python爬虫3之去哪儿网
学习任务
获取去哪儿网的出发地列表
获取旅游景点列表
获取景点产品列表
存储数据
1 获取出发地站点
(1)访问touch.qunar.com
(2)按F12,单击自由行,在自由行页面点击搜索框


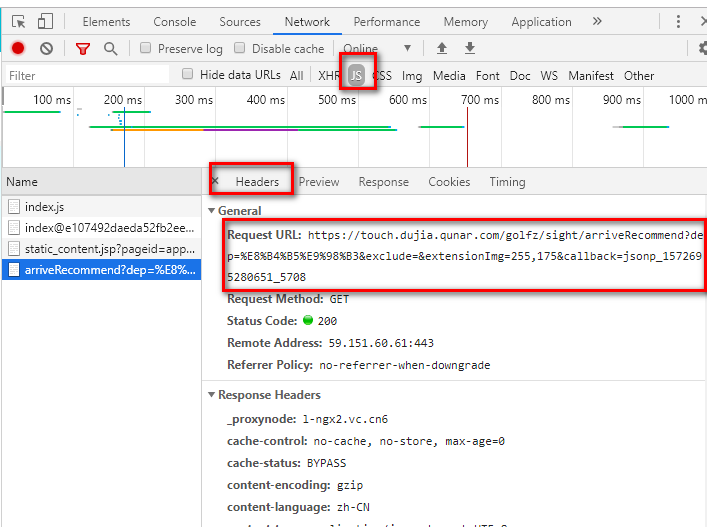
(3)单击任意一个城市,切换到headers,查看request URL如下所示。但是需要工具还原编码咋们才能知道这是啥(dep参数表示出发地,query表示目的地)。推荐网站http://www.jsons.cn/urlencode/,解码效果下面图2
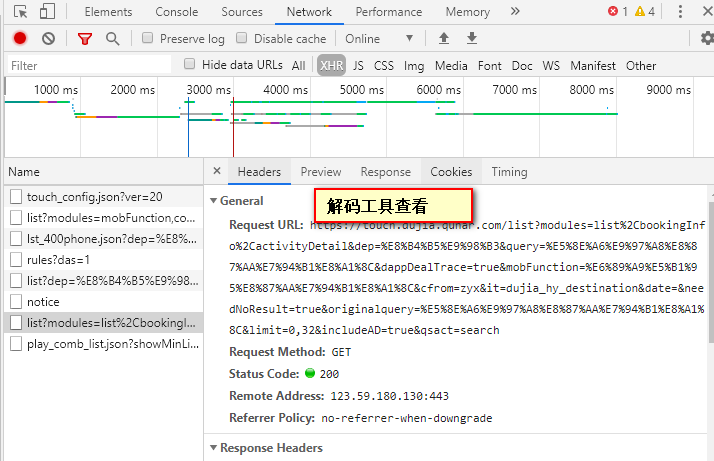

3 实现
(1)首先获得出发地站点,因为最终需要获得整个自由行的产品列表。
自由行首页中点击左侧的出发点站点,然后获取目标URL如图二

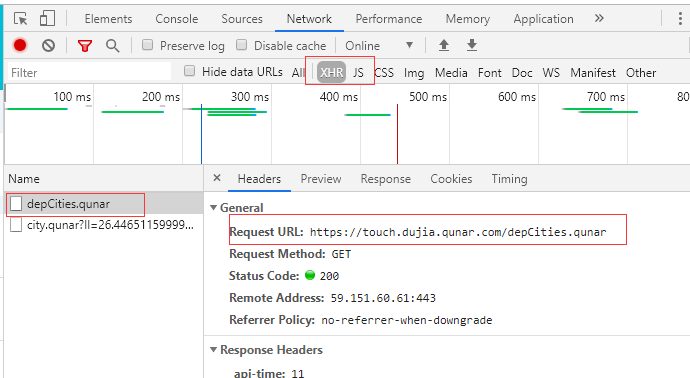
import requests
url="https://touch.dujia.qunar.com/depCities.qunar" strhtml=requests.get(url)
print(strhtml)
dep_dict=strhtml.json()
print(dep_dict)
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
print(dep)
(2)获得目的地。根据上面的分析,json工具解码以后通过拼接可得URL。
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
(3)总源码
import requests
import urllib
import time
#import pymongo # client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# sheet_qunar_zyx=book_qunar['qunar_zyx'] #获取产品列表
def get_list(dep,item):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit=0,20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item), urllib.request.quote(item))
strhtml = get_json(url)
try:
routeCount = int(strhtml['data']['limit']['routeCount'])
except:
return
for limit in range(0, routeCount, 20):
url = 'https://touch.dujia.qunar.com/list?modules=list,bookingInfo&dep={}&query={}&mtype=all&ddt=false&mobFunction=%E6%89%A9%E5%B1%95%E8%87%AA%E7%94%B1%E8%A1%8C&cfrom=zyx&it=FreetripTouchin&et=FreetripTouch&date=&configDepNew=&needNoResult=true&originalquery={}&limit={},20&includeAD=true&qsact=search'.format(
urllib.request.quote(dep), urllib.request.quote(item),
urllib.request.quote(item), limit)
strhtml = get_json(url)
result = {
'date': time.strftime('%Y-%m-%d', time.localtime(time.time())),
'dep': dep,
'arrive': item,
'limit': limit,
'result': strhtml
}
#sheet_qunar_zyx.insert_one(result)
print(result) # def connect_mongo():
# client=pymongo.MongoClient('localhost',27017)
# book_qunar=client['qunar']
# return book_qunar['qunar_zyx'] def get_json(url):
strhtml=requests.get(url)
time.sleep(1)
return strhtml.json() if __name__ == "__main__": url='https://touch.dujia.qunar.com/depCities.qunar'
dep_dict=get_json(url)
#这里是json格式 dep_dict中内嵌勒一层
for dep_item in dep_dict['data']:
for dep in dep_dict['data'][dep_item]:
a = []#目的地去重
#经过解码工具可以得到dep表示出发地 query和originalquery表示目的地
url = 'https://m.dujia.qunar.com/golfz/sight/arriveRecommend?dep={}&exclude=&extensionImg=255,175'.format(urllib.request.quote(dep))
arrive_dict = get_json(url)
for arr_item in arrive_dict['data']:
for arr_item_1 in arr_item['subModules']:
for query in arr_item_1['items']:
if query['query'] not in a:
a.append(query['query'])
for item in a:
get_list(dep,item)
python爬虫3之去哪儿网的更多相关文章
- 用python爬虫爬取去哪儿4500个热门景点,看看国庆不能去哪儿
前言:本文建议有一定Python基础和前端(html,js)基础的盆友阅读. 金秋九月,丹桂飘香,在这秋高气爽,阳光灿烂的收获季节里,我们送走了一个个暑假余额耗尽哭着走向校园的孩籽们,又即将迎来一年一 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫入门教程 34-100 掘金网全站用户爬虫 scrapy
爬前叨叨 已经编写了33篇爬虫文章了,如果你按着一个个的实现,你的爬虫技术已经入门,从今天开始慢慢的就要写一些有分析价值的数据了,今天我选了一个<掘金网>,我们去爬取一下他的全站用户数据. ...
- Python爬虫入门教程 11-100 行行网电子书多线程爬取
行行网电子书多线程爬取-写在前面 最近想找几本电子书看看,就翻啊翻,然后呢,找到了一个 叫做 周读的网站 ,网站特别好,简单清爽,书籍很多,而且打开都是百度网盘可以直接下载,更新速度也还可以,于是乎, ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
- python爬虫–爬取煎蛋网妹子图片
前几天刚学了python网络编程,书里没什么实践项目,只好到网上找点东西做. 一直对爬虫很好奇,所以不妨从爬虫先入手吧. Python版本:3.6 这是我看的教程:Python - Jack -Cui ...
- Python爬虫入门教程 20-100 慕课网免费课程抓取
写在前面 美好的一天又开始了,今天咱继续爬取IT在线教育类网站,慕课网,这个平台的数据量并不是很多,所以爬取起来还是比较简单的 准备爬取 打开我们要爬取的页面,寻找分页点和查看是否是异步加载的数据. ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
- Python 爬虫 爬取 煎蛋网 图片
今天, 试着爬取了煎蛋网的图片. 用到的包: urllib.request os 分别使用几个函数,来控制下载的图片的页数,获取图片的网页,获取网页页数以及保存图片到本地.过程简单清晰明了 直接上源代 ...
随机推荐
- java技术思维导图(转载)
在网上看到有个人总结的java技术的东东,觉得很好,就保存下来了,码农还真是累啊,只有不断的学习才能有所提高,才能拿更多的RMB啊. java技术思维导图 服务端思维导图 前端思维导图
- jeecg uedit 自定义图片上传路径
jeecg uedit 图片上传配置自定义物理路径,简单描述:我们知道 jeecg 中使用的 uedit 默认图片上传路径为 "当前项目\plug-in\ueditor\jsp\upload ...
- MySQL 内连接、外连接、左连接、右连接、全连接……太多了
用两个表(a_table.b_table),关联字段a_table.a_id和b_table.b_id来演示一下MySQL的内连接.外连接( 左(外)连接.右(外)连接.全(外)连接). 主题:内连接 ...
- Windbg命令的语法规则系列(二)
二.字符串通配符语法 一些调试器命令具有接受各种通配符的字符串参数.这些类型的参数支持以下语法功能: 星号(*)表示零个或多个字符. 问号(?)表示任何单个字符. 包含字符列表的括号([])表示列表中 ...
- for循环计算
计算0-100之间所有偶数的和: var a = 0 ; //声明一个变量 for (var i = 0; i<100 ; i++){ //起始条件 判断条件 结束条件 if (i%2===0) ...
- jQuery - 添加元素append/prepend和after/before的区别
append <p> <span class="s1">s1</span> </p> <script> $(" ...
- P1270 “访问”美术馆——不太一样的树形DP
P1270 “访问”美术馆 dfs读入,存图有点像线段树: 在枚举时间时,要减去走这条边的代价: #include<cstdio> #include<cstring> #inc ...
- VSCode 本地如何查看历史页面
1.首先要在VSCode的扩展中安装一个 Local history插件,蓝色框部分不用管,直接安装即可 2.安装并操作:安装后,修改 productManage/supplierList/addSu ...
- c++中关于堆和堆栈的区别
在C++中,内存分成5个区,他们分别是堆.栈.自由存储区.全局/静态存储区和常量存储区. 栈,就是那些由编译器在需要的时候分配,在不需要的时候自动清楚的变量 的存储区.里面的变量通常是局部 ...
- manjaro系统的回滚操作
作为linux系统的爱好者,自从使用linux后,就喜欢追求新的软件,连系统都换成了滚动升级的版本.manjaro基于arch linux,同时也是kde的支持系统,升级非常频繁.使用了几年,很少碰到 ...