java面试总结(资料来源网络)
core java:
一、集合
1、hashMap
结构如图:
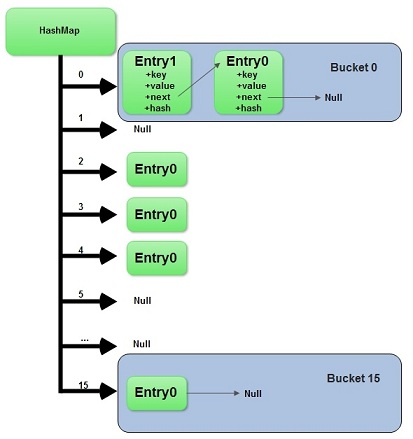
HashMap在Map.Entry静态内部类实现中存储key-value对。
HashMap使用哈希算法。在put和get方法中。它使用hashCode()和equals()方法。当我们通过传递key-value对调用put方法的时候。HashMap使用Key hashCode()和哈希算法来找出存储key-value对的索引。
Entry存储在LinkedList中,所以假设存在entry。它使用equals()方法来检查传递的key是否已经存在。假设存在,它会覆盖value。假设不存在。它会创建一个新的entry然后保存。
当我们通过传递key调用get方法时,它再次使用hashCode()来找到数组中的索引,然后使用equals()方法找出正确的Entry,然后返回它的值。下面的图片解释了详细内容。
其他关于HashMap比較重要的问题是容量、负荷系数和阀值调整。HashMap默认的初始容量是32,负荷系数是0.75。
阀值是为负荷系数乘以容量,不管何时我们尝试加入一个entry,假设map的大小比阀值大的时候,HashMap会对map的内容进行又一次哈希。且使用更大的容量。容量总是2的幂。所以假设你知道你须要存储大量的key-value对,比方缓存从数据库里面拉取的数据,使用正确的容量和负荷系数对HashMap进行初始化是个不错的做法。
equals()和hashCode()的实现应该遵循下面规则:
(1)假设o1.equals(o2),那么o1.hashCode() == o2.hashCode()总是为true的。
(2)假设o1.hashCode() == o2.hashCode()。并不意味着o1.equals(o2)会为true。
2、HashMap、HashTable、SynchronizedMap、ConcurrentHashMap
(1)HashMap同意key和value为null。而HashTable不同意。
(2)HashTable是同步的,而HashMap不是。所以HashMap适合单线程环境,HashTable适合多线程环境。
(3)在Java1.4中引入了LinkedHashMap,HashMap的一个子类,假如你想要遍历顺序,你非常easy从HashMap转向LinkedHashMap,可是HashTable不是这种。它的顺序是不可预知的。
(4)HashMap提供对key的Set进行遍历。因此它是fail-fast的。但HashTable提供对key的Enumeration进行遍历,它不支持fail-fast。
(5)HashTable被觉得是个遗留的类。假设你寻求在迭代的时候改动Map,你应该使用CocurrentHashMap。
(6)HashMap不是线程安全的;Hashtable线程安全,但效率低,因为是Hashtable是使用synchronized的,所有线程竞争同一把锁;SynchronizedMap线程安全,其实是保持外部同步来实现的,效率也很低;而ConcurrentHashMap不仅线程安全而且效率高,因为它包含一个segment数组,将数据分段存储,给每一段数据配一把锁,也就是所谓的锁分段技术。
Synchronized Map
ConcurrentHashMap
---------------------
作者:huaxun66
来源:CSDN
原文:https://blog.csdn.net/huaxun66/article/details/53036625
版权声明:本文为博主原创文章,转载请附上博文链接!
3、HashMap和TreeMap
对于在Map中插入、删除和定位元素这类操作,HashMap是最好的选择。然而。假如你须要对一个有序的key集合进行遍历,TreeMap是更好的选择。基于你的collection的大小,或许向HashMap中加入元素会更快。将map换为TreeMap进行有序key的遍历。
4、ArrayList和LinkedList
(1)ArrayList是由Array所支持的基于一个索引的数据结构,所以它提供对元素的随机訪问。复杂度为O(1),但LinkedList存储一系列的节点数据。每一个节点都与前一个和下一个节点相连接。所以。虽然有使用索引获取元素的方法,内部实现是从起始点開始遍历,遍历到索引的节点然后返回元素。时间复杂度为O(n)。比ArrayList要慢。
(2)与ArrayList相比,在LinkedList中插入、加入和删除一个元素会更快。由于在一个元素被插入到中间的时候,不会涉及改变数组的大小,或更新索引。
(3)LinkedList比ArrayList消耗很多其他的内存,由于LinkedList中的每一个节点存储了前后节点的引用。
二、JVM
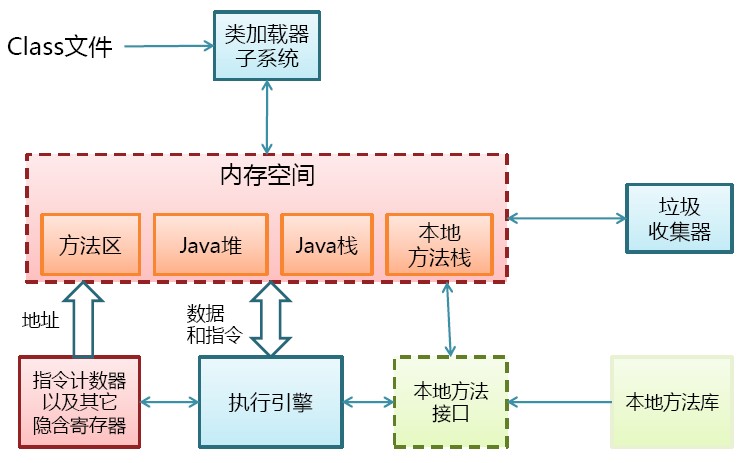
1、JVM物理结构:
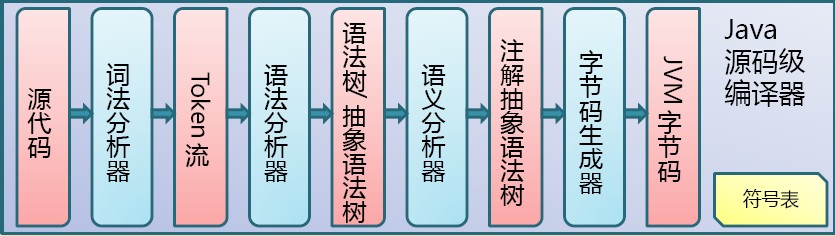
Java代码编译是由Java源码编译器来完成,流程图如下所示:
Java字节码的执行是由JVM执行引擎来完成,流程图如下所示:

类加载机制:
2、内存管理
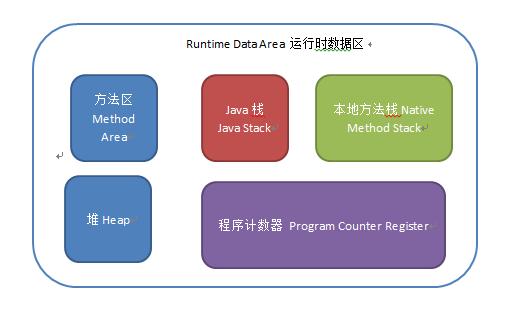
(1)堆
所有通过new创建的对象的内存都在堆中分配,堆的大小可以通过-Xmx和-Xms来控制。堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区,最后Survivor由From Space和To Space组成,结构图如下所示:

新生代。新建的对象都是用新生代分配内存,Eden空间不足的时候,会把存活的对象转移到Survivor中,新生代大小可以由-Xmn来控制,也可以用-XX:SurvivorRatio来控制Eden和Survivor的比例
旧生代。用于存放新生代中经过多次垃圾回收仍然存活的对象
持久带(Permanent Space)实现方法区,主要存放所有已加载的类信息,方法信息,常量池等等。可通过-XX:PermSize和-XX:MaxPermSize来指定持久带初始化值和最大值。Permanent Space并不等同于方法区,只不过是Hotspot JVM用Permanent Space来实现方法区而已,有些虚拟机没有Permanent Space而用其他机制来实现方法区。

-Xmx:最大堆内存,如:-Xmx512m
-Xms:初始时堆内存,如:-Xms256m
-XX:MaxNewSize:最大年轻区内存
-XX:NewSize:初始时年轻区内存.通常为 Xmx 的 1/3 或 1/4。新生代 = Eden + 2 个 Survivor 空间。实际可用空间为 = Eden + 1 个 Survivor,即 90%
-XX:MaxPermSize:最大持久带内存
-XX:PermSize:初始时持久带内存
-XX:+PrintGCDetails。打印 GC 信息
-XX:NewRatio 新生代与老年代的比例,如 –XX:NewRatio=2,则新生代占整个堆空间的1/3,老年代占2/3
-XX:SurvivorRatio 新生代中 Eden 与 Survivor 的比值。默认值为 8。即 Eden 占新生代空间的 8/10,另外两个 Survivor 各占 1/10
堆是JVM所管理的内存中国最大的一块,是被所有Java线程锁共享的,不是线程安全的,在JVM启动时创建。
(2)栈
每个线程执行每个方法的时候都会在栈中申请一个栈帧,每个栈帧包括局部变量区和操作数栈,用于存放此次方法调用过程中的临时变量、参数和中间结果。
-xss:设置每个线程的堆栈大小. JDK1.5+ 每个线程堆栈大小为 1M,一般来说如果栈不是很深的话, 1M 是绝对够用了的。
由于Java栈是与线程对应起来的,Java栈数据不是线程共有的,所以不需要关心其数据一致性,也不会存在同步锁的问题。
(3)本地方法栈
用于支持native方法的执行,存储了每个native方法调用的状态
(4)方法区
存放了要加载的类信息、静态变量、final类型的常量、属性和方法信息。JVM用持久代(Permanet Generation)来存放方法区,可通过-XX:PermSize和-XX:MaxPermSize来指定最小值和最大值,方法区是被Java线程锁共享的
(5)程序计数器
严格来说是一个数据结构,用于保存当前正在执行的程序的内存地址,由于Java是支持多线程执行的,所以程序执行的轨迹不可能一直都是线性执行。当有多个线程交叉执行时,被中断的线程的程序当前执行到哪条内存地址必然要保存下来,以便用于被中断的线程恢复执行时再按照被中断时的指令地址继续执行下去。为了线程切换后能恢复到正确的执行位置,每个线程都需要有一个独立的程序计数器,各个线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存,这在某种程度上有点类似于“ThreadLocal”,是线程安全的。
3、垃圾回收
引用计数(Reference Counting):
比较古老的回收算法。原理是此对象有一个引用,即增加一个计数,删除一个引用则减少一个计数。垃圾回收时,只用收集计数为0的对象。此算法最致命的是无法处理循环引用的问题。
标记-清除(Mark-Sweep):

此算法执行分两阶段。第一阶段从引用根节点开始标记所有被引用的对象,第二阶段遍历整个堆,把未标记的对象清除。此算法需要暂停整个应用,同时,会产生内存碎片。
复制(Copying):

此算法把内存空间划为两个相等的区域,每次只使用其中一个区域。垃圾回收时,遍历当前使用区域,把正在使用中的对象复制到另外一个区域中。算法每次只处理正在使用中的对象,因此复制成本比较小,同时复制过去以后还能进行相应的内存整理,不会出现“碎片”问题。当然,此算法的缺点也是很明显的,就是需要两倍内存空间。
标记-整理(Mark-Compact):

此算法结合了“标记-清除”和“复制”两个算法的优点。也是分两阶段,第一阶段从根节点开始标记所有被引用对象,第二阶段遍历整个堆,把清除未标记对象并且把存活对象“压缩”到堆的其中一块,按顺序排放。此算法避免了“标记-清除”的碎片问题,同时也避免了“复制”算法的空间问题。
现代商用虚拟机基本都采用分代收集算法来进行垃圾回收。这种算法没什么特别的,无非是上面内容的结合罢了,根据对象的生命周期的不同将内存划分为几块,然后根据各块的特点采用最适当的收集算法。大批对象死去、少量对象存活的(新生代),使用复制算法,复制成本低;对象存活率高、没有额外空间进行分配担保的(老年代),采用标记-清理算法或者标记-整理算法。
垃圾回收机制详解:https://www.cnblogs.com/xiaoxi/p/6486852.html
4、类加载机制
JVM类加载机制分为五个部分:加载,验证,准备,解析,初始化,下面我们就分别来看一下这五个过程。

加载
加载是类加载过程中的一个阶段,这个阶段会在内存中生成一个代表这个类的java.lang.Class对象,作为方法区这个类的各种数据的入口。注意这里不一定非得要从一个Class文件获取,这里既可以从ZIP包中读取(比如从jar包和war包中读取),也可以在运行时计算生成(动态代理),也可以由其它文件生成(比如将JSP文件转换成对应的Class类)。
验证
这一阶段的主要目的是为了确保Class文件的字节流中包含的信息是否符合当前虚拟机的要求,并且不会危害虚拟机自身的安全。
准备
准备阶段是正式为类变量分配内存并设置类变量的初始值阶段,即在方法区中分配这些变量所使用的内存空间。注意这里所说的初始值概念,比如一个类变量定义为:
|
1
|
public static int v = 8080; |
实际上变量v在准备阶段过后的初始值为0而不是8080,将v赋值为8080的putstatic指令是程序被编译后,存放于类构造器<client>方法之中,这里我们后面会解释。
但是注意如果声明为:
|
1
|
public static final int v = 8080; |
在编译阶段会为v生成ConstantValue属性,在准备阶段虚拟机会根据ConstantValue属性将v赋值为8080。
解析
解析阶段是指虚拟机将常量池中的符号引用替换为直接引用的过程。符号引用就是class文件中的:
- CONSTANT_Class_info
- CONSTANT_Field_info
- CONSTANT_Method_info
等类型的常量。
下面我们解释一下符号引用和直接引用的概念:
- 符号引用与虚拟机实现的布局无关,引用的目标并不一定要已经加载到内存中。各种虚拟机实现的内存布局可以各不相同,但是它们能接受的符号引用必须是一致的,因为符号引用的字面量形式明确定义在Java虚拟机规范的Class文件格式中。
- 直接引用可以是指向目标的指针,相对偏移量或是一个能间接定位到目标的句柄。如果有了直接引用,那引用的目标必定已经在内存中存在。
初始化
初始化阶段是类加载最后一个阶段,前面的类加载阶段之后,除了在加载阶段可以自定义类加载器以外,其它操作都由JVM主导。到了初始阶段,才开始真正执行类中定义的Java程序代码。
初始化阶段是执行类构造器<client>方法的过程。<client>方法是由编译器自动收集类中的类变量的赋值操作和静态语句块中的语句合并而成的。虚拟机会保证<client>方法执行之前,父类的<client>方法已经执行完毕。p.s: 如果一个类中没有对静态变量赋值也没有静态语句块,那么编译器可以不为这个类生成<client>()方法。
注意以下几种情况不会执行类初始化:
- 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 常量在编译期间会存入调用类的常量池中,本质上并没有直接引用定义常量的类,不会触发定义常量所在的类。
- 通过类名获取Class对象,不会触发类的初始化。
- 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。
- 通过ClassLoader默认的loadClass方法,也不会触发初始化动作。
类加载器
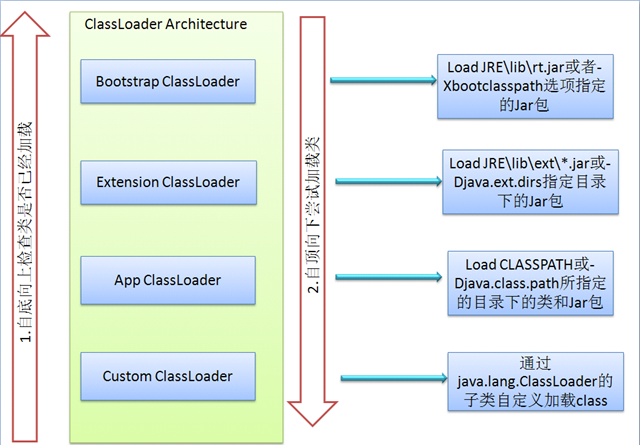
虚拟机设计团队把加载动作放到JVM外部实现,以便让应用程序决定如何获取所需的类,JVM提供了3种类加载器:
- 启动类加载器(Bootstrap ClassLoader):负责加载 JAVA_HOME\lib 目录中的,或通过-Xbootclasspath参数指定路径中的,且被虚拟机认可(按文件名识别,如rt.jar)的类。
- 扩展类加载器(Extension ClassLoader):负责加载 JAVA_HOME\lib\ext 目录中的,或通过java.ext.dirs系统变量指定路径中的类库。
- 应用程序类加载器(Application ClassLoader):负责加载用户路径(classpath)上的类库。
JVM通过双亲委派模型进行类的加载,当然我们也可以通过继承java.lang.ClassLoader实现自定义的类加载器。

当一个类加载器收到类加载任务,会先交给其父类加载器去完成,因此最终加载任务都会传递到顶层的启动类加载器,只有当父类加载器无法完成加载任务时,才会尝试执行加载任务。
采用双亲委派的一个好处是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。
三、并发编程
原子性:一个操作或多个操作要么全部执行完成且执行过程不被中断,要么就不执行。
可见性:当多个线程同时访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
有序性:程序执行的顺序按照代码的先后顺序执行。
Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
对于可见性,Java提供了volatile关键字来保证可见性。当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
在Java里面,可以通过volatile关键字来保证一定的“有序性”。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
volatile保证可见性、不能确保原子性、保证有序性。
java面试总结(资料来源网络)的更多相关文章
- Java 面试知识点解析(五)——网络协议篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- 五分钟学Java:如何学习Java面试必考的网络编程
原创声明 本文作者:黄小斜 转载请务必在文章开头注明出处和作者. 本文思维导图 简介 Java作为一门后端语言,对于网络编程的支持是必不可少的,但是,作为一个经常CRUD的Java工程师,很多时候都不 ...
- Java 面试知识点解析(六)——数据库篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java 面试知识点解析(七)——Web篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Wmyskxz文章目录导航附Java精品学习资料
前言:这段时间一直在准备校招的东西,所以一晃眼都好长时间没更新了,这段时间准备的稍微好那么一点点,还是觉得准备归准备,该有的学习节奏还是要有..趁着复习的空隙来整理整理自己写过的文章吧..好多加了微信 ...
- Java程序员面试学习资料汇总
整理了一些关于Java程序员面试的书籍及免费资料. 一.书籍篇1)<Offer来了:Java面试核心知识点精讲(原理篇)>精讲Java面试必需的JVM原理.Java基础.并发编程.数据结构 ...
- Java 面试知识点解析(四)——版本特性篇
前言: 在遨游了一番 Java Web 的世界之后,发现了自己的一些缺失,所以就着一篇深度好文:知名互联网公司校招 Java 开发岗面试知识点解析 ,来好好的对 Java 知识点进行复习和学习一番,大 ...
- Java面试总结(面试流程及核心面试题)
Java面试流程及核心面试题 面试整体流程 1.1 简单的自我介绍 我是xxxx,工作xxx年.我先后在xxxx公司.yyyy公司工作.先后做个xxxx项目.yyyy项目. 1.2 你简单介 ...
- java面试宝典(蓝桥学院)
Java面试宝典(蓝桥学院) 回答技巧 这套面试题主要目的是帮助那些还没有java软件开发实际工作经验,而正在努力寻找java软件开发工作的学生在笔试/面试时更好地赢得好的结果.由于这套试题涉及的范围 ...
随机推荐
- 截取所有的winform runtime error
https://stackify.com/csharp-catch-all-exceptions/ AppDomain.CurrentDomain.FirstChanceException += (s ...
- Poj2688cleaningrobot
这道题让我们求一个地图上的各个点之间的最短路径说白了旅行商问题. 那么我们先用一个裸的BFS求出各个点之间的最短距离,然后我们再枚举各个点的全排列即可 这道题的细节很多,详见注释 上代码~ #incl ...
- Movist for Mac(高清媒体播放器)v2.0.7中文特别版
Movist for Mac中文破解版是目前Mac平台上最好用的视频播放器,功能强大简单好用.movist mac版拥有美观简洁的用户界面,提供多种功能,支持视频解码加速高品质的字幕,全屏幕浏览,是与 ...
- haproxy反向代理
haproxy是个高性能的tcp和http的反向代理.它就是个代理.不像nginx还做web服务器 官网地址为www.haproxy.org nginx的优点和缺点 优点: 1.web服务器,应用比较 ...
- 18.22 sprintf函数功能
函数功能:把格式化的数据写入某个字符串 函数原型:int sprintf( char *buffer, const char *format [, argument] … ); 返回值:字符串长度(s ...
- RabbitMq C# .net 教程
本文转载来自 [http://www.cnblogs.com/yangecnu/p/Introduce-RabbitMQ.html]写的很详细. 文件安装包官方DEMO下载地址是:http://pan ...
- 【PLM】【PDM】60页PPT终于说清了PDM和PLM的区别;智造时代,PLM系统10大应用趋势!
https://blog.csdn.net/np4rhi455vg29y2/article/details/79266738
- 升级GCC以支持C++11
本文主要介绍在Linux系统下,如何升级GCC以支持C++11.目前来看GCC是对C++11支持程度最高最多的编译器,但需要GCC4.8及以上版本. 本文使用操作系统:Centos 6.4 Desk ...
- redis的pub/sub命令
Redis 发布订阅 Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息. Redis 客户端可以订阅任意数量的频道. 下图展示了频道 cha ...
- php对函数的引用
function &example($tmp=0){ //定义一个函数,别忘了加“&”符 return $tmp; ...