Lucene 基础理论 (zhuan)
http://www.blogjava.net/hoojo/archive/2012/09/06/387140.html
****************************************
1. 全文检索系统与Lucene简介
1.1 什么是全文检索与全文检索系统
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
全文检索的方法主要分为按字检索和按词检索两种。按字检索是指对于文章中的每一个字都建立索引,检索时将词分解为字的组合。对于各种不同的语言而言,字有不同的含义,比如英文中字与词实际上是合一的,而中文中字与词有很大分别。按词检索指对文章中的词,即语义单位建立索引,检索时按词检索,并且可以处理同义项等。英文等西方文字由于按照空白切分词,因此实现上与按字处理类似,添加同义处理也很容易。中文等东方文字则需要切分字词,以达到按词索引的目的,关于这方面的问题,是当前全文检索技术尤其是中文全文检索技术中的难点,在此不做详述。
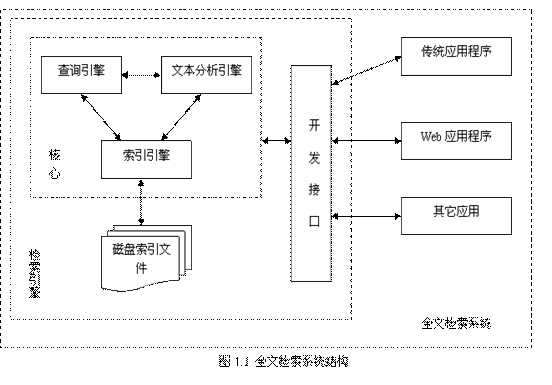
全文检索系统是按照全文检索理论建立起来的用于提供全文检索服务的软件系统。一般来说,全文检索需要具备建立索引和提供查询的基本功能,此外现代的全文检索系统还需要具有方便的用户接口、面向WWW[1]的开发接口、二次应用开发接口等等。功能上,全文检索系统核心具有建立索引、处理查询返回结果集、增加索引、优化索引结构等等功能,外围则由各种不同应用具有的功能组成。结构上,全文检索系统核心具有索引引擎、查询引擎、文本分析引擎、对外接口等等,加上各种外围应用系统等等共同构成了全文检索系统。图1.1展示了上述全文检索系统的结构与功能。
在上图中,我们看到:全文检索系统中最为关键的部分是全文检索引擎,各种应用程序都需要建立在这个引擎之上。一个全文检索应用的优异程度,根本上由全文检索引擎来决定。因此提升全文检索引擎的效率即是我们提升全文检索应用的根本。另一个方面,一个优异的全文检索引擎,在做到效率优化的同时,还需要具有开放的体系结构,以方便程序员对整个系统进行优化改造,或者是添加原有系统没有的功能。比如在当今多语言处理的环境下,有时需要给全文检索系统添加处理某种语言或者文本格式的功能,比如在英文系统中添加中文处理功能,在纯文本系统中添加XML或者HTML格式的文本处理功能,系统的开放性和扩充性就十分的重要。
1.2 什么是Lucene
Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,即它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene的原作者是Doug Cutting,他是一位资深全文索引/检索专家,曾经是V-Twin搜索引擎的主要开发者,后在Excite担任高级系统架构设计师,目前从事于一些Internet底层架构的研究。早先发布在作者自己的http://www.lucene.com/,后来发布在SourceForge,2001年年底成为apache软件基金会jakarta的一个子项目:http://jakarta.apache.org/lucene/。
1.3 Lucene的应用、特点及优势
作为一个开放源代码项目,Lucene从问世之后,引发了开放源代码社群的巨大反响,程序员们不仅使用它构建具体的全文检索应用,而且将之集成到各种系统软件中去,以及构建Web应用,甚至某些商业软件也采用了Lucene作为其内部全文检索子系统的核心。apache软件基金会的网站使用了Lucene作为全文检索的引擎,IBM的开源软件eclipse的2.1版本中也采用了Lucene作为帮助子系统的全文索引引擎,相应的IBM的商业软件Web Sphere中也采用了Lucene。Lucene以其开放源代码的特性、优异的索引结构、良好的系统架构获得了越来越多的应用。
Lucene作为一个全文检索引擎,其具有如下突出的优点:
(1)索引文件格式独立于应用平台。Lucene定义了一套以8位字节为基础的索引文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件。
(2)在传统全文检索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的。
(3)优秀的面向对象的系统架构,使得对于Lucene扩展的学习难度降低,方便扩充新功能。
(4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的创立,用户扩展新的语言和文件格式,只需要实现文本分析的接口。
(5)已经默认实现了一套强大的查询引擎,用户无需自己编写代码即使系统可获得强大的查询能力,Lucene的查询实现中默认实现了布尔操作、模糊查询(Fuzzy Search)、分组查询等等。
面对已经存在的商业全文检索引擎,Lucene也具有相当的优势:
首先,它的开发源代码发行方式(遵守Apache Software License),在此基础上程序员不仅仅可以充分的利用Lucene所提供的强大功能,而且可以深入细致的学习到全文检索引擎制作技术和面相对象编程的实践,进而在此基础上根据应用的实际情况编写出更好的更适合当前应用的全文检索引擎。在这一点上,商业软件的灵活性远远不及Lucene。其次,Lucene秉承了开放源代码一贯的架构优良的优势,设计了一个合理而极具扩充能力的面向对象架构,程序员可以在Lucene的基础上扩充各种功能,比如扩充中文处理能力,从文本扩充到HTML、PDF等等文本格式的处理,编写这些扩展的功能不仅仅不复杂,而且由于Lucene恰当合理的对系统设备做了程序上的抽象,扩展的功能也能轻易的达到跨平台的能力。最后,转移到apache软件基金会后,借助于apache软件基金会的网络平台,程序员可以方便的和开发者、其它程序员交流,促成资源的共享,甚至直接获得已经编写完备的扩充功能。最后,虽然Lucene使用Java语言写成,但是开放源代码社区的程序员正在不懈的将之使用各种传统语言实现(例如.net framework),在遵守Lucene索引文件格式的基础上,使得Lucene能够运行在各种各样的平台上,系统管理员可以根据当前的平台适合的语言来合理的选。
2. Lucene系统结构分析
2.1 系统结构组织
Lucene作为一个优秀的全文检索引擎,其系统结构具有强烈的面向对象特征。首先是定义了一个与平台无关的索引文件格式,其次通过抽象将系统的核心组成部分设计为抽象类,具体的平台实现部分设计为抽象类的实现,此外与具体平台相关的部分比如文件存储也封装为类,经过层层的面向对象式的处理,最终达成了一个低耦合高效率,容易二次开发的检索引擎系统。
以下将讨论Lucene系统的结构组织,并给出系统结构与源码组织图:
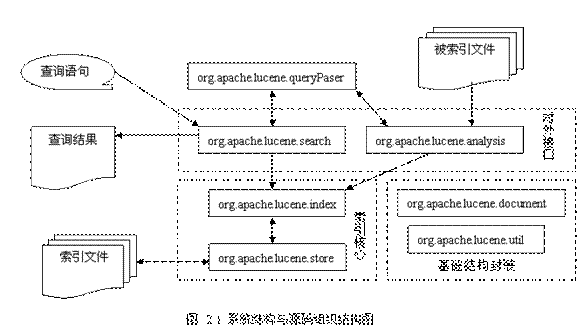
从图中我们清楚的看到,Lucene的系统由基础结构封装、索引核心、对外接口三大部分组成。其中直接操作索引文件的索引核心又是系统的重点。Lucene的将所有源码分为了7个模块(在java语言中以包即package来表示),各个模块所属的系统部分也如上图所示。需要说明的是org.apache.lucene.queryPaser是做为org.apache.lucene.search的语法解析器存在,不被系统之外实际调用,因此这里没有当作对外接口看待,而是将之独立出来。
从面象对象的观点来考察,Lucene应用了最基本的一条程序设计准则:引入额外的抽象层以降低耦合性。首先,引入对索引文件的操作org.apache.lucene.store的封装,然后将索引部分的实现建立在(org.apache.lucene.index)其之上,完成对索引核心的抽象。在索引核心的基础上开始设计对外的接口org.apache.lucene.search与org.apache.lucene.analysis。在每一个局部细节上,比如某些常用的数据结构与算法上,Lucene也充分的应用了这一条准则。在高度的面向对象理论的支撑下,使得Lucene的实现容易理解,易于扩展。
Lucene在系统结构上的另一个特点表现为其引入了传统的客户端服务器结构以外的的应用结构。Lucene可以作为一个运行库被包含进入应用本身中去,而不是做为一个单独的索引服务器存在。这自然和Lucene开放源代码的特征分不开,但是也体现了Lucene在编写上的本来意图:提供一个全文索引引擎的架构,而不是实现。
2.2 数据流分析
了解数据流分析的重要性:
理解Lucene系统结构的另一个方式是去探讨其中数据流的走向,并以此摸清楚Lucene系统内部的调用时序。在此基础上,我们能够更加深入的理解Lucene的系统结构组织,以方便以后在Lucene系统上的开发工作。这部分的分析,是深入Lucene系统的钥匙,也是进行重写的基础。
Lucene系统中的主要的数据流以及它们之间的关系图:
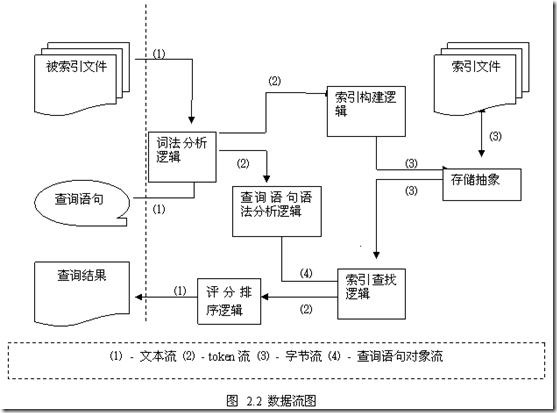
图2.2很好的表明了Lucene在内部的数据流组织情况,并且沿着数据流的方向我们也可以对与Lucene内部的执行时序有一个清楚的了解。现在将图中的涉及到的流的类型与各个逻辑对应系统的相关部分的关系说明一下。
图中共存在4种数据流,分别是文本流、token流、字节流与查询语句对象流。文本流表示了对于索引目标和交互控制的抽象,即用文本流表示了将要索引的文件,用文本流向用户输出信息;在实际的实现中,Lucene中的文本流采用了UCS-2作为编码,以达到适应多种语言文字的处理的目的。Token流是Lucene内部所使用的概念,是对传统文字中的词的概念的抽象,也是Lucene在建立索引时直接处理的最小单位;简单的讲Token就是一个词和所在域值的组合,后面在叙述文件格式时也将继续涉及到token,这里不详细展开。字节流则是对文件抽象的直接操作的体现,通过固定长度的字节(Lucene定义为8比特位长,后面文件格式将详细叙述)流的处理,将文件操作解脱出来,也做到了与平台文件系统的无关性。查询语句对象流则是仅仅在查询语句解析时用到的概念,它对查询语句抽象,通过类的继承结构反映查询语句的结构,将之传送到查找逻辑来进行查找的操作。
图中的涉及到了多种逻辑,基本上直接对应于系统某一模块,但是也有跨模块调用的问题发生,这是因为Lucene的重用程度非常好,因此很多实现直接调用了以前的工作成果,这在某种程度上其实是加强了模块耦合性,但是也是为了避免系统的过于庞大和不必要的重复设计的一种折衷体现。词法分析逻辑对应于org.apache.lucene.analysis部分。查询语句语法分析逻辑对应于org.apache.lucene.queryParser部分,并且调用了org.apache.lucene.analysis的代码。查询结束之后向评分排序逻辑输出token流,继而由评分排序逻辑处理之后给出文本流的结果,这一部分的实现也包含在了org.apache.lucene.search中。索引构建逻辑对应于org.apache.lucene.index部分。索引查找逻辑则主要是org.apache.lucene.search,但是也大量的使用了org.apache.lucene.index部分的代码和接口定义。存储抽象对应于org.apache.lucene.store。没有提到的模块则是做为系统公共基础设施存在。
2.3 基于Lucene的应用开发
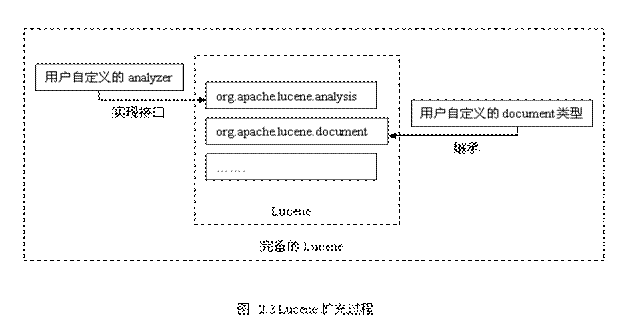
首先,我们需要的是按照目标语言的词法结构来构建相应的词法分析逻辑,实现Lucene在org.apache.lucene.analysis中定义的接口,为Lucene提供目标系统所使用的语言处理能力。Lucene默认的已经实现了英文和德文的简单词法分析逻辑(按照空格分词,并去除常用的语法词,如英语中的is,am,are等等)。在这里,主要需要参考实现的接口在org.apache.lucene.analysis中的Analyzer.java和Tokenizer.java中定义,Lucene提供了很多英文规范的实现样本,也可以做为实现时候的参考资料。其次,需要按照被索引的文件的格式来提供相应的文本分析逻辑,这里是指除开词法分析之外的部分,比如HTML文件,通常需要把其中的内容按照所属于域分门别类加入索引,这就需要从org.apache.lucene.document中定义的类document继承,定义自己的HTMLDocument类,然后就可以将之交给org.apache.lucene.index模块来写入索引文件。完成了这两步之后,Lucene全文检索引擎就基本上完备了。这个过程可以用下图表示:
下面是使用java语言开发,Lucene系统能够方便的嵌入到整个系统中去,作为一个API集来调用。这个过程十分简单,以下便是一个示例程序,配合注释理解起来很容易。

2.4 Lucene索引文件格式
首先在Lucene的文件格式中,以字节为基础,定义了如下的数据类型:
表 3.1 Lucene文件格式中定义的数据类型
数据类型
所占字节长度(字节)
说明
Byte
1
基本数据类型,其他数据类型以此为基础定义
UInt32
4
32位无符号整数,高位优先
UInt64
8
64位无符号整数,高位优先
VInt
不定,最少1字节
动态长度整数,每字节的最高位表明还剩多少字节,每字节的低七位表明整数的值,高位优先。可以认为值可以为无限大。其示例如下
值
字节1
字节2
字节3
0
00000000
1
00000001
2
00000010
127
01111111
128
10000000
00000001
129
10000001
00000001
130
10000010
00000001
16383
10000000
10000000
00000001
16384
10000001
10000000
00000001
16385
10000010
10000000
00000001
Chars
不定,最少1字节
采用UTF-8编码[20]的Unicode字符序列
String
不定,最少2字节
由VInt和Chars组成的字符串类型,VInt表示Chars的长度,Chars则表示了String的值
以上的数据类型就是Lucene索引文件格式中用到的全部数据类型,由于它们都以字节为基础定义而来,因此保证了是平台无关,这也是Lucene索引文件格式平台无关的主要原因。接下来我们看看Lucene索引文件的概念组成和结构组成。
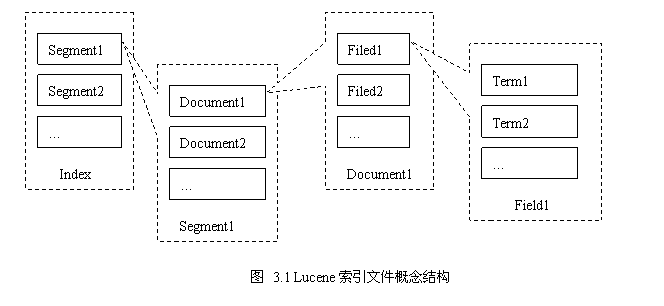
以上就是Lucene的索引文件的概念结构。Lucene索引index由若干段(segment)组成,每一段由若干的文档(document)组成,每一个文档由若干的域(field)组成,每一个域由若干的项(term)组成。项是最小的索引概念单位,它直接代表了一个字符串以及其在文件中的位置、出现次数等信息。域是一个关联的元组,由一个域名和一个域值组成,域名是一个字串,域值是一个项,比如将“标题”和实际标题的项组成的域。文档是提取了某个文件中的所有信息之后的结果,这些组成了段,或者称为一个子索引。子索引可以组合为索引,也可以合并为一个新的包含了所有合并项内部元素的子索引。我们可以清楚的看出,Lucene的索引结构在概念上即为传统的倒排索引结构。
从概念上映射到结构中,索引被处理为一个目录(文件夹),其中含有的所有文件即为其内容,这些文件按照所属的段不同分组存放,同组的文件拥有相同的文件名,不同的扩展名。此外还有三个文件,分别用来保存所有的段的记录、保存已删除文件的记录和控制读写的同步,它们分别是segments,deletable和lock文件,都没有扩展名。每个段包含一组文件,它们的文件扩展名不同,但是文件名均为记录在文件segments中段的名字。让我们看如下的结构图3.2:
每个段的文件中,主要记录了两大类的信息:域集合与项集合。这两个集合中所含有的文件在图3.2中均有表明。由于索引信息是静态存储的,域集合与项集合中的文件组采用了一种类似的存储办法:一个小型的索引文件,运行时载入内存;一个对应于索引文件的实际信息文件,可以按照索引中指示的偏移量随机访问;索引文件与信息文件在记录的排列顺序上存在隐式的对应关系,即索引文件中按照“索引项1、索引项2…”排列,则信息文件则也按照“信息项1、信息项2…”排列。比如在图3.2所示文件中,segment1.fdx与segment1.fdt之间,segment1.tii与segment1.tis、segment1.prx、segment1.frq之间,都存在这样的组织关系。而域集合与项集合之间则通过域的在域记录文件(比如segment1.fnm)中所记录的域记录号维持对应关系,在图3.2中segment1.fdx与segment1.tii中就是通过这种方式保持联系。这样,域集合和项集合不仅仅联系起来,而且其中的文件之间也相互联系起来。此外,标准化因子文件和被删除文档文件则提供了一些程序内部的辅助设施(标准化因子用在评分排序机制中,被删除文档是一种伪删除手段)。这样,整个段的索引信息就通过这些文档有机的组成。

2.5 一些公用的基础类
基础结构封装,或者基础类,由org.apache.lucene.util和org.apache.lucene.document两个包组成,前者定义了一些常量和优化过的常用的数据结构和算法,后者则是对于文档(document)和域(field)概念的一个类定义。以下我们用列表的方式来分析这些封装类,指出其要点;
表 3.2 基础类包org.apache.lucene.util
类
说明
Arrays
一个关于数组的排序方法的静态类,提供了优化的基于快排序的排序方法sort
BitVector
C/C++语言中位域的java实现品,但是加入了序列化能力
Constants
常量静态类,定义了一些常量
PriorityQueue
一个优先队列的抽象类,用于后面实现各种具体的优先队列,提供常数时间内的最小元素访问能力,内部实现机制是哈析表和堆排序算法
表 3.3 基础类包org.apache.lucene.document
类
说明
Document
是文档概念的一个实现类,每个文档包含了一个域表(fieldList),并提供了一些实用的方法,比如多种添加域的方法、返回域表的迭代器的方法
Field
是域概念的一个实现类,每个域包含了一个域名和一个值,以及一些相关的属性
DateField
提供了一些辅助方法的静态类,这些方法将java中Date和Time数据类型和String相互转化
2.6 存储抽象
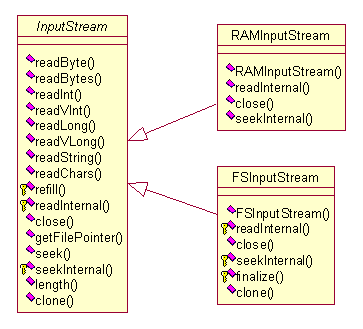
org.apache.lucene.store包:存储抽象是唯一能够直接对索引文件存取的包,因此其主要目的是抽象出和平台文件系统无关的存储抽象,提供诸如目录服务(增、删文件)、输入流和输出流。在分析其实现之前,首先我们看一下UML图;
图 3.3 存储抽象实现UML图(一)
图 3.4 存储抽象实现UML图(二)
图 3.4 存储抽象实现UML图(三)
图3.2到3.4展示了整个org.apache.lucene.store中主要的继承体系。共有三个抽象类定义:Directory、InputStream和OutputStrem,构成了一个完整的基于抽象文件系统的存取体系结构,在此基础上,实作出了两个实现品:(FSDirectory,FSInputStream,FSOutputStream)和(RAMDirectory,RAMInputStream和RAMOutputStream)。前者是以实际的文件系统做为基础实现的,后者则是建立在内存中的虚拟文件系统。前者主要用来永久的保存索引文件,后者的作用则在于索引操作时是在内存中建立小的索引,然后一次性的输出合并到文件中去,这一点我们在后面的索引逻辑部分能够看到。此外,还定以了org.apache.lucene.store.lock和org.apache.lucene.store.with两个辅助内部实现的类用在实现Directory方法的makeLock的时候,以在锁定索引读写之前来让客户程序做一些准备工作。
(FSDirectory,FSInputStream,FSOutputStream)的内部实现依托于java语言中的io类库,只是简单的做了一个外部逻辑的包装。这当然要归功于java语言所提供的跨平台特性,同时也带了一些隐患:文件存取的效率提升需要依耐于文件类库的优化。如果需要继续优化文件存取的效率,应该还提供一个文件与目录的抽象,以根据各种文件系统或者文件类型来提供一个优化的机会。当然,这是应用开发者所不需要关系的问题。
(RAMDirectory,RAMInputStream和RAMOutputStream)的内部实现就比较直接了,直接采用了虚拟的文件RAMFile类(定义于文件RAMDirectory.java中)来表示文件,目录则看作一个String与RAMFile对应的关联数组。RAMFile中采用数组来表示文件的存储空间。在此的基础上,完成各项操作的实现,就形成了基于内存的虚拟文件系统。因为在实际使用时,并不会牵涉到很大字节数量的文件,因此这种设计是简单直接的,也是高效率的。


3. Lucene索引构建逻辑模块分析
3.1对象体系与UML图
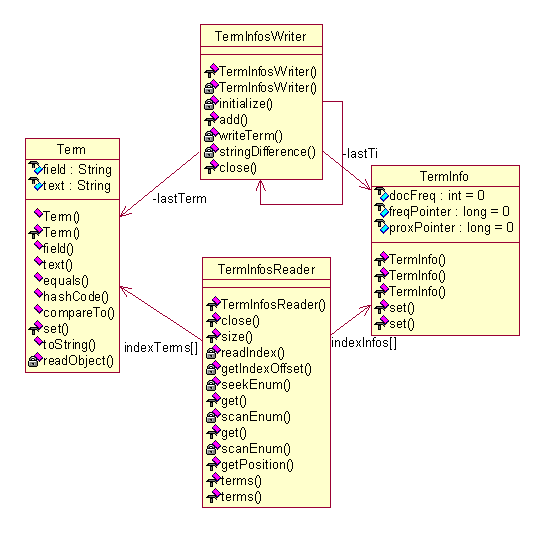
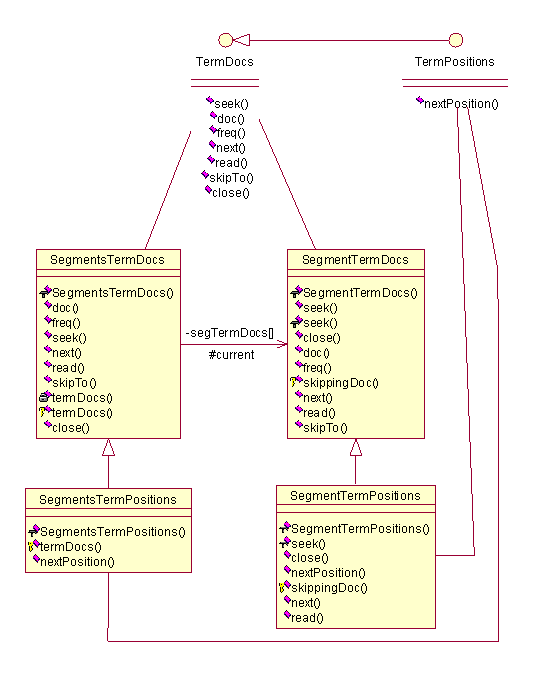
1. 项(Term)
项(Term):包括概念所实际涉及的类、永久化类。项(Term)所表示的是一个字符串,它拥有域、频数和位置信息等等属性。因此,Lucene中设计了两个类来表示这个概念,如下图
图 4.1 UML图(-)
上图中,有意的突出了类Term和TermInfo中的数据成员,因为它反映了对于项(Term)这个概念的具体表示。同时上图中也同时列出了用于永久化项(Term)的代理类TermInfosWriter和TermInfosReader,它们完成永久化的功能,需要注意的是,TermInfosReader内部使用了数组indexTerms和indexInfos来存储一系列项;而TermInfosWriter则是一个类似于链表的结构,通过一个other指向下一个TermInfosWriter,每一个TermInfosWriter只负责本身那个lastTerm和lastTi的永久化工作。这是一个设计上的技巧,通过批量读取(或者称为缓冲的方式)来获得读入时候的效率优化;而通过一个链表式的、各负其责的方式,来获得写出时候的设计简化。
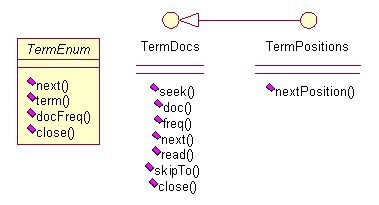
项(term)这部分的设计中,还有一些重要的接口和类:
图 4.2 UML图(二)
图4.2中,我们看到三个类:TermEnum、TermDocs与TermPositions,第一个是抽象类,后两个都是接口。TermEnum的设计主要用在后面Segment和Document等等的实现中,以提供枚举其中每一个项(Term)的能力。TermDocs是一个接口,用来继承以提供返回<document, frequency>值对的能力,通过这个接口就可以获得某个项(Term)在某个文档中出现的频数。TermPositions则是在TermDocs上的扩展,将项(Term)在文档中的位置信息也表示出来。TermDocs(TermPositions)接口的使用方式类似于java中的Enumration接口,即通过next方法跳转,通过doc,freq等方法获得当前的属性值。
2. 域(Field)
由于Field的基本概念在org.apache.lucene.document中已经做了定义,因此在这部分主要是针对项文件(.fnm文件、.fdx文件、.fdt文件)所需要的信息再来设计一些类。
图 4.3 UML图(三)
图 4.3中展示的,就是表示与域(Field)所关联的属性信息的类。其中isIndexed表示的这个域的值是否被索引过,即值是否被分词然后索引;另外两个属性所表示的意思则很明显:一个是域的名字,一个是域的编号。
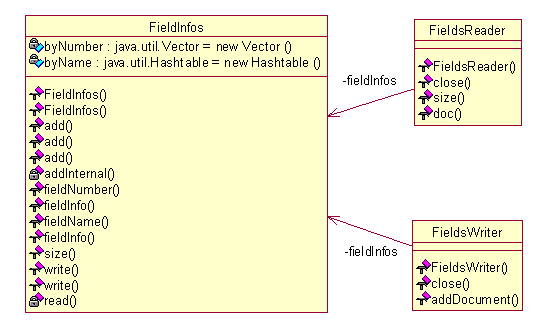
关于域表和存取逻辑的UML图:
FieldInfos即为域表的概念表示,内部采用了冗余的方式以获取在通过域的编号访问或者通过域的名字来访问时候的高效率。FieldsReader与FieldsWriter则分别是写出和读入的代理类。在功能和实现上,这两个类都比较简单。
3. 文档(document)
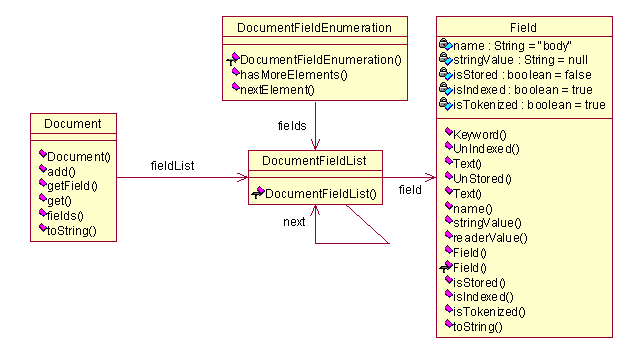
文档(document)同样也是在org.apache.lucene.document中定义过的结构。由于对于这部分比较重要,我们也来看看其UML图:
图 4.5 UML图(五)
在图4.5中我们看到,Document的设计基本上沿用了链表的处理方法。左边的Document类作为一个数据外包类,用来提供对于内部结构DocumentFieldList的增加删除访问操作等等。DocumentFieldList才是实际上的数据存储单位,它用了链表的处理方法,直接指向一个当前的Field对象和下一个DocumentFieldList对象,这个与前面的类似。为了能够逐个访问链表中的节点,还设计了DocumentFieldEnumeration枚举类。
图 4.6 UML图(六)
实际上定义于org.apache.lucene.index中的有关于Document的就是永久化的代理类。在图4.6中给出了其UML图。需要说明的是为什么没有出现读入的方法:这个方法已经隐含在图4.5中Document类中的add方法中了,结合图2.4中的程序代码段,我们就能够清楚的理解这种设计。
4. 段(segment)
段(Segment)这一部分设计的比较特殊,在实现简单的对象结构之上,还特意的设计了用于段之间合并的类。接下来,我们仍然采取对照UML分析的方式逐个叙述。接下来我们看Lucene中如何表示段这个概念。
图 4.7 UML图(七)
Lucene定义了一个类SegmentInfo用来表示每一个段(Segment)的信息,包括名字(name)、含有的文档的数目(docCount)和段所位于的目录的位置(dir)。根据索引文件中的段的意义,有了这三点,就能唯一确定一个段了。SegmentInfos这个类则是用来表示一个段的链表(从标准的java.util.Vector继承而来),实际上,也就是索引(index)的意思了。需要注意的是,这里并没有在SegmentInfo中安插一个文档(document)的链表。这样做的原因牵涉到Lucene内部对于文档(相当于一个被索引文件)的处理;Lucene内部采用了赋予文档编号,给域赋值的方式来处理文档,即加入的文档顺次编号,以后用文档号表示文档,而路径信息,文件名字等等在以后索引查找需要的属性,都作为域存储下来;因此SegmentInfo中并没有另外存储一个文档(document)的链表,对于这些的写出和读入,则交给了永久化的代理类来做。
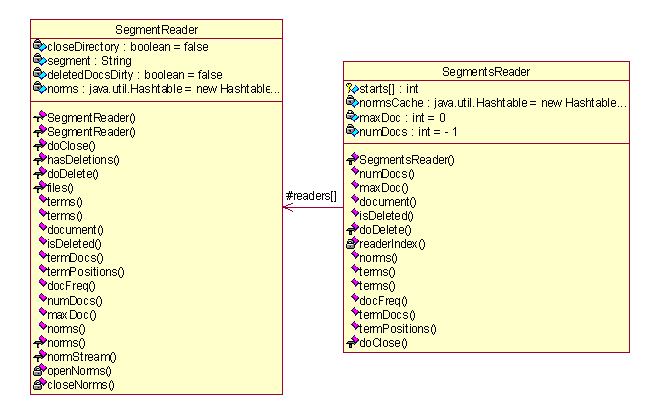
图 4.8 UML图(八)
图4.8给出了负责段(segment)的读入操作的代理类,而负责段(segment)的写出操作也同样没有定义,这些操作都直接实现在了类IndexWriter类中。段的操作同样采用了之前的数组或者说是缓冲的处理方式。
针对前面项(term)那部分定义的几个接口,段(segment)这部分也需要做相应的接口实现,因为提供直接遍历访问段中的各个项的能力对于检索来说,无疑是十分重要的。即这部分的设计,实际上都是在为了检索在服务。
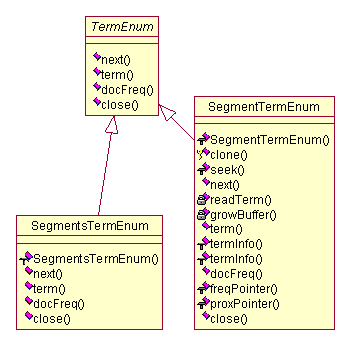
图 4.9 UML图(九)
图 4.10 UML图(十)
图4.9和图4.10分别展示了前面项(term)那里定义的接口是如何在这里通过继承实现的。Lucene在处理这部分的时候,也是分成两部分(Segment与Segments开头的类)来实现,而且很合理的运用了数组的技法,以及注意了继承重用。但是细化到局部,终归是比较简单的按照语义来获得结果而已了。
Lucene为了兼顾建立索引时的效率和读取索引查找的速度,引入了分小段建立索引的方式,即每一次批量建立索引时,先在内存中的虚拟文件系统中为每一个文档单独建立一个段,然后在输出的时候将这些段合并之后输出成为索引文件,这时仅仅存在一个段。多次建立的索引后,如果想优化索引文件,也可采取合并段的方法,将索引中的段合并成为一个段。我们来看一下在IndexWriter类中相应的方法的实现,来了解一下这中建立索引的实现。
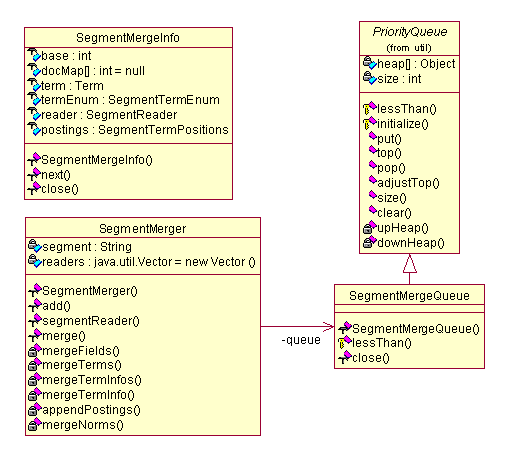
在mergeSegments函数中,将用到几个重要的类结构,它们记录了合并时候的一些重要信息,完成合并时候的工作。接下来,我们来看这几个类的UML图:
图 4.12 UML图(十一)
从图4.12中,我们看到Lucene设计一个类SegmentMergeInfo用来保存每一个被合并的段的信息,也保存能够访问其内部的接口句柄,也就是说合并时的操作使用这个类作为对被合并的段的操作代理。类SegmentMergeQueue则设计为org.apache.lucene.util.PriorityQueue的子类,做为SegmentMergeInfo的容器类,而且附带能够自动排序。SegmentMerger是主要进行操作的类,主要完成合并各个数据项的问题。
5. IndexReader类与IndexWirter类
最后剩下的,就是整个索引逻辑部分的使用接口类了。外界通过这两个类以及文档(document)类的构造函数调用之,比如图2.4中的代码示例所示。下面我们来看一下这部分最后两个类的UML图:
图 4.13 UML图(十二)
IndexWriter的设计与IndexReader的设计很不相同,前者是一个实现类,而后者是一个抽象类,带有没有实现的接口。IndexWriter的主要作用就是接收新加入的文档(document),然后在内部为之生成相应的小段,最后再合并并向索引文件中输出,图4.11中已经给出了一些实现的代码。由于Lucene在面向对象上封装的努力,通过各个构造函数就已经完成了对于各个概念的构造过程,剩下部分的代码主要是依据各个数组或者是链表中的信息,逐个逐个的将信息写出到相应的文件中去了。IndexReader部分则只是做了接口设计,没有具体的实现,这个和本部分所完成的主要功能有关:索引构建逻辑。设计这个抽象类的目的是,预先完成一些函数,为以后的检索(search)部分的各种形式的IndexReader铺平道路,也是利用了在同一个包内可以方便访问其它类的保护变量这个java语言的限制。
3.2 数据流逻辑
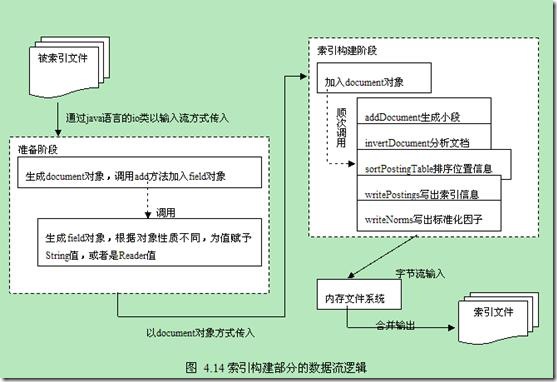
从宏观上明白一个系统的设计,理清楚其中的运行规律,最好的方式应该是通过数据流图。在分析了各个位于索引构建逻辑部分的类的设计之后,我们接下来就通过分析数据流图的方式来总结一下。但是由于之前提到的原因:索引读入部分在这一部分并没有完全实现,所以我们在数据流图中主要给出的是索引构建的数据流图。
对于图4.14中所描述的内容,结合Lucene源代码中的一些文件看,能够加深理解。准备阶段可以参考demo文件夹中的org.apache.lucene.demo.IndexFiles类和java文件夹中的org.apache.lucene.document文件包。索引构建阶段的主要源码位于java文件夹中org.apache.lucene.index.IndexWriter类,因此这部分可以结合这个类的实现来看。至于内存文件系统,比较复杂,但是这时的逻辑相对简单,因此也不难理解。
上面的数据流图十分清楚的勾画除了整个索引构建逻辑这部分的设计:通过层层嵌套的类结构,在构建时候即分步骤有计划的生成了索引结构,将之存储到内存中的文件系统中,然后通过对内存中的文件系统优化合并输出到实际的文件系统中。





本文是在我2010年学习Lucene的时候在互联网上摘抄整理而来,当时是在一家电子商务公司做商品检索需要用到Lucene,所以就研究了下。这篇文章也是在当时在网络上阅读Lucene相关知识整理而来的。
Lucene 基础理论 (zhuan)的更多相关文章
- 【手把手教你全文检索】Apache Lucene初探 (zhuan)
http://www.cnblogs.com/xing901022/p/3933675.html *************************************************** ...
- Lucene用法10个小结 (zhuan)
http://www.cfanz.cn/index.PHP?c=article&a=read&id=303149 *********************************** ...
- Lucene:基于Java的全文检索引擎简介 (zhuan)
http://www.chedong.com/tech/lucene.html ********************************************** Lucene是一个基于Ja ...
- 实战 Lucene,第 1 部分: 初识 Lucene (zhuan)
http://www.ibm.com/developerworks/cn/Java/j-lo-lucene1/ ******************************************** ...
- 开源搜索引擎评估:lucene sphinx elasticsearch (zhuan)
http://lutaf.com/158.htm ************************ 开源搜索引擎程序有3大类 lucene系,java开发,包括solr和elasticsearch s ...
- Elasticsearch Lucene 数据写入原理 | ES 核心篇
前言 最近 TL 分享了下 <Elasticsearch基础整理>https://www.jianshu.com/p/e8226138485d ,蹭着这个机会.写个小文巩固下,本文主要讲 ...
- lucene 基础知识点
部分知识点的梳理,参考<lucene实战>及网络资料 1.基本概念 lucence 可以认为分为两大组件: 1)索引组件 a.内容获取:即将原始的内容材料,可以是数据库.网站(爬虫).文本 ...
- 用lucene替代mysql读库的尝试
采用lucene对mysql中的表建索引,并替代全文检索操作. 备注:代码临时梳理很粗糙,后续修改. import java.io.File; import java.io.IOException; ...
- Lucene的评分(score)机制研究
首先,需要学习Lucene的评分计算公式—— 分值计算方式为查询语句q中每个项t与文档d的匹配分值之和,当然还有权重的因素.其中每一项的意思如下表所示: 表3.5 评分公式中的因子 评分因子 描 述 ...
随机推荐
- Round Numbers(组合数学)
Round Numbers Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 10484 Accepted: 3831 Descri ...
- Emag eht htiw Em Pleh 分类: POJ 2015-06-29 18:54 10人阅读 评论(0) 收藏
Emag eht htiw Em Pleh Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 2937 Accepted: ...
- JAVA基础知识之IO——Java IO体系及常用类
Java IO体系 个人觉得可以用"字节流操作类和字符流操作类组成了Java IO体系"来高度概括Java IO体系. 借用几张网络图片来说明(图片来自 http://blog.c ...
- 给table设置滚动条
<div scroll="no" style="width:1200px;overflow-x:scroll;overflow-y:hidden"> ...
- SqlSever基础 where 与 group by组合起来 处理数据
镇场诗:---大梦谁觉,水月中建博客.百千磨难,才知世事无常.---今持佛语,技术无量愿学.愿尽所学,铸一良心博客.------------------------------------------ ...
- 如何重置CentOS/RHEL 7中遗忘的根用户帐户密码
你有没有遇到过这种情况:想不起来Linux系统上的用户帐户密码?要是你忘了根用户密码,情况就更为糟糕.你无法执行任何面向整个系统的变更.要是你忘了用户密码,很容易使用根帐户来重置密码. 可要是你忘了根 ...
- 编写一个Java程序,计算一下1,2,…,9这9个数字可以组成多少个互不相同的、无重复数字的三位偶数。
package a; public class SanWeiOuShu { public static void main(String[] args) { String str="1234 ...
- Java——再看IO
一.编码问题 utf-8编码中,一个中文占3个字节,一个英文占1个字节:gbk编码中,一个中文占2个字节,一个英文占1个字节. Java是双字节编码,为utf-16be编码,是说一个字符(无论中文还是 ...
- Reading Csv Files with Text_io in Oracle D2k Forms
Below is the example to read and import comma delimited csv file in oracle forms with D2k_Delimited_ ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...