centos7下zookeeper集群安装部署
应用场景:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。
它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。[摘自百度百科]
官网:http://zookeeper.apache.org/
安装环境:Zookeeper集群最好至少安装3个节点,这里端口采用默认zookeeper默认端口:2181

安装步骤:
1. 下载zookeeper并解压
官网推荐下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/
~]# .tar.gz -C /opt/ //这里解压至/opt目录中使用

2. 编辑配置文件
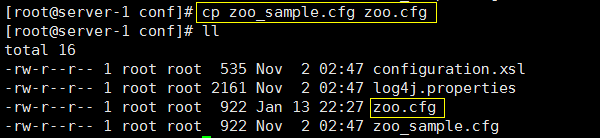
进入conf目录,cp生成一个zk能识别的配置文件名:zoo.cfg,如下
[root@server- conf]# cp zoo_sample.cfg zoo.cfg
修改配置文件zoo.cfg,如下:
[root@server- conf]# vim zoo.cfg
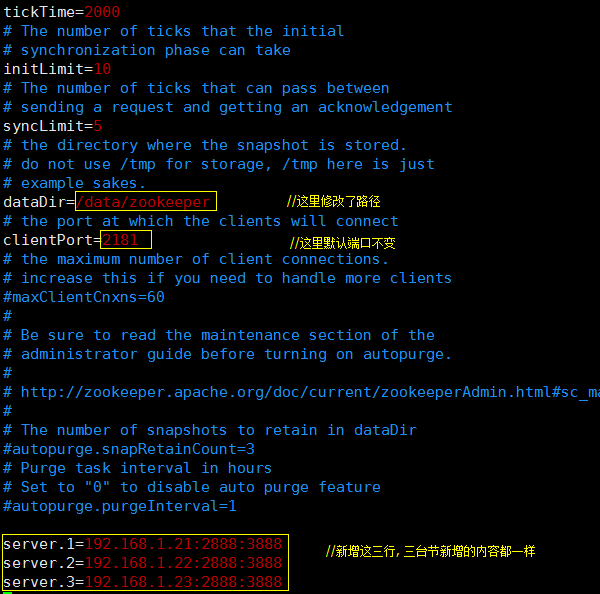
保存,退出;
三台节点配置一样,其他两台略。
3. 添加myid文件
说明:除了修改 zoo.cfg 配置文件,集群模式下还要新增一个名叫myid的文件,这个文件放在上述dataDir指定的目录下,这个文件里面就
只有一个数据,就是上图配置中server.x的这个x(1,2,3)值,zookeeper启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面
的配置信息比较从而判断到底是那个server(节点)。



4. 启动节点
切换到bin目录中查看一下:
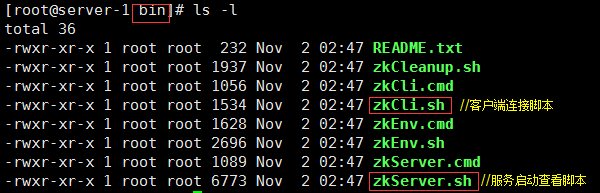
启动方法查看:

启动节点1:
[root@server- bin]# ./zkServer.sh start // 默认会到同级目录conf中寻找zoo.cfg文件,所以默认不用加配置文件
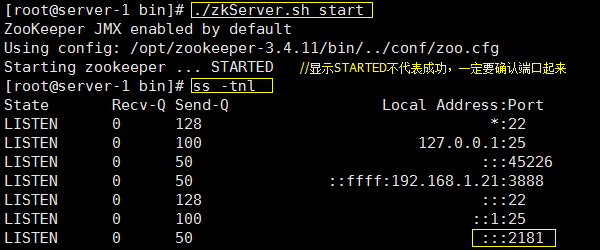
同样的,启动节点2,节点3:
[root@server- bin]# ./zkServer.sh start
[root@server- bin]# ./zkServer.sh start
启动后,会在当前bin目录下生成一个日志zookeeper.out,如果启动不成功里面会有错,可供排错使用。
5. 查看节点状态
当三台节点都启动完毕后可以查看他们各自在集群中的状态:
[root@server- bin]# ./zkServer.sh status



至此,zookeeper集群部署成功。
排错:如果查看集群状态的时候报“Error contacting service. It is probably not running.”请检查防火墙是不是阻挡了contacting。

6. zookeeper客户端使用
使用bin目录下的客户端登录脚本:zkCli.sh
比方说:登录、查看、退出。
[root@server- bin]# ./zkCli.sh -server 192.168.1.21:2181 //连本地节点
[root@server- bin]# ./zkCli.sh -server 192.168.1.21 //不带端口就采用默认2181端口
[root@server- bin]# ./zkCli.sh //不带参数回车默认连接本地IP和2181端口
[root@server- bin]# ./zkCli.sh -server 192.168.1.22 //也可以连接节点2的zk
登录后操作:
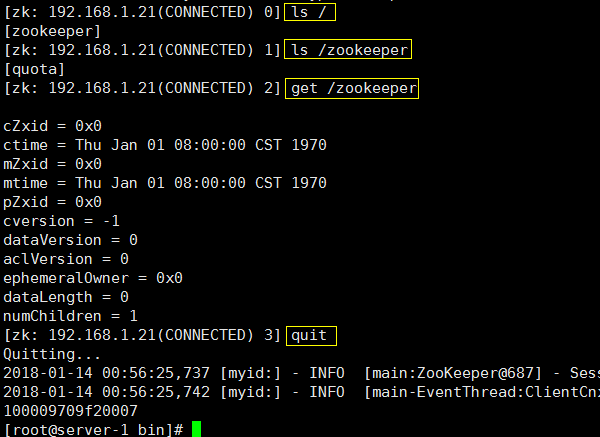
说明:客户端连接后,用get / 命令可以发现此时只有zookeeper一项;如果此Zookeeper用于对Kafka或JStorm等提供服务,
则还会有相应的其他目录,后面在介绍kafka时会有相关内容。
kafka集群安装:http://www.cnblogs.com/ding2016/p/8282907.html
7. 集群测试
这里就模拟断掉"leader"节点——node-2,另外两台会通过之前设定的这个端口来重新选举leader,结果如下:


结束.
centos7下zookeeper集群安装部署的更多相关文章
- centos7下kafka集群安装部署
应用摘要: Apache kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的 分布式发布订阅消息系统,是消息中间件的一种,用于构建实时 ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
- windows下zookeeper集群安装
windows下zookeeper单机版安装,见:https://www.cnblogs.com/lbky/p/9867899.html 一:zookeeper节点为什么是奇数个? 单机模式的zk进程 ...
- Linux 下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)
一.应用场景介绍 本文主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联网的Linux环境和脱机的Linux环境下是如何安装的.因为大多数时候,公司的生产环境是在内网环境下,无外网 ...
- centos7:Zookeeper集群安装
将安装包上传到安装目录 解压文件 tar -zxvf zookeeper-3.4.12.tar.gz 移动解压后的文件到软件目录 mv zookeeper-3.4.12 /home/softwareD ...
- Linux下zookeeper集群搭建
Linux下zookeeper集群搭建 部署前准备 下载zookeeper的安装包 http://zookeeper.apache.org/releases.html 我下载的版本是zookeeper ...
- Elasticsearch学习总结 (Centos7下Elasticsearch集群部署记录)
一. ElasticSearch简单介绍 ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticse ...
- 【分布式】Zookeeper伪集群安装部署
zookeeper:伪集群安装部署 只有一台linux主机,但却想要模拟搭建一套zookeeper集群的环境.可以使用伪集群模式来搭建.伪集群模式本质上就是在一个linux操作系统里面启动多个zook ...
- Storm集群安装部署步骤【详细版】
作者: 大圆那些事 | 文章可以转载,请以超链接形式标明文章原始出处和作者信息 网址: http://www.cnblogs.com/panfeng412/archive/2012/11/30/how ...
随机推荐
- VS2008引入头文件包含目录和lib库目录
全局级别的引入 为VS所有项目设置包含目录和库目录,对所有项目都有效 如下图所示:工具-选项-项目和解决方案-VC++目录-包含文件:在此添加头文件目录即可 工具-选项-项目和解决方案-VC++目录- ...
- js去除数组重复成员
js去除数组重复成员 第一种思路是:遍历要删除的数组arr, 把元素分别放入另一个数组tmp中,在判断该元素在arr中不存在才允许放入tmp中 用到两个函数:for ...in 和 indexOf() ...
- Tomcat启用GZIP压缩,提升web性能
一.前言 最近做了个项目,遇到这么一个问题:服务器返回给客户端的json数据量太大(大概65M),在客户端加载了1分多钟才渲染完毕,费时耗流量,用户体验极其不好.后来网上搜优化的方法,就是Http压缩 ...
- [转帖]ulimit、limits.conf、sysctl和proc文件系统
ulimit.limits.conf.sysctl和proc文件系统 来源:https://blog.csdn.net/weixin_33918114/article/details/86882372 ...
- Day 4-5 序列化 json & pickle &shelve
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 反序列化: 把字符转成内存里的数据类型. 用于序列化的两个模块.他 ...
- JavaList addAll removeAll
List<String>list1=new ArrayList<>(); list1.add("a"); list1.add("b"); ...
- PLA-1
PLA(Principal Component Analysis)主成分分析: 思路1:坐标旋转 1.数据分布以及投影: 2.特征值以及特征向量 思路2: 未完待续...
- valgrind 检查内存泄露
https://www.oschina.net/translate/valgrind-memcheck
- hdu-4763(kmp+拓展kmp)
题意:给你一个串,问你满足最大字串既是前后缀,也在字符串除去前后缀的位置中出现过: 思路:我用的是拓展kmp求的前后缀,只用kmp也能解,在字符串2/3的位置后开始遍历,如果用一个maxx保存前2/3 ...
- gym-10135I
题意:和H差不多,这个是找字符串中最长的镜像字串: 思路:一样的思路,标记下: #include<iostream> #include<algorithm> #include& ...