【大数据技术】HBase介绍
1.HBase简介
1.1 Hbase是什么
HBase是一种构建在HDFS之上的分布式、面向列、多版本、非关系型的数据库,是Google Bigtable 的开源实现。
在需要实时读写、随机访问超大规模数据集时,可以使用HBase。
1.2 HBase特点
大:一个表可以有上亿行,上百万列。
面向列:面向列(组)的存储和权限控制,列(组)独立检索。
稀疏矩阵:对于为空(NULL)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
无模式:每一行都有一个可以排序的主键和任意多的列,列可以根据需要动态增加,同一张表中不同的行可以有截然不同的列。
数据多版本:每个单元中的数据可以有多个版本,默认情况下,版本号自动分配,版本号就是单元格插入时的时间戳。
数据类型单一:HBase中的数据都是字符串,没有类型,存储在hbase上的都是字节数组。
强一致性:Hbase是一个强一致性数据库,不是“最终一致性”数据库。
1.3 HBase缺点
单一RowKey固有的局限性决定了它不可能有效地支持多条件查询
不适合于大范围扫描查询
(2)支持上亿行、百万列;
(3)强一致性、高扩展、高可用
HBase数据读写,更新的数据是放在Memstore,只有当Memstore里的数据达到阈值,或者时间达到阈值,就会flush到磁盘上,生成HFile,而一旦生成HFile就是不可改变的。
当某一个DataNode上生成一个HFile后,就会异步更新到其他两个DataNode上(假设为3副本),这3个HFile是一模一样的。
PS:当客户端提交删除操作的时候,数据不是真正的删除,只是做了一个删除标记(delete marker,又称母被标记),表明给定航已经被伤处了,在检索过程中,这些删除标记掩盖了实际值,客户端读不到实际值。直到发生compaction的时候数据才会真正被删除。
HBase采用Master/Slave架构搭建集群,它隶属于Hadoop生态系统,由一下类型节点组成:HMaster节点、HRegionServer节点、ZooKeeper集群,而在底层,它将数据存储于HDFS中,因而涉及到HDFS的NameNode、DataNode等,总体结构如下
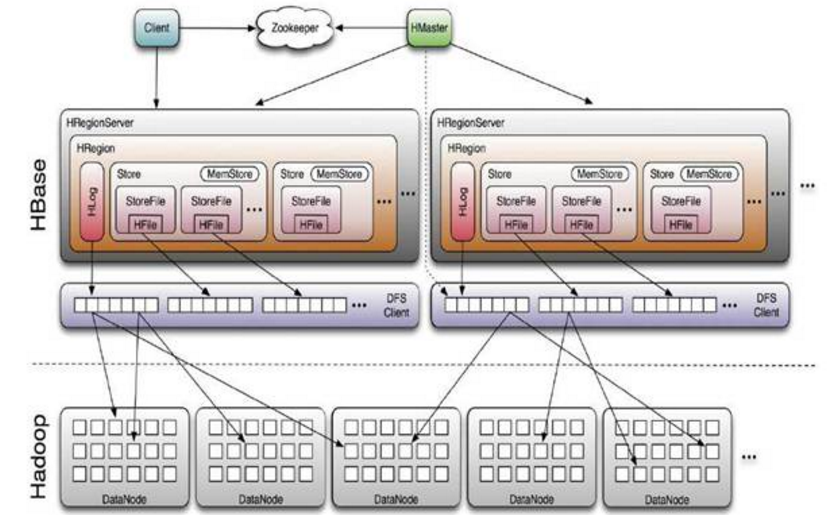
ROOT:系统内部表,里面存储了对应的.meta地址和开始结束信息。
.META:系统内部表,同样存储了对应HRegion地址和开始结束信息。
-ROOT-和.META.
参考文档:
【大数据技术】HBase介绍的更多相关文章
- 开源大数据技术专场(上午):Spark、HBase、JStorm应用与实践
16日上午9点,2016云栖大会“开源大数据技术专场” (全天)在阿里云技术专家封神的主持下开启.通过封神了解到,在上午的专场中,阿里云高级技术专家无谓.阿里云技术专家封神.阿里巴巴中间件技术部高级技 ...
- 大数据技术之HBase
第1章 HBase简介 1.1 什么是HBase HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储. 官方 ...
- 大数据技术 - MapReduce的Combiner介绍
本章来简单介绍下 Hadoop MapReduce 中的 Combiner.Combiner 是为了聚合数据而出现的,那为什么要聚合数据呢?因为我们知道 Shuffle 过程是消耗网络IO 和 磁盘I ...
- MaxCompute 最新特性介绍 | 2019大数据技术公开课第三季
摘要:距离上一次MaxCompute新功能的线上发布已经过去了大约一个季度的时间,而在这一段时间里,MaxCompute不断地在增加新的功能和特性,比如参数化视图.UDF支持动态参数.支持分区裁剪.生 ...
- 参加2013中国大数据技术大会(BDTC2013)
2013年12月5日-6日参加了为期两天的2013中国大数据技术大会(Big Data Technology Conference, BDTC2013),本期会议主题是:“应用驱动的架构与技术 ”.大 ...
- 大数据技术生态圈形象比喻(Hadoop、Hive、Spark 关系)
[摘要] 知乎上一篇很不错的科普文章,介绍大数据技术生态圈(Hadoop.Hive.Spark )的关系. 链接地址:https://www.zhihu.com/question/27974418 [ ...
- 从大数据技术变迁猜一猜AI人工智能的发展
目前大数据已经成为了各家互联网公司的核心资产和竞争力了,其实不仅是互联网公司,包括传统企业也拥有大量的数据,也想把这些数据发挥出作用.在这种环境下,大数据技术的重要性和火爆程度相信没有人去怀疑. 而A ...
- 开源大数据技术专场(下午):Databircks、Intel、阿里、梨视频的技术实践
摘要: 本论坛第一次聚集阿里Hadoop.Spark.Hbase.Jtorm各领域的技术专家,讲述Hadoop生态的过去现在未来及阿里在Hadoop大生态领域的实践与探索. 开源大数据技术专场下午场在 ...
- 【学习笔记】大数据技术原理与应用(MOOC视频、厦门大学林子雨)
1 大数据概述 大数据特性:4v volume velocity variety value 即大量化.快速化.多样化.价值密度低 数据量大:大数据摩尔定律 快速化:从数据的生成到消耗,时间窗口小,可 ...
- 大数据技术 - 为什么是SQL
在大数据处理以及分析中 SQL 的普及率非常高,几乎是每一个大数据工程师必须掌握的语言,甚至非数据处理岗位的人也在学习使用 SQL.今天这篇文章就聊聊 SQL 在数据分析中作用以及掌握 SQL 的必要 ...
随机推荐
- 使用VSCode如何调试C#控制台程序_1
A-环境安装 https://www.microsoft.com/net/download 下载 .NET Core SDK Installer: https://www.microsoft.com/ ...
- [转]Docker版本变化和新版安装
本文转自:http://www.cnblogs.com/Peter2014/p/7704306.html Docker从1.13版本之后采用时间线的方式作为版本号,分为社区版CE和企业版EE. 社区版 ...
- C#装箱和拆箱。
装箱:值类型-->引用类型. 拆箱:引用类型-->值类型 装箱:把值类型拷贝一份到堆里.反之拆箱. 具有父子关系 是拆装箱的条件之一. 所以: class Program { static ...
- webAPI 控制器(Controller)太多怎么办?
写过接口的同学都知道,接口会越来越多,那么控制器也会越来越多.这时候就需要根据某种业务或特性对controller进行分类然后建立文件夹. 我想到一个折中的方案:伪Areas! 在Areas文件夹下建 ...
- eclipse下svn的使用
描述:本篇用解决下面的案例中的问题来描述eclipse svn插件的使用. a.案例 某研发团队开发了一款名为App,目前已发布v1.0版本.此项目初期已有部分基础代码, 研发团队再此基础代码上经过3 ...
- 【Tomcat】Tomcat的类加载机制
在Tomcat中主要有以下几种类加载器:(图片来自网络) tomcat启动时,会创建几种类加载器: 1 Bootstrap 引导类加载器 加载JVM启动所需的类,以及标准扩展类,位于jre/lib/e ...
- virtualbox中设置u盘启动
1.在磁盘管理中查看u盘的磁盘号X 2.管理员运行cmd,进入virtualbox目录 3.运行命令: VBoxManage internalcommands createrawvmdk -filen ...
- vue从入门到进阶:计算属性computed与侦听器watch(三)
计算属性computed 模板内的表达式非常便利,但是设计它们的初衷是用于简单运算的.在模板中放入太多的逻辑会让模板过重且难以维护.例如: <div id="example" ...
- java调用matlab
object result[]; result = pClass1.job_3in1(2, c, ws2, 1275, a, 0); string adg[]; adg = result[1].toS ...
- CSS的基本语法
W3School离线手册(2017.03.11版)下载:https://pan.baidu.com/s/1c6cUPE7jC45mmwMfM6598A CSS(层叠样式表) ...