[大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)
4.2 排序(SORT)
在MapReduce中,排序的目的有两个:
- MapReduce可以通过排序将Map输出的键分组。然后每组键调用一次reduce。
- 在某些需要排序的特定场景中,用户可以将作业(job)的全部输出进行总体排序。
例如:需要了解前N个最受欢迎的用户或网页的数据分析工作。
在这一节中,有两个场景需要对MapReduce的排序行为进行优化。
- 次排序(Secondary sort)
- 总排序(Total order sorting)
次排序可以根据reduce的键对它的值进行排序。如果要求一些数据先于另外一些数据到达reduce,次排序就很有用。(这一章在讲解优化过的重分区连接中也提到了这样的场景。)另一个场景中,需要将作业的输出根据两个键进行排序,一个键的优先级高于另外一个键(secondary key)。这个场景也可以用到次排序。例如:将股票数据先根据股票标志进行主排序(primary sort),然后根据股票配额进行次排序。本书很多技术中将会运用次排序,如重分区连接的优化,朋友图算法等。
这一节第二部分中,将探讨对reduce的输出的全部数据进行总体排序。这在分析数据集中的前N个元素或后N个元素时会比较有用。
4.2.1 次排序(Secondary sort)
在前一节(MapReduce连接)中,次排序用于使一部分数据先于另外一部分到达reduce。作为基础知识,学习次排序前需要了解MapReduce中的数据整理和数据流。图4.12说明了三个影响数据整理和数据流(分区,排序,分组)的元素,并且说明了这些元素如何整合到MapReduce中。
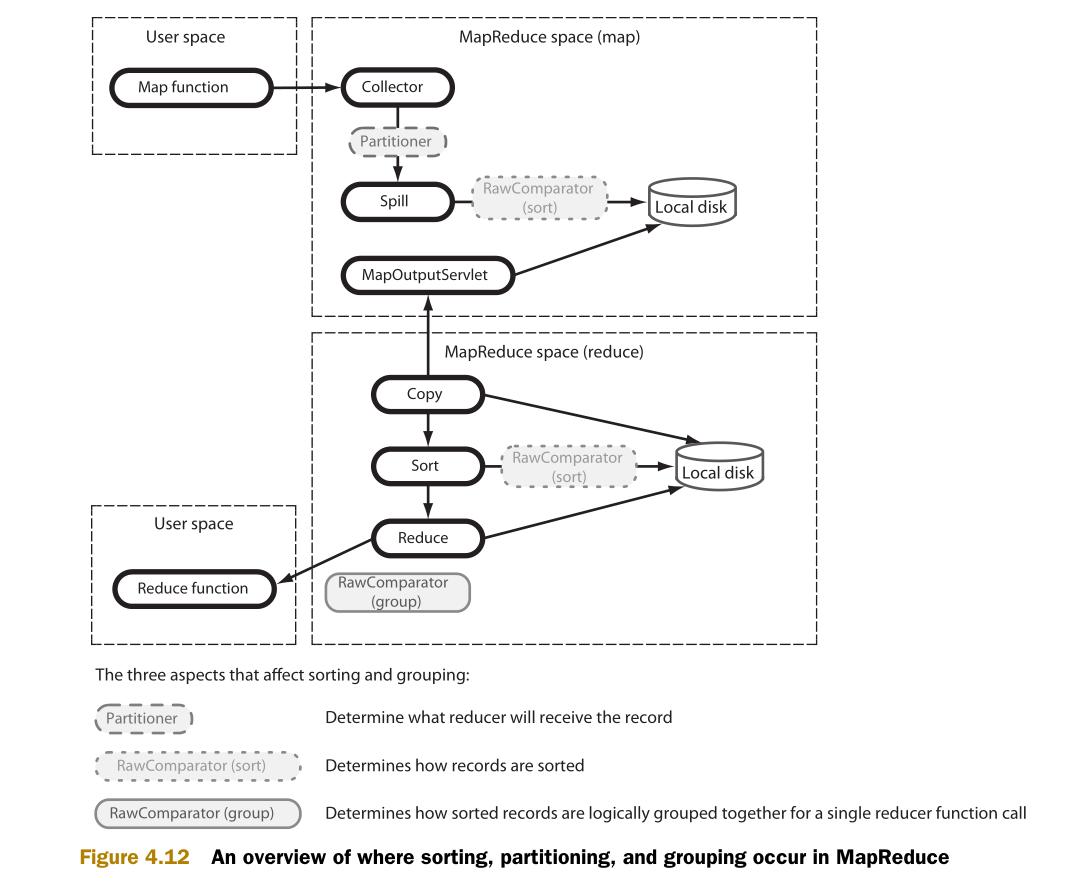
在map输出收集(output collection)阶段,由分区器(Partitioner)选择哪个reduce应该接收map的输出。map输出的各个分区的数据,由RawComparator进行排序。Reduce端也用RawComparator进行排序。然后,由RawComparator对排序好的数据进行分组。
技术21 实现次排序
对于某个map的键的所有值,如果需要其中一部分值先于另外一部分值到达reduce,就可以用到次排序。次排序还用在了本书的第7章中的朋友图算法,和经过优化的重分区排序中。
问题
在发送给某个reduce的数据中,需要对某个自然键(natural key)的值进行排序。
方案
这个技术中将应用到自定义分区类,排序比较类(sort comparator),分组比较类(grouping comparator)。这些是实现次排序的基础。
讨论
在这个技术中,使用次排序来对人的名字进行排序。具体步骤是:先用主排序对人的姓排序,再用次排序对人的名字排序。
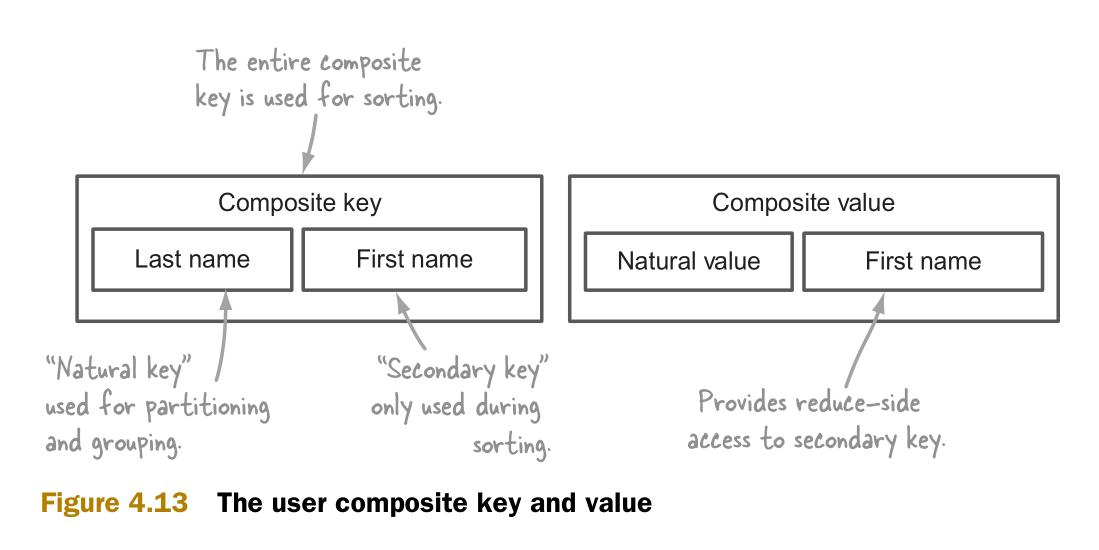
次排序需要在map函数中生成组合键(composite key)作为输出键。
组合输出键包括两个部分:
- 自然键,用于连接。
- 次键(secondary key),用于对隶属于自然键的值进行排序。排序后的结果将被发送给reduce。
图4.13说明了组合键的构成。它还包括了一个用于reduce端的组合值(composite value)。组合值让reduce可以访问次键。
在介绍了组合键类之后,接下来具体说明分区,排序和分组阶段以及他们的实现。
组合键(COMPOSITE KEY)
组合键包括姓氏和名字。它扩展了WritableComparable。WritableComparable被推荐用于map函数输出键的Writable类。
public class Person implements WritableComparable<Person> {
private String firstName;
private String lastName;
@Override
public void readFields(DataInput in) throws IOException {
this.firstName = in.readUTF();
this.lastName = in.readUTF();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(firstName);
out.writeUTF(lastName);
}
...
图4.14说明了分区,排序和分组的类的名字和方法的设置。同时还有各个类如何使用组合键。

接下来是对其它类的实现代码的介绍。
分区器(PARTITIONER)
分区器用来决定map的输出值应该分配到哪个reduce。MapReduce的默认分区器(HashPartitioner)调用输出键的hashCode方法,然后用hashCode方法的结果对reduce的数量进行一个模数(modulo)运算,最后得到那个目标reduce。默认的分区器使用整个键。这就不适于组合键了。因为它可能把有同样自然键的组合键发送给不同的reduce。因此,就需要自定义分区器,基于自然键进行分区。
以下代码实现了分区器的接口。getPartition方法的输入参数有key,value和分区的数量:
public interface Partitioner<K2, V2> extends JobConfigurable {
int getPartition(K2 key, V2 value, int numPartitions);
}
自定义的分区器将基于Person类中的姓计算哈希值,然后将这个哈希值对分区的数量进行模运算。在这里,分区的数量就是reduce的数量:
public class PersonNamePartitioner extends Partitioner<Person, Text> {
@Override
public int getPartition(Person key, Text value, int numPartitions) {
return Math.abs(key.getLastName().hashCode() * ) % numPartitions;
}
}
排序(SORTING)
Map端和reduce端都要进行排序。Map端排序的目的是让reduce端的排序更加高效。这里将让MapReduce使用组合键的所有值进行排序,也就是基于姓氏和名字。
在下列例子中实现了WritableComparator。WritableComparator比较用户的姓氏和名字。
public class PersonComparator extends WritableComparator {
protected PersonComparator() {
super(Person.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
Person p1 = (Person) w1;
Person p2 = (Person) w2;
int cmp = p1.getLastName().compareTo(p2.getLastName());
if (cmp != 0) {
return cmp;
}
return p1.getFirstName().compareTo(p2.getFirstName());
}
}
分组(GROUPING)
当reduce阶段将在本地磁盘上的map输出的记录进行流化处理(streaming)的时候,需要要进行分组。在分组中,记录将被按一定方式排成一个有逻辑顺序的流,并被传输给reduce。
在分组阶段,所有的记录已经经过了次排序。分组比较器需要将有相同姓氏的记录分在同一个组。下面是分组比较器的实现:
public class PersonNameComparator extends WritableComparator {
protected PersonNameComparator() {
super(Person.class, true);
}
@Override
public int compare(WritableComparable o1, WritableComparable o2) {
Person p1 = (Person) o1;
Person p2 = (Person) o2;
return p1.getLastName().compareTo(p2.getLastName());
}
}
MAPREDUCE
最后一步是告诉MapReduce使用自定义的分区器类,排序比较器类和分组比较器类:
job.setPartitionerClass(PersonNamePartitioner.class);
job.setSortComparatorClass(PersonComparator.class);
job.setGroupingComparatorClass(PersonNameComparator.class);
然后需要实现map和reduce代码。Map类创建具有姓和名的组合键,然后将它作为输出键。将名字作为输出值。
Reduce类的输出和输入一样:
public static class Map extends Mapper<Text, Text, Person, Text> {
private Person outputKey = new Person();
@Override
protected void map(Text lastName, Text firstName, Context context)
throws IOException, InterruptedException {
outputKey.set(lastName.toString(), firstName.toString());
context.write(outputKey, firstName);
}
}
public static class Reduce extends Reducer<Person, Text, Text, Text> {
Text lastName = new Text();
@Override
public void reduce(Person key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
lastName.set(key.getLastName());
for (Text firstName : values) {
context.write(lastName, firstName);
}
}
}
上传一个包含了乱序的名字的小文件,并测试次排序是否能够生成已经根据名字排序好的结果:
$ hadoop fs -put test-data/ch4/usernames.txt . $ hadoop fs -cat usernames.txt
Smith John
Smith Anne
Smith Ken $ bin/run.sh com.manning.hip.ch4.sort.secondary.SortMapReduce usernames.txt output $ hadoop fs -cat output/part*
Smith Anne
Smith John
Smith Ken
上面的结果和期望一致。
小结
这一节展示了MapReduce中如何使用次排序。下一部分介绍如何将多个reduce的结果做总体排序。
[大牛翻译系列]Hadoop(5)MapReduce 排序:次排序(Secondary sort)的更多相关文章
- [大牛翻译系列]Hadoop(16)MapReduce 性能调优:优化数据序列化
6.4.6 优化数据序列化 如何存储和传输数据对性能有很大的影响.在这部分将介绍数据序列化的最佳实践,从Hadoop中榨出最大的性能. 压缩压缩是Hadoop优化的重要部分.通过压缩可以减少作业输出数 ...
- [大牛翻译系列]Hadoop(1)MapReduce 连接:重分区连接(Repartition join)
4.1 连接(Join) 连接是关系运算,可以用于合并关系(relation).对于数据库中的表连接操作,可能已经广为人知了.在MapReduce中,连接可以用于合并两个或多个数据集.例如,用户基本信 ...
- [大牛翻译系列]Hadoop(4)MapReduce 连接:选择最佳连接策略
4.1.4 为你的数据选择最佳连接策略 已介绍的每个连接策略都有不同的优点和缺点.那么,怎么来判断哪个最适合待处理的数据? 图4.11给出了一个决策树.这个决策树是于论文<A Compariso ...
- [大牛翻译系列]Hadoop 翻译文章索引
原书章节 原书章节题目 翻译文章序号 翻译文章题目 链接 4.1 Joining Hadoop(1) MapReduce 连接:重分区连接(Repartition join) http://www.c ...
- [大牛翻译系列]Hadoop(13)MapReduce 性能调优:优化洗牌(shuffle)和排序阶段
6.4.3 优化洗牌(shuffle)和排序阶段 洗牌和排序阶段都很耗费资源.洗牌需要在map和reduce任务之间传输数据,会导致过大的网络消耗.排序和合并操作的消耗也是很显著的.这一节将介绍一系列 ...
- [大牛翻译系列]Hadoop(6)MapReduce 排序:总排序(Total order sorting)
4.2.2 总排序(Total order sorting) 有的时候需要将作业的的所有输出进行总排序,使各个输出之间的结果是有序的.有以下实例: 如果要得到某个网站中最受欢迎的网址(URL),就需要 ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- [大牛翻译系列]Hadoop(3)MapReduce 连接:半连接(Semi-join)
4.1.3 半连接(Semi-join) 假设一个场景,需要连接两个很大的数据集,例如,用户日志和OLTP的用户数据.任何一个数据集都不是足够小到可以缓存在map作业的内存中.这样看来,似乎就不能使用 ...
随机推荐
- python 逻辑运算符与比较运算符的差别
文章内容摘自:http://www.cnblogs.com/vamei/archive/2012/05/29/2524376.html 逻辑运算符 and, or, not 比较运算符 ==, !=, ...
- sizeclass
横竖9种组合,代表所有大小屏幕,在storyboard中可以把contrans与不同组合绑定,也就是说,可能横向有多一个约束,纵向就没了... 实现不同屏幕不同约束,这应该是sizeclass 的存在 ...
- EOF 与 getchar()
1.EOF EOF是end of file的缩写,表示"文字流"(stream)的结尾.这里的"文字流",可以是文件(file),也可以是标准输入(stdin) ...
- oracle 11g 添加控制文件
OS: Oracle Linux Server release 5.7 DB: Oracle Database 11g Enterprise Edition Release 11.2.0.3.0 - ...
- C# ArrayList的用法总结
C# ArrayList的用法总结 System.Collections.ArrayList类是一个特殊的数组.通过添加和删除元素,就可以动态改变数组的长度. 一.优点 1. 支持自动改变大小的功能 ...
- hdu 4857 逃生
题目连接 http://acm.hdu.edu.cn/showproblem.php?pid=4857 逃生 Description 糟糕的事情发生啦,现在大家都忙着逃命.但是逃命的通道很窄,大家只能 ...
- Swift学习初步(一)
前几天刚刚将有关oc的教程草草的看了一遍,发现oc其实也不像传说的那么难.今天又开始马不停蹄的学习Swift因为我很好奇,到底苹果出的而且想要代替oc的编程语言应该是个什么样子呢?看了网上的一些中文教 ...
- Windows Phone动画
从事Windows Phone开发已经有一段时间了,但是一直没有好好的静下心来梳理一下自己这段时间的知识,一是怕自己学问不到家,写不出那些大牛一般的高屋建瓴:二是以 前一直没有写博客的习惯:好了废话不 ...
- 黑客群体的露面说明互联网公司开始回馈IT行业了,
揭开中国黑客群体的神秘面纱 年薪数百万 2015-04-26 09:59:45 15259 次阅读 14 次推荐 稿源:经济观察报 33 条评论 在网络世界有专属的代号,那里才是他们最习惯的“世界 ...
- golang:slice陷阱
slice陷阱,slice底层指向某个array,在赋值后容易导致array长期被引用而无法释放