最大熵模型 Maximum Entropy Model
熵的概念在统计学习与机器学习中真是很重要,熵的介绍在这里:信息熵 Information Theory 。今天的主题是最大熵模型(Maximum Entropy Model,以下简称MaxEnt),MaxEnt 是概率模型学习中一个准则,其思想为:在学习概率模型时,所有可能的模型中熵最大的模型是最好的模型;若概率模型需要满足一些约束,则最大熵原理就是在满足已知约束的条件集合中选择熵最大模型。最大熵原理指出,对一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况不要做任何主观假设。在这种情况下,概率分布最均匀,预测的风险最小,因此得到的概率分布的熵是最大。
直观理解 MaxEnt
在求解概率模型时,当没有任何约束条件则只需找到熵最大的模型,比如预测一个骰子的点数,每个面为 $\frac{1}{6}$, 是, 当模型有一些约束条件之后,首先要满足这些约束条件, 然后在满足约束的集合中寻找熵最大的模型,该模型对未知的情况不做任何假设,未知情况的分布是最均匀的。举例来说对于随机变量 $X$ ,其可能的取值为 $\left \{ A,B,C\right\}$ ,没有任何约束的情况下下,各个值等概率得到的 MaxEnt 模型为:
\[P(A) = P(B) = P(C) = \frac{1}{3}\]
当给定一个约束 $P(A)= \frac{1}{2}$ , 满足该约束条件下的 MaxEnt 模型是:
\[P(A) = \frac{1}{2}\]
\[P(B) = P(C) = \frac{1}{4}\]
如果用欧式空间中的 simplex 来表示随机变量 $X$ 的话,则 simplex 中三个顶点分别代表随机变量 $X$ 的三个取值 A, B, C , 这里定义 simplex 中任意一点 $p$ 到三条边的距离之和(恒等于三角形的高)为 1,点到其所对的边为该取值的概率,比如任给一点 $p$ ,则$P(A)$ 等于 $p$ 到 边 BC 的距离,如果给定如下概率:
\[P(A) = 1 ,P(B) =P(C) = 0\]
\[P(A) = P(B) =P(C) = \frac{1}{3}\]
分别用下图表示以上两种情况:
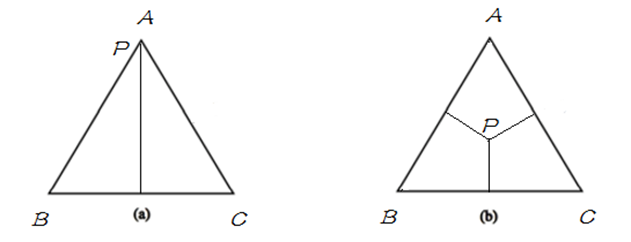 明白了 simplex 的定义之后,将其与概率模型联系起来,在 simplex 中,不加任何约束,整个概率空间的取值可以是 simplex 中的任意一点,只需找到满足最大熵条件的的即可;当引入一个约束条件 $C_1$ 后,如下图中 (b),模型被限制在 $C_1$ 表示的直线上,则应在满足约束 $C_1$ 的条件下来找到熵最大的模型;当继续引入条件 $C_2$ 后,如图(c),模型被限制在一点上,即此时有唯一的解;当 $C_1$ 与 $C_2$ 不一致时,如图(d),此时模型无法满足约束,即无解。在 MaxEnt 模型中,由于约束从训练数据中取得,所以不会出现不一致。即不会出现(d) 的情况。
明白了 simplex 的定义之后,将其与概率模型联系起来,在 simplex 中,不加任何约束,整个概率空间的取值可以是 simplex 中的任意一点,只需找到满足最大熵条件的的即可;当引入一个约束条件 $C_1$ 后,如下图中 (b),模型被限制在 $C_1$ 表示的直线上,则应在满足约束 $C_1$ 的条件下来找到熵最大的模型;当继续引入条件 $C_2$ 后,如图(c),模型被限制在一点上,即此时有唯一的解;当 $C_1$ 与 $C_2$ 不一致时,如图(d),此时模型无法满足约束,即无解。在 MaxEnt 模型中,由于约束从训练数据中取得,所以不会出现不一致。即不会出现(d) 的情况。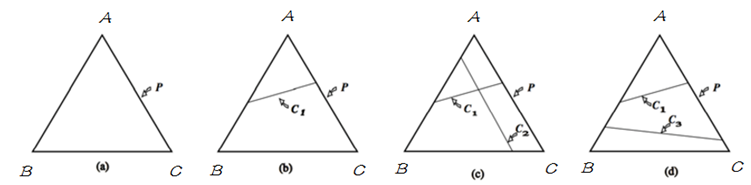
接下来以统计建模的形式来描述 MaxEnt 模型,给定训练数据 $\left \{ (x_i,y_i)\right\}_{i=1}^N$ ,现在要通过Maximum Entrop 来建立一个概率判别模型,该模型的任务是对于给定的 $X = x$ 以条件概率分布 $P(Y|X = x )$ 预测 $Y$ 的取值。根据训练语料能得出 $(X,Y)$ 的经验分布, 得出部分 $(X,Y)$ 的概率值,或某些概率需要满足的条件,即问题变成求部分信息下的最大熵或满足一定约束的最优解,约束条件是靠特征函数来引入的,首先先回忆一下函数期望的概念
对于随机变量 $X = x_i,i = 1,2,… $,则可以得到:
随机变量期望: 对于随机变量 $X$ ,其数学期望的形式为 $ E(X) = \sum_ix_ip_i$
随机变量函数期望:若 $Y = f(X)$ , 则关于 $X$ 的函数 $Y$ 的期望: $E(Y) = \sum_if(x_i)p_i$.
特征函数
特征函数 $f(x,y)$ 描述 $x$ 与 $y$ 之间的某一事实,其定义如下:
\[ f(x,y) = \left \{ \begin{aligned}
1, & \ 当 \ x、y \ 满足某一事实.\\
0, & \ 不满足该事实.\\
\end{aligned}\right .\]
特征函数 $f(x,y)$ 是一个二值函数, 当 $x$ 与 $y$ 满足事实时取值为 1 ,否则取值为 0 。比如对于如下数据集:

数据集中,第一列为 Y ,右边为 X ,可以为该数据集写出一些特征函数,数据集中得特征函数形式如下:
\[ f(x,y) = \left \{ \begin{aligned}
1, & \ if \ x= Cloudy \ and \ y=Outdoor.\\
0, & \ else.
\end{aligned}\right.\]
为每个 <feature,label> 对 都做一个如上的特征函数,用来描述数据集数学化。
约束条件
接下来看经验分布,现在把训练数据当做由随机变量 $(X,Y)$ 产生,则可以根据训练数据确定联合分布的经验分布 $\widetilde{P}(X,Y)$ 与边缘分布的经验分布 $\widetilde{P}(X)$ :
\begin{aligned}
\widetilde{P}(X = x,Y = y) &= \frac{count(X=x,Y= y)}{N}\\
\widetilde{P}(X = x) &= \frac{count(X=x)}{N}
\end{aligned}
用 $E _{\widetilde{P}}(f)$ 表示特征函数 $f(x,y)$ 关于经验分布 $\widetilde{P}(X ,Y )$ 的期望,可得:
\[E _{\widetilde{P}}(f) = \sum_{x,y}\widetilde{P}(x ,y)f(x,y) = \frac{1}{N} \sum_{x,y}f(x,y) \]
$\widetilde{P}(x ,y)$ 前面已经得到了,数数 $f(x,y)$ 的次数就可以了,由于特征函数是对建立概率模型有益的特征,所以应该让 MaxEnt 模型来满足这一约束,所以模型 $P(Y|X)$ 关于函数 $f$ 的期望应该等于经验分布关于 $f$ 的期望,模型 $P(Y|X)$ 关于 $f$ 的期望为:
\[E_P(f) =\sum_{x,y}P(x,y)f(x,y) \approx \sum_{x,y}\widetilde{P}(x)P(y|x)f(x,y)\]
经验分布与特征函数结合便能代表概率模型需要满足的约束,只需使得两个期望项相等, 即 $E_P(f) = E _{\widetilde{P}}(f)$ :
\[\sum_{x,y}\widetilde{P}(x)p(y|x)f(x,y) = \sum_{x,y}\widetilde{P}(x ,y)f(x,y)\]
上式便为 MaxEnt 中需要满足的约束,给定 $n$ 个特征函数 $f_i(x,y)$ ,则有 $n$ 个约束条件,用 $C$ 表示满足约束的模型集合:
\[C = \left\{ P \ | \ E_P(f_i) = E _{\widetilde{P}}(f_i) ,I = 1,2,…,n \right \}\]
从满足约束的模型集合 $C$ 中找到使得 $P(Y|X)$ 的熵最大的即为 MaxEnt 模型了。
最大熵模型
关于条件分布 $P(Y|X)$ 的熵为:
\[H(P) =–\sum_{x,y}P(y,x)logP(y|x)= –\sum_{x,y}\widetilde{P}(x)P(y|x)logP(y|x)\]
首先满足约束条件然后使得该熵最大即可,MaxEnt 模型 $P^*$ 为:
\[ P^* = arg\max_{P \in C} H(P) \ \ 或 \ \ P^* = arg\min_{P \in C} -H(P) \]
综上给出形式化的最大熵模型:
给定数据集 $\left \{ (x_i,y_i)\right\}_{i=1}^N$,特征函数 $f_i(x,y),i= 1,2…,n$ ,根据经验分布得到满足约束集的模型集合 $C$ :
\begin{aligned}
& \min_{P \in C} \ \ \sum_{x,y} \widetilde{P}(x)P(y|x)logP(y|x) \\
& \ s.t. \ \ \ E_p(f_i) = E _{\widetilde{P}}(f_i) \\
& \ \ \ \ \ \ \ \ \ \sum_yP(y|x) = 1
\end{aligned}
MaxEnt 模型的求解
MaxEnt 模型最后被形式化为带有约束条件的最优化问题,可以通过拉格朗日乘子法将其转为无约束优化的问题,引入拉格朗日乘子:
$w_0,w_1,…,w_n$, 定义朗格朗日函数 $L(P,w)$:
\begin{aligned}
L(P,w)
&= -H(P) + w_0\left (1-\sum_yP(y|x) \right ) + \sum^n_{i=1}w_i(E _{\widetilde{P}}(f_i) - E_p(f_i))\\
&=\sum_{x,y} \widetilde{P}(x)P(y|x)logP(y|x) + w_0\left (1-\sum_yP(y|x) \right ) + \sum^n_{i=1}w_i\left (\sum_{x,y}\widetilde{P}(x ,y)f(x,y) -\sum_{x,y}\widetilde{P}(x)p(y|x)f(x,y) \right )
\end{aligned}
现在问题转化为: $\min_{P \in C}L(P,w)$ ,拉格朗日函数 $L(P,w)$ 的约束是要满足的 ,如果不满足约束的话,只需另 $w_i \rightarrow +\infty$ ,则可得 $L(P,w) \rightarrow +\infty$ ,因为需要得到极小值,所以约束必须要满足,满足约束后可得: $L(P,w) = \max L(P,w)$ ,现在问题可以形式化为便于拉格朗日对偶处理的极小极大的问题:
\[\min_{P \in C} \max_w L(P,w)\]
由于 $L(P,w)$ 是关于 P 的凸函数,根据拉格朗日对偶可得 $L(P,w)$ 的极小极大问题与极大极小问题是等价的:
\[\min_{P \in C} \max_w L(P,w) = \max_w \min_{P \in C} L(P,w) \]
现在可以先求内部的极小问题 $\min_{P \in C} L(P,w)$ ,$\min_{P \in C} L(P,w)$ 得到的解为关于 $w$ 的函数,可以记做 $\Psi(w)$ :
\[\Psi(w) = \min_{P \in C} L(P,w) = L(P_w,w)\]
上式的解 $P_w$ 可以记做:
\[P_w = arg \min_{P \in C}L(P,w) = P_w(y|x)\]
由于求解 $P$ 的最小值 $P_w$ ,只需对于 $P(y|x)$ 求导即可,令导数等于 0 即可得到 $P_w(y|x)$ :
\begin{aligned}
\frac{\partial L(P,w) }{\partial P(y|x)} &= \sum_{x,y}\widetilde{P}(x)(logP(y|x)+1)-\sum_yw_0-\sum_{x,y}\left ( \widetilde{P}(x)\sum_{i=1}^nw_if_i(x,y) \right ) \\
&= \sum_{x,y}\widetilde{P}(x)\left ( logP(y|x)+1-w_0-\sum_{i=1}^n w_if_i(x,y) \right ) = 0 \\
\Rightarrow \\
P(y|x) &= exp \left ( \sum_{i=1}^n w_if_i(x,y) +w_0-1 \right ) = \frac{exp\left(\sum_{i=1}^n w_if_i(x,y) \right )}{exp(1-w_0)}
\end{aligned}
由于 $\sum_yP(y|x) = 1$,可得:
\[\sum_yP(y|x) = 1 \Rightarrow \frac {1} {exp(1-w_0)} \sum _y exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) = 1\]
进而可以得到:
\[ exp(1-w_0) = \sum _y exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) \]
这里 $exp(1-w_0)$ 起到了归一化的作用,令 $Z_w(x)$ 表示 $exp(1-w_0)$ ,便得到了 MaxEnt 模型 :
\begin{aligned}
P_w(y|x) &= \frac{1}{Z_w(x) }exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) \\
Z_w(x) &=\sum _y exp \left ( \sum_{i=1}^n w_if_i(x,y) \right )
\end{aligned}
这里 $f_i(x,y)$ 代表特征函数,$w_i$ 代表特征函数的权值, $P_w(y|x)$ 即为 MaxEnt 模型,现在内部的极小化求解得到关于 $w$ 的函数,现在求其对偶问题的外部极大化即可,将最优解记做 $w^*$:
\[w^* = arg \max_w \Psi(w)\]
所以现在最大上模型转为求解 $\Psi(w)$ 的极大化问题,求解最优的 $w^*$ 后, 便得到了所要求的MaxEnt 模型,将 $P_w(y|x)$ 带入 $\Psi(w)$ ,可得:
\begin{aligned}
\Psi(w) &=\sum_{x,y}\widetilde{P}(x)P_w(y|x)logP_w(y|x) + \sum^n_{i=1}w_i\left (\sum_{x,y}\widetilde{P}(x ,y)f(x,y) -\sum_{x,y}\widetilde{P}(x)P_w(y|x)f(x,y) \right )\\
&= \sum_{x,y} \widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y) +\sum_{x,y}\widetilde{P}(x)P_w(y|x)\left (logP_w(y|x) - \sum_{i=1}^nw_if_i(x,y) \right) \\
&=\sum_{x,y} \widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y) +\sum_{x,y}\widetilde{P}(x)P_w(y|x)logZ_w(x)\\
&=\sum_{x,y} \widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y) +\sum_x\widetilde{P}(x)logZ_w(x)\sum_yP_w(y|x)\\
&=\sum_{x,y} \widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y) +\sum_x\widetilde{P}(x)logZ_w(x)\\
\end{aligned}
以上推倒第二行到第三行用到以下结论:
\[P_w(y|x) = \frac{1}{Z_w(x) }exp \left ( \sum_{i=1}^n w_if_i(x,y) \right ) \Rightarrow logP_w(y|x) =\sum_{i=1}^n w_if_i(x,y) - logZ_w(x)\]
倒数第二行到最后一行是由于:$\sum_yP_w(y|x) = 1$,最终通过一系列极其复杂的运算,得到了需要极大化的式子:
\[\max_{p \in C} \sum_{x,y} \widetilde{P}(x,y)\sum_{i=1}^nw_if_i(x,y) +\sum_x\widetilde{P}(x)logZ_w(x)\]
极大化似然估计解法
这太难了,有没有简单又 work 的方式呢? 答案是有的,就是极大似然估计 MLE 了,这里有训练数据得到经验分布 $\widetilde{P}(x,y)$ , 待求解的概率模型 $P(Y|X)$ 的似然函数为:
\[L_{\widetilde{P}}(P_w) = log\prod_{x,y}P(y|x)^{\widetilde{P}(x,y)} = \sum_{x,y}\widetilde{P}(x,y)logP(y|x) \]
将 $P_w(y|x)$ 带入以下公式可以得到:
\begin{aligned}
L_{\widetilde{P}}(P_w) &= \sum_{x,y}\widetilde{P}(x,y)logP(y|x)\\
&= \sum_{x,y}\widetilde{P}(x,y)\left ( \sum_{i=1}^n w_if_i(x,y) -logZ_w(x)\right )\\
&= \sum_{x,y}\widetilde{P}(x,y)\sum_{i=1}^n w_if_i(x,y) - \sum_{x,y}\widetilde{P}(x,y)logZ_w(x)\\
&= \sum_{x,y}\widetilde{P}(x,y)\sum_{i=1}^n w_if_i(x,y) - \sum_{x}\widetilde{P}(x)logZ_w(x)\\
\end{aligned}
显而易见,拉格朗日对偶得到的结果与极大似然得到的结果时等价的,现在只需极大化似然函数即可,顺带优化目标中可以加入正则项,这是一个凸优化问题,一般的梯度法、牛顿法都可解之,专门的算法有GIS IIS 算法,。
这里给出来做下参考吧! ==
参考文献:
《统计学习方法》
http://blog.csdn.net/itplus/article/details/26550201
http://www.cnblogs.com/hexinuaa/p/3353479.html
A Maximum Entropy Approach A Maximum Entropy Approach
Classical Probabilistic Models and Conditional Random Fields
最大熵模型 Maximum Entropy Model的更多相关文章
- 逻辑斯特回归(logistic regression)与最大熵模型(maximum entropy model)
- 最大熵模型(Maximum Entropy Models)具体分析
因为本篇文章公式较多,csdn博客不同意复制公式,假设将公式一一保存为图片在上传太繁琐了,就用word排好版后整页转为图片传上来了.如有错误之处.欢迎指正.
- Maximum Entropy Model(最大熵模型)初理解
0,熵的描述 熵(entropy)指的是体系的混沌的程度(可也理解为一个随机变量的不确定性),它在控制论.概率论.数论.天体物理.生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的定义, ...
- 最大熵模型The Maximum Entropy
http://blog.csdn.net/pipisorry/article/details/52789149 最大熵模型相关的基础知识 [概率论:基本概念CDF.PDF] [信息论:熵与互信息] [ ...
- class-逻辑回归与最大熵模型
我们知道,线性回归能够进行简单的分类,但是它有一个问题是分类的范围问题,只有加上一个逻辑函数,才能使得其概率值位于0到1之间,因此本次介绍逻辑回归问题.同时,最大熵模型也是对数线性模型,在介绍最大熵模 ...
- 最大熵模型(Maximum Etropy)—— 熵,条件熵,联合熵,相对熵,互信息及其关系,最大熵模型。。
引入1:随机变量函数的分布 给定X的概率密度函数为fX(x), 若Y = aX, a是某正实数,求Y得概率密度函数fY(y). 解:令X的累积概率为FX(x), Y的累积概率为FY(y). 则 FY( ...
- [zz] 混合高斯模型 Gaussian Mixture Model
聚类(1)——混合高斯模型 Gaussian Mixture Model http://blog.csdn.net/jwh_bupt/article/details/7663885 聚类系列: 聚类( ...
- Maximum Entropy Population-Based Training for Zero-Shot Human-AI Coordination
原文:https://www.cnblogs.com/Twobox/p/16791412.html 熵 熵:表述一个概率分布的不确定性.例如一个不倒翁和一个魔方抛到地上,看他们平稳后状态.很明显,魔方 ...
- 最大熵模型(MEM)
1. 最大熵原理 最大熵Max Entropy原理:学习概率模型时,在所有可能的概率模型(即概率分布)中,熵最大的模型是最好的模型. 通常还有其他已知条件来确定概率模型的集合,因此最大熵原理为:在满足 ...
随机推荐
- java基础知识回顾之final
//继承弊端:打破了封装性. /* final关键字: 1,final是一个修饰符,可以修饰类,方法,变量. 2,final修饰的类不可以被继承. 3,final修饰的方法不可以被覆盖. 4,fina ...
- 记一段使用node对mysql数据库做处理
所用到的存储过程如下: temp_get_userCount: BEGIN #Routine body goes here... SELECT COUNT(id) as num FROM tbl_us ...
- 【XJOI-NOIP16提高模拟训练9】题解。
http://www.hzxjhs.com:83/contest/55 说实话这次比赛真的很水..然而我只拿了140分,面壁反思. 第一题: 发现数位和sum最大就是9*18,k最大1000,那么su ...
- JSTL标签库中fmt标签,日期,数字的格式化
首先介绍日期的格式化:(不要嫌多哦) JSTL格式化日期(本地化) 类似于数字和货币格式化,本地化环境还会影响生成日期和时间的方式. <%@ page pageEncoding="UT ...
- Ibm-jQuery教程学习笔记
一.概述 1.虽然 jQuery 本身并非一门新的语言.但是,学习其语法有助于我们熟练.灵活地使用它.回顾下我们熟悉的 CSS 语法,不难发现 jQuery 的语法与 CSS 有相似之处. jQuer ...
- linux 屏幕录像(recordmydesktop)
需求:命令行工具进行屏幕录像ffcast ffmpeg 简单点的是recordmydesktop. 1. 安装: apt-get install gtk-recordmydesktop recordm ...
- 281. Zigzag Iterator
题目: Given two 1d vectors, implement an iterator to return their elements alternately. For example, g ...
- MyBatis学习总结_15_定制Mybatis自动代码生成的maven插件
==================================================================================================== ...
- JSP下载txt 和 Excel两种文件
JSP下载txt 和 Excel两种文件 jsp 下载txt文件和excel文件 jsp 下载txt文件和excel文件 最近做了个用jsp下载的页面 将代码贴出来 权作记录吧 1 下载txt文件 ...
- Vi Usage
标签: linux 编辑工具 md 快捷键以及常用命令(前面带:的是命令) h -> 左移一个字符 j -> 下移一行 k -> 上移一行 l -> 右移一个字符 w或Shif ...