分布式结构化存储系统-Kudu简介
分布式结构化存储系统-Kudu简介
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破。在追求高吞吐的批处理场景下,我们选用HDFS;在追求低延迟,有随机读写需求的场景下,我们选用HBase。那么是否存在一种系统,能结合两个系统的优点,同时支持高吞吐率和低延迟呢?Kudu的出现正式为了解决这以难题。
一.Kudu基本特点
Kudu是Cloudera开源的列式存储引擎,专门为了对快速变化的数据进行快速分析,填补了以往Hadoop存储层的空缺。Kudu具有以下几个特点:
(1)C++语言开发;
(2)可以高效处理类OLAP负载;
(3)可以与MapReduce,Spark以及Hadoop生态系统中其他组件进行友好集成;
(4)可与Imapla集成,替代目前Impala常用的HDFS+Parquet组合;
(5)灵活的一致性模型;
(6)顺序写和随机写并存的场景下,仍能达到良好的性能;
(7)高可用,使用Raft协议保证数据高可靠存储;
(8)结构化数据模型; Kudu的出现,有望解决目前Hadoop生态系统难以解决的一大类问题,比如:
(1)流式实时计算结果的实时更新和查询;
(2)时间序列相关应用,具体要求有:
1)查询海量历史数据;
2)查询个体数据,并要求快速返回;
(3)预测模型中,周期性更新模型,并根据历史数据快速做出决策。
二.Kudu数据模型与架构
kudu是一个强类型的纯列式存储数据库。类似于HBase,Kudu的表是由很多数据子集构成的,表被水平拆分成多个Tablet(类似于HBase的Region),这些Tablet被散布到不同机器上,以实现分布式的存储存储和读写。
Kudu有两种类型的组件:Master Server和Tablet Server。Kudu Master与HBase Master类似,主要功能包括:
(1)负责管理元数据,这些元数据包括Tablet的描述信息及位置信息;
(2)管理Tablet Server,监听Tablet Server的健康状态,一旦发生故障便触发容错;对于副本书过低的Tablet,启动复制任务来提高其副本数。
Master的所有信息都在cache中,因此速度非常快,每次查询都是毫秒级别。Kudu支持多Master,但只有一个Active Master,其余知识作为灾备,不提供服务,一旦Active Master出现故障,其他Master将采用Raft一致性协议重新选举产生新的Active Master。
Table Server用于存储实际的Tablet数据,通常每个Tablet有3个副本存放在不同的Tabale Server。同一个Table的副本分为leader和follower两种类别:每个Tablet只能有一个leader副本,这个副本为用户提供修改操作,然后将修改结果同步给follower;而follower只提供读服务,不提供修改服务;Tablet副本之间使用Raft协议来实现高可用,当leader所在的节点发生故障时,follower会重新选举leader。
三.Kudu与HBase对比
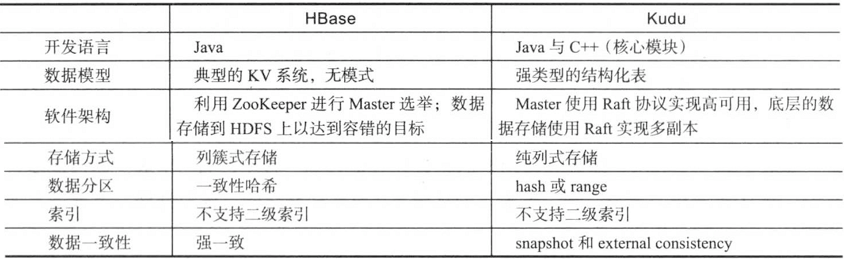
如上图所示,软件架构,存储方式等方面对比了HBase和Kudu。 总结起来,HBase是一个强一致性的KV系统,其扩展性和伸缩性是其最大的有点,通常用于海量数据更新和随机读取的场景;而kudu则是一个实现来多种一致性协议的结构化存储引擎,它通常与Impala结合使用,可用实时OLAP分析(流式导入实时分析)的场景。
分布式结构化存储系统-Kudu简介的更多相关文章
- 分布式结构化存储系统-HBase基本架构
分布式结构化存储系统-HBase基本架构 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在大数据领域中,除了直接以文件形式保存数据外,还有大量结构化和半结构化的数据,这类数据通常需 ...
- 分布式结构化存储系统-HBase应用案例
分布式结构化存储系统-HBase应用案例 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 为了让读者更进一步了解HBase在实际生成环境中的应用方法,在董西成的书里介绍两个经典的HB ...
- 分布式结构化存储系统-HBase访问方式
分布式结构化存储系统-HBase访问方式 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. HBase提供了多种访问方式,包括HBase shell,HBase API,数据收集组件( ...
- [翻译] Cassandra 分布式结构化存储系统
Cassandra 分布式结构化存储系统 摘要 Cassandra 是一个分布式存储系统,用于管理分布在许多商品服务器上的大量结构化数据,同时提供无单点故障(no single point of fa ...
- Solr系列四:Solr(solrj 、索引API 、 结构化数据导入)
一.SolrJ介绍 1. SolrJ是什么? Solr提供的用于JAVA应用中访问solr服务API的客户端jar.在我们的应用中引入solrj: <dependency> <gro ...
- Hadoop生态新增列式存储系统Kudu
Hadoop生态系统发展到现在,存储层主要由HDFS和HBase两个系统把持着,一直没有太大突破.在追求高吞吐的批处理场景下,我们选用HDFS,在追求低延迟,有随机读写需求的场景下,我们选用H ...
- Bigtable:一个分布式的结构化数据存储系统
Bigtable:一个分布式的结构化数据存储系统 摘要 Bigtable是一个管理结构化数据的分布式存储系统,它被设计用来处理海量数据:分布在数千台通用服务器上的PB级的数据.Google的很多项目将 ...
- Bigtable:结构化数据的分布式存储系统
Bigtable最初是谷歌设计用来存储大规模结构化数据的分布式系统,其可以在数以千计的商用服务器上存储高达PB级别的数据量.开源社区根据Bigtable的设计思路开发了HBase.其优势在于提供了高效 ...
- 分布式存储系统Kudu与HBase的简要分析与对比
本文来自网易云社区 作者:闽涛 背景 Cloudera在2016年发布了新型的分布式存储系统——kudu,kudu目前也是apache下面的开源项目.Hadoop生态圈中的技术繁多,HDFS作为底层数 ...
随机推荐
- matlab学习笔记10_3关系运算符和逻辑运算符
一起来学matlab-matlab学习笔记10 10_3关系运算符和逻辑运算符 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张德丰 ...
- [LeetCode] 109. Convert Sorted List to Binary Search Tree 把有序链表转成二叉搜索树
Given a singly linked list where elements are sorted in ascending order, convert it to a height bala ...
- Bcrypt.check_pass/3 用法
defmodule My do defstruct password: "", apassword_hash: "", aencrypted_password: ...
- 【视频开发】OpenCV中Mat,图像二维指针和CxImage类的转换
在做图像处理中,常用的函数接口有OpenCV中的Mat图像类,有时候需要直接用二维指针开辟内存直接存储图像数据,有时候需要用到CxImage类存储图像.本文主要是总结下这三类存储方式之间的图像数据的转 ...
- Go语言中的值类型和引用类型
一.值类型和引用类型值类型:int.float.bool和string这些类型都属于值类型,使用这些类型的变量直接指向存在内存中的值,值类型的变量的值存储在栈中.当使用等号=将一个变量的值赋给另一个变 ...
- [06]Go设计模式:适配器模式(Adapter Pattern)
目录 适配器模式 一.简介 二.代码 三.参考资料 适配器模式 一.简介 适配器模式(Adapter Pattern)是作为两个不兼容的接口之间的桥梁.这种类型的设计模式属于结构型模式,它结合了两个独 ...
- python技巧 — pip install 错误,超时
jieba库安装失败 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba wordcloud库安装失败 pip instal ...
- Oracle 11g 总结篇2
第一部分: 字段名的别名用""括起来,如:last_name as "姓名". 去除重复:在投影的字段名前加上 distinct 就可以了. 比如:select ...
- spring session cpu占用过高
集成spring session很简单,只需几行代码即可. @Configuration @EnableRedisHttpSession public class SessionConfig { ...
- 小贴士--Python
1.查看python安装好的包版本信息:pip list 原贴,有空完善.http://yangzb.iteye.com/blog/1824761 2.Python文件快速执行. 加头文件快速执行Py ...