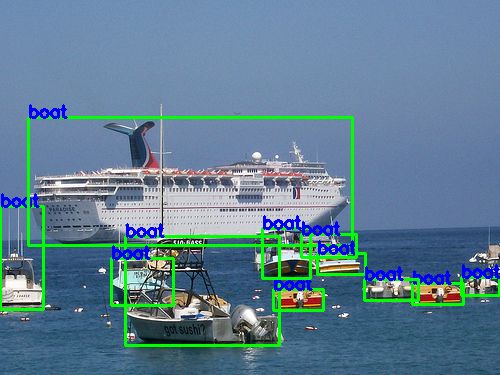

原图 随机处理后


原图 随机处理后
处理逻辑
这就完了吗?大家认真思考一下上面的 _data_pre_aug_fn 函数做数据增强有什么潜在缺点?假设我们的训练图像高宽非常不确定的话,比如有的图是300x1000而有的图是1000x300,上面的函数一上来就把图片resize到一个正方形,会导致很多形状高宽信息丢失!
当我们的数据集存在高宽比例多样性很大时,我们需要另外的机制来解决这个问题。下面的函数中,我们的resize会根据原图高宽来决定,我们把原图最小的那个边resize成最终尺寸对应需要的大小,同时另外一个边以同比例resize(比如,如果原图高比宽小,则把高resize成最终需要的高,同时宽以相同比例resize)。做完这一步之后,我们再对其进行随机左右翻转,缩放等操作,最终裁剪出我们需要的尺寸的图。
- def _data_aug_fn(self, data, jitter):
- im, ann = data
- clas, coords = ann
- ## resize到高宽合适的大小
- scale = np.max((self.im_size[1] / float(im.shape[1]),
- self.im_size[0] / float(im.shape[0])))
- im, coords = tl.prepro.obj_box_imresize(im, coords,
- [int(im.shape[0]*scale)+2, int(im.shape[1]*scale)+2],
- is_rescale=True, interp='bicubic')
- ## 几何增强 geometric transformation
- im, coords = tl.prepro.obj_box_left_right_flip(im,
- coords, is_rescale=True, is_center=True, is_random=True)
- im, clas, coords = tl.prepro.obj_box_shift(im, clas,
- coords, wrg=0.1, hrg=0.1, is_rescale=True,
- is_center=True, is_random=True)
- im, clas, coords = tl.prepro.obj_box_zoom(im, clas,
- coords, zoom_range=(1-jitter, 1+jitter),
- is_rescale=True, is_center=True, is_random=True)
- im, clas, coords = tl.prepro.obj_box_crop(im, clas, coords,
- wrg=self.im_size[1], hrg=self.im_size[0],
- is_rescale=True, is_center=True, is_random=True)
- ## 光度增强 photometric transformation
- im = tl.prepro.illumination(im, gamma=(0.5, 1.5),
- contrast=(0.5, 1.5), saturation=(0.5, 1.5), is_random=True)
- im = tl.prepro.adjust_hue(im, hout=0.1, is_offset=True,
- is_clip=True, is_random=True)
- im = tl.prepro.pixel_value_scale(im, 0.1, [0, 255], is_random=True)
- ## 把数值范围从 [0, 255] 转到 [-1, 1] (可选)
- im = im / 127.5 - 1.
- im = np.clip(im, -1., 1.)
- return im, [clas, coords]


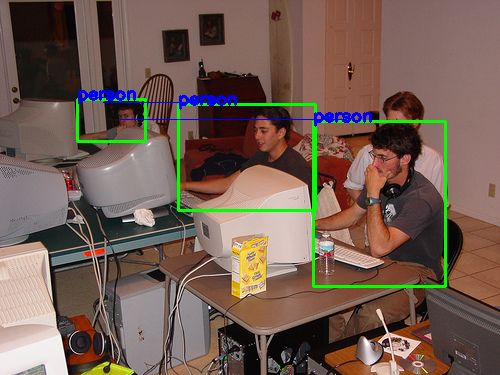
原图 随机处理后


原图 随机处理后

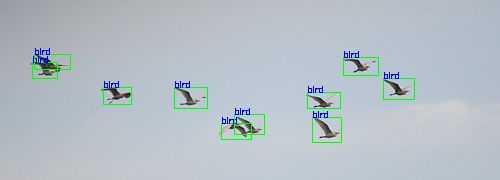
原图 随机处理后
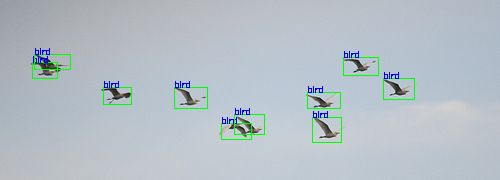
处理前 随机处理后
更新
新版本的TensorFlow发布了dataset API,自带threading功能,大家可以到下面链接获取代码。
TensorLayer结合Dataset API生成VOCgithub.com
结束语
对于产业界的朋友来说,数据增强的逻辑和业务本身是非常相关的,我们需要对不同的数据集写不同的增强代码,合理的增强逻辑往往会在相同的算法上大大提高准确性。各位还可以仔细思考一下crop和shift, zoom之间的先后问题会对图片有什么影响。TensorLayer把每一种增强行为都独立开来,以便大家完全可控地实现自己的增强算法逻辑。
转自:知乎(如何用TensorLayer做目标检测的数据增强)
附:tensorlayer目标检测数据增强文档
(转)如何用TensorLayer做目标检测的数据增强的更多相关文章
- 使用Faster R-CNN做目标检测 - 学习luminoth代码
像玩乐高一样拆解Faster R-CNN:详解目标检测的实现过程 https://mp.weixin.qq.com/s/M_i38L2brq69BYzmaPeJ9w 直接参考开源目标检测代码lumin ...
- caffe-ssd使用预训练模型做目标检测
首先参考https://www.jianshu.com/p/4eaedaeafcb4 这是一个傻瓜似的目标检测样例,目前还不清楚图片怎么转换,怎么验证,后续继续跟进 模型测试(1)图片数据集上测试 p ...
- 第三十二节,使用谷歌Object Detection API进行目标检测、训练新的模型(使用VOC 2012数据集)
前面已经介绍了几种经典的目标检测算法,光学习理论不实践的效果并不大,这里我们使用谷歌的开源框架来实现目标检测.至于为什么不去自己实现呢?主要是因为自己实现比较麻烦,而且调参比较麻烦,我们直接利用别人的 ...
- #Deep Learning回顾#之基于深度学习的目标检测(阅读小结)
原文链接:https://www.52ml.net/20287.html 这篇博文主要讲了深度学习在目标检测中的发展. 博文首先介绍了传统的目标检测算法过程: 传统的目标检测一般使用滑动窗口的框架,主 ...
- 目标检测--Rich feature hierarchies for accurate object detection and semantic segmentation(CVPR 2014)
Rich feature hierarchies for accurate object detection and semantic segmentation 作者: Ross Girshick J ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- caffe SSD目标检测lmdb数据格式制作
一.任务 现在用caffe做目标检测一般需要lmdb格式的数据,而目标检测的数据和目标分类的lmdb格式的制作难度不同.就目标检测来说,例如准备SSD需要的数据,一般需要以下几步: 1.准备图片并标注 ...
- [目标检测]SSD原理
1 SSD基础原理 1.1 SSD网络结构 SSD使用VGG-16-Atrous作为基础网络,其中黄色部分为在VGG-16基础网络上填加的特征提取层.SSD与yolo不同之处是除了在最终特征图上做目标 ...
- 多目标检测分类 RCNN到Mask R-CNN
最近做目标检测需要用到Mask R-CNN,之前研究过CNN,R-CNN:通过论文的阅读以及下边三篇博客大概弄懂了Mask R-CNN神经网络.想要改进还得努力啊... 目标检测的经典网络结构,顺序大 ...
随机推荐
- 原生js操作Dom命令总结
常用的dom方法 document.getElementById(“box”);//通过id获取标签 document.getElementsByTagName(“div”);根据标签名获取页面 ...
- go goroutine
进程和线程 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的 一个独立单位. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更 小的能独立运行的基本单位. 一个进程可 ...
- eclipse_maven换源
1. 手动新增一个xml文件: <?xml version="1.0" encoding="UTF-8"?> <settings xmlns= ...
- VirtualBox虚拟机中安装XP系统
Windows XP是一款经典的操作系统,同时也是一款很老的操作系统,不过尽管如此,还是有一批用户在使用XP系统,所以发行一些软件的时候还是要测试在XP系统中能否运行,这时候我们就可以借助Virtua ...
- shop++改造之Filter类
基于shop++源码进行商城改造.本来想大展手脚,结果一入手.发觉瞬间淹没了我的才华,sql语句也得贼溜没啥用. 不得不说这个商城源码价值很高,封装的很精屁. 下面是我第一天入手的坑. 数据库建好了表 ...
- HDU 6433(2的n次方 **)
题意是就是求出 2 的 n 次方. 直接求肯定不行,直接将每一位存在一个数组的各个位置即可,这里先解出 2 的 n 次方的位数,再直接模拟每一位乘以 2 即可得到答案. 求解 2 的 n 次方的位数的 ...
- Fetch诞生记
Fetch作用? https://developer.mozilla.org/zh-CN/docs/Web/API/Fetch_API/Using_Fetch Fetch API 提供了一个 Jav ...
- ads出现村田电容电感无法仿真的问题解决(`BJT1' is an instance of an undefined model `BJTM1')
需要的控件是 murata include,该控件是跟随村田库一起倒入ADS中的
- tab选项卡在鼠标经过时实现切换延迟
偶然间在浏览网页时,发现这样的效果.当鼠标不经意间滑过tab时并不会切换,当鼠标停留在上面一段时候后才会切换. 个人觉得用户体验不错,优点是1.当用户只是滑过标签,并不需要切换,而此时如果切换标签需要 ...
- 第27月第12天 webrtc ios openssl boost
1. source 'https://github.com/CocoaPods/Specs.git' target 'YOUR_APPLICATION_TARGET_NAME_HERE' do pla ...