C++分治策略实现线性时间选择
问题描述:
给定线性序集中n个元素和一个整数k,1≤k≤n,要求找出这n个元素中第k小的元素,即如果将这n个元素依其线性序排列时,排在第k个的元素即为要找到元素。
细节须知:(与之前的随笔相比)
(1)设置了对于程序运行次数的手动输入设定
(2)取消了文件的读入,直接生成随机数进行排序查找
(3)扩大了随机数的范围、数组的可申请大小
(4)时间统计精确到了微秒级
(5)运行结束后一次性写入提升了程序稳定性,写入的数据可用于数据分析图表
算法原理:
将n个输入元素划分成⌈n/5⌉个组,每组5个元素,只可能有一个组不是5个元素。用任意一种排序算法,将每组中的元素排好序,并取出每组的中位数,共⌈n/5⌉个。递归调用算法Select来找出⌈n/5⌉个元素的中位数。如果⌈n/5⌉是偶数,就找它的两个中位数中较大的一个。以这个元素作为划分基准。以此递归排序找到所需的第k项。
- #include<iostream>
- #include<cstdio>
- #include<cstdlib>
- #include<cstring>
- #include<fstream>
- #include<algorithm>
- #include<windows.h>
- #include<ctime>
- using namespace std;
- LARGE_INTEGER nFreq;//LARGE_INTEGER在64位系统中是LONGLONG,在32位系统中是高低两个32位的LONG,在windows.h中通过预编译宏作定义
- LARGE_INTEGER nBeginTime;//记录开始时的计数器的值
- LARGE_INTEGER nEndTime;//记录停止时的计数器的值
- //一次快排
- int Partition(int nums[],int p,int r,int x)
- {
- if(p>r) return -;
- //找出基准x的位置并与第一位交换
- for(int i=p;i<=r;i++)
- {
- if(nums[i]==x)
- {
- swap(x,nums[p]);
- break;
- }
- }
- int left=p,right=r;
- while(left<right)
- {
- while(left<right && nums[right]>=x) right--;
- nums[left]=nums[right];
- while(left<right && nums[left]<x) left++;
- nums[right]=nums[left];
- }
- nums[left]=x;
- return left;
- }
- //快速排序
- void QuickSort(int nums[],int low,int high)
- {
- if(low>high) return;
- int key=nums[low];
- int left=low,right=high;
- while(left<right)
- {
- while(left<right && nums[right]>=key) right--;
- nums[left]=nums[right];
- while(left<right && nums[left]<key) left++;
- nums[right]=nums[left];
- }
- nums[left]=key;
- QuickSort(nums,low,left-);
- QuickSort(nums,left+,high);
- }
- int Select(int nums[],int p,int r,int k)
- {
- if(r-p<)
- {
- QuickSort(nums,p,r);
- return nums[p+k-];
- }
- //每5个为一组,找到各组的中位数,并存储在前(r-p-4)/5个位置里
- for(int i=;i<=(r-p-)/;i++)
- {
- QuickSort(nums,p+*i,p+*i+);
- swap(nums[p+i],nums[p+*i+]);
- }
- //找所有中位数的中位数
- int x=Select(nums,p,p+(r-p-)/,(r-p-)/);
- //以x为基准做一次快排
- int i=Partition(nums,p,r,x);
- int j=i-p+;
- //判断k属于那个部分
- if(k<=j)
- return Select(nums,p,i,k);
- else
- return Select(nums,i+,r,k-j);
- }
- int main(){
- ofstream fout;
- double cost;
- int i = ,m = ,n = ,key = ;
- cout<<"Please enter the number of times you want to run the program:"; //输入程序运行次数
- cin>>m;
- int data_amount[m];
- double runtime[m];
- srand((unsigned int)time(NULL)); //设置随机数种子
- for(i=;i<m;i++)
- {
- n=+RAND_MAX*(rand()%)+rand(); //RAND_MAX=32767,随机生成数据量
- data_amount[i]=n; //限定数据规模为10000~9872867
- cout<<"☆The "<<i+<<"th test Data amount is:"<<n<<endl;
- int j=;
- int *a=(int *)malloc(n*sizeof(int));
- for(j=;j<n;j++){
- a[j]=RAND_MAX*(rand()%)+rand(); //随机生成0~13139567的随机数
- }
- key=rand()%+; //随机生成1~10000作为所要选择的次序
- QueryPerformanceFrequency(&nFreq);//获取系统时钟频率
- QueryPerformanceCounter(&nBeginTime);//获取开始时刻计数值
- int t=Select(a,,n-,key);
- QueryPerformanceCounter(&nEndTime);//获取停止时刻计数值
- cost=(double)(nEndTime.QuadPart - nBeginTime.QuadPart) / (double)nFreq.QuadPart;
- runtime[i]=cost;
- cout<<"The "<<key<<"th number is:"<<t<<endl;
- cout<<"The running time is:"<<cost<<" s"<<endl;
- free(a);
- }
- fout.open("data.txt");
- if(!fout){
- cerr<<"Can not open file 'data.txt' "<<endl;
- return -;
- }
- for(i=;i<m;i++){
- fout<<data_amount[i]<<","<<runtime[i]<<endl;
- }
- fout.close();
- cout<<"Success!"<<endl;
- return ;
- }
程序设计思路:
假设输入的数据规模为n,要查找的数据次序为k。
(1)判断数组长度,若小于75则直接进行快速排序,否则进行之后的算法。
(2)将n个输入元素划分成⌈n/5⌉个组,每组五个元素。用快速排序将每组中的元素排好序,并确定每组的中位数,共⌈n/5⌉个。
(3)递归调用算法Select来找出这⌈n/5⌉个元素的中位数。如果⌈n/5⌉是偶数,就找它的两个中位数中较大的一个。以这个元素作为划分基准。
(4)以此递归调用进行排序,最终搜索得到要找的第k项。
时间复杂性分析:
为了分析算法Select的计算时间复杂性,设n=r-p+1,即n为输入数组的长度。算法的递归调用只有在n≥75时才执行。因此,当n<75是算法Select所用的计算时间不超过一个常数C1。找到中位数的中位数x后,算法Select以x为划分基准调用Partition对数组a[p:r]进行划分,这需要O(n)时间。算法Select的for循环体行共执行n/5次,每一次需要O(1)时间。因此,执行for循环共需O(n)时间。
设对n个元素的数组调用算法Select需要T(n)时间,那么找中位数的中位数x至多用了T(n/5)的时间。已经证明了,按照算法所选的基准x进行划分所得到的2个子数组分别至多有3n/4个元素。所以,无论对哪一个子数组调用,Select都至多用了T(3n/4)的时间。
总之,可以得到关于T(n)的递归式
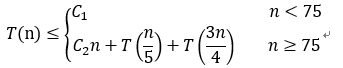
解此递归式可得T(n)=O(n)。
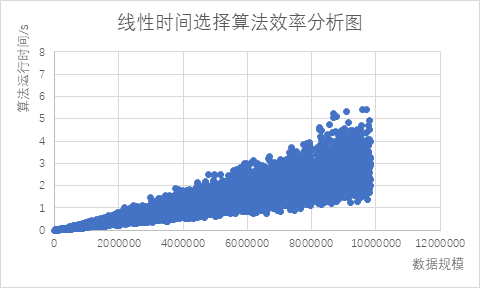
经过5000次不同规模数据的实验并统计运行时间得到如下算法效率分析图:
C++分治策略实现线性时间选择的更多相关文章
- [图解算法]线性时间选择Linear Select——<递归与分治策略>
#include <ctime> #include <iostream> using namespace std; template <class Type> vo ...
- 【技术文档】《算法设计与分析导论》R.C.T.Lee等·第4章 分治策略
分治策略有一种“大事化小,小事化了”的境界,它的思想是将原问题分解成两个子问题,两个子问题的性质和原问题相同,因此这两个子问题可以再用分治策略求解,最终将两个子问题的解合并成原问题的解.有时,我们会有 ...
- 【从零学习经典算法系列】分治策略实例——高速排序(QuickSort)
在前面的博文(http://blog.csdn.net/jasonding1354/article/details/37736555)中介绍了作为分治策略的经典实例,即归并排序.并给出了递归形式和循环 ...
- 递归与分治策略之循环赛日程表Java实现
递归与分治策略之循环赛日程表 一.问题描述 设有n=2^k个运动员要进行网球循环赛.现要设计一个满足以下要求的比赛日程表: (1)每个选手必须与其他n-1个选手各赛一次: (2)每个选手一天只能参赛一 ...
- 递归与分治策略之棋盘覆盖Java实现
递归与分治策略之棋盘覆盖 一.问题描述 二.过程详解 1.棋盘如下图,其中有一特殊方格:16*16 . 2.第一个分割结果:8*8 3.第二次分割结果:4*4 4.第三次分割结果:2*2 5.第四次分 ...
- 小旭讲解 LeetCode 53. Maximum Subarray 动态规划 分治策略
原题 Given an integer array nums, find the contiguous subarray (containing at least one number) which ...
- C++分治策略实现二分搜索
问题描述: 给定已排好序的n个元素组成的数组,现要利用二分搜索算法判断特定元素x是否在该有序数组中. 细节须知: (1)由于可能需要对分治策略实现二分搜索的算法效率进行评估,故使用大量的随机数对算法进 ...
- 【Unsolved】线性时间选择算法的复杂度证明
线性时间选择算法中,最坏情况仍然可以保持O(n). 原因是通过对中位数的中位数的寻找,保证每次分组后,任意一组包含元素的数量不会大于某个值. 普通的Partition最坏情况下,每次只能排除一个元素, ...
- 算法:线性时间选择(C/C++)
Description 给定线性序集中n个元素和一个整数k,n<=2000000,1<=k<=n,要求找出这n个元素中第k小的数. Input 第一行有两个正整数n,k. 接下来是n ...
随机推荐
- Java 之 Stack 集合
一.Stack:栈 概述 栈是一种先进后出(FILO)或后进先出(LIFO:Last in first out)的数据结构. Stack是Vector的子类,比Vector多了几个方法,它的后进先出的 ...
- android studio学习---怎么创建一个新的module并且再次运行起来(在当前的project里面)
选择File->new module出现的界面,选择android application选择下一步,就出现了和刚刚一样的流程了,一步步创建完成即可. 我们看到多了个secondAndroid的 ...
- Kubernetes概念之mater、node
很久没写博客了,终于把重心找回来了,不过没有以前有斗志.有理想.有目标了.慢慢来.你若问我我最近几年的规划是什么,还真不知道.突然发现摧毁一个人真的很简单.k8s也是一遍一遍的从入门到放弃,还是要好好 ...
- 高性能的编程IO与NIO阻塞分析
1.什么是阻塞,什么是非阻塞? 阻塞:结果返回之前,线程一直被挂起. 非阻塞:做一件事,尝试去做 2.传统IO模型 socket编程:
- mac下sourcetree创建git分支和合并分支
git默认创建的分支为:master主分支 要实现的效果:新建和合并分支. 1.在master基础上创建分支v1.0.1并切换至v1.0.1然后推送分支到远程服务器 确定即可!! 然后查看远端已经发现 ...
- 【Cookie】java.lang.IllegalArgumentException An invalid character [32] was present in the Cookie value
创建时间:6.30 java.lang.IllegalArgumentException: An invalid character [32] was present in the Cookie va ...
- 大数据技术原理与应用【第五讲】NoSQL数据库:5.4 NoSQL的三大基石
NoSQL的三大基石:cap,Base,最终一致性 5.4.1 cap理论(帽子理论): consistency:一致性availability:可用性partition tolerance: ...
- Linux应急响应
1.识别现象 top / ps -aux 监控与目标IP通信的进程 while true; do netstat -antp | grep [ip]; done 若恶意IP变化,恶意域名不变,使用ho ...
- hbase的javaAPI
https://www.cnblogs.com/tiantianbyconan/p/3557571.html hbase和dataFrame之间的互相转换: https://stackoverflow ...
- 【reactNative 大杂烩 好文章汇总 】
1. React Native之打包 https://blog.csdn.net/xiangzhihong8/article/details/70162784