从零开始搭建django前后端分离项目 系列六(实战之聚类分析)
项目需求
本项目从impala获取到的数据为用户地理位置数据,每小时的数据量大概在8000万条,数据格式如下:

公司要求对这些用户按照聚集程度进行划分,将300米范围内用户数大于200的用户划分为一个簇,并计算这个簇的中心点和簇的边界点。
附模拟的数据:https://files.cnblogs.com/files/dotafeiying/test.zip
实现原理
下面我们来一步一步实现上述需求:
1、将用户按照聚集程度进行划分
我们可以选择基于密度的聚类算法DBscan算法,DBSCAN算法的重点是选取的聚合半径参数eps和聚合所需指定的数目min_samples,正好对应这里的300米和200个用户。但是需要注意的是,dbscan算法的默认距离度量为欧几里得距离,而我们需要的是球面距离,所以需要定制我们自己的距离算法运用到dbscan算法中。解决方法是:将dbscan设置为 metric='precomputed' ,这时fit传入的X参数必须为相似度矩阵,然后fit函数会直接用你这个矩阵来进行计算。这意味着我们可以用我们自定义的距离事先计算好各个向量的相似度,然后调用这个函数来获得结果。
2、识别簇的边界点
这里我使用凸包算法来计算簇的边界点,那么问题就变成:如何求一个平面内所有点的最小凸边形。在scipy.spatial 和opencv 分别有计算凸包的函数,不清楚的可以自行百度。
3、计算簇的中心点
由于dbscan算法中并没有提到获取簇中心点的方法,那么我们就需要自己设计来计算簇的中心点。现在簇的所有点已知,我们可以利用k-means算法来计算簇的中心点,只需要设置K=1(即质心为1)。
实现代码
# -*- coding:utf-8 -*-
from math import radians, cos, sin, asin, sqrt,degrees
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN, KMeans
from scipy.spatial import ConvexHull
from sklearn.cluster import MeanShift, estimate_bandwidth
from scipy.spatial.distance import pdist, squareform
from sklearn import metrics pd.set_option('display.width', 400)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('display.max_columns', 70) def haversine(lonlat1, lonlat2):
lat1, lon1 = lonlat1
lat2, lon2 = lonlat2
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2) ** 2 + cos(lat1) * cos(lat2) * sin(dlon / 2) ** 2
c = 2 * asin(sqrt(a))
r = 6371 # Radius of earth in kilometers. Use 3956 for miles
return c * r if __name__=='__main__':
df=pd.read_csv('test.csv')
print(df.head())
X=df[['mr_longitude','mr_latitude']].values radius = 200
epsilon = radius / 100000
min_samples = 40 # model = DBSCAN(eps=epsilon, min_samples=min_samples)
# y_pred = model.fit_predict(X) # # 自定义度量距离
distance_matrix = squareform(pdist(X, (lambda u, v: haversine(u, v))))
db = DBSCAN(eps=300, min_samples=200, metric='precomputed')
y_pred = db.fit_predict(distance_matrix)
print(y_pred.tolist()) n_clusters_ = len(set(y_pred)) - (1 if -1 in y_pred else 0) # 获取分簇的数目
print('分簇的数目:',n_clusters_)
df['label'] = y_pred df_group = df[df['label'] != -1][['mr_longitude', 'mr_latitude', 'label']].groupby(['label'])
plt.figure(facecolor='w')
for label, group in df_group:
points = group[['mr_longitude', 'mr_latitude']].values
# 得到凸轮廓坐标的索引值,逆时针画
hull = ConvexHull(points).vertices.tolist()
hull.append(hull[0])
plt.plot(points[hull, 0], points[hull, 1], 'r--^', lw=2)
for i in range(len(hull) - 1):
plt.text(points[hull[i], 0], points[hull[i], 1], str(i), fontsize=10)
plt.scatter(X[:, 0], X[:, 1], c=y_pred,s=4)
plt.grid(True)
plt.show()
可视化
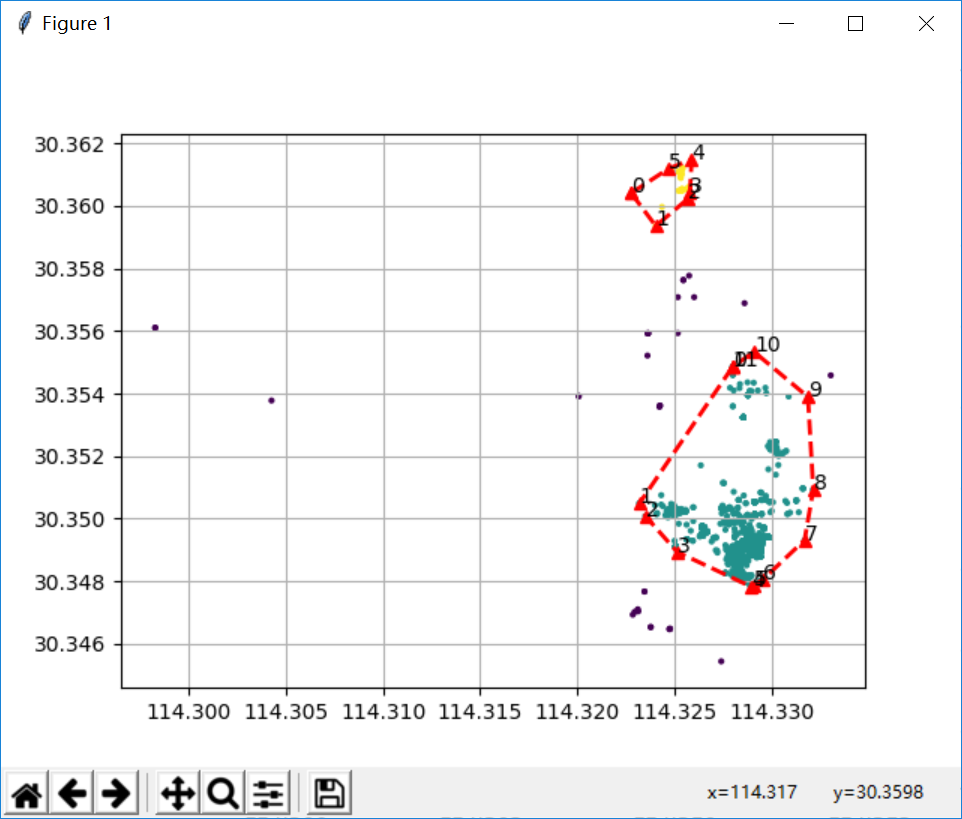
实际项目中的效果图

从零开始搭建django前后端分离项目 系列六(实战之聚类分析)的更多相关文章
- 从零开始搭建django前后端分离项目 系列一(技术选型)
前言 最近公司要求基于公司的hadoop平台做一个关于电信移动网络的数据分析平台,整个项目需求大体分为四大功能模块:数据挖掘分析.报表数据查询.GIS地理化展示.任务监控管理.由于页面功能较复杂,所以 ...
- 从零开始搭建django前后端分离项目 系列四(实战之实时进度)
本项目实现了任务执行的实时进度查询 实现方式 前端websocket + 后端websocket + 后端redis订阅/发布 实现原理 任务执行后,假设用变量num标记任务执行的进度,然后将num发 ...
- 从零开始搭建django前后端分离项目 系列三(实战之异步任务执行)
前面已经将项目环境搭建好了,下面进入实战环节.这里挑选项目中涉及到的几个重要的功能模块进行讲解. celery执行异步任务和任务管理 Celery 是一个专注于实时处理和任务调度的分布式任务队列.由于 ...
- 从零开始搭建django前后端分离项目 系列二(项目搭建)
在开始项目之前,假设你已了解以下知识:webpack配置.vue.js.django.这里不会教你webpack的基本配置.热更新是什么,也不会告诉你如何开始一个django项目,有需求的请百度,相关 ...
- 从零开始搭建django前后端分离项目 系列五(实战之excel流式导出)
项目中有一处功能需求是:需要在历史数据查询页面进行查询字段的选择,然后由后台数据库动态生成对应的excel表格并下载到本地. 如果文件较小,解决办法是先将要传送的内容全生成在内存中,然后再一次性传入R ...
- Django前后端分离项目部署
vue+drf的前后端分离部署笔记 前端部署过程 端口划分: vue+nginx的端口 是81 vue向后台发请求,首先发给的是代理服务器,这里模拟是nginx的 9000 drf后台运行在 9005 ...
- luffy项目搭建流程(Django前后端分离项目范本)
第一阶段: 1.版本控制器:Git 2.pip安装源换国内源 3.虚拟环境搭建 4.后台:Django项目创建 5.数据库配置 6.luffy前 ...
- nginx+vue+uwsgi+django的前后端分离项目部署
Vue+Django前后端分离项目部署,nginx默认端口80,数据提交监听端口9000,反向代理(uwsgi配置)端口9999 1.下载项目文件(统一在/opt/luffyproject目录) (1 ...
- List多个字段标识过滤 IIS发布.net core mvc web站点 ASP.NET Core 实战:构建带有版本控制的 API 接口 ASP.NET Core 实战:使用 ASP.NET Core Web API 和 Vue.js 搭建前后端分离项目 Using AutoFac
List多个字段标识过滤 class Program{ public static void Main(string[] args) { List<T> list = new List& ...
随机推荐
- python语言学习--2
第三天1. python代码缩进规则:具有相同缩进的代码被视为代码块,4个空格, 不要使用Tab,更不要混合Tab和空格,否则很容易造成因为缩进引起的语法错误. 2.list:[...] 用(名称任意 ...
- Thrift的C++服务端(线程池和非阻塞)模式
非阻塞模式 #include "RpcServiceHandler.h" #include <thrift/concurrency/ThreadManager.h> # ...
- Linux中Root密码破解
1.开机后在选择菜单时按下e进入编辑模式 2.选择linux16这一行,在行末尾添加 rd.break 3.然后Ctrl+x执行.然后进入shell界面: 4.设置密码: 1.重新挂载根目录为读写模式 ...
- mssql sql server上如何建一个只读视图–视图锁定的另类解决方案
转自:http://www.maomao365.com/?p=4508 <span style="color:red;font-weight:bold;">我们熟知一个 ...
- 洗礼灵魂,修炼python(82)--全栈项目实战篇(10)—— 信用卡+商城项目(模拟京东淘宝)
本次项目相当于对python基础做总结,常用语法,数组类型,函数,文本操作等等 本项目在博客园里其他开发者也做过,我是稍作修改来的,大体没变的 项目需求: 信用卡+商城: A.信用卡(类似白条/花呗) ...
- SQL Server 锁实验(UPDATE加锁探究)
update语句: 本例中由于看到的是update执行完的锁情况,因此无法看到IU锁,但其实针对要修改的数据页和索引页会先加IU锁,记录和键先加U锁,然后再转化为IX和X锁. 如果想要看到IU锁和U锁 ...
- python3使用selenium + Chrome基础操作代码
selenium是Python的第三方库,使用前需要安装.但是如果你使用的是anaconda,就可以省略这个步骤,为啥?自带,任性. 安装命令: pip install selenium (一)使用s ...
- Win10安装sqlserver2014打开显示黑色界面,mardown打开显示报错
问题描述: 我电脑从win7更新到win10以后就打开sqlserver2014显示黑色背景有问题,卸载了又装都是没有用 然后我又发现mardown也是有问题打开报告什么错误,忘记截图了,去网上找了个 ...
- February 23rd, 2018 Week 8th Friday
It takes a strong man to save himself, and a great man to save another. 强者自救,圣者渡人. When you are not ...
- IntelliJ IDEA 创建Spring+SpringMVC+mybatis+maven项目
参考自:https://www.cnblogs.com/hackyo/p/6646051.html 第一步: 创建maven项目 输入项目名和工程id 选择maven 默认就可以了 刚开始时间比较长, ...