day6_7.4总结数据类型的可变不可变
续昨天:
列表的常用方法:
1.chear()
用途:清空列表,其返回值无,返回none。
list1=[1,2,3,4,5]
a=list1.clear()
print(list1)
print(a)
#输出结果>>>[]
# None
2.reverse()
用途:将列表反转。
list1=[1,2,3,4,5]
list1.reverse()
print(list1)
#输出结果>>>[5, 4, 3, 2, 1]
3.sort()
用途:在默认情况下,从小到大排序。当改变函数参数为reverse=true时,会从大到小排序。
l1 = [43,6,1,7,99]
l1.sort(reverse=True)
print(l1)
l1.sort()
print(l1)
#输出结果>>>[99, 43, 7, 6, 1]
#[1, 6, 7, 43, 99]
4.队列
队列是数据类型的一种,其显著特点是先进先出,这里用列表实现其数据存储模式
l1 = []
# 先进
l1.append('first')
l1.append('second')
l1.append('third')
# 先出
print(l1.pop(0))
print(l1.pop(0))
print(l1.pop(0))
#输出结果>>>first
#second
#third
5.栈
栈的存储方式是先进后出,它与队列相反
# 先进
l1.append('first')
l1.append('second')
l1.append('third')
# 后出
print(l1.pop())
print(l1.pop())
print(l1.pop())
#输出结果>>>third
#second
#first
二.元组(tuple)
用途:元组能够存储多个数据类型和多个数据,它们之间需要用逗号隔开,由于它在定义单个元素时容易与整型搞混,所以在定义时需要在后面加逗号。
a=tuple((1))
当执行以上代码时,结果会报错,是因为(1)既可以是元组,也可以是带有括号的整型1,而系统默认的是后者,所以在定义任何单个的元组时,需要加上逗号区分
a=tuple((1,))
print(type(a))
#输出结果>>><class 'tuple'>
元组与其他数据类型不同的时元组不支持改变,即不可删除与添加元素,而且它时不可变数据类型。
1.索引
tuple1=(1,2,3,4,5,6)
for i in range(0,6):
print(tuple1[i])
#输出结果>>>1 2 3 4 5 6
2.切片
tuple1=(1,2,3,4,5,6)
tuple2=tuple1[0:4:2]
tuple3=tuple1[0:4]
print(tuple2,tuple3)
#输出结果>>>(1, 3) (1, 2, 3, 4)
3.长度
tuple1=(1,2,3,4,5,6)
print(len(tuple1))
#输出结果>>>6
4.成员运算
tuple1=(1,2,3,4,5,6)
print(1 in tuple1)
print(7 in tuple1)
#输出结果>>>True
#False
5.循环
tuple1=(1,2,3,4,5,6)
for i in tuple1:
print(i)
#输出结果>>>1,2,3,4,5,6
一些内置方法
1.count
用途:输出其中的元素在元组中有多少个。
tuple1=(1,2,3,4,5,6)
print(tuple1.count(2))
#输出结果>>>1
2.index
用途:检索某个值在元组中的位置,返还其位置信息,若没有这个值则报错。
tuple1=(1,2,3,4,100,6)
print(tuple1.index(100))
#输出结果>>>4
三.字典
作用:能存储多组key:value键值对
key是对value的描述
key只能是不可变类型。
value可以是任何数据类型。
定义:
在定义是key值不能是重复的,如果重复定义会将前面的覆盖。(*******)
d2 = {'name':'jason','name':'tank','name':'nick','password':123}
#输出结果>>>{'name': 'nick', 'password': 123}
定义方法3
l = [
['name','jason'],
['age',18],
['hobby','read']
]
d3 = dict(l)
优先掌握操作
1.按key取值,可存可取
d3 = {'name':'jason','password':''}
print(d3['name'])
d3['name']='egon'
print(d3['name'])
#输出结果>>>jason
#egon
当键值不存在时,会将其作为新的键值添加。(*********)
d3 = {'name':'jason','password':''}
d3['age']=123
print(d3)
#输出结果>>>
#{'name': 'jason', 'password': '123', 'age': 123}
2.len()取出长度
d3 = {'name':'jason','password':''}
print(len(d3))
#输出结果>>>2
3.成员运算in,not in
判断字典中是否有某个key值,这里只能判断有没有key值,不能判断有没有value
d3 = {'name':'jason','password':''}
print('jason' in d3)
print('name' in d3)
#输出结果>>>False
#True
4.删除
1.可以直接引用del
2.可以用pop()弹出,但弹出的值仅仅是value
3.可以pop()中传出的key值没有找到,则会报错
d3 = {'name':'jason','password':''}
res=d3.pop('name')
print(res)
res1=d3.pop('age')#报错
#输出结果>>>jason
4.keys(),values(),item()
d3 = {'name':'jason','password':''}
print(d3.keys(),type(d3.keys()))
print(d3.values(),type(d3.values()))
print(d3.items(),type(d3.items()))
#输出结果>>>
#dict_keys(['name', 'password']) <class 'dict_keys'>
#dict_values(['jason', '123']) <class 'dict_values'>
#dict_items([('name', 'jason'), ('password', '123')]) <class 'dict_items'>
keys(),代表的是将字典中的数据以dict_keys数据类型取出其所有key值。
values(),代表将字典中的数据以dict_values的数据类型取出其所有的value值。
items(),代表的是将字典转化成列表加元组的形式,即dict_items的数据类型。
5.get()
用途:根据key值取value值(*****)
当get函数没有找到所输入的key值的value值时,会返回none值,
get可以设置第二参数,其代表当key没有找到时会返回第二个参数的信息。
d3 = {'name':'jason','password':''}
print(d3.get('name'))
print(d3.get('age'))
a=d3.get('age',['qwe','qwe'])
print(a)
#输出结果>>>jason
#None
#['qwe', 'qwe']
其中第二参数中的值可以是任意类型的数据。
6.dict.fromkeys(,)
用途:可以快速创建一个字典。
a=dict.fromkeys(['wo','ni','ta'],11)
print(a)
#输出结果>>>{'wo': 11, 'ni': 11, 'ta': 11}
可以看到使用dict.fromkeys(),创造出来的字典它的值都是第二参数所设的值,第一参数必须是列表。
7.dict.popitem()
用途:在尾部以元组的形式弹出一对键值对。
d1 = {'name':'jason','pwd':123}
print(d1.popitem()) # 尾部以元组的形式弹出键值对
print(type(d1.popitem()))
#输出结果>>>('pwd', 123)
#<class 'tuple'>
8.setdeflult()
用途:检索第一参数的key值,如果有,则输出其value值,如果没有,则将key:value添加至字典中,并返还其value值。
d1 = {'name':'jason','pwd':123}
res1=d1.setdefault('name','egon')
print(res1)
res2=d1.setdefault('age','')
print(res2)
#输出结果>>>jason
#
9.update()
用途:update(),就是将其参数更新到字典中(根据其key值),如果字典有,则更新其值,如果字典没有,将其作为新的元素添加进去。
d1 = {'name':'jason','pwd':123}
d2 = {"age":18}
d1.update(d2)
print(d1)
d1.update(age=666)
print(d1)
d1.update(pwd='sadsad')
print(d1)
#输出结果>>>
#{'name': 'jason', 'pwd': 123, 'age': 18}
#{'name': 'jason', 'pwd': 123, 'age': 666}
#{'name': 'jason', 'pwd': 'sadsad', 'age': 666}
四。集合(set)
用途:1.可用于关系运算。
2.去重。
在空集合的定义中,只能使用s=set()方法定义,如果使用{}定义的话会被系统识别为字典。
s1 = set()
print(type(s1)) # 注意在定义空集合的只能用关键字set
s2={}
print(type(s2))
#输出结果>>><class 'set'>
#<class 'dict'>
集合的三个原则:
1.每个元素必须是不可变类型。
2.没有重复的元素。如果有则会将其合并成一个。
3.无序。不可以用索引定位。
优先掌握的操作
1.长度len()
2.成员运算in not in
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(len(pythons))
print('jason' in pythons)
print('abc' not in pythons)
#输出结果>>>7
#True
#True
3.&:输出两个集合之间的交集
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(pythons&linux)
#输出结果>>>{'egon', 'tank', 'alex'}
4.‘-’从a交集中移除既在a又在b的。
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(pythons-linux)
#输出结果>>>{'nick', 'kevin', 'jason', 'owen'}
5.‘^’没有同时在两个集合里的
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(pythons^linux)
#输出结果>>>{'jerry', 'owen', 'kevin', 'jason', 'nick', 'frank'}
6.”|“两个集合之间的所有值
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(pythons|linux)
#输出结果>>>{'jerry', 'tank', 'egon', 'jason', 'alex', 'kevin', 'owen', 'frank', 'nick'}
7”==“判断两个集合是否相等(无序判断)
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
print(pythons==linux)
#输出结果>>>False
8.”>“,">="父集,a>b,判断a是否为b的父集(等同于issubset())
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
linux2={'jason', 'nick', 'tank'}
print(pythons>linux2)
print(pythons>=linux)
#输出结果>>>True
#False
9.”<“,”<=“,a<b,a是否为b的子集(等同于issuperset())
pythons = {'jason', 'nick', 'tank', 'egon', 'kevin', 'owen', 'alex'}
linux = {'frank', 'jerry', 'tank', 'egon', 'alex'}
linux2={'jason', 'nick', 'tank'}
print(linux<pythons)
print(linux2<pythons)
#输出结果>>>False
#True
10.add()添加一个元素进入集合。
set1={1,2,3,4,5,6,7}
set1.add(9)
print(set1)
set1.add(1)
print(set1)
#输出结果>>>{1, 2, 3, 4, 5, 6, 7, 9}
#{1, 2, 3, 4, 5, 6, 7, 9}
11.remove(),删除某个元素。
set1={1,2,3,4,5,6,7}
set1.remove(1)
print(set1)
#输出结果>>>{2, 3, 4, 5, 6, 7}
如果元素不存在,则报错
12.discard(),删除某个元素
set1={1,2,3,4,5,6,7}
set1.discard(1)
print(set1)
set1.discard(1)
print(set1)
#输出结果>>>{2, 3, 4, 5, 6, 7}
#{2, 3, 4, 5, 6, 7}
如果删除的元素不存在,则不会报错。
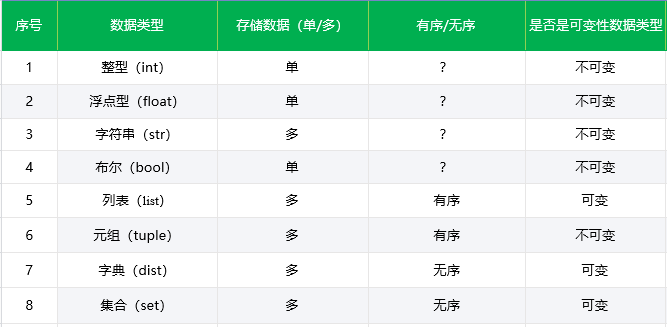
总结
一共有以下几种数据类型
整型(int),浮点型(float),字符串(str),布尔(bool),列表(list),元组(tuple),字典(dist),集合(set)
就其能存储的值的个数,可变与不可变性能,有序无序进行总结
day6_7.4总结数据类型的可变不可变的更多相关文章
- Python--基本数据类型(可变/不可变类型)
目录 Python--基本数据类型 1.整型 int 2.浮点型 float 3.字符串 str 字符串格式 字符串嵌套 4.列表 list 列表元素的下标位置 索引和切片:字符串,列表常用 5.字典 ...
- python函数参数是值传递还是引用传递(以及变量间复制后是否保持一致):取决于对象内容可变不可变
函数参数传递本质上和变量整体复制一样,只是两个变量分别为形参a和实参b.那么,a=b后,a变了,b值是否跟着变呢?这取决于对象内容可变不可变 首先解释一下,什么是python对象的内容可变不可变? p ...
- Python(可变/不可变类型,list,tuple,dict,set)
补充:(可用操作技巧) >>> x=900 >>> y=900 >>> x==y True >>> type(x) is typ ...
- 005 python 整数类型/字符串类型/列表类型/可变/不可变
可变/不可变类型 可变类型 ID不变的情况下,值改变,则称之为可变类型,如列表,字典 不可变类型 值改变,ID改变,则称之为不可变类型,如 整数 字符串,元组 整数类型 int 正整数 用途就是记录年 ...
- [Python] 可变/不可变类型 & 参数传递
与c/c++不同,Python/Java中的变量都是引用类型,没有值类型 Python赋值语句由三部分构成,例如: int a = 1 类型 标识 值 标识(identity):用于唯一标识 ...
- Java可变参数/可变长参数
Java可变参数/可变长参数 传递的参数不确定长度,是变长的参数,例如小例子: package demo; public class Demo { public static int sum(int ...
- day06 可变不可变类型
1.可变不可变类型 可变类型 定义:值改变,id不变,改的是原值 不可变类型 定义:值改变,id也变了,证明是产生了新的值没有改变原值 验证 x = 10 print(id(x)) x = 11 pr ...
- python 数据类型(元组(不可变列表),字符串
元组(不可变列表) 创建元组: ages = (11, 22, 33, 44, 55) 或 ages = tuple((11, 22, 33, 44, 55)) 一般情况下是不需要被人该的数值才使用元 ...
- Day 05 可变不可变、数据类型内置方法
1.可变类型:值改变,但是id不变,证明就是改变原值,是可变类型 2.不可变类型:值改变,但是id也跟着改变,证明是产生新的值,是不可变类型 数字类型 一.整型int 1.用途:记录年龄.等级.数量 ...
随机推荐
- GET POST 区分
get传送的数据量较小,不能大于2KB.post传送的数据量较大,一般被默认为不受限制.但理论上,IIS4中最大量为80KB,IIS5中为100KB. get安全性非常低,get设计成传输数据,一般都 ...
- MySQL 字符集与比较规则
MySQL 字符集与比较规则 由于 MySQL 客户端与服务端之间通信时需要将字符串编码传输,所以不可避免会产生编码转换 字符集 MySQL 中 utf8 就是 utf8mb3,只使用 1-3 个字节 ...
- Spring Security OAuth2学习
什么是 oAuth oAuth 协议为用户资源的授权提供了一个安全的.开放而又简易的标准.与以往的授权方式不同之处是 oAuth 的授权不会使第三方触及到用户的帐号信息(如用户名与密码),即第三方无需 ...
- 大话设计模式Python实现-建造者模式
建造者模式(Builder Pattern):将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示 下面是一个建造者模式的demo #!/usr/bin/env python # ...
- svg描边路径动画
svg描边路径动画<pre><!DOCTYPE html><html> <head> <meta charset="UTF-8" ...
- 使用Redis作为Spring Security OAuth2的token存储
写在前边 本文对Spring Security OAuth2的token使用Redis保存,相比JWT实现的token存储,Redis可以随时吊销access_token,并且Redis响应速度很快, ...
- 【LOJ#3144】[APIO2019]奇怪装置(数论)
[LOJ#3144][APIO2019]奇怪装置(数论) 题面 LOJ 题解 突然发现\(LOJ\)上有\(APIO\)的题啦,赶快来做一做. 这题是窝考场上切了的题嗷.写完暴力之后再推了推就推出正解 ...
- [IDA] Oops! internal error 40343 occured.
问题描述: 解决方案: 安装 IDA 时,其路径下不要出现中文.
- checked,unchecked
static void Main(string[] args) { byte b1 = 100; byte b2 = 250; //Checked try { byte sum = checked ( ...
- POC挖矿没有前途
最好的工作量证明是能力证明,能力不适合存储.望文生义,能力的本质意义是“能”和“力”(所有的词汇都按照望文生义理解,因为所有不能望文生义的词汇都是不良的已经被前人修正或将来被后人修正)能力是流动的,迁 ...