运维开发笔记整理-Django模型语法
运维开发笔记整理-Django模型语法
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.模型基本概念
1>.什么是模型
模型是你的数据唯一的,权威的信息源。它包含你所存储数据的必要字段和行为。每个模型对应数据库中唯一的一张表。它包含你所存储数据的必要字段和行为。每个模型对应数据库中唯一的一张表。
2>.如何编写模型
模型:每个模型都用一个类表示,该类继承自“django.db.models.Model”。每个模型有多个类的属性变量,而每一个类的属性变量又都代表类数据库表中的一个字段。
字段:每个字段通过Field类的一个实例表示,例如字符字段CharField和日期字段DataTimeField。这种方法告诉Django每个字段保存着什么类型的数据。(偷偷告诉你,Django支持的模型字段比数据库本身的字段要支持的多,比如MySQL的varchar类型,就被Django封装成了不同的模型字段,比如EmailField)。
字段名:每个Field实例的名字(例如username)就是字段的名字,并且是机器刻度的格式。你将在Python代码中使用它的值,并且你的数据库把它为表的列名。
3>.模型字段类型
模型字段类型又很多,比如CharField,BooleanFielld,IntegerField,DateField/DateTimeField,EmailField,TextField,TimeField等等,更多字段类型(Field-types)可参考Django组建的官方地址:https://docs.djangoproject.com/en/1.11/ref/models/fields/#field-types。
4>.自增主键字段
默认情况下Django会给每个模型添加下面这个字段。
id = models.AutoField(primary_key=True)
如果Django看到你显示设置了Field.primary_key,就不会自动添加id列。
每个模型只能有一个字段指定primary_key=True(无论是显示声明还是自动添加)。
5>.字段的自述名
每个字段类型都接受一个可选的位置参数,字段的自述名,如果没有给定自述名,Django将根据字段的属性名称自动创建自述名,将属性名称的下划线替换成空格。
ForeignKey,ManyToManyField和OneToOneField这三个可以使用verbose_name指定自述名。
#例如:自述名为:"person's first name"
first_name = models.CharField("person's first name", max_length=30) #例如:自述名为:"first name"
first_name = models.CharField(max_length=30)
6>.字段选项
每个字段有一个也有的参数,例如,CharField(和它的派生类)需要max_length参数来指定VARCHAR数据库字段的大小。
null:
如果为True,Django将用NULL来在数据库中存储空值,默认值是False。
blank:
如果为True,该字段允许不填,默认值是False。null是纯数据库范畴,而blank是数据验证范畴的,blank=True,表单验证允许为空,blank=False,该字段就是必须的。
choices:
由二元组组成的一个可迭代对象(如列表或元组),用来给字段提供选择项,如果设置了choices,默认的表单将是一个选择框,选择框的选择就是choices中的选项。
YEAR_IN_SCHOOL_CHOICES = (
('FR', 'Freshman'),
('SO', 'Sophomore'),
('JR', 'Junior'),
('SR', 'Senior'),
)
defaulat:
字段的默认值,可以是一个值或者调用对象。
primary_key:
如果为True,那么这个字段就是模型的主键。
unique:
如果改值设置为True,这个字段的值在整张表中必须是唯一的。
更多关于Field字段选项可参考官方链接:https://docs.djangoproject.com/en/1.11/ref/models/fields/#field-options。
7>.模型meta选项
使用内部的class Meta定义模型的元数据,例如:
from django.db import models
class User(models.Model):
username = models.IntegerField()
class Meta:
ordering = ["username"]
模型元数据是“任何不是字段的数据”,比如排序选项(ordering),数据库表名(tb_table)。在模型中添加class Meta是完全可选的,所有选项都不是必须的。更多文档可参考官方链接:https://docs.djangoproject.com/en/1.11/ref/models/options/。
db_table:
db_table是用于指定自定义数据库表名的。Django有一套默认的按照一定规则生成数据模型对应的数据库表名,如果你想使用自定义的表名,就通过这个属性执行。
若不提供该参数,Django会使用app_label + '_' + module_name作为表的名字。
class Meta:
db_table = 'server’
Django会根据模型类的名称和包含它的应用的名称自动指定数据库表名称。一个模型数据库表名称,由这个模型的“应用名”和模型名称之间加上下划线组成。
使用Meta类中的db_table参数来重写数据表的名称。
当你通过db_table覆写表名称时,强烈推荐使用小字母给表命名。
order:
这个字段是告诉Django模型对象返回的记录结果集是按照哪个字段排序的
class Meta:
ordering = ['-order_date']
它是一个字符串的猎豹或元组。每个字符串是一个字段名,前面带有可选的“-”前缀表示倒叙。前面没有“-”表示正序。使用“?”来表示随机排序。
ordering=['order_date'] # 按订单升序排列
ordering=['-order_date'] # 按订单降序排列,-表示降序
ordering=['?order_date'] # 随机排序,?表示随机
ordering = ['-pub_date', 'author'] # 对 pub_date 降序,然后对 author 升序
app_label:
app_label这个选项只在一种情况下使用,就是你的模型类不在默认的程序包下models.py文件中,这时候你需要指定你这个模型属于哪个应用程序。
class Meta:
app_label='myapp'
get_latest_by:
由于Django的管理方法中有个lastest()方法,就是得到最近一行记录。如果你的数据模型中有DataField或DateTimeField类型的字段,你可以通过这个选项来指定lastest()是按照哪个字段进行选取的。
一个DataField或DateTimeField字段的名称,若提供该选项,该模块将拥有一个get_lastest()函数以得到“最新的”对象(依据那个字段):
class Meta:
get_latest_by = "order_date"
verbose_name:
verbose_name的意思很艰难,就是给你的模型类起一个更可读的名字,代码如下:
class Meta:
verbose_name = "Jason"
managed:
由于Django会自动根据类型生成映射的数据库表,如果你不希望Django这么做,可以把managed的值设置为False。
默认值为True,这个选项为True时Django可以对数据库表进行migrate或migrations,删除等操作。在这个时间Django将管理数据库中表的声明周期。
如果为False的时候,不户籍对数据库表进行创建,删除等操作。可以用于现有表,数据库视图等,其他操作是一样的。
二.编写IDC模型
1>.编写对应的数据库模型
#!/usr/bin/env python
#_*_conding:utf-8_*_
#@author :yinzhengjie
#blog:http://www.cnblogs.com/yinzhengjie/tag/python%E8%87%AA%E5%8A%A8%E5%8C%96%E8%BF%90%E7%BB%B4%E4%B9%8B%E8%B7%AF/ from django.db import models class IDC(models.Model):
name = models.CharField("机房名称",max_length=32)
address = models.CharField("机房地址",max_length=200)
phone = models.CharField("机房联系电话",max_length=15)
email = models.EmailField("邮件地址",default="")
letter = models.CharField("机房地址缩写名称",max_length=5) class Meta:
db_table = "idc"
2>.数据库迁移命令
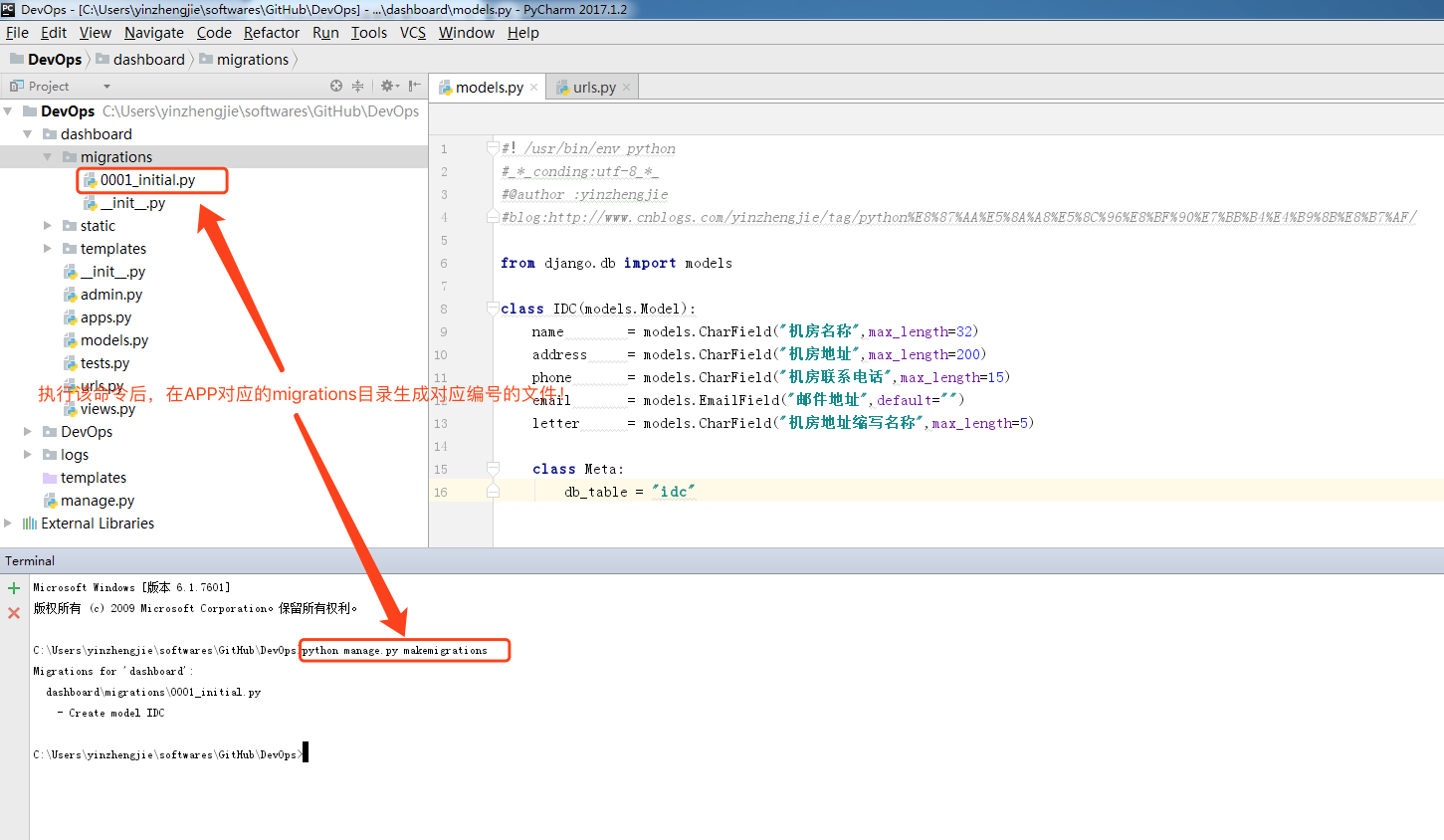
C:\Users\yinzhengjie\softwares\GitHub\DevOps>python manage.py makemigrations
Migrations for 'dashboard':
dashboard\migrations\0001_initial.py
- Create model IDC C:\Users\yinzhengjie\softwares\GitHub\DevOps>
负责基于你的模型修改创建一个新的迁移,并把这个迁移记录到本地的当前项目中一个叫migrations目录(python manage.py makemigrations)
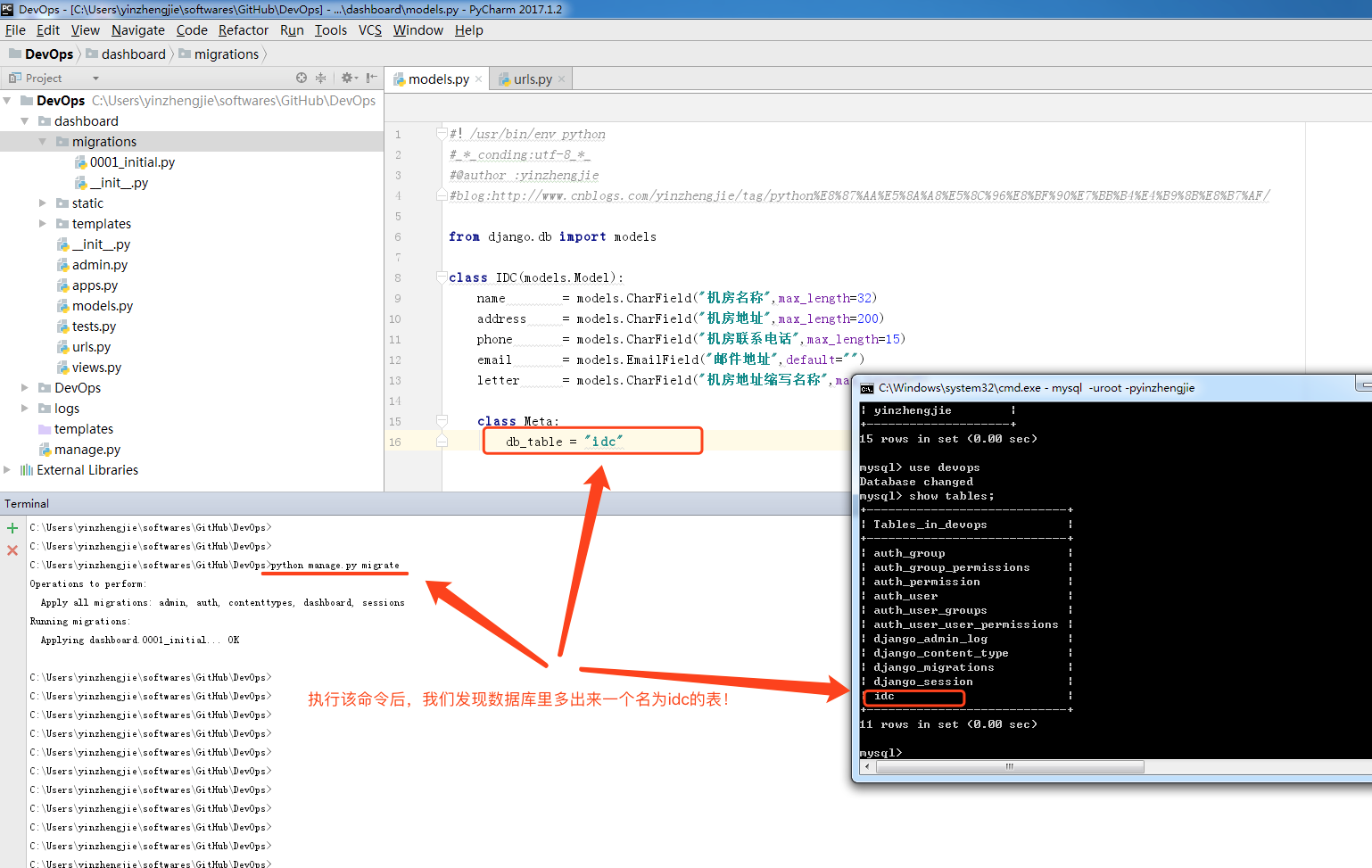
C:\Users\yinzhengjie\softwares\GitHub\DevOps>python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, dashboard, sessions
Running migrations:
Applying dashboard.0001_initial... OK C:\Users\yinzhengjie\softwares\GitHub\DevOps>
负责执行迁移,以及撤销和列出迁移的状态,我们可以简单的理解就是将我们写的python 代码翻译成SQL语句并执行(python manage.py migrate)注意,后面可以跟APP的名称,如果不加默认迁移所有
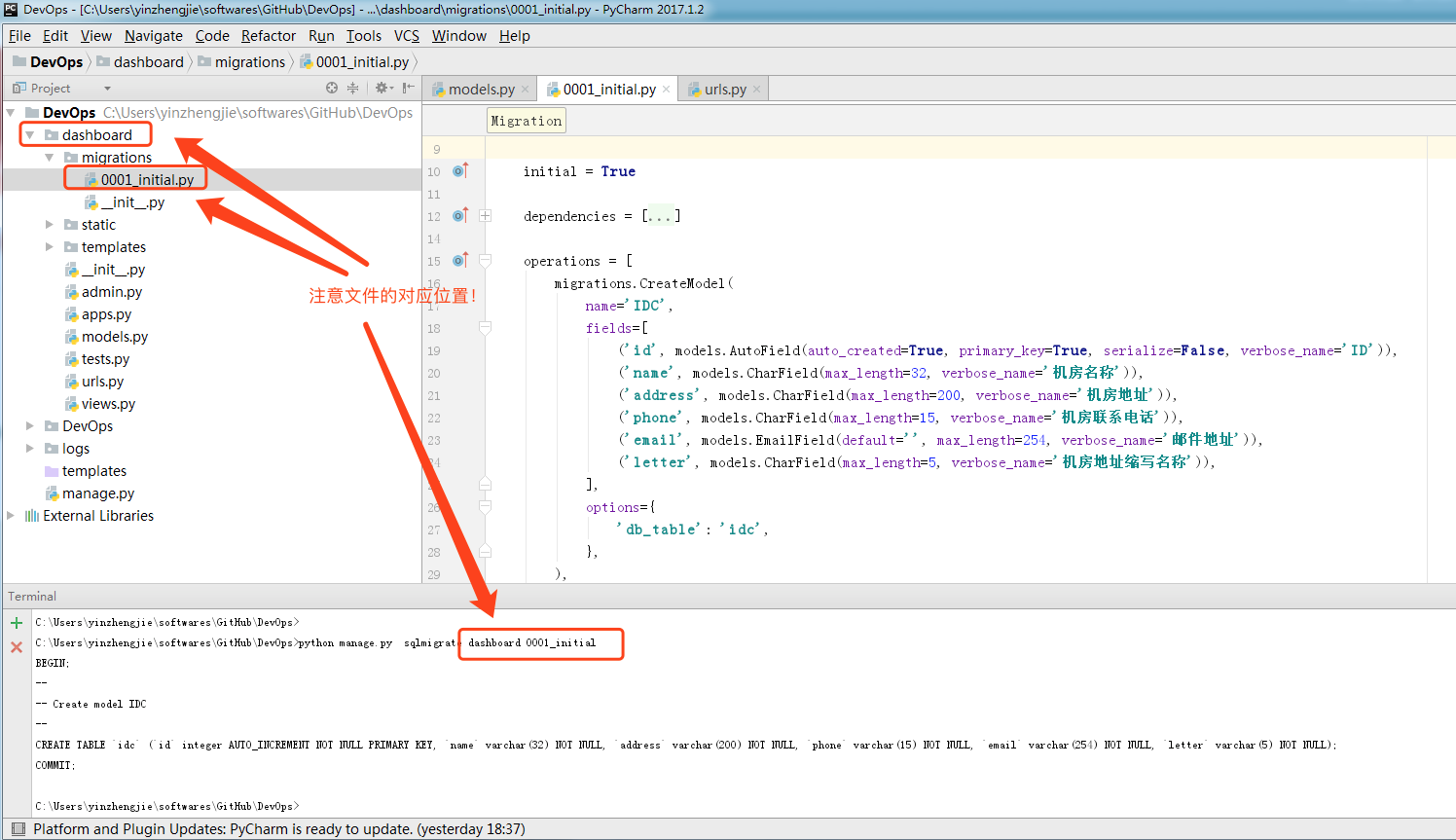
C:\Users\yinzhengjie\softwares\GitHub\DevOps>python manage.py sqlmigrate dashboard 0001_initial
BEGIN;
--
-- Create model IDC
--
CREATE TABLE `idc` (`id` integer AUTO_INCREMENT NOT NULL PRIMARY KEY, `name` varchar(32) NOT NULL, `address` varchar(200) NOT NULL, `phone` varchar(15) NOT NULL, `email` varchar(254) NOT NULL, `letter` varchar(5) NOT NULL);
COMMIT; C:\Users\yinzhengjie\softwares\GitHub\DevOps>
展示迁移的SQL语句(python manage.py sqlmigrate dashboard 0001_initial)
三.模型的增删改查操作
1>.创建对象
Django使用一种直观的方式把数据库表中的数据表示成Python对象:一个模型类代表数据库中的表,一个模型类的实例代表这个数据库中的一条特定的记录;
使用关键字实例化模型实例来创建一个对象,然后调用save()方法把它保存到数据库中;
也可以使用一条语句创建并保存一个对象,使用create()方法,此方法我们不推荐使用;
C:\Users\yinzhengjie\softwares\GitHub\DevOps>python manage.py shell
Python 3.6.0 (v3.6.0:41df79263a11, Dec 23 2016, 08:06:12) [MSC v.1900 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
(InteractiveConsole)
>>>
>>> from dashboard.models import IDC
>>> idc = IDC()
>>> idc.name = "亦庄机房"
>>> idc.address = "北京市亦庄经济技术开发区荣华南路11号"
>>> idc.phone = "010-53897114"
>>> idc.email = "yinzhengjie@caiq.org.cn"
>>> idc.letter = "yz"
>>> idc.save()
>>>
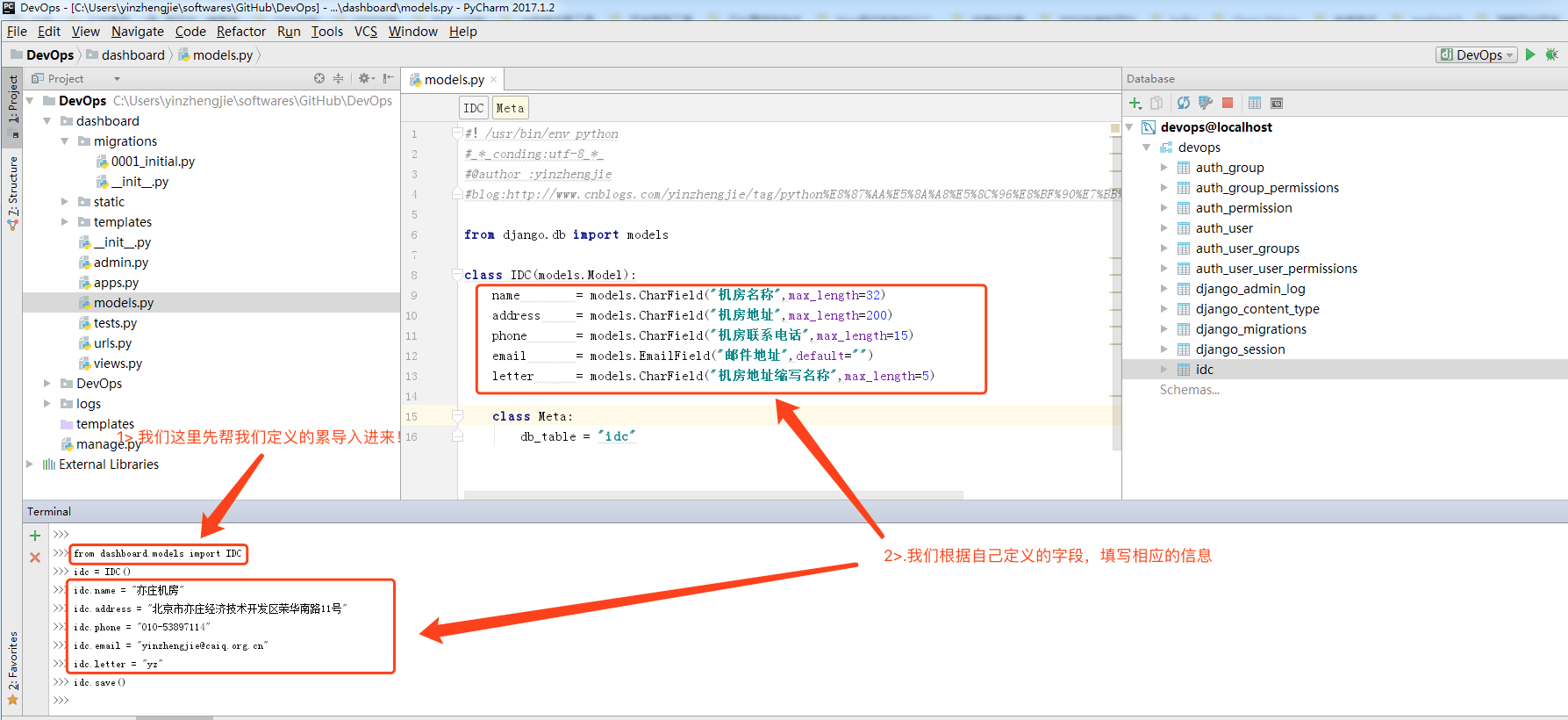
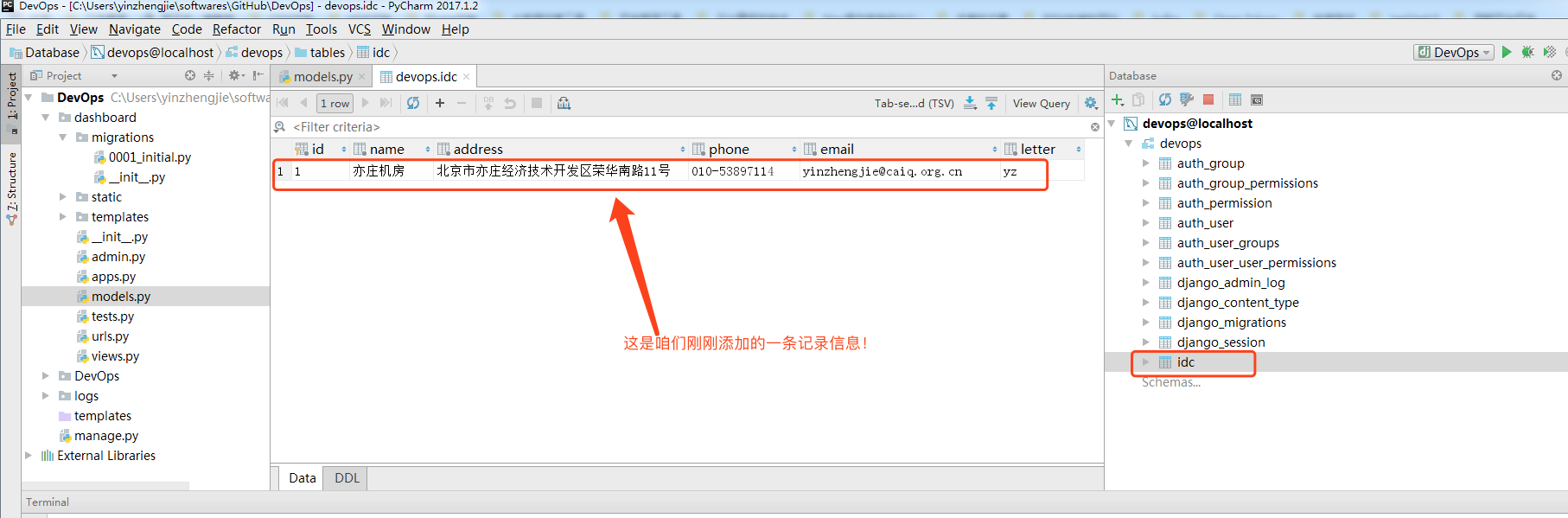
执行成功后,我们可以查看数据库有相应的信息生成:
2>.查询对象
通过模型中管理器构造一个查询集,来从你的数据库中获取对象。
查询集(querylist)表示从数据库中取出来的对象集合。它可以含有零个,一个或者多个过滤器。过滤器基于所给的参数限制查询的结果。从SQL的角度,查询集合SELECT语句等价,过滤器像WHERE和LIMIT一样的限制子句。
你可以从模型的管理器那里取得查询集。每个模型都至少有一个管理器,它默认命名为objects。通过模型类来直接访问它。
管理器只可以通过模型的类访问,而不可以通过模型的实例访问,目的是为了强制分区“表级别”的操作和“记录级别”的操作。
对于一个模型来说,管理器是查询集的主要来源。例如,User.objects.all() 返回包含数据库中所有User对象的一个查询集。
3>.获取所有对象
获取一个表中所有对象最简单的方式是全部获取。可以使用管理器的all()方法。
all()方法返回包含数据库中所有对象的一个查询集。
all_users = User.objects.all()
4>.使用过滤器获取特定对象
all()方法返回李一个包含数据库表中所有记录查询集。但在通常情况下,你往往想要获取的是完整数据集的一个子集。
要创建这样一个子集,你需要在原始的查询集上增加一些过滤条件。两个最普遍的途经是:
filter(**kwargs) 返回一个新的查询集,它包含满足查询参数的对象。
exclude(**kwargs)返回一个新的查询集,它包含不满足查询参数的对象。
查询参数(上面函数定义中的**kwargs)需要满足特定的格式。
使用过滤器获取特定对象示例:
要获取年份为2006的所有文章的查询集,可以使用lter()方法:
Entry.objects.filter(pub_date__year=2006)
利用默认的管理器,它相当于:
Entry.objects.all().filter(pub_date__year=2006)
5>.链式过滤
查询集的筛选结果本身还是查询集合,所以可以将筛选语句链接在一起。如下代码所示:
Entry.objects.filter(
headline__startswith='What’
).exclude(
pub_date__gte=datetime.date.today()
).filter(
pub_date__gte=datetime(2005, 1, 30)
)
这个例子最开始获取数据库中所有对象的一个查询集,之后增加一个过滤器,然后又增加一个排除,再之后又是另外一个过滤器。最后的结果仍然是一个查询集,它包含标题以“What”开头,发布日期在2005年1月30日至今天之间的所有记录。
6>.过滤后的查询集是独立的
每次你筛选一个查询集,得到的都是全新的另一个查询集,它和之前的查询集之间没有任何绑定关系。每次筛选都会创建一个独立的查询集。它可以被存储及复制使用。
q1 = Entry.objects.filter(headline__startswith="What")
q2 = q1.exclude(pub_date__gte=datetime.date.today())
q3 = q1.filter(pub_date__gte=datetime.date.today())
7>.查询集是惰性执行的
查询集是惰性执行的,创建查询集不会带来任何数据库的访问。你可以将过滤器保持一整天。直到查询集需要求值时,Django才会真正允许这个查询。
>>> q = Entry.objects.filter(headline__startswith="What")
>>> q = q.filter(pub_date__lte=datetime.date.today())
>>> q = q.exclude(body_text__icontains="food")
>>> print(q)
虽然它看上去又三次数据库访问,但事实上只有最红一行“print(q)”时访问一次数据库。一般来说,只有在“请求”查询集的结果时才会到数据库中去获取它们。当你确实需要结果时,查询集通过访问数据库来求值。
8>.获取一个单一的对象-get()
fillter()始终给你一个查询集,即使只有一个对象满足查询条件,这种情况下,查询集将只包含一个元素。
如果你直到只有一个对象满足你的查询,你可以使用管理器的get()方法,它直接返回该对象。
one_entry = Entry.objects.get(pk=1)
可以对get()使用任何查询表达式,和filter()一样。
使用get()和使用filter()的切片[0]有一点区别。如果没有结果满足查询,get()将引入一个DoesNotExsist异常。这个异常是正在查询的模型类的一个属性。所以在上面的代码中,如果没有主键为1的Entry对象,Django将引发一个Entry.DoesNotExist。
如果有多条记录满足get()的查询条件,Django也将报错。这种情况将引发MultipleObjectsRetruned,它同样是模型类自身的一个属性。
9>.限制查询集
可以使用Python的切片语法来限制查询集记录的数目。它等同于SQL的LIMIT和OFFSET子句。
>>> Entry.objects.all()[:5]
>>> Entry.objects.all()[5:10]
10>.字段查询
字段查询是只如何指定SQL WHERE子句的内容,它们通过查询方法集filter(),exclude()和get()的关键字参数指定。
查询的关键字参数的基本形式是“field__lookuptype=value”(中间是2个下划线)
>>> Entry.objects.filter(pub_date__lte='2006-01-01')
SELECT * FROM blog_entry WHERE pub_date <= '2006-01-01';
exact:精确匹配。
>>> Entry.objects.get(headline__exact=“Man bites dog”)
SELECT … WHERE headline = ‘Man bites dog’; >>> Blog.objects.get(id__exact=14)
>>> Blog.objects.get(id=14)
iexact:大小写不敏感的匹配。
contains:大小写铭感的包含指定字符串。
icontains:大小写不铭感的包含指定字符串。
startswith,endswith:以指定字符串开头或结尾。
istartswith,iendswith:以指定字符串开头或结尾。
in:在给定的列表内。
gt:大于
gte:大雨或者等于
lt:小于
lte:小于或等于
range:在指定范围内
year/mouth/day/week_day:对于日期和日期时间字段,匹配年/月/日/星期
11>.查询的快捷方式pk
Django提供一个查询快捷方式pk,它表示‘primary key’的意思
>>> Blog.objects.get(id__exact=14)
>>> Blog.objects.get(id=14)
>>> Blog.objects.get(pk=14)
12>.Order_by
默认情况下,QuerySet根据模型Meta类的ordering选项排序。你可以使用order_by方法给每个QuerySet指定特定的排序。
Entry.objects.filter(pub_date__year=2005).order_by('-pub_date', 'headline')
上面的结果将按照pub_date降序排序,然后在按照headline升序排序。“pub_date”前面的负号表示降序排序。隐式的是升序排序。若要随机排序,请使用“?”,像这样:
Entry.objects.order_by('?')
13>.values
返回一个ValuesQuerySet —— QuerySet 的一个子类,迭代时返回字典而不是模型实例对象。
每个字典表示一个对象,键对应于模型对象的属性名称。
values() 接收可选的位置参数*elds,它指定SELECT 应该限制哪些字段。如果指定字段, 每个字典将只包含指定的字段的键/值。如果没有指定字段,每个字典将包含数据库表中所 有字段的键和值。
User.objects.values("id", "username")
14>.values_list
与values() 类似,只是在迭代时返回的是元组而不是字典。每个元组包含传递给 values_list() 调用的字段的值 —— 所以第一个元素为第一个字段,以此类推。
User.objects.values_list('id', 'username')
15>.defer
在一些复杂的数据建模情况下,您的模型可能包含大量字段,其中一些可能包含大量数据 (例如,文本字段),或者需要昂贵的处理来将它们转换为Python对象。如果您在某些情 况下使用查询集的结果,当您最初获取数据时不知道是否需要这些特定字段,可以告诉 Django不要从数据库中检索它们。
User.objects.defer("username", "email")
16>.删除对象
删除对象使用delete()。这个方法将立即删除对象且没有返回值。
Entry.objects.filter(pub_date__year=2005).delete()
17>.拷贝模型实例
虽然没有内建的方法用于拷贝模型实例,但还是很容易创建一个新的实例并让它的所有字段都 拷贝过来。最简单的方法是,只需要将pk 设置为None。
blog = Blog(name='My blog', tagline='Blogging is easy')
blog.save() # blog.pk == 1
blog.pk = None
blog.save() # blog.pk == 2
18>.更新对象
更新对象使用update()
Entry.objects.filter(pub_date__year=2007).update(headline='Everything is the same')
update() 方法会立即执行并返回查询匹配的行数(如果有些行已经具有新的值,返回的行 数可能和被更新的行数不相等)
19>.专门取对象由某列值的操作
F()允许Django在未实际链接数据的情况下具有对数据库字段的值的引用。通常情况下我们 在更新数据时需要先从数据库里将原数据取出后方在内存里,然后编辑某些属性,最后提 交。例如
order = Order.objects.get(orderid='') order.amount += 1 order.save()
这时就可以使用F()方法,代码如下
from django.db.models import F order = Order.objects.get(orderid='') order.amount = F('amount') - 1 order.save()
20>.Q() -- 对对象的复杂查询
Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询。可以 组合使用 &(and),|(or),~(not)操作符,当一个操作符是用于两个Q的对象,它产生 个新的 对象 一个新的Q对象。
Order.objects.get(
Q(desc__startswith='Who'),
Q(create_time=date(2016, 10, 2)) | Q(create_time=date(2016,10, 6))
)
相当于:
SELECT * from polls WHERE question LIKE 'Who%' AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
21>.序列化模型对象
from django.core import serializers
data = serializers.serialize("json", SomeModel.objects.all())
序列化子集
from django.core import serializers
data = serializers.serialize("json", User.objects.all()[0:10], fields=('username','is_active'))
四.模型关系
1>.多对一
django是使用django.db.models.ForeignKey 定义多对一关系
class Manufacturer(models.Model):
name = models.CharField(max_length=30) class Car(models.Model):
manufacturer = models.ForeignKey(Manufacturer) name = models.CharField(max_length=30)
2>.多对一查询
car = Car.objects.get(pk=2)
car.manufacturer #返回一条Manufacturer 对象
如果模型有一个ForeignKey,那么该ForeignKey 所指的模型实例可以通过一个管理器返回 前一个有ForeignKey的模型的所有实例。默认情况下,这个管理器的名字为foo_set,其中 foo 是源模型的小写名称。该管理器返回的查询集可以用上一节提到的方式进行过滤和操作。
manufacturer = Manufacturer.objects.get(pk=1) manufacturer.car_set.all() # 返回多个car对象
3>.处理关联对象的其它方法
add(obj1, obj2, ...) #添加一指定的模型对象到关联的对象集中。 create(**kwargs) #创建一个新的对象,将它保存并放在关联的对象集中。返回新创建的对象。 remove(obj1, obj2, ...) #从关联的对象集中删除指定的模型对象。 clear() #从关联的对象集中删除所有的对象。
4>.多对多
要实现多对多,就要使用django.db.models.ManyToManyField类,和ForeignKey一样,它 也有一个位置参数,用来指定和它关联的Model。
如果不仅仅需要知道两个Model之间是多对多的关系,还需要知道这个关系的更多信息, 比如Person和Group是多对多的关系,每个person可以在多个group里,那么group里可以有多个person。
class Group(models.Model):
#... class Person(models.Model):
groups = models.ManyToManyField(Group)
在哪个模型中设置 ManyToManyField 并不重要,在两个模型中任选一个即可——不要在两个模型中都设置
5>.一对一
当某个对象想扩展自另一个对象时,最常用的方式就是在这个对象的主键上添加一对一关系。
运维开发笔记整理-Django模型语法的更多相关文章
- 运维开发笔记整理-django日志配置
运维开发笔记整理-django日志配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Django日志 Django使用python内建的logging模块打印日志,Pytho ...
- 运维开发笔记整理-template的使用
运维开发笔记整理-Django的template的使用 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在上一篇博客中我们学习了HttpResponse 和JsonResponse方 ...
- 运维开发笔记整理-创建django用户
运维开发笔记整理-创建django用户 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建普通用户 C:\Users\yinzhengjie\softwares\Pycharm ...
- 运维开发笔记整理-使用Django编写helloworld
运维开发笔记整理-使用Django编写helloworld 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.创建Django项目 1>.创建Django项目 djang ...
- 运维开发笔记整理-URL配置
运维开发笔记整理-URL配置 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.URL路由 对于高质量的Web应用来说,使用简洁,优雅的URL的路由是一个非常值得重视的细节.Dja ...
- 运维开发笔记整理-基于类的视图(CBV)
运维开发笔记整理-基于类的视图(CBV) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.FBV与CBV 1>.什么是FBV FBC(function base views ...
- 运维开发笔记整理-QueryDict对象
运维开发笔记整理-QueryDict对象 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 客户端发送数据请求有很多种,相信运维人员已经很清楚了,如果不太清楚的话可以参考我之前的学习笔 ...
- 运维开发笔记整理-JsonResponse对象
运维开发笔记整理-JsonResponse对象 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用HttpResponse发送json格式的数据 1>.HttpRespo ...
- 运维开发笔记整理-Request对象与Response对象
运维开发笔记整理-Request对象与HttpResponse对象 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.request对象 1>.什么是request 首先,我 ...
随机推荐
- Global.asax.cs 为 /.aspx 执行子请求时出错。 Server.Transfer
x 后台代码 Global.asax.cs protected void Application_Error(object sender, EventArgs e){Server.Transfer(& ...
- TestDirector(TD)—测试管理工具
简介 TestDirector是全球最大的软件测试工具提供商Mercury Interactive公司生产的企业级测试管理工具,也是业界第一个基于Web的测试管理系统,它可以在您公司内部或外部进行全球 ...
- SQL server触发器学习记录
作为C#程序员,我工作内容基本就是winform,wpf,asp.net.sql接触的比较少,今天突然来了一个ticket要我修改触发器脚本....只会select*的我顿感迷茫... 需求描述:as ...
- SOC中的DMIPS_GFLOPS_GMACS的含义
l DMIPS全称叫Dhrystone MIPS 这项测试是用来计算同一秒内系统的处理能力,它的单位以百万来计算,也就是(MIPS) 上面的意思也就是,这个处理器测整数计算能力为(200*100万) ...
- C++标准异常与自定义异常
参见https://www.runoob.com/cplusplus/cpp-exceptions-handling.html C++ 标准的异常 C++ 提供了一系列标准的异常,定义在 中,我们可以 ...
- [转帖]Linux中的find(-atime、-ctime、-mtime)指令分析
Linux中的find(-atime.-ctime.-mtime)指令分析 https://www.cnblogs.com/zhangjinjin01/p/5505970.html https://w ...
- [转帖]抢先AMD一步,英特尔推出新处理器,支持LPDDR5!
抢先AMD一步,英特尔推出新处理器,支持LPDDR5! http://www.eetop.cn/cpu_soc/6946240.html 2019.10 intel的最新技术发展. 近日,知名硬件爆料 ...
- scrapy服务化持久运行
如果要将scrapy做成服务持久运行,通常我们会尝试下面的方式,这样是不可行的: class myspider(scrapy.Spider): q = queue() #task qu ...
- Git手册(一):基本操作
Git小册 本手册参考自runoob及其他网络资源,仅用于学习交流 Git工作流程 一般工作流程 1.克隆 Git 资源作为工作目录. 2.在克隆的资源上添加或修改文件. 3.如果其他 ...
- kubernetes 实践三:使用kubeadm安装k8s1.16.0
环境版本说明: 三台vmware虚拟机,系统版本CentOS7.6. Kubernetes 1.16.0,当前最新版. flannel v0.11 docker 18.09 使用kubeadm可以简单 ...