数据结构与STL容器
一、
1、线性表
线性表包括顺序存储结构(用一段连续地址存储)和链式存储结构(数据域+指针域)。顺序存储结构的代表是C/C++中的数组,其读时间复杂度为O(1),插入/删除为O(n),因为从插入/删除位置到最后一个元素都要向前/后移动一个位置。链式存储结构包括单链表(普通链表)、循环链表、双向链表等,单链表的读取为O(n),插入/删除O(n)——不清楚第i个元素指针位置时,但是已知时为O(1),代表为list容器。
2、栈
属于特殊的线性表,它一种先进后出的数据结构,代表为STL的stack。
3、队列
属于特殊的线性表,它一种先进先出的数据结构,代表为queue。
4、树
分为二叉树和多叉树(N叉树),map和set内部使用红黑树结构,在最坏的情况下查找、插入和删除仅消耗对数时间log(n)。
5、哈希表
STL中的unorder_map和unorder_set使用的就是hash table结构,查找、插入和删除消耗为常数级别O(1)。
二、
1、静态数组
静态数组就是大小固定不能扩展的数组,如C中普通数组、C++11中array。
2、动态数组
动态数组的空间大小在需要的时候可以进行再分配,其代表为vector。由于数组的特点,在位置0插入需要将整个数组后移一个位置来腾出空间,删除位置0的元素则需要将剩余元素前移一个位置,这两种最坏的情况为O(n)。所以vector只适合在末尾添加或删除元素,使用[]或迭代器随机访问是快速的。
deque可以可以看作是vector的增强版,它增加了在头部快速插入和删除元素。
3、链表
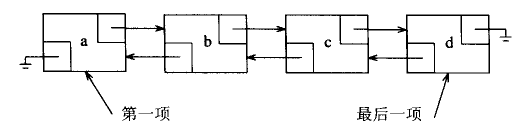
链表由一系列不必在内存中相连的结点组成,每个结点包含了结点元素和到后继结点的链。链表避免了插入和删除的线性开销,但随机访问效率很低。使用链表结构的代表是list容器,而且list是基于双向链表实现的。下图是普通链表与双向链表的示意图:

4、栈
栈的特点是后进先出,位于栈顶的元素是唯一可见的元素。栈可以使用链表来实现,通过在链表顶端插入元素来实现push,通过删除链表顶端元素来实现pop,top操作返回顶端元素。c++中栈数据结构的实现是容器适配器stack,stack其所关联的基础容器可以为vector、list、deque,默认为deque。

5、队列
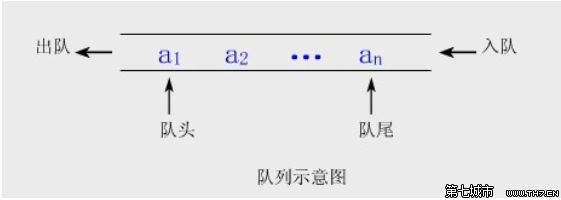
队列的特点是先进先出,队列也可以使用链表来实现,enqueue(入队)是在链表的末端插入一个元素,dequeue(出队)是删除并返回链表开头的元素。c++中队列数据结构的实现是容器适配器queue,其所关联的基础容器可以为list或deque,默认为deque。
6、链表的创建和操作
typedef struct node
{
int iIndex;
struct node* pNext;
}Node, *NodePtr; //创建链表
NodePtr CreateList(unsigned iLen)
{
NodePtr pHeadNode = NULL, pLastNode = NULL;
for (unsigned i = ; i < iLen; i++)
{
NodePtr pNode = new Node;
pNode->iIndex = i;
if (pLastNode)
pLastNode->pNext = pNode;
else
pHeadNode = pNode; pLastNode = pNode;
}
pLastNode->pNext = NULL; return pHeadNode;
} //输出链表
void PrintList(NodePtr pHeadNode)
{
NodePtr pNode = pHeadNode;
do
{
cout << pNode->iIndex << ", ";
pNode = pNode->pNext;
} while (pNode); cout << endl;
} //链表排序:利用选择排序法思想
void SelectSortList(NodePtr pHeadNode)
{
NodePtr pNode = pHeadNode;
while (pNode->pNext)
{
NodePtr pNodeMin = pNode;
NodePtr pNodeNext = pNode->pNext;
while (pNodeNext)
{
if (pNodeNext->iIndex < pNodeMin->iIndex)
pNodeMin = pNodeNext; pNodeNext = pNodeNext->pNext;
} if (pNodeMin != pNode)
swap(&pNode->iIndex, &pNodeMin->iIndex); pNode = pNode->pNext;
}
} //合并两个有序链表为一个
NodePtr UnionList(NodePtr pHeadNode1, NodePtr pHeadNode2)
{
NodePtr pHeadNode = new Node;//新的链表添加一个头结点
NodePtr pNode1 = pHeadNode1, pNode2 = pHeadNode2, pNode = pHeadNode; while (pNode1 && pNode2)
{
if (pNode1->iIndex <= pNode2->iIndex)
{
pNode->pNext = pNode1;
pNode = pNode->pNext;
pNode1 = pNode1->pNext;
}
else
{
pNode->pNext = pNode2;
pNode = pNode->pNext;
pNode2 = pNode2->pNext;
}
} pNode->pNext = pNode1 ? pNode1 : pNode2;//插入剩余段 NodePtr pReturnNode = pHeadNode->pNext;
delete pHeadNode;//删除新链表的头结点
return pReturnNode;
} //链表逆序:定义三个节点指针分别指向前三个节点,第二个节点的pNext重新指向第一个节点,三个节点指针再往后移动,如此往复
NodePtr TurnList(NodePtr pHeadNode)
{
if (pHeadNode->pNext)
{
NodePtr pLastNode = pHeadNode;
NodePtr pNode = pLastNode->pNext;
NodePtr pNextNode = pNode->pNext; while (pNextNode)
{
pNode->pNext = pLastNode; pLastNode = pNode;
pNode = pNextNode;
pNextNode = pNextNode->pNext;
} pNode->pNext = pLastNode;
pHeadNode->pNext = NULL; return pNode;
}
else
return pHeadNode;
}
三、
1、顺序容器:
vector为向量容器,支持使用下标来快速随机访问(所以提供了[]和at()访问元素的方法,迭代器支持++、--、+=、-=算数操作),支持在尾部快速插入、删除元素,不支持在头部或中间快速插入数据(因为这样会导致重新分配整个内存)。
list为链表容器,支持在容器头、尾、内部快速插入、删除元素(插入、删除不会重新分配内存),不支持快速随机访问(不提供[]或at()来访问元素,仅提供迭代器的++、--算数操作,使用find()查找元素会很慢)。
虽然list的迭代器不提供+、-、+=、-=操作,但其实可以通过advance、next/prev方法来实现这些操作,但是通过这些方法获得的list的迭代器进行distance操作的话会出错,所以如果要对list进行advance、next等操作的话应该想一想使用的容器是不是改成vector更合适:
std::list<int> myList = {, , , , };
auto it = myList.begin();
std::advance(it, ); //advance移动当前迭代器
int n = *it; //
auto it2 = std::next(myList.begin(), ); //next/prev获得迭代器之后/之前的迭代器,不改变当前迭代器
n = *it2; //
n = std::distance(myList.begin(), myList.end()); //5,distance获得迭代器之间的距离
n = std::distance(it, it2); //error
queue队列,适合队尾插入元素,队头删除元素的情况,它是容器适配器,其所关联的基础容器可以为list或deque,默认为deque。
deque为双端队列,它可以看作是queue的增强版,其支持在头部和尾部快速插入和删除元素。
priority_queue为优先级队列,允许设置元素的优先级,将新的元素放置在比它优先级低的元素前面,要求提供随机访问的功能,所以其所关联的基础容器可以为vector、deque,默认基础容器为vector
stack栈,适合后进先出的情况,它是容器适配器,其所关联的基础容器可以为vector、list、deque,默认为deque
2、关联容器
map、unordered_map、multimap为映射容器,支持通过键来快速查找和读取元素,其元素为键-值对的形式,键相当于元素的索引,值为元素所存储的数据。当使用下标[]来引用映射容器内元素的时候如果当前容器内没有该键则会自动创建该键值对。map元素是排序的,multimap支持同一个键多次出现。
set、multiset为集合容器,其元素仅包含一个键,有效的支持某个键是否存在的查询。set中元素是排序的,multiset支持同一个键多次出现。
3、vector等容器对于元素的要求是可复制和可赋值,map容器的key还需要支持<比较操作,所以如果把自定义类型作为map的key的话需要重载<,如:
struct Data
{
int i;
bool operator<(const Data& d)const
{
return i < d.i;
}
};
数据结构与STL容器的更多相关文章
- STL容器底层数据结构的实现
C++ STL 的实现: 1.vector 底层数据结构为数组 ,支持快速随机访问 2.list 底层数据结构为双向链表,支持快速增删 3.deque ...
- STL容器的本质
http://blog.sina.com.cn/s/blog_4d3a41f40100eof0.html 最近在学习unordered_map里面的散列函数和相等函数怎么写.学习过程中看到了一个好帖子 ...
- STL容器是否是线程安全的
转载http://blog.csdn.net/zdl1016/article/details/5941330 STL的线程安全. 说一些关于stl容器的线程安全相关的话题. 一般说来,stl对于多线程 ...
- STL容器总结
一. 种类: 标准STL序列容器:vector.string.deque和list. 标准STL关联容器:set.multiset.map和multimap. 非标准序列容器slist和rope.sl ...
- STL容器之优先队列(转)
STL容器之优先队列 原地址:http://www.cnblogs.com/summerRQ/articles/2470130.html 优先级队列,以前刷题的时候用的比较熟,现在竟然我只能记得它的关 ...
- STL容器之优先队列
STL容器之优先队列 优先级队列,以前刷题的时候用的比较熟,现在竟然我只能记得它的关键字是priority_queue(太伤了).在一些定义了权重的地方这个数据结构是很有用的. 先回顾队列的定义:队列 ...
- 关于STL容器
容器: 概念:如果把数据看做物体,容器就是放置这些物体的器物,因为其内部结构不同,数据摆放的方式不同,取用的方式也不同,我们把他们抽象成不同的模板类,使用时去实例化它 分类: 序列容器.关联容器.容器 ...
- STL 容器简介
一.概述 STL 对定义的通用容器分三类:顺序性容器.关联式容器和容器适配器. 顺序性容器是一种各元素之间有顺序关系的线性表.元素在顺序容器中保存元素置入容器时的逻辑顺序,除非用删除或插入的操作改变这 ...
- STL 容器的概念
STL 容器的概念 在实际的开发过程中,数据结构本身的重要性不会逊于操作于数据结构的算法的重要性,当程序中存在着对时间要求很高的部分时,数据结构的选择就显得更加重要. 经典的数据结构数量有限,但是我们 ...
随机推荐
- 四百万条数据创建简单索引报错ora01652
经过几次度娘之后终于找到了解决方案,因为当时创建的indextest表是属于系统表空间,而系统表空间默认好像有大小限制,所以需要修改系统表空间的大小,至于修改表空间的语句可以随时度娘. 经过修改,创建 ...
- 云笔记项目-Spring事务学习-传播REQUIRES_NEW
接下来测试事务传播的REQUIRES_NEW. Service层 Service层代码在这里不展示了,主要将EMPService1Impl类中的方法事务传播属性设置为REQUIRED,EMPServi ...
- gson 入门使用
参考文章:https://www.cnblogs.com/majay/p/6336918.html Java 对象与 Json 之间的互相转换,用的比较多大是 Jackson 与 Gson 第一步:添 ...
- SpringCloud Zuul网关超时
最近在使用SpringCloudZuul网关时,报错"NUMBEROF_RETRIES_NEXTSERVER_EXCEEDED", 查询资料后,发现: ribbon.Connect ...
- Mac 安装 mongoDB
因Homebrew被墙, 这里使用压缩包安装. 一 从官网下载压缩包 二 解压缩 cd ~/Downloads/ tar -zxvf mongodb-osx-ssl-x86_64-4.0.8.tgz ...
- 20175234 2018-2019-2 《Java程序设计》第九周学习总结
目录 20175234 2018-2019-2 <Java程序设计>第九周学习总结 教材学习内容总结 教材学习中的问题和解决过程 代码托管 感想 学习进度条 参考资料 20175234 2 ...
- Tableau可视化绘图教程
https://www.w3cschool.cn/tableau/tableau_environment_setup.html
- 7K - find your present (2)
In the new year party, everybody will get a "special present".Now it's your turn to get yo ...
- 7B - 今年暑假不AC
“今年暑假不AC?” “是的.” “那你干什么呢?” “看世界杯呀,笨蛋!” “@#$%^&*%...” 确实如此,世界杯来了,球迷的节日也来了,估计很多ACMer也会抛开电脑,奔向电视了. ...
- linux下编译protobuf(可以编译成pb.go)
编译前需要安装gtest $ cd googletest $ cmake -DBUILD_SHARED_LIBS=ON . $ make $ sudo cp -a include/gtest /hom ...