数据库事务隔离级ORACLE数据库事务隔离级别介绍
本文系转载,原文地址:http://singo107.iteye.com/blog/1175084
数据库事务的隔离级别有4个,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏读、不可重复读、幻读这几类问题。
√: 可能出现 ×: 不会出现
| 脏读 | 不可重复读 | 幻读 | |
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable read | × | × | √ |
| Serializable | × | × | × |
注意:我们讨论隔离级别的场景,主要是在多个事务并发的情况下,因此,接下来的讲解都围绕事务并发。
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有2000元,singo空欢喜一场。

出现上述情况,即我们所说的脏读,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为何......
出现上述情况,即我们所说的不可重复读,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
当隔离级别设置为Repeatable read时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额(select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出现了幻觉,幻读就这样产生了。
注:MySQL的默认隔离级别就是Repeatable read。
Serializable 序列化
Serializable是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
本文系转载,原文地址:http://blog.csdn.NET/w_l_j/article/details/7354530
- 对于同时运行的多个事务, 当这些事务访问数据库中相同的数据时, 如果没有采取必要的隔离机制, 就会导致各种并发问题:
- • 脏读: 对于两个事物 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
- • 不可重复读: 对于两个事物 T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
- • 幻读: 对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
- 数据库事务的隔离性: 数据库系统必须具有隔离并发运行各个事务的能力, 使它们不会相互影响, 避免各种并发问题.
- 一个事务与其他事务隔离的程度称为隔离级别. 数据库规定了多种事务隔离级别, 不同隔离级别对应不同的干扰程度, 隔离级别越高, 数据一致性就越好, 但并发性越弱
- 数据库提供了4中隔离级别:
- 隔离级别 描述
- READ UNCOMMITTED(读未提交数据) 允许事务读取未被其他事务提交的变更,脏读、不可重复读和幻读的问题都会出现
- READ COMMITED(读已提交数据) 只允许事务读取已经被其他事务提交的变更,可以避免脏读,但不可重复读和幻读问题仍然会出现
- REPEATABLE READ(可重复读) 确保事务可以多次从一个字段中读取相同的值,在这个事务持续期间,禁止其他事务对这个字段进行更新,可以避免脏读和不可重复读,但幻读的问题依然存在
- SERIALIZABLE(串行化) 确保事务可以从一个表中读取相同的行,在这个事务持续期间,禁止其他事务对该表执行插入、更新和删除操作,所有并发问题都可以避免,但性能十分低
- Oracle 支持的 2 种事务隔离级别:READ COMMITED, SERIALIZABLE. Oracle 默认的事务隔离级别为: READ COMMITED
- Mysql 支持 4 中事务隔离级别. Mysql 默认的事务隔离级别为: REPEATABLE READ
本文系转载,原文地址:http://baike.baidu.com/link?url=ECqk10IwUnE8JxHPn-qyzNsqT1XgkD6P3td71Wj3HUT-lWoJ76uU-9hSKtSuCNwp7w56IbIcQ0J00__Qn0z9ra
事务隔离级别编辑
1定义编辑
2问题的提出编辑
更新丢失
脏读
不可重复读
3解决方案编辑
未授权读取
授权读取
可重复读取(Repeatable Read)
序列化(Serializable)
ORACLE数据库事务隔离级别介绍
两个并发事务同时访问数据库表相同的行时,可能存在以下三个问题:
1、幻想读:事务T1读取一条指定where条件的语句,返回结果集。此时事务T2插入一行新记录,恰好满足T1的where条件。然后T1使用相同的条件再次查询,结果集中可以看到T2插入的记录,这条新纪录就是幻想。
2、不可重复读取:事务T1读取一行记录,紧接着事务T2修改了T1刚刚读取的记录,然后T1再次查询,发现与第一次读取的记录不同,这称为不可重复读。
3、脏读:事务T1更新了一行记录,还未提交所做的修改,这个T2读取了更新后的数据,然后T1执行回滚操作,取消刚才的修改,所以T2所读取的行就无效,也就是脏数据。
一、为了处理这些问题,SQL标准定义了以下几种事务隔离级别:
READ UNCOMMITTED 幻想读、不可重复读和脏读都允许。一个会话可以读取其他事务未提交的更新结果,如果这个事务最后以回滚结束,这时的读取结果就可能是不正确的,所以多数的数据库都不会运用这种隔离级别。
READ COMMITTED 允许幻想读、不可重复读,不允许脏读。一个会话只能读取其他事务已提交的更新结果,否则,发生等待,但是其他会话可以修改这个事务中被读取的记录,而不必等待事务结束,显然,在这种隔离级别下,一个事务中的两个相同的读取操作,其结果可能不同。
REPEATABLE READ 允许幻想读,不允许不可重复读和脏读。在一个事务中,如果在两次相同条件的读取操作之间没有添加记录的操作,也没有其他更新操作导致在这个查询条件下记录数增多,则两次读取结果相同。换句话说,就是在一个事务中第一次读取的记录保证不会在这个事务期间发生改动。SQL Server是通过在整个事务期间给读取的记录加锁实现这种隔离级别的,这样,在这个事务结束前,其他会话不能修改事务中读取的记录,而只能等待事务结束,但是SQL Server不会阻碍其他会话向表中添加记录,也不阻碍其他会话修改其他记录。
SERIALIZABLE 幻想读、不可重复读和脏读都不允许。在一个事务中,读取操作的结果是在这个事务开始之前其他事务就已经提交的记录,SQL Server通过在整个事务期间给表加锁实现这种隔离级别。在这种隔离级别下,对这个表的所有DML操作都是不允许的,即要等待事务结束,这样就保证了在一个事务中的两次读取操作的结果肯定是相同的。SQL标准所定义的默认事务隔离级别是SERIALIZABLE。
二、Oracle中的隔离级别及实现机制:
Oracle数据库支持READ COMMITTED 和 SERIALIZABLE这两种事务隔离级别。所以Oracle不支持脏读,即Oracle中不允许一个会话读取其他事务未提交的数据修改结果,从而防止了由于事务回滚发生的读取不正确。
Oracle回滚段,在修改数据记录时,会把这些记录被修改之前的结果存入回滚段或撤销段中。Oracle读取操作不会阻碍更新操作,更新操作也不会阻碍读取操作,这样在Oracle中的各种隔离级别下,读取操作都不会等待更新事务结束,更新操作也不会因为另一个事务中的读取操作而发生等待,这也是Oracle事务处理的一个优势所在。
Oracle缺省的配置是Read Committed隔离级别(也称为语句级别的隔离),在这种隔离级别下,如果一个事务正在对某个表执行 DML操作,而这时另外一个会话对这个表的记录执行读取操作,则Oracle会去读取回滚段或撤销段中存放的更新之前的记录,而不会象SQL Server一样等待更新事务的结束。
Oracle的Serializable隔离级别(也称为事务级别的隔离),事务中的读取操作只能读取这个事务开始之前已经提交的数据结果。如果在读取时,其他事务正在对记录执行修改,则Oracle就会在回滚段或撤销段中去寻找对应的原来未经修改的记录(而且是在读取操作所在的事务开始之前存放于回滚段或撤销段的记录),这时读取操作也不会因为相应记录被更新而等待。
设置隔离级别使用 SET TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
下面是oracle 设置SERIALIZABLE隔离级别一个示例:
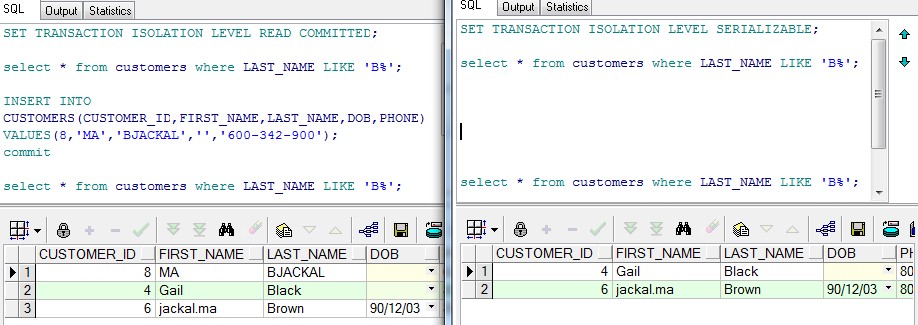
左面是事务T1,右面是事务T2,因为T2级别为SERIALIZABLE,所以即使事务T1在提交了数据之后,事务T2还是看不到T1提交的数据,幻想读和不可重复读都不允许了。
那如何能查看到T1新增的记录呢? 上面T1和T2是并发执行,在T1执行insert的时候事务T2已经开始了,因为T2级别是SERIALIZABLE,所以T2所查询的数据集是T2事务开始前数据库的数据。即事务T1在事务T2开始之后的insert和update操作的影响都不会影响事务T2。现在重新开启一个事务T3 就可以看到T1新增的记录了。
当下列事件发生时,事务就开始了:
1、连接到数据库,并执行第一条DML语句
2、前一个事务结束后,又输入了另一条DML语句
两个并发事务同时访问数据库表相同的行时,可能存在以下三个问题:
1、幻想读:事务T1读取一条指定where条件的语句,返回结果集。此时事务T2插入一行新记录,恰好满足T1的where条件。然后T1使用相同的条件再次查询,结果集中可以看到T2插入的记录,这条新纪录就是幻想。
2、不可重复读取:事务T1读取一行记录,紧接着事务T2修改了T1刚刚读取的记录,然后T1再次查询,发现与第一次读取的记录不同,这称为不可重复读。
3、脏读:事务T1更新了一行记录,还未提交所做的修改,这个T2读取了更新后的数据,然后T1执行回滚操作,取消刚才的修改,所以T2所读取的行就无效,也就是脏数据。
一、为了处理这些问题,SQL标准定义了以下几种事务隔离级别:
READ UNCOMMITTED 幻想读、不可重复读和脏读都允许。一个会话可以读取其他事务未提交的更新结果,如果这个事务最后以回滚结束,这时的读取结果就可能是不正确的,所以多数的数据库都不会运用这种隔离级别。
READ COMMITTED 允许幻想读、不可重复读,不允许脏读。一个会话只能读取其他事务已提交的更新结果,否则,发生等待,但是其他会话可以修改这个事务中被读取的记录,而不必等待事务结束,显然,在这种隔离级别下,一个事务中的两个相同的读取操作,其结果可能不同。
REPEATABLE READ 允许幻想读,不允许不可重复读和脏读。在一个事务中,如果在两次相同条件的读取操作之间没有添加记录的操作,也没有其他更新操作导致在这个查询条件下记录数增多,则两次读取结果相同。换句话说,就是在一个事务中第一次读取的记录保证不会在这个事务期间发生改动。SQL Server是通过在整个事务期间给读取的记录加锁实现这种隔离级别的,这样,在这个事务结束前,其他会话不能修改事务中读取的记录,而只能等待事务结束,但是SQL Server不会阻碍其他会话向表中添加记录,也不阻碍其他会话修改其他记录。
SERIALIZABLE 幻想读、不可重复读和脏读都不允许。在一个事务中,读取操作的结果是在这个事务开始之前其他事务就已经提交的记录,SQL Server通过在整个事务期间给表加锁实现这种隔离级别。在这种隔离级别下,对这个表的所有DML操作都是不允许的,即要等待事务结束,这样就保证了在一个事务中的两次读取操作的结果肯定是相同的。SQL标准所定义的默认事务隔离级别是SERIALIZABLE。
二、Oracle中的隔离级别及实现机制:
Oracle数据库支持READ COMMITTED 和 SERIALIZABLE这两种事务隔离级别。所以Oracle不支持脏读,即Oracle中不允许一个会话读取其他事务未提交的数据修改结果,从而防止了由于事务回滚发生的读取不正确。
Oracle回滚段,在修改数据记录时,会把这些记录被修改之前的结果存入回滚段或撤销段中。Oracle读取操作不会阻碍更新操作,更新操作也不会阻碍读取操作,这样在Oracle中的各种隔离级别下,读取操作都不会等待更新事务结束,更新操作也不会因为另一个事务中的读取操作而发生等待,这也是Oracle事务处理的一个优势所在。
Oracle缺省的配置是Read Committed隔离级别(也称为语句级别的隔离),在这种隔离级别下,如果一个事务正在对某个表执行 DML操作,而这时另外一个会话对这个表的记录执行读取操作,则Oracle会去读取回滚段或撤销段中存放的更新之前的记录,而不会象SQL Server一样等待更新事务的结束。
Oracle的Serializable隔离级别(也称为事务级别的隔离),事务中的读取操作只能读取这个事务开始之前已经提交的数据结果。如果在读取时,其他事务正在对记录执行修改,则Oracle就会在回滚段或撤销段中去寻找对应的原来未经修改的记录(而且是在读取操作所在的事务开始之前存放于回滚段或撤销段的记录),这时读取操作也不会因为相应记录被更新而等待。
设置隔离级别使用 SET TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTED|REPEATABLE READ|SERIALIZABLE]
下面是oracle 设置SERIALIZABLE隔离级别一个示例:
左面是事务T1,右面是事务T2,因为T2级别为SERIALIZABLE,所以即使事务T1在提交了数据之后,事务T2还是看不到T1提交的数据,幻想读和不可重复读都不允许了。
那如何能查看到T1新增的记录呢? 上面T1和T2是并发执行,在T1执行insert的时候事务T2已经开始了,因为T2级别是SERIALIZABLE,所以T2所查询的数据集是T2事务开始前数据库的数据。即事务T1在事务T2开始之后的insert和update操作的影响都不会影响事务T2。现在重新开启一个事务T3 就可以看到T1新增的记录了。
当下列事件发生时,事务就开始了:
1、连接到数据库,并执行第一条DML语句
2、前一个事务结束后,又输入了另一条DML语句
http://blog.csdn.Net/jialinqiang/article/details/8723044
1.数据库事务的概念:
•事务是指一组相互依赖的操作行为,如银行交易、股票交易或网上购物。事务的成功取决于这些相互依赖的操作行为是否都能执行成功,只要有一个操作行为失败,就意味着整个事务失败。例如,Tom到银行办理转账事务,把100元钱转到Jack的账号上,这个事务包含以下操作行为:
–(1)从Tom的账户上减去100元。
–(2)往Jack的账户上增加100元。
•显然,以上两个操作必须作为一个不可分割的工作单元。假如仅仅第一步操作执行成功,使得Tom的账户上扣除了100元,但是第二步操作执行失败,Jack的账户上没有增加100元,那么整个事务失败。
•数据库事务是对现实生活中事务的模拟,它由一组在业务逻辑上相互依赖的SQL语句组成。
2.数据库事务的生命周期:

3.声明事务的边界:
•事务的开始边界。
•事务的正常结束边界(COMMIT):提交事务,永久保存被事务更新后的数据库状态。
•事务的异常结束边界(ROLLBACK):撤销事务,使数据库退回到执行事务前的初始状态。
(1).在mysql.exe中声明事务:
•每启动一个mysql.exe程序,就会得到一个单独的数据库连接。每个数据库连接都有个全局变量@@autocommit,表示当前的事务模式,它有两个可选值:
–0:表示手工提交模式。
–1:默认值,表示自动提交模式。
•如果要察看当前的事务模式,可使用如下SQL命令:
–mysql> select @@autocommit
•如果要把当前的事务模式改为手工提交模式,可使用如下SQL命令:
–mysql> set autocommit=0;
——在自动提交模式下提交事务:
•在自动提交模式下,每个SQL语句都是一个独立的事务。如果在一个mysql.exe程序中执行SQL语句:
–mysql>insert into ACCOUNTS values(1,'Tom',1000);
•MySQL会自动提交这个事务,这意味着向ACCOUNTS表中新插入的记录会永久保存在数据库中。此时在另一个mysql.exe程序中执行SQL语句:
–mysql>select * from ACCOUNTS;
•这条select语句会查询到ID为1的ACCOUNTS记录。这表明在第一个mysql.exe程序中插入的ACCOUNTS记录被永久保存,这体现了事务的ACID特性中的持久性。
——在手工模式下提交事务:
•在手工提交模式下,必须显式指定事务开始边界和结束边界:
–事务的开始边界:begin
–提交事务:commit
–撤销事务:rollback
例:
–mysql>begin;
–mysql>select * from ACCOUNTS;
–mysql>commit;
(2).通过JDBC API声明事务边界:
• Connection提供了以下用于控制事务的方法:
–setAutoCommit(boolean autoCommit):设置是否自动提交事务
–commit():提交事务
–rollback():撤销事务
例:
try {
con = Java.sql.DriverManager.getConnection(dbUrl,dbUser,dbPwd);
//设置手工提交事务模式
con.setAutoCommit(false);
stmt = con.createStatement();
//数据库更新操作1
stmt.executeUpdate("update ACCOUNTS set BALANCE=900 where ID=1 ");
//数据库更新操作2
stmt.executeUpdate("update ACCOUNTS set BALANCE=1000 where ID=2 ");
con.commit(); //提交事务
}catch(Exception e) {
try{
con.rollback(); //操作不成功则撤销事务
}catch(Exception ex){
//处理异常
……
}
//处理异常
……
}finally{…}
(3).通过hibernate API声明事务边界:
•声明事务的开始边界:Transaction tx=session.beginTransaction();
•提交事务: tx.commit();
•撤销事务: tx.rollback();
4.多个事务并发时的并发问题:
•第一类丢失更新:撤销一个事务时,把其他事务已提交的更新数据覆盖。
•脏读:一个事务读到另一事务未提交的更新数据。
•虚读:一个事务读到另一事务已提交的新插入的数据。
•不可重复读:一个事务读到另一事务已提交的更新数据。
•第二类丢失更新:这是不可重复读中的特例,一个事务覆盖另一事务已提交的更新数据。
以取款事务和支票转账事务例:
•取款事务包含以下步骤:
–(1)某银行客户在银行前台请求取款100元,出纳员先查询账户信息,得知存款余额为1000元。
–(2)出纳员判断出存款额超过了取款额,就支付给客户100元,并将账户上的存款余额改为900元。
•支票转账事务包含以下步骤:
–(1)某出纳员处理一转帐支票,该支票向一帐户汇入100元。出纳员先查询账户信息,得知存款余额为900元。
–(2)出纳员将存款余额改为1000元。
并发运行的两个事务导致脏读:

取款事务在T5时刻把存款余额改为900元,支票转账事务在T6时刻查询账户的存款余额为900元,取款事务在T7时刻被撤销,支票转账事务在T8时刻把存款余额改为1000元。
由于支票转账事务查询到了取款事务未提交的更新数据,并且在这个查询结果的基础上进行更新操作,如果取款事务最后被撤销,会导致银行客户损失100元。
并发运行的两个事务导致第二类更新丢失:

取款事务在T5时刻根据在T3时刻的查询结果,把存款余额改为1000-100元,在T6时刻提交事务。支票转账事务在T7时刻根据在T4时刻的查询结果,把存款余额改为1000+100
元。由于支票转账事务覆盖了取款事务对存款余额所做的更新,导致银行最后损失100元。
5.数据库的隔离级别:

(1).隔离级别与并发性能的关系:

(2).设置隔离级别的原则:
•隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
•对于多数应用程序,可以优先考虑把数据库系统的隔离级别设为Read Committed,它能够避免脏读,而且具有较好的并发性能。尽管它会导致不可重复读、虚读
和第二类丢失更新这些并发问题,在可能出现这类问题的个别场合,可以由应用程序采用悲观锁或乐观锁来控制。
(3)在mysql.exe程序中中设置隔离级别:
•每启动一个mysql.exe程序,就会获得一个单独的数据库连接。每个数据库连接都有个全局变量@@tx_isolation,表示当前的事务隔离级别。MySQL默认的隔离
级别为Repeatable Read。如果要察看当前的隔离级别,可使用如下SQL命令:
–mysql> select @@tx_isolation;
•如果要把当前mysql.exe程序的隔离级别改为Read Committed,可使用如下SQL命令:
–mysql> set transaction isolation level read committed;
(4)在Hibernate中设置隔离级别:
•在Hibernate的配置文件中可以显式的设置隔离级别。每一种隔离级别都对应一个整数:
–1:Read Uncommitted
–2:Read Committed
–4:Repeatable Read
–8:Serializable
•例如,以下代码把hibernate.cfg.xml文件中的隔离级别设为Read Committed:
hibernate.connection.isolation=2
对于从数据库连接池中获得的每个连接,Hibernate都会把它改为使用Read Committed隔离级别。
数据库事务隔离级ORACLE数据库事务隔离级别介绍的更多相关文章
- 数据库的特性与隔离级别和spring事务的传播机制和隔离级别
首先数据库的特性就是 ACID: Atomicity 原子性:所有事务是一个整体,要么全部成功,要么失败 Consistency 一致性:在事务开始和结束前,要保持一致性状态 Isolation 隔离 ...
- 数据库事务 ACID属性、数据库并发问题和四种隔离级别
数据库事务 ACID属性.数据库并发问题和四种隔离级别 数据库事务 数据库事务是一组逻辑操作单元,使数据从一种状态变换到另一种状态 一组逻辑操作单元:一个或多个DML操作 事务处理原则 保证所有事务都 ...
- spring 中常用的两种事务配置方式以及事务的传播性、隔离级别
一.注解式事务 1.注解式事务在平时的开发中使用的挺多,工作的两个公司中看到很多项目使用了这种方式,下面看看具体的配置demo. 2.事务配置实例 (1).spring+mybatis 事务配置 &l ...
- 理解 spring 事务传播行为与数据隔离级别
事务,是为了保障逻辑处理的原子性.一致性.隔离性.永久性. 通过事务控制,可以避免因为逻辑处理失败而导致产生脏数据等等一系列的问题. 事务有两个重要特性: 事务的传播行为 数据隔离级别 1.事务传播行 ...
- springboot事务的传播行为和隔离级别
springboot事务的传播行为和隔离级别 在springboot中事务的传播行为和隔离级别都是在TransactionDefinition这个接口中定义的 传播行为定义了7种,分别用0-6来表示 ...
- spring 事务配置方式以及事务的传播性、隔离级别
在前面的文章中总结了spring事务的5中配置方式,但是很多方式都不用而且当时的配置使用的所有参数都是默认的参数,这篇文章就看常用的两种事务配置方式并信息配置事务的传播性.隔离级别.以及超时等问题,废 ...
- 一天五道Java面试题----第七天(mysql索引结构,各自的优劣--------->事务的基本特性和隔离级别)
这里是参考B站上的大佬做的面试题笔记.大家也可以去看视频讲解!!! 文章目录 1 .mysql索引结构,各自的优劣 2 .索引的设计原则 3 .mysql锁的类型有哪些 4 .mysql执行计划怎么看 ...
- SQL Server与Oracle中的隔离级别
在SQL92标准中,事务隔离级别分为四种,分别为:Read Uncommitted.Read Committed.Read Repeatable.Serializable 其中Read Uncommi ...
- 在mysql数据库中创建Oracle数据库中的scott用户表
在mysql数据库中创建Oracle数据库中的scott用户表 作者:Eric 微信:loveoracle11g create table DEPT ( DEPTNO int(2) not null, ...
随机推荐
- javascript 变量声明有var与无var 的区别
1.在函数作用域内 加var定义的变量是局部变量,不加var定义的就成了全局变量.使用var定义var a = 'hello World';function bb(){var a = 'hello B ...
- access手工注入
1.判断数据类型 and exists (select * from msysobjects) >0 and exists (select * from sysobjects) >0 一般 ...
- STL 源码分析《1》---- list 归并排序的 迭代版本, 神奇的 STL list sort
最近在看 侯捷的 STL源码分析,发现了以下的这个list 排序算法,乍眼看去,实在难以看出它是归并排序. 平常大家写归并排序,通常写的是 递归版本..为了效率的考虑,STL库 给出了如下的 归并排序 ...
- 在国内时,更新ADT时需要配置的
RT
- ERP存储过程的调用和树形菜单的加载(四)
引用:DAL:System.Data.SqlClient;System.Data; namespace CommTool { public class SqlComm { /// <summar ...
- MongoDB索引、聚合
用$where可以执行任意的js作为查询的一部分. db.foo.find({"$where" : function(){ for(var current in ...
- 通过一段代码说明C#中rel与out的使用区别
using System; public partial class testref : System.Web.UI.Page { static void outTest(out int x, out ...
- .csproj文件的配置 IIS可以调试
<ProjectExtensions> <VisualStudio> <FlavorProperties GUID="{349c5851-65df-11da-9 ...
- 用NSOperation和NSOperationQueue实现多线程编程
1.上一讲简单介绍了NSThread的使用,虽然也可以实现多线程编程,但是需要我们去管理线程的生命周期,还要考虑线程同步.加锁问题,造成一些性能上的开销.我们也可以配合使用NSOperation和NS ...
- 【题解】【BT】【Leetcode】Binary Tree Level Order Traversal
Given a binary tree, return the level order traversal of its nodes' values. (ie, from left to right, ...