SQLAlchemy基础
1.介绍
做个简单笔记,方便回顾.
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
pip3 install sqlalchemy
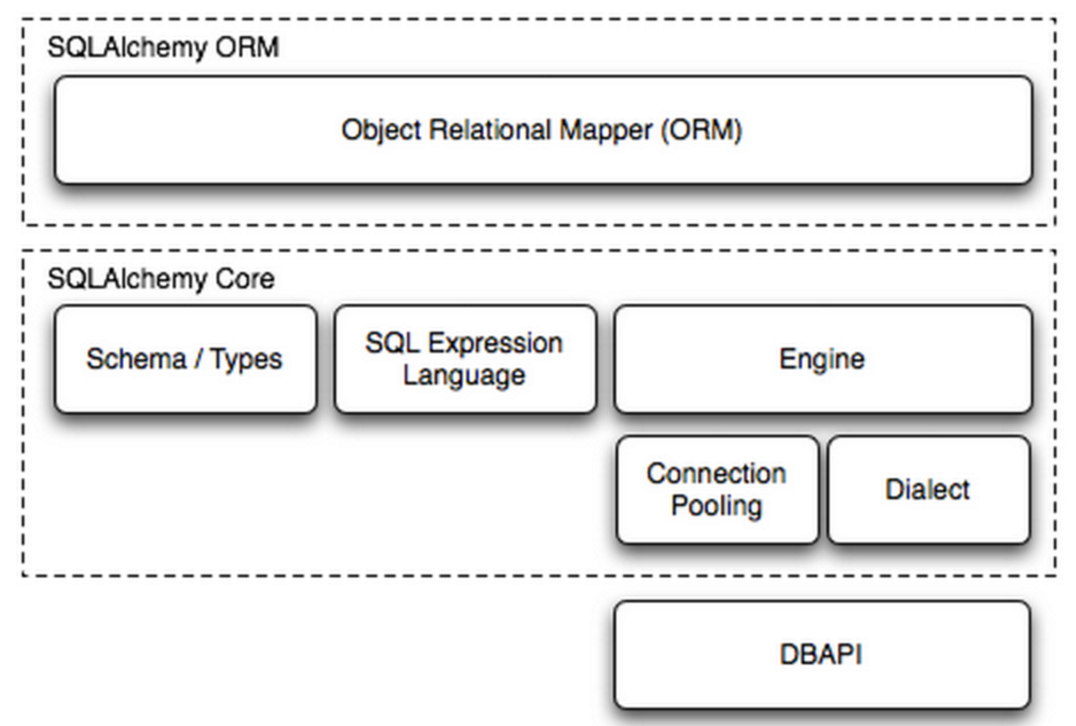
组成部分:
Engine,框架的引擎
Connection Pooling ,数据库连接池
Dialect,选择连接数据库的DB API种类
Schema/Types,架构和类型
SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
2.简单使用(能创建表,删除表,不能修改表)
修改表:在数据库添加字段,类对应上
1执行原生sql(不常用)
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/test?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
def task(arg):
conn = engine.raw_connection()
cursor = conn.cursor()
cursor.execute(
"select * from app01_book"
)
result = cursor.fetchall()
print(result)
cursor.close()
conn.close()
for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
2 orm使用
models.py
import datetime
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
Base = declarative_base()
class Users(Base):
__tablename__ = 'users' # 数据库表名称
id = Column(Integer, primary_key=True) # id 主键
name = Column(String(32), index=True, nullable=False) # name列,索引,不可为空
# email = Column(String(32), unique=True)
#datetime.datetime.now不能加括号,加了括号,以后永远是当前时间
# ctime = Column(DateTime, default=datetime.datetime.now)
# extra = Column(Text, nullable=True)
__table_args__ = (
# UniqueConstraint('id', 'name', name='uix_id_name'), #联合唯一
# Index('ix_id_name', 'name', 'email'), #索引
)
def init_db():
"""
根据类创建数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/aaa?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Base.metadata.create_all(engine)
def drop_db():
"""
根据类删除数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123456@127.0.0.1:3306/aaa?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Base.metadata.drop_all(engine)
if __name__ == '__main__':
# drop_db()
init_db()
app.py
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users
#"mysql+pymysql://root@127.0.0.1:3306/aaa"
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5)
Connection = sessionmaker(bind=engine)
# 每次执行数据库操作时,都需要创建一个Connection
con = Connection()
# ############# 执行ORM操作 #############
obj1 = Users(name="lqz")
con.add(obj1)
# 提交事务
con.commit()
# 关闭session,其实是将连接放回连接池
con.close()
3.一对多关系
class Hobby(Base):
__tablename__ = 'hobby'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='篮球')
class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
# hobby指的是tablename而不是类名
hobby_id = Column(Integer, ForeignKey("hobby.id"))
# 跟数据库无关,不会新增字段,只用于快速链表操作
# 类名,backref用于反向查询
hobby=relationship('Hobby',backref='pers')
4.多对多关系
class Boy2Girl(Base):
__tablename__ = 'boy2girl'
id = Column(Integer, primary_key=True, autoincrement=True)
girl_id = Column(Integer, ForeignKey('girl.id'))
boy_id = Column(Integer, ForeignKey('boy.id'))
class Girl(Base):
__tablename__ = 'girl'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False)
class Boy(Base):
__tablename__ = 'boy'
id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False)
# 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以
servers = relationship('Girl', secondary='boy2girl', backref='boys')
5.操作数据表
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/aaa", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
# 每次执行数据库操作时,都需要创建一个session
session = Session()
# ############# 执行ORM操作 #############
obj1 = Users(name="lqz")
session.add(obj1)
# 提交事务
session.commit()
# 关闭session
session.close()
6.基于scoped_session实现线程安全
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session
from models import Users
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
"""
# 线程安全,基于本地线程实现每个线程用同一个session
# 特殊的:scoped_session中有原来方法的Session中的一下方法:
public_methods = (
'__contains__', '__iter__', 'add', 'add_all', 'begin', 'begin_nested',
'close', 'commit', 'connection', 'delete', 'execute', 'expire',
'expire_all', 'expunge', 'expunge_all', 'flush', 'get_bind',
'is_modified', 'bulk_save_objects', 'bulk_insert_mappings',
'bulk_update_mappings',
'merge', 'query', 'refresh', 'rollback',
'scalar'
)
"""
#scoped_session类并没有继承Session,但是却又它的所有方法
session = scoped_session(Session)
# ############# 执行ORM操作 #############
obj1 = Users(name="alex1")
session.add(obj1)
# 提交事务
session.commit()
# 关闭session
session.close()
7.基本增删查改
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from db import Users, Hosts
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# ################ 添加 ################
"""
obj1 = Users(name="wupeiqi")
session.add(obj1)
session.add_all([
Users(name="lqz"),
Users(name="egon"),
Hosts(name="c1.com"),
])
session.commit()
"""
# ################ 删除 ################
"""
session.query(Users).filter(Users.id > 2).delete()
session.commit()
"""
# ################ 修改 ################
"""
#传字典
session.query(Users).filter(Users.id > 0).update({"name" : "lqz"})
#类似于django的F查询
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "099"}, synchronize_session=False)
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate")
session.commit()
"""
# ################ 查询 ################
"""
r1 = session.query(Users).all()
#只取age列,把name重命名为xx
r2 = session.query(Users.name.label('xx'), Users.age).all()
#filter传的是表达式,filter_by传的是参数
r3 = session.query(Users).filter(Users.name == "lqz").all()
r4 = session.query(Users).filter_by(name='lqz').all()
r5 = session.query(Users).filter_by(name='lqz').first()
#:value 和:name 相当于占位符,用params传参数
r6 = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(Users.id).all()
#自定义查询sql
r7 = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='ed').all()
"""
#增,删,改都要commit()
session.close()
8.常用操作
# 条件
ret = session.query(Users).filter_by(name='lqz').all()
#表达式,and条件连接
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
#注意下划线
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
#~非,除。。外
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
#二次筛选
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
from sqlalchemy import and_, or_
#or_包裹的都是or条件,and_包裹的都是and条件
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'eric', Users.id > 3),
Users.extra != ""
)).all()
# 通配符,以e开头,不以e开头
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()
# 限制,用于分页,区间
ret = session.query(Users)[1:2]
# 排序,根据name降序排列(从大到小)
ret = session.query(Users).order_by(Users.name.desc()).all()
#第一个条件重复后,再按第二个条件升序排
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组
from sqlalchemy.sql import func
ret = session.query(Users).group_by(Users.extra).all()
#分组之后取最大id,id之和,最小id
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
#haviing筛选
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表(默认用forinkey关联)
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
#join表,默认是inner join
ret = session.query(Person).join(Favor).all()
#isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可
ret = session.query(Person).join(Favor, isouter=True).all()
#打印原生sql
aa=session.query(Person).join(Favor, isouter=True)
print(aa)
# 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上
ret = session.query(Person).join(Favor,Person.id==Favor.id, isouter=True).all()
# 组合(了解)UNION 操作符用于合并两个或多个 SELECT 语句的结果集
#union和union all的区别?
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
9.执行原生sql
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 查询
# cursor = session.execute('select * from users')
# result = cursor.fetchall()
# 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'lqz'})
session.commit()
print(cursor.lastrowid)
session.close()
10.一对多
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Hobby(caption='乒乓球'),
Hobby(caption='羽毛球'),
Person(name='张三', hobby_id=3),
Person(name='李四', hobby_id=4),
])
person = Person(name='张九', hobby=Hobby(caption='姑娘'))
session.add(person)
#添加二
hb = Hobby(caption='人妖')
hb.pers = [Person(name='文飞'), Person(name='博雅')]
session.add(hb)
session.commit()
"""
# 使用relationship正向查询
"""
v = session.query(Person).first()
print(v.name)
print(v.hobby.caption)
"""
# 使用relationship反向查询
"""
v = session.query(Hobby).first()
print(v.caption)
print(v.pers)
"""
#方式一,自己链表
# person_list=session.query(models.Person.name,models.Hobby.caption).join(models.Hobby,isouter=True).all()
person_list=session.query(models.Person,models.Hobby).join(models.Hobby,isouter=True).all()
for row in person_list:
# print(row.name,row.caption)
print(row[0].name,row[1].caption)
#方式二:通过relationship
person_list=session.query(models.Person).all()
for row in person_list:
print(row.name,row.hobby.caption)
#查询喜欢姑娘的所有人
obj=session.query(models.Hobby).filter(models.Hobby.id==1).first()
persons=obj.pers
print(persons)
session.close()
11.多对多
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Server(hostname='c1.com'),
Server(hostname='c2.com'),
Group(name='A组'),
Group(name='B组'),
])
session.commit()
s2g = Server2Group(server_id=1, group_id=1)
session.add(s2g)
session.commit()
gp = Group(name='C组')
gp.servers = [Server(hostname='c3.com'),Server(hostname='c4.com')]
session.add(gp)
session.commit()
ser = Server(hostname='c6.com')
ser.groups = [Group(name='F组'),Group(name='G组')]
session.add(ser)
session.commit()
"""
# 使用relationship正向查询
"""
v = session.query(Group).first()
print(v.name)
print(v.servers)
"""
# 使用relationship反向查询
"""
v = session.query(Server).first()
print(v.hostname)
print(v.groups)
"""
session.close()
12.其它
import time
import threading
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text, func
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 关联子查询:correlate(Group)表示跟Group表做关联,as_scalar相当于对该sql加括号,用于放在后面当子查询
subqry = session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id).correlate(Group).as_scalar()
result = session.query(Group.name, subqry)
"""
SELECT `group`.name AS group_name, (SELECT count(server.id) AS sid
FROM server
WHERE server.id = `group`.id) AS anon_1
FROM `group`
"""
'''
select * from tb where id in [select id from xxx];
select id,
name,
#必须保证此次查询只有一个值
(select max(id) from xxx) as mid
from tb
例如,第三个字段只能有一个值
id name mid
1 lqz 1,2 不合理
2 egon 2
'''
# 原生SQL
"""
# 查询
cursor = session.execute('select * from users')
result = cursor.fetchall()
# 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'wupeiqi'})
session.commit()
print(cursor.lastrowid)
"""
session.close()
13.Flask-SQLAlchemy
flask和SQLAchemy的管理者,通过他把他们做连接
db = SQLAlchemy()
- 包含配置
- 包含ORM基类
- 包含create_all
- engine
- 创建连接
SQLAlchemy基础的更多相关文章
- SQLAlchemy基础操作二
多线程示例 import time import threading from sqlalchemy.ext.declarative import declarative_base from sqla ...
- SQLAlchemy基础操作一
用前安装 pip3 install sqlalchemy ORM ORM就是运用面向对象的知识,将数据库中的每个表对应一个类,将数据库表中的记录对应一个类的对象.将复杂的sql语句转换成类和对象的操作 ...
- sqlalchemy基础教程
一.基本配置 连接数据库 外部连接数据库时,用于表名数据库身份的一般是一个URL.在sqlalchemy中将该URL包装到一个引擎中,利用这个引擎可以扩展出很多ORM中的对象. from sqlalc ...
- flask插件系列之SQLAlchemy基础使用
sqlalchemy是一个操作关系型数据库的ORM工具.下面研究一下单独使用和其在flask框架中的使用方法. 直接使用sqlalchemy操作数据库 安装sqlalchemy pip install ...
- Python Flask SQLALchemy基础知识
一.介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并 ...
- Python-ORM之sqlalchemy的简单使用
ORM之sqlalchemy 基础章节 使用SQLAlchemy链接数据库 from sqlalchemy import create_engine from sqlalchemy.ext.decla ...
- 【tips】ORM - SQLAlchemy操作MySQL数据库
优先(官方文档SQLAlchemy-version1.2): sqlalchemy | 作者:斯芬克斯 推荐一(长篇幅version1.2.0b3):python约会之ORM-sqlalchemy | ...
- 第一弹:超全Python学习资源整理(入门系列)
随着人工智能.大数据的时代到来,学习Python的必要性已经显得不言而喻.我经常逛youtube,发现不仅仅是以编程为职业的程序员,证券交易人员,生物老师,高级秘书......甚至许多自由撰稿人,设计 ...
- 后端API入门到放弃指北
后端API入门学习指北 了解一下一下概念. RESTful API标准] 所有的API都遵循[RESTful API标准]. 建议大家都简单了解一下HTTP协议和RESTful API相关资料. 阮一 ...
随机推荐
- Python - 标准库概况 - 第二十一天
Python 标准库概览 操作系统接口 os模块提供了不少与操作系统相关联的函数. 建议使用 "import os" 风格而非 "from os import *&quo ...
- python3之本地文件模拟登录
本地文件模拟登录 user.txt文本文件数据格式: username:password #coding:utf-8 #读取数据 userFile = open("user.txt" ...
- Java多线程——ThreadLocal类的原理和使用
Java多线程——ThreadLocal类的原理和使用 摘要:本文主要学习了ThreadLocal类的原理和使用. 概述 是什么 ThreadLocal可以用来维护一个变量,提供了一个ThreadLo ...
- iOS - 常用宏定义和PCH文件知识点整理
(一)PCH文件操作步骤演示: 第一步:图文所示: 第二步:图文所示: (二)常用宏定义整理: (1)常用Log日志宏(输出日志详细可定位某个类.某个函数.某一行) //=============== ...
- 团队作业第3周——需求改进&系统设计(crtl冲锋队)
2.需求&原型改进: 1.问题:游戏中我方飞机和敌方飞机是怎么控制的? 改进: 在游戏中,我控制我方飞机,按下方向键飞机便向按下的方向移动,按下Z键,我方飞机发射子弹. 敌方飞机面向随机的方向 ...
- Tomcat 配置介绍
参数说明: maxThreads: 最大可以创建请求的线程数 minSpareThreads: 服务启动时创建的处理请求的进程数 Connector中的port: 创建服务器端的端口号,此端口监听用户 ...
- 服务器Oracle数据库配置与客户端访问数据库的一系列必要设置
tips:所有路径请对应好自己电脑的具体文件路径. 一.服务器及Oracle数据库设置 1.刚装完的Oracle数据库中只有一个dba账户,首先需要创建一个用户. 2.配置监听,C:\app\Admi ...
- 还是畅通工程 HDU - 1233
题目链接:https://vjudge.net/problem/HDU-1233 思路: 最小生成树板子. #include <iostream> #include <stdio.h ...
- day36_8_20数据库3外键
一.一对多 在数据库使用数据中经常遇到一对多的情况,以公司员工为例. 一张完整的员工表有以下字段: id name gender dep_name dep_desc . 以此建表得: id n ...
- 【Spring AOP】AOP介绍(一)
AOP(Aspect Oriented Programming) 面向切面编程,是Spring框架的一个重要组件. AOP应该算是对OOP(面向对象编程)的补充和完善.OOP引入封装.继承.多态等概念 ...