python爬虫之requests的基本使用
简介
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作。
一、安装
pip快速安装
pip install requests
二、使用
1、先上一串代码
import requests
response = requests.get("https://www.baidu.com")
print(type(response))
print(response.status_code)
print(type(response.text))
response.enconding = "utf-8'
print(response.text)
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))
response.text返回的是Unicode格式,通常需要转换为utf-8格式,否则就是乱码。response.content是二进制模式,可以下载视频之类的,如果想看的话需要decode成utf-8格式。
不管是通过response.content.decode("utf-8)的方式还是通过response.encoding="utf-8"的方式都可以避免乱码的问题发生
2、一大推请求方式
import requests
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
基本GET:
import requests url = 'https://www.baidu.com/'
response = requests.get(url)
print(response.text)
带参数的GET请求:
如果想查询http://httpbin.org/get页面的具体参数,需要在url里面加上,例如我想看有没有Host=httpbin.org这条数据,url形式应该是http://httpbin.org/get?Host=httpbin.org
下面提交的数据是往这个地址传送data里面的数据。
import requests url = 'http://httpbin.org/get'
data = {
'name':'zhangsan',
'age':'25'
}
response = requests.get(url,params=data)
print(response.url)
print(response.text)
Json数据:
从下面的数据中我们可以得出,如果结果:
1、requests中response.json()方法等同于json.loads(response.text)方法
import requests
import json response = requests.get("http://httpbin.org/get")
print(type(response.text))
print(response.json())
print(json.loads(response.text))
print(type(response.json())
获取二进制数据
在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及
视频资源
添加header
首先说,为什么要加header(头部信息)呢?例如下面,我们试图访问知乎的登录页面(当然大家都你要是不登录知乎,就看不到里面的内容),我们试试不加header信息会报什么错。
import requests url = 'https://www.zhihu.com/'
response = requests.get(url)
response.encoding = "utf-8"
print(response.text)
结果:
提示发生内部服务器错误(也就说你连知乎登录页面的html都下载不下来)。
<html><body><h1>500 Server Error</h1>
An internal server error occured.
</body></html>
如果想访问就必须得加headers信息。
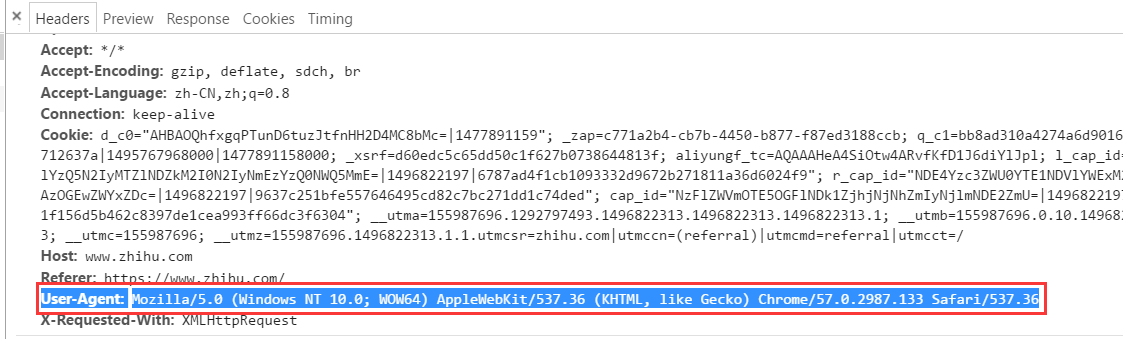
import requests url = 'https://www.zhihu.com/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
response = requests.get(url,headers=headers)
print(response.text)
基本post请求:
通过post把数据提交到url地址,等同于一字典的形式提交form表单里面的数据
import requests url = 'http://httpbin.org/post'
data = {
'name':'jack',
'age':'23'
}
response = requests.post(url,data=data)
print(response.text)
结果:
{
"args": {},
"data": "",
"files": {},
"form": {
"age": "23",
"name": "jack"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Connection": "close",
"Content-Length": "16",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.13.0"
},
"json": null,
"origin": "118.144.137.95",
"url": "http://httpbin.org/post"
}
响应:
import requests
response = requests.get("http://www.baidu.com")
#打印请求页面的状态(状态码)
print(type(response.status_code),response.status_code)
#打印请求网址的headers所有信息
print(type(response.headers),response.headers)
#打印请求网址的cookies信息
print(type(response.cookies),response.cookies)
#打印请求网址的地址
print(type(response.url),response.url)
#打印请求的历史记录(以列表的形式显示)
print(type(response.history),response.history)

内置的状态码:
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# Redirection.
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# Client Error.
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# Server Error.
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication'),
内置的状态码
import requests
response = requests.get('http://www.jianshu.com/404.html')
# 使用request内置的字母判断状态码 #如果response返回的状态码是非正常的就返回404错误
if response.status_code != requests.codes.ok:
print('404') #如果页面返回的状态码是200,就打印下面的状态
response = requests.get('http://www.jianshu.com')
if response.status_code == 200:
print('200')
request的高级操作
文件上传
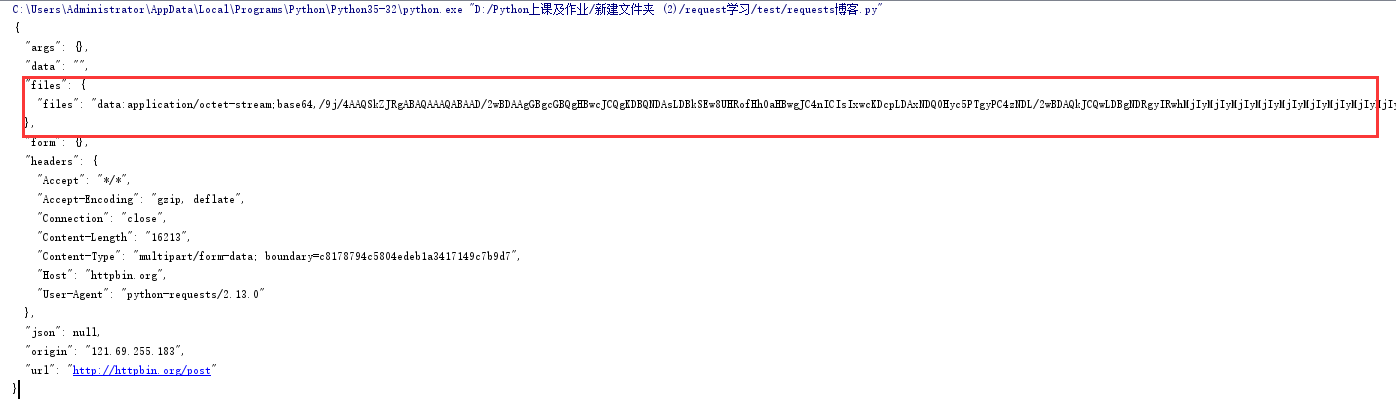
import requests
url = "http://httpbin.org/post"
files= {"files":open("test.jpg","rb")}
response = requests.post(url,files=files)
print(response.text)
结果:
获取cookie
import requests
response = requests.get('https://www.baidu.com')
print(response.cookies)
for key,value in response.cookies.items():
print(key,'==',value)
会话维持
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests
session = requests.session()
session.get('http://httpbin.org/cookies/set/number/12456')
response = session.get('http://httpbin.org/cookies')
print(response.text)
证书验证
1、无证书访问
import requests
response = requests.get('https://www.12306.cn')
# 在请求https时,request会进行证书的验证,如果验证失败则会抛出异常
print(response.status_code)
报错:


关闭证书验证
import requests
# 关闭验证,但是仍然会报出证书警告
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
为了避免这种情况的发生可以通过verify=False,但是这样是可以访问到页面结果

消除验证证书的警报
from requests.packages import urllib3
import requests urllib3.disable_warnings()
response = requests.get('https://www.12306.cn',verify=False)
print(response.status_code)
手动设置证书
import requests
response = requests.get('https://www.12306.cn', cert=('/path/server.crt', '/path/key'))
print(response.status_code)
代理设置
1、设置普通代理
import requests
proxies = {
"http": "http://127.0.0.1:9743",
"https": "https://127.0.0.1:9743",
}
response = requests.get("https://www.taobao.com", proxies=proxies)
print(response.status_code)
2、设置用户名和密码代理
import requests
proxies = {
"http": "http://user:password@127.0.0.1:9743/",
}
response = requests.get("https://www.taobao.com", proxies=proxies)
print(response.status_code)
设置socks代理
安装socks模块 pip3 install 'requests[socks]'
import requests
proxies = {
'http': 'socks5://127.0.0.1:9742',
'https': 'socks5://127.0.0.1:9742'
}
response = requests.get("https://www.taobao.com", proxies=proxies)
print(response.status_code)
超时设置
通过timeout参数可以设置超时的时间
import requests
from requests.exceptions import ReadTimeout try:
# 设置必须在500ms内收到响应,不然或抛出ReadTimeout异常
response = requests.get("http://httpbin.org/get", timeout=0.5)
print(response.status_code)
except ReadTimeout:
print('Timeout')
认证设置
如果碰到需要认证的网站可以通过requests.auth模块实现
import requests
from requests.auth import HTTPBasicAuth
#方法一
r = requests.get('http://120.27.34.24:9001', auth=HTTPBasicAuth('user', '123'))
#方法二
r = requests.get('http://120.27.34.24:9001', auth=('user', '123'))
print(r.status_code)
异常处理
关于reqeusts的异常在这里可以看到详细内容:
http://www.python-requests.org/en/master/api/#exceptions
所有的异常都是在requests.excepitons中

从源码我们可以看出RequestException继承IOError,
HTTPError,ConnectionError,Timeout继承RequestionException
ProxyError,SSLError继承ConnectionError
ReadTimeout继承Timeout异常
这里列举了一些常用的异常继承关系,详细的可以看:
http://cn.python-requests.org/zh_CN/latest/_modules/requests/exceptions.html#RequestException
通过下面的例子进行简单的演示
import requests
from requests.exceptions import ReadTimeout, ConnectionError, RequestException
try:
response = requests.get("http://httpbin.org/get", timeout = 0.5)
print(response.status_code)
except ReadTimeout:
print('Timeout')
except ConnectionError:
print('Connection error')
except RequestException:
print('Error')
首先被捕捉的异常是timeout,当把网络断掉的haul就会捕捉到ConnectionError,如果前面异常都没有捕捉到,最后也可以通过RequestExctption捕捉到
python爬虫之requests的基本使用的更多相关文章
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- python爬虫之requests库
在python爬虫中,要想获取url的原网页,就要用到众所周知的强大好用的requests库,在2018年python文档年度总结中,requests库使用率排行第一,接下来就开始简单的使用reque ...
- Python爬虫之requests
爬虫之requests 库的基本用法 基本请求: requests库提供了http所有的基本请求方式.例如 r = requests.post("http://httpbin.org/pos ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- python爬虫之requests库介绍(二)
一.requests基于cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests模块常规操作时,往往达不到我们 ...
- Python爬虫之requests库介绍(一)
一:Requests: 让 HTTP 服务人类 虽然Python的标准库中 urllib2 模块已经包含了平常我们使用的大多数功能,但是它的 API 使用起来让人感觉不太好,而 Requests 自称 ...
- Python爬虫之requests模块(1)
一.引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃 ...
- Python爬虫之requests模块(2)
一.今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 二.回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 三. ...
- python爬虫值requests模块
- 基于如下5点展开requests模块的学习 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在 ...
随机推荐
- 当web应用包含了websocket长连接,如何在web应用前加一层nginx转发
1 通过在web应用的前面加一层nginx ,可以实现一台主机部署多个应用,每个应用都可以用不同的域名去访问,并且端口都是80 2 nignx 转发websocket长连接 1 每个web应用,他们运 ...
- (折扣计算)需求说明:普通顾客购物满100元打9折;会员购物打8折;会员购物满200元打7.5折(判断语句if-else和switch语句的嵌套结
package com.summer.cn; import java.util.Scanner; /** * @author Summer *折扣计算 需求说明:普通顾客购物满100元打9折:会员购物 ...
- 线程概念( 线程的特点,进程与线程的关系, 线程和python理论知识,线程的创建)
参考博客: https://www.cnblogs.com/xiao987334176/p/9041318.html 线程概念的引入背景 进程 之前我们已经了解了操作系统中进程的概念,程序并不能单独运 ...
- face detection[CNN casade]
本文是基于< A convolutional neural network cascade for face detection>的解读,所以时间线是2015年. 0 引言 人脸检测是CV ...
- djongo:Django和MongoDB连接器
在Django项目中使用MongoDB作为后端数据库,且不改变Django的ORM框架.实现Django用户管理程序对MongoDB数据库中文件的增加和修改. 用法 1.pip install djo ...
- 生产者消费者 ProducerConsumer
生产者消费者是常见的同步问题.一个队列,头部生产数据,尾部消费数据,队列的长度为固定值.当生产的速度大于消费的速度时,队列逐渐会填满,这时就会阻塞住.当尾部消费了数据之后,生产者就可以继续生产了. 生 ...
- hibernate 解决诡异的mysql存入中文乱码
使用hibernate查询mysql,通过bean的get方法拿到字符串再写入mysql中的字段会中文乱码,需要String string = xxx.get(),把get方法拿到的值传入到新的str ...
- disruptor 高性能之道
disruptor是一个高性能的线程间异步通信的框架,即在同一个JVM进程中的多线程间消息传递.应用disruptor知名项目有如下的一些:Storm, Camel, Log4j2,还有目前的美团点评 ...
- Arduino通过MAX9814实现录音
如果通过Arduino进行录音不是单纯地接一个驻极电容MIC就可以的,因为自然界中的声音非常复杂,波形极其复杂,通常我们采用的是脉冲代码调制编码.即PCM编码.PCM通过抽样.量化.编码三个步骤将连续 ...
- 设置placeholder无效解决办法
一.设置placeholder的方法 placeholder属性用来设置控件内部的提示信息 <input type="text" placeholder="请输入用 ...