Hadoop2.8.4集群配置
建hadoop用户
#添加用户hadoop
adduser hadoop
这个过程中需要输入密码两次
Enter new password:
Retype new password:
passwd: password updated successfully 编辑/etc/sudoers文件
root ALL=(ALL) ALL
后面加入
hadoop ALL=(ALL) ALL下载所需要用到的工具包,并上传到hadoop用户目录
需要用到的工具包包括java,hadoop
安装java
设置环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_161
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
安装hadoop
解压并移动至/opt目录
tar -zxvf hadoop-2.8.4.tar.gz
mv hadoop-2.8.4 /opt/hadoop
设置环境变量vi /etc/profileexport HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行
source /ect/profile在hadoop-env.sh中,再显示地重新声明一遍JAVA_HOME,添加:
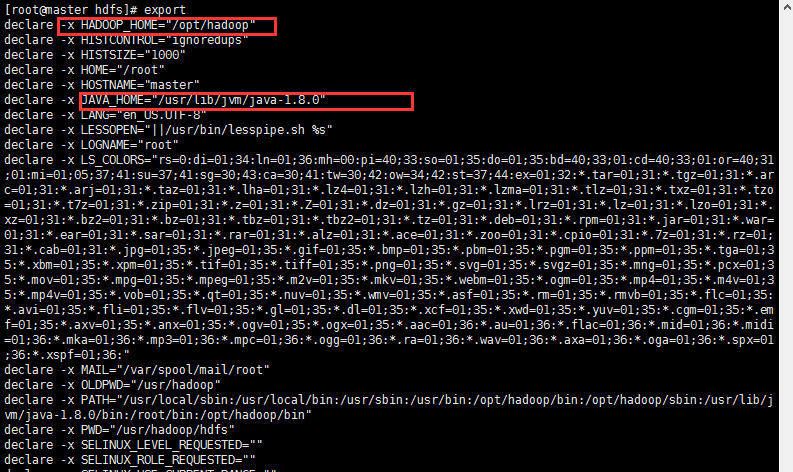
export JAVA_HOME=/usr/lib/jvm/java-1.8.0
通过export可以查看配置的环境变量情况
配置集群服务器参数
我们这里用到的是三台服务器,一台master,两台slave.三台机器的名称和ip如下:
| 主机名称 | ip地址 |
|---|---|
| master | 192.168.11.128 |
| node1 | 192.168.11.129 |
| node2 | 192.168.11.130 |
三台电脑主机的用户名均为hadoop.
三台机器可以ping双方的ip来测试三台电脑的连通性。
配置host如下:
192.168.11.128 master
192.168.11.129 node1
192.168.11.130 node2
配置ssh免密码登陆
Hadoop集群配置
修改master主机修改Hadoop如下配置文件,这些配置文件都位于/opt/hadoop/etc/hadoop目录下。
修改slaves文件,把DataNode的主机名写入该文件,每行一个。这里让master节点主机仅作为NameNode使用。
master
node1
node2
hadoop-env.sh

core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/usr/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/usr/hadoop/hdfs/data</value>
</property>
</configuration>
mapred-site.xml ( 没有mapred-site.xml但是有一个 mapred-site.xml.template,拷贝下改个名称)
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value></value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value></value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value></value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value></value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:</value>
</property>
</configuration>
注:以上修改的文件需要在所有slave服务器上同步,使用前面的scp命令即可
同步hadoop文件
scp /opt/hadoop/ hadoop@node1:/opt/
scp /opt/hadoop/ hadoop@node2:/opt/
启动hadoop集群
启动hadoop集群
在master主机上执行如下命令:
cd /opt/hadoop/
hdfs namenode -format
./sbin/start-all.sh
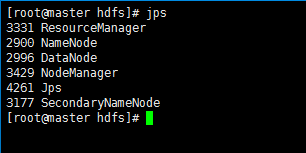
运行后,在master,node1,node2运行jps命令,查看hadoop运行状态:
jps
向hadoop集群系统提交第一个mapreduce任务(wordcount)
进入本地hadoop目录(/usr/hadoop)
1、 bin/hdfs dfs -mkdir -p /data/input在虚拟分布式文件系统上创建一个测试目录/data/input
2、 hdfs dfs -put README.txt /data/input 将当前目录下的README.txt 文件复制到虚拟分布式文件系统中
3、 bin/hdfs dfs-ls /data/input 查看文件系统中是否存在我们所复制的文件
如图操作:

3、 运行如下命令向hadoop提交单词统计任务
进入jar文件目录,执行下面的指令。
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.4.jar wordcount /data/input /data/output/result
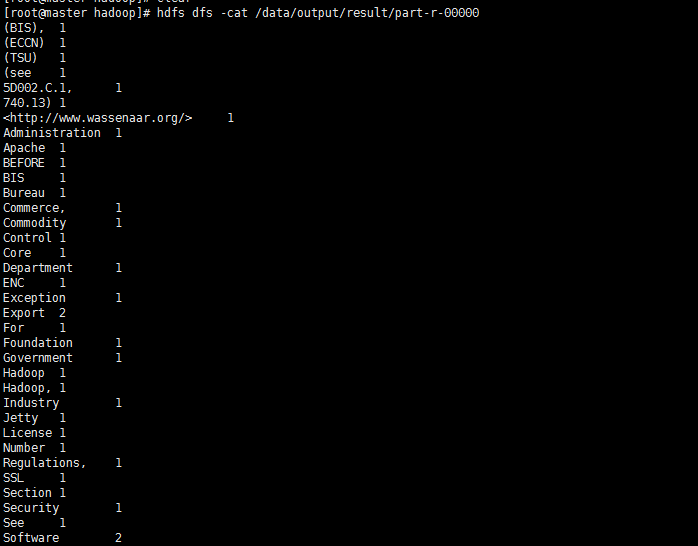
查看result,结果在result下面的part-r-00000中
hdfs dfs -cat /data/output/result/part-r-00000
常见异常
1、 org.apache.hadoop.hbase.util.JvmPauseMonitorDetected pause in JVM or host machine (eg GC): pause of approximately 2489ms
No GCs detected
表示内存不够用,修改hdfs-env.sh和GC相关的参数:
export HADOOP_DATANODE_OPTS=”"-Xmx1024m -Xms256m"
参考:
https://blog.csdn.net/sinat_42447818/article/details/81158282
Hadoop2.8.4集群配置的更多相关文章
- hadoop2.6.0集群配置
1.修改机器名 集群的搭建最少需要三个节点,机器名分别修改为master,slave1,slave2.其中以master为主要操作系统. 修改hostname: sudo gedit /etc/hos ...
- Hadoop-2.6.0 集群的 安装与配置
1. 配置节点bonnie1 hadoop环境 (1) 下载hadoop- 2.6.0 并解压缩 [root@bonnie1 ~]# wget http://apache.fayea.com/had ...
- hadoop集群配置方法---mapreduce应用:xml解析+wordcount详解---yarn配置项解析
注:以下链接均为近期hadoop集群搭建及mapreduce应用开发查找到的资料.使用hadoop2.6.0,其中hadoop集群配置过程下面的文章都有部分参考. hadoop集群配置方法: ---- ...
- Hadoop2.X分布式集群部署
本博文集群搭建没有实现Hadoop HA,详细文档在后续给出,本次只是先给出大概逻辑思路. (一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 基于A ...
- 新闻实时分析系统-Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- 新闻网大数据实时分析可视化系统项目——3、Hadoop2.X分布式集群部署
(一)hadoop2.x版本下载及安装 Hadoop 版本选择目前主要基于三个厂商(国外)如下所示: 1.基于Apache厂商的最原始的hadoop版本, 所有发行版均基于这个版本进行改进. 2.基于 ...
- 部署hadoop2.7.2 集群 基于zookeeper配置HDFS HA+Federation
转自:http://www.2cto.com/os/201605/510489.html hadoop1的核心组成是两部分,即HDFS和MapReduce.在hadoop2中变为HDFS和Yarn.新 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置HA配置
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
- hadoop-2.3.0-cdh5.1.0完全分布式集群配置及HA配置(待)
一.安装前准备: 操作系统:CentOS 6.5 64位操作系统 环境:jdk1.7.0_45以上,本次采用jdk-7u55-linux-x64.tar.gz master01 10.10.2.57 ...
随机推荐
- 奶牛抗议 DP 树状数组
奶牛抗议 DP 树状数组 USACO的题太猛了 容易想到\(DP\),设\(f[i]\)表示为在第\(i\)位时方案数,转移方程: \[ f[i]=\sum f[j]\;(j< i,sum[i] ...
- 使用docker 基于centos7制作mysql镜像
说明:由于业务需要使用centos7.6+mysql5.7+jdk8以及其他的java程序,本想在网上找一个现成的,发现镜像都不适合我. 一.yum方式安装mysql 1.编写dockerfile文件 ...
- udf也能用Python
具体步骤见<fluent加载第三方(C++,Fortran等)动态链接库> 我们对导入的动态链接库进行改动 打开VS2013 完成了上述过程以后,还需要配置Python 首先需要安装Pyt ...
- Cache busting
Cache busting https://www.keycdn.com/support/what-is-cache-busting https://curtistimson.co.uk/post/f ...
- 安装EOS合约工具eosio.cdt
安装: 安装完之后 会产生 eosio-cpp_, eosio-cc, eosio-ld, eosio-pp, and _eosio_abigen (These are the C++ compile ...
- openresty开发系列37--nginx-lua-redis实现访问频率控制
openresty开发系列37--nginx-lua-redis实现访问频率控制 一)需求背景 在高并发场景下为了防止某个访问ip访问的频率过高,有时候会需要控制用户的访问频次在openresty中, ...
- Cisco设备配置SSH登录
一 试验拓扑 二 Server配置 ①配置hostname和domain name 因为rsa的秘钥是用hostname和domain name产生的 Router(config)#host Serv ...
- 将map对象参数转换成String=String&方式
* 将map对象参数转换成String=String&方式 * @param params * @param charset * @return * @throws UnsupportedEn ...
- jquery click 与原生 click 的区别
$.click() 触发的事件中没有 event.originalEvent , 不同触发 href="" 中的内容 $[0].click() 可以 <script type ...
- Node.js 多线程完全指南
[原文] 很多人都想知道单线程的 Node.js 怎么能与多线程后端竞争.考虑到其所谓的单线程特性,许多大公司选择 Node 作为其后端似乎违反直觉.要想知道原因,必须理解其单线程的真正含义. Jav ...