TreeMap源码分析1
二叉树他们都需要满足一个基本性质--即树中的任何节点的值大于它的左子节点,且小于它的右子节点。按照这个基本性质使得树的检索效率大大提高。我们知道在生成二叉树的过程是非常容易失衡的,最坏的情况就是一边倒(只有右/左子树),这样势必会导致二叉树的检索效率大大降低(O(n)),所以为了维持二叉树的平衡,大牛们提出了各种实现的算法,如:AVL,SBT,伸展树,TREAP ,红黑树等等。
平衡二叉树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。
两个节点要想可达必须是父子关系。 从根节点到任一节点只有一条路径。 一个节点只有一个父节点多个子节点。一个节点的所有父节点路径是唯一的。
任何一个节点只有一个父节点,从下往上走只有一条路径,其他节点在这个路径上就可以到达,不在路径上的节点就到达不了,每一层在这个路径上的只有一个节点。
二分查找的查找效率高于顺序查找,但不适合插入。
要支持高效的插入操作,我们似乎需要一种链式结构。
单链接的链表是无法使用二分查找的,因为二分查找的高效来自于能够快速通过索引取得任何子数组的中间元素。为了将二分查找的效率和链表的灵活性结合起来,我们需要更加复杂的数据结构。
能够同时拥有两者的就是二叉查找树BST。
交换所有节点的左右子树:

public class InvertBinaryTree {
//交换所有节点
public TreeNode invertTree(TreeNode root) {
if (root != null) {
TreeNode t = root.left;// 交换根
root.left = root.right;
root.right = t;
invertTree(root.left);// 交换左子树
invertTree(root.right);// 交换右子树
return root;
} else {
return null;
}
}
// 层序遍历
public TreeNode invertTree_bfs(TreeNode root) {
if (root == null) {
return null;
} else {
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.offer(root);
while (!queue.isEmpty()) {
TreeNode p = queue.poll();
TreeNode t = p.left;
p.left = p.right;
p.right = t;
if (p.left != null) {
queue.offer(p.left);
}
if (p.right != null) {
queue.offer(p.right);
}
}
return root;
}
}
}
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode(int x) {
val = x;
}
public TreeNode(int val, TreeNode left, TreeNode right) {
super();
this.val = val;
this.left = left;
this.right = right;
}
public TreeNode() {
super();
}
}
二叉排序树也叫二叉搜索树也叫Binary Sort Tree也叫Binary Search Tree也叫BST
具有如下性质:
定义空树是一个BST
左子树所有结点的值均小于根结点的值
右子树所有结点的值均大于根结点的值
左右子树都是BST(递归定义)
中序遍历序列为升序
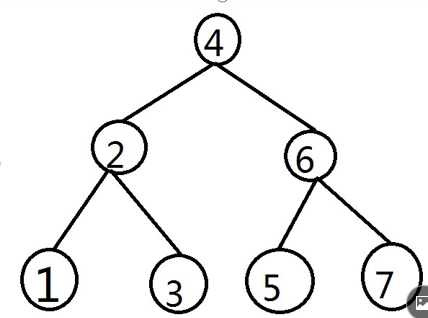
依次插入4、2、6、2、1、3、5、1、7:
插入4根节点直接插入,插入2小于4在左边,插入6大于4在右边,插入2小于4在左边,在和4的左边2比较,相等不用插入,插入1小于4在左边,左边有2,小于2在2的左边,插入3小于4在左边,大于2在右边,5大于4在右边,5小于6在左边,1小于4在左边,1小于2在左边,有一个1相等就不动,7大于4大于6.
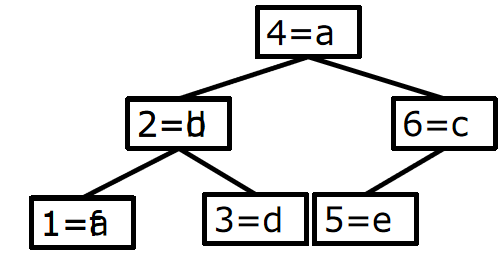
键值对的插入:
依次插入{4:a},{2:b},{6:c},{2:d},{1:a},{3:d},{5:e},{1:f}
{2:d}替换{2:b},{1:f}替换{1:a}
二叉搜索树Binary Search Tree BST:一边大一边小。
AVL:一边大一边小,同时左右子树高度差只能为0,1。解决了二叉搜索树的极端条件就是成为链表。
红黑树:RedBlackTree、RBT。AVL树的调整需要左右旋转,AVL的查找效率高但是插入和删除效率低,就出现红黑树。
1.红黑树不像AVL一样,永远保持绝对平衡
2.相对平衡
3.若H(left)>=H(right),则:H(left)<=2*H(right)+1,但BH(left)===BH(right)黑高相等,H(left)<H(right)同理
4.定理:N个节点的RBT,最大高度是2log(N+1),严格证明参考CLRS
5.查询效率RBT低于AVL
6.插入、删除效率好于AVL
红黑树是平衡二叉树,平衡儿茶B树,本质是一课B-tree。小的在一边大的在另一边,为了防止都是小的变成链表,所以要平衡。
AVL是通过高度实现的平衡,SBT是通过节点域维持平衡的,红黑树通过红黑节点维持平衡。红黑树中序遍历单调不减。

第一棵树:違反中序遍歷不減。
第三课:根节点是黑色。
第四课:红节点子节点是黑色。
第五棵:黑高不相等。
红黑树的遍历简单:小于就走左边,大于就走右边,。
遍历分为广度优先和深度优先。
红黑树从根到叶子节点的最长路径不会超过最短路径的2倍。就保证了自平衡性,不会造成节点全在一个路径上导致变成链表而使得查找效率低。
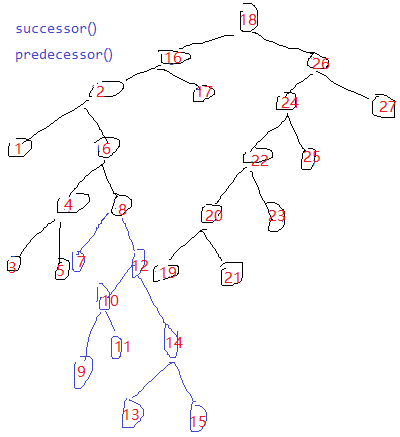
map.put(12, 12);
map.put(1, 1);
map.put(9, 9);
map.put(2, 2);
map.put(0, 0);
map.put(11, 11);
map.put(7, 7);
map.put(19, 19);
map.put(4, 4);
map.put(15, 15);

TreeMap的接口:
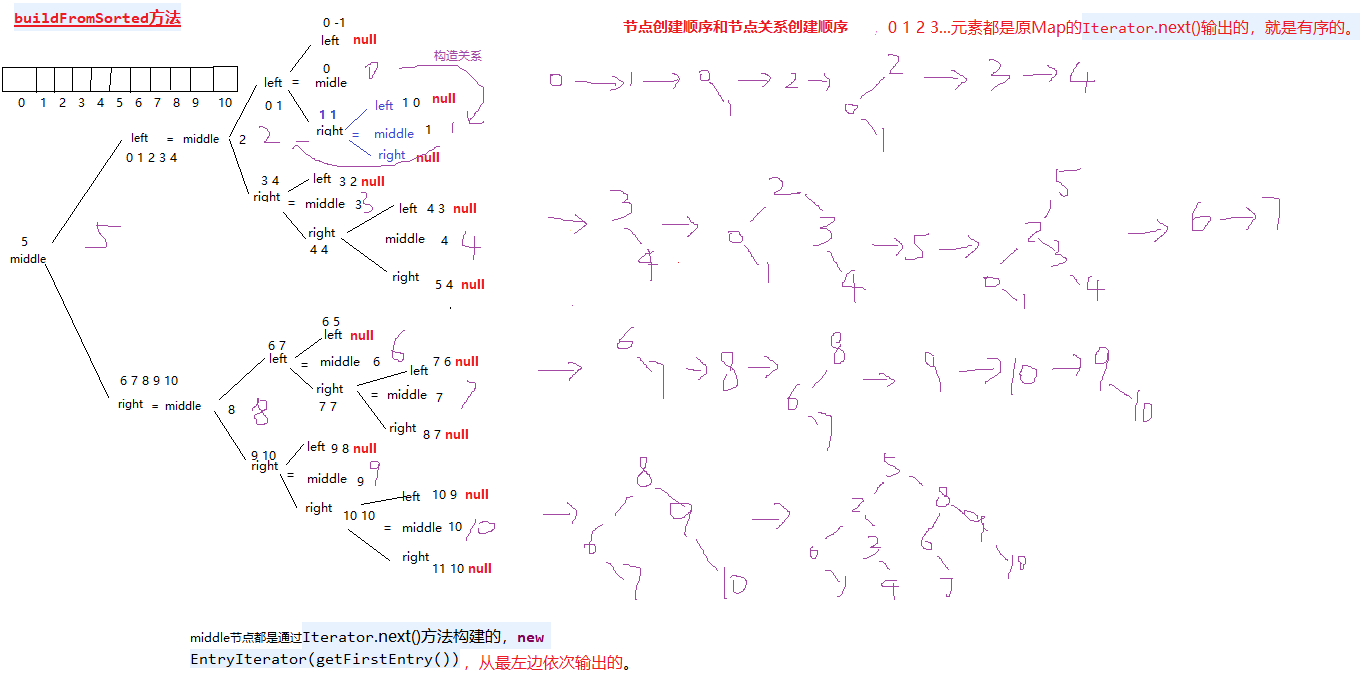


TreeMap源码分析1的更多相关文章
- Java集合之TreeMap源码分析
一.概述 TreeMap是基于红黑树实现的.由于TreeMap实现了java.util.sortMap接口,集合中的映射关系是具有一定顺序的,该映射根据其键的自然顺序进行排序或者根据创建映射时提供的C ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- TreeMap 源码分析
简介 TreeMap最早出现在JDK 1.2中,是 Java 集合框架中比较重要一个的实现.TreeMap 底层基于红黑树实现,可保证在log(n)时间复杂度内完成 containsKey.get.p ...
- TreeMap源码分析,看了都说好
概述 TreeMap也是Map接口的实现类,它最大的特点是迭代有序,默认是按照key值升序迭代(当然也可以设置成降序).在前面的文章中讲过LinkedHashMap也是迭代有序的,不过是按插入顺序或访 ...
- 死磕 java集合之TreeMap源码分析(四)-内含彩蛋
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 二叉树的遍历 我们知道二叉查找树的遍历有前序遍历.中序遍历.后序遍历. (1)前序遍历,先遍历 ...
- 死磕 java集合之TreeMap源码分析(三)- 内含红黑树分析全过程
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 删除元素 删除元素本身比较简单,就是采用二叉树的删除规则. (1)如果删除的位置有两个叶子节点 ...
- 死磕 java集合之TreeMap源码分析(二)- 内含红黑树分析全过程
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 插入元素 插入元素,如果元素在树中存在,则替换value:如果元素不存在,则插入到对应的位置, ...
- 死磕 java集合之TreeMap源码分析(一)- 内含红黑树分析全过程
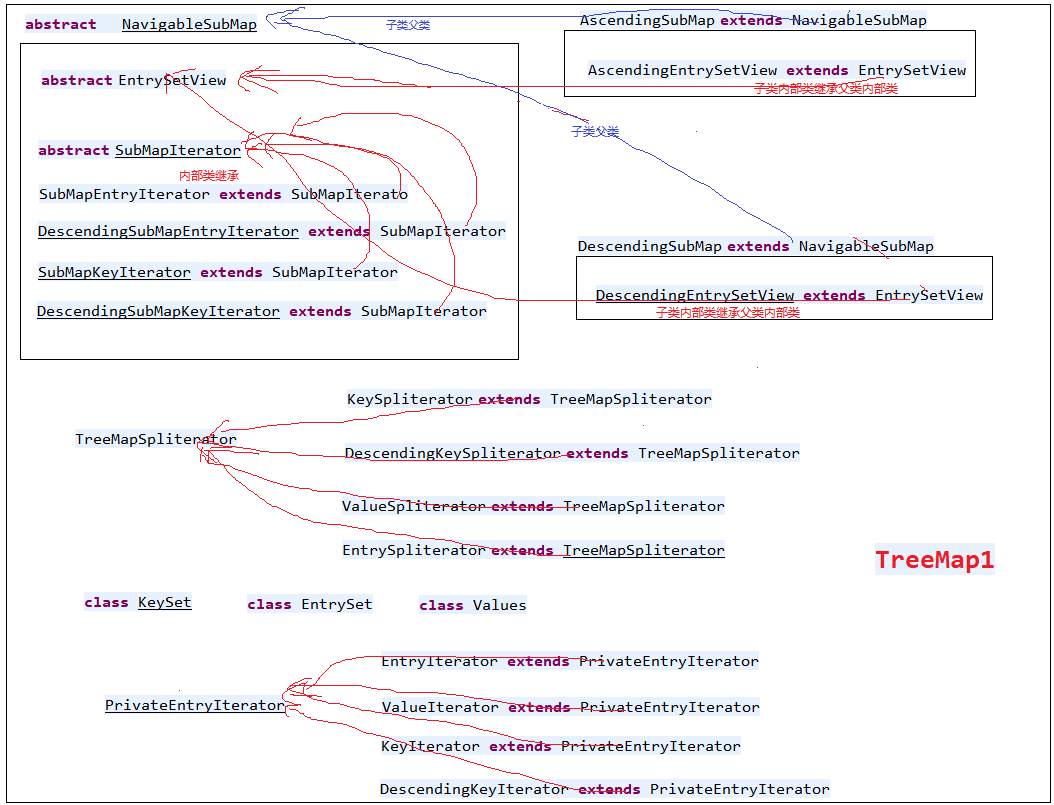
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 简介 TreeMap使用红黑树存储元素,可以保证元素按key值的大小进行遍历. 继承体系 Tr ...
- TreeMap源码分析
MapClassDiagram
- java.util.TreeMap源码分析
TreeMap的实现基于红黑树,排列的顺序根据key的大小,或者在创建时提供的比较器,取决于使用哪个构造器. 对于,containsKey,get,put,remove操作,保证时间复杂度为log(n ...
随机推荐
- Python学习笔记之测试函数
11-1 城市和国家:编写一个函数,它接受两个形参:一个城市名和一个国家名.这个函数返回一个格式为City, Country 的字符串,如Santiago, Chile.将这个函数存储在一个名为cit ...
- Python基础14
P73. 内嵌函数的讲解介绍 内部函数,书中讲的应用较简单,后面找篇具体的文章学习下
- RabbitMQ如何实现高可用
RabbitMQ一共具有三种模式:单机.普通集群.镜像集群 单机模式 单机模式,就是我们平常玩的demo,生产上肯定不能用.具体安装部署过程可以参考我的这篇文章:CentsOS原生RabbitMQ安装 ...
- 解决 Electron 5.0 版本出现 require is not defined 的问题
Electron已经发布了5.0正式版,升级后发现原来能运行的代码报错提示require is not defined 经查相关资料,原来官方在5.0版本修改了nodeIntegration的默认值, ...
- riscv 汇编与反汇编
为了riscv指令集,我们需要汇编与反汇编工具来分析指令格式. 可以用下面的两个工具来汇编和反汇编,下载链接:https://pan.baidu.com/s/1eUbBlVc riscv-none-e ...
- Kubernetes概念之RC
感觉自己浪费了一年的时间,种一棵树最好的时间是十年前,还有就是现在,虽然这颗树种了又种,种了又种,这次真的要种了...... 本文通过<Kubernetes权威指南>的概念部分学习总结 ...
- linux下使用selenium
安装chromedriver 1.安装chrome 用下面的命令安装最新的 Google Chrome yum install https://dl.google.com/linux/direct/g ...
- 常用dos命令(4)
系统管理at 安排在特定日期和时间运行命令和程序shutdown立即或定时关机或重启taskkill结束进程(WinXPHome版中无该命令)tasklist显示进程列表(Windows XP Hom ...
- Java 基本类型、封装类型、常量池、基本运算
基本数据类型: byte:Java中最小的数据类型,在内存中占8位(bit),即1个字节,取值范围-128~127,默认值0 short:短整型,在内存中占16位,即2个字节,取值范围-32768~3 ...
- vue大文件上传组件选哪个好?
需求:项目要支持大文件上传功能,经过讨论,初步将文件上传大小控制在500M内,因此自己需要在项目中进行文件上传部分的调整和配置,自己将大小都以501M来进行限制. 第一步: 前端修改 由于项目使用的是 ...