Kubernetes集群安装(自己搭过,已搭好)
k8s安装目录
- 1. 组件版本 && 集群环境
- 2. 创建CA 证书和密钥
- 3. 部署高可用etcd 集群
- 4. 配置kubectl 命令行工具
- 5. 部署Flannel 网络
- 6. 部署master 节点
- 7. kube-apiserver 高可用
- 8. 部署Node 节点
- 9. 部署kubedns 插件
- 10. 部署Dashboard 插件
- 11. 部署Heapster 插件
- 12. 安装Ingress
- 13. 日志收集
- 14. 私有仓库harbor 搭建
- 15. 问题汇总
- 15.1 dashboard无法显示监控图
- 15.2 kube-proxy报错kube-proxy[2241]: E0502 15:55:13.889842 2241 conntrack.go:42] conntrack returned error: error looking for path of conntrack: exec: “conntrack”: executable file not found in $PATH
- 15.3 Unable to access kubernetes services: no route to host
- 15.4 使用NodePort 类型的服务,只能在POD 所在节点进行访问
- 参考资料
在该文档的基础上重新部署了最新的v1.8.2版本,实现了kube-apiserver的高可用、traefik ingress 的部署、在kubernetes上安装docker的私有仓库harbor、容器化kubernetes部分组建、使用阿里云日志服务收集日志。
部署完成后,你将理解系统各组件的交互原理,进而能快速解决实际问题,所以本文档主要适合于那些有一定kubernetes基础,想通过一步步部署的方式来学习和了解系统配置、运行原理的人。
本系列系文档适用于 CentOS 7、Ubuntu 16.04 及以上版本系统,由于启用了 TLS 双向认证、RBAC 授权等严格的安全机制,建议从头开始部署,否则可能会认证、授权等失败!
有人问我为什么这么长的文章不分拆成几篇文章啊?这样阅读起来也方便啊,然而在我自己学习的过程中,这种整个一篇文章把一件事情从头到尾讲清楚的形式是最好的,能给读者提供一种
沉浸式的学习体验,阅读完整个文章后有种酣畅淋漓的感觉,所以我选择这种一篇文章的形式。
1. 组件版本 && 集群环境
组件版本
- Kubernetes 1.8.2(1.9.x版本也可以,只有细微的差别)
- Docker 17.10.0-ce
- Etcd 3.2.9
- Flanneld
- TLS 认证通信(所有组件,如etcd、kubernetes master 和node)
- RBAC 授权
- kubelet TLS Bootstrapping
- kubedns、dashboard、heapster等插件
- harbor,使用nfs后端存储
etcd 集群 && k8s master 机器 && k8s node 机器
- master01:192.168.1.137
- master02:192.168.1.138
- master03/node03:192.168.1.170
- 由于机器有限,所以我们将master03 也作为node 节点,后续有新的机器增加即可
- node01: 192.168.1.161
- node02: 192.168.1.162
集群环境变量
后面的嗯部署将会使用到的全局变量,定义如下(根据自己的机器、网络修改):
# TLS Bootstrapping 使用的Token,可以使用命令 head -c /dev/urandom | od -An -t x | tr -d ' ' 生成
BOOTSTRAP_TOKEN="8981b594122ebed7596f1d3b69c78223" # 建议使用未用的网段来定义服务网段和Pod 网段
# 服务网段(Service CIDR),部署前路由不可达,部署后集群内部使用IP:Port可达
SERVICE_CIDR="10.254.0.0/16"
# Pod 网段(Cluster CIDR),部署前路由不可达,部署后路由可达(flanneld 保证)
CLUSTER_CIDR="172.30.0.0/16" # 服务端口范围(NodePort Range)
NODE_PORT_RANGE="30000-32766" # etcd集群服务地址列表
ETCD_ENDPOINTS="https://192.168.1.137:2379,https://192.168.1.138:2379,https://192.168.1.170:2379" # flanneld 网络配置前缀
FLANNEL_ETCD_PREFIX="/kubernetes/network" # kubernetes 服务IP(预先分配,一般为SERVICE_CIDR中的第一个IP)
CLUSTER_KUBERNETES_SVC_IP="10.254.0.1" # 集群 DNS 服务IP(从SERVICE_CIDR 中预先分配)
CLUSTER_DNS_SVC_IP="10.254.0.2" # 集群 DNS 域名
CLUSTER_DNS_DOMAIN="cluster.local." # MASTER API Server 地址
MASTER_URL="k8s-api.virtual.local"
将上面变量保存为: env.sh,然后将脚本拷贝到所有机器的/usr/k8s/bin目录
为方便后面迁移,我们在集群内定义一个域名用于访问apiserver,在每个节点的/etc/hosts文件中添加记录:192.168.1.137 k8s-api.virtual.local k8s-api
其中192.168.1.137为master01 的IP,暂时使用该IP 来做apiserver 的负载地址
如果你使用的是阿里云的ECS 服务,强烈建议你先将上述节点的安全组配置成允许所有访问,不然在安装过程中会遇到各种访问不了的问题,待集群配置成功以后再根据需要添加安全限制。
2. 创建CA 证书和密钥
kubernetes 系统各个组件需要使用TLS证书对通信进行加密,这里我们使用CloudFlare的PKI 工具集cfssl 来生成Certificate Authority(CA) 证书和密钥文件, CA 是自签名的证书,用来签名后续创建的其他TLS 证书。
安装 CFSSL
$ wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
$ chmod +x cfssl_linux-amd64
$ sudo mv cfssl_linux-amd64 /usr/k8s/bin/cfssl $ wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
$ chmod +x cfssljson_linux-amd64
$ sudo mv cfssljson_linux-amd64 /usr/k8s/bin/cfssljson $ wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
$ chmod +x cfssl-certinfo_linux-amd64
$ sudo mv cfssl-certinfo_linux-amd64 /usr/k8s/bin/cfssl-certinfo $ export PATH=/usr/k8s/bin:$PATH
$ mkdir ssl && cd ssl
$ cfssl print-defaults config > config.json
$ cfssl print-defaults csr > csr.json
为了方便,将/usr/k8s/bin设置成环境变量,为了重启也有效,可以将上面的export PATH=/usr/k8s/bin:$PATH添加到/etc/rc.local文件中。
创建CA
修改上面创建的config.json文件为ca-config.json:
$ cat ca-config.json
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
config.json:可以定义多个profiles,分别指定不同的过期时间、使用场景等参数;后续在签名证书时使用某个profile;signing: 表示该证书可用于签名其它证书;生成的ca.pem 证书中CA=TRUE;server auth: 表示client 可以用该CA 对server 提供的证书进行校验;client auth: 表示server 可以用该CA 对client 提供的证书进行验证。
修改CA 证书签名请求为ca-csr.json:
$ cat ca-csr.json
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
CN:Common Name,kube-apiserver 从证书中提取该字段作为请求的用户名(User Name);浏览器使用该字段验证网站是否合法;O:Organization,kube-apiserver 从证书中提取该字段作为请求用户所属的组(Group);
生成CA 证书和私钥:
$ cfssl gencert -initca ca-csr.json | cfssljson -bare ca
$ ls ca*
$ ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
分发证书
将生成的CA 证书、密钥文件、配置文件拷贝到所有机器的/etc/kubernetes/ssl目录下面:
$ sudo mkdir -p /etc/kubernetes/ssl
$ sudo cp ca* /etc/kubernetes/ssl
3. 部署高可用etcd 集群
kubernetes 系统使用etcd存储所有的数据,我们这里部署3个节点的etcd 集群,这3个节点直接复用kubernetes master的3个节点,分别命名为etcd01、etcd02、etcd03:
- etcd01:192.168.1.137
- etcd02:192.168.1.138
- etcd03:192.168.1.170
定义环境变量
使用到的变量如下:
$ export NODE_NAME=etcd01 # 当前部署的机器名称(随便定义,只要能区分不同机器即可)
$ export NODE_IP=192.168.1.137 # 当前部署的机器IP
$ export NODE_IPS="192.168.1.137 192.168.1.138 192.168.1.170" # etcd 集群所有机器 IP
$ # etcd 集群间通信的IP和端口
$ export ETCD_NODES=etcd01=https://192.168.1.137:2380,etcd02=https://192.168.1.138:2380,etcd03=https://192.168.1.170:2380
$ # 导入用到的其它全局变量:ETCD_ENDPOINTS、FLANNEL_ETCD_PREFIX、CLUSTER_CIDR
$ source /usr/k8s/bin/env.sh
下载etcd 二进制文件
到https://github.com/coreos/etcd/releases页面下载最新版本的二进制文件:
$ wget https://github.com/coreos/etcd/releases/download/v3.2.9/etcd-v3.2.9-linux-amd64.tar.gz
$ tar -xvf etcd-v3.2.9-linux-amd64.tar.gz
$ sudo mv etcd-v3.2.9-linux-amd64/etcd* /usr/k8s/bin/
创建TLS 密钥和证书
为了保证通信安全,客户端(如etcdctl)与etcd 集群、etcd 集群之间的通信需要使用TLS 加密。
创建etcd 证书签名请求:
$ cat > etcd-csr.json <<EOF
{
"CN": "etcd",
"hosts": [
"127.0.0.1",
"${NODE_IP}"
],
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
hosts字段指定授权使用该证书的etcd节点IP
生成etcd证书和私钥:
$ cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem \
-ca-key=/etc/kubernetes/ssl/ca-key.pem \
-config=/etc/kubernetes/ssl/ca-config.json \
-profile=kubernetes etcd-csr.json | cfssljson -bare etcd
$ ls etcd*
etcd.csr etcd-csr.json etcd-key.pem etcd.pem
$ sudo mkdir -p /etc/etcd/ssl
$ sudo mv etcd*.pem /etc/etcd/ssl/
创建etcd 的systemd unit 文件
$ sudo mkdir -p /var/lib/etcd # 必须要先创建工作目录
$ cat > etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
WorkingDirectory=/var/lib/etcd/
ExecStart=/usr/k8s/bin/etcd \\
--name=${NODE_NAME} \\
--cert-file=/etc/etcd/ssl/etcd.pem \\
--key-file=/etc/etcd/ssl/etcd-key.pem \\
--peer-cert-file=/etc/etcd/ssl/etcd.pem \\
--peer-key-file=/etc/etcd/ssl/etcd-key.pem \\
--trusted-ca-file=/etc/kubernetes/ssl/ca.pem \\
--peer-trusted-ca-file=/etc/kubernetes/ssl/ca.pem \\
--initial-advertise-peer-urls=https://${NODE_IP}:2380 \\
--listen-peer-urls=https://${NODE_IP}:2380 \\
--listen-client-urls=https://${NODE_IP}:2379,http://127.0.0.1:2379 \\
--advertise-client-urls=https://${NODE_IP}:2379 \\
--initial-cluster-token=etcd-cluster- \\
--initial-cluster=${ETCD_NODES} \\
--initial-cluster-state=new \\
--data-dir=/var/lib/etcd
Restart=on-failure
RestartSec=
LimitNOFILE=
[Install]
WantedBy=multi-user.target
EOF
- 指定
etcd的工作目录和数据目录为/var/lib/etcd,需要在启动服务前创建这个目录; - 为了保证通信安全,需要指定etcd 的公私钥(cert-file和key-file)、Peers通信的公私钥和CA 证书(peer-cert-file、peer-key-file、peer-trusted-ca-file)、客户端的CA 证书(trusted-ca-file);
--initial-cluster-state值为new时,--name的参数值必须位于--initial-cluster列表中;
启动etcd 服务
$ sudo mv etcd.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable etcd
$ sudo systemctl start etcd
$ sudo systemctl status etcd
最先启动的etcd 进程会卡住一段时间,等待其他节点启动加入集群,在所有的etcd 节点重复上面的步骤,直到所有的机器etcd 服务都已经启动
验证服务
部署完etcd 集群后,在任一etcd 节点上执行下面命令:
for ip in ${NODE_IPS}; do
ETCDCTL_API= /usr/k8s/bin/etcdctl \
--endpoints=https://${ip}:2379 \
--cacert=/etc/kubernetes/ssl/ca.pem \
--cert=/etc/etcd/ssl/etcd.pem \
--key=/etc/etcd/ssl/etcd-key.pem \
endpoint health; done
输出如下结果:
https://192.168.1.137:2379 is healthy: successfully committed proposal: took = 1.509032ms
https://192.168.1.138:2379 is healthy: successfully committed proposal: took = 1.639228ms
https://192.168.1.170:2379 is healthy: successfully committed proposal: took = 1.4152ms
可以看到上面的信息3个节点上的etcd 均为healthy,则表示集群服务正常。
4. 配置kubectl 命令行工具
kubectl默认从~/.kube/config配置文件中获取访问kube-apiserver 地址、证书、用户名等信息,需要正确配置该文件才能正常使用kubectl命令。
需要将下载的kubectl 二进制文件和生产的~/.kube/config配置文件拷贝到需要使用kubectl 命令的机器上。
很多童鞋说这个地方不知道在哪个节点上执行,
kubectl只是一个和kube-apiserver进行交互的一个命令行工具,所以你想安装到那个节点都行,master或者node任意节点都可以,比如你先在master节点上安装,这样你就可以在master节点使用kubectl命令行工具了,如果你想在node节点上使用(当然安装的过程肯定会用到的),你就把master上面的kubectl二进制文件和~/.kube/config文件拷贝到对应的node节点上就行了。
环境变量
$ source /usr/k8s/bin/env.sh
$ export KUBE_APISERVER="https://${MASTER_URL}:6443"注意这里的
KUBE_APISERVER地址,因为我们还没有安装haproxy,所以暂时需要手动指定使用apiserver的6443端口,等haproxy安装完成后就可以用使用443端口转发到6443端口去了。
- 变量KUBE_APISERVER 指定kubelet 访问的kube-apiserver 的地址,后续被写入
~/.kube/config配置文件
下载kubectl
$ wget https://dl.k8s.io/v1.8.2/kubernetes-client-linux-amd64.tar.gz # 如果服务器上下载不下来,可以想办法下载到本地,然后scp上去即可
$ tar -xzvf kubernetes-client-linux-amd64.tar.gz
$ sudo cp kubernetes/client/bin/kube* /usr/k8s/bin/
$ sudo chmod a+x /usr/k8s/bin/kube*
$ export PATH=/usr/k8s/bin:$PATH
创建admin 证书
kubectl 与kube-apiserver 的安全端口通信,需要为安全通信提供TLS 证书和密钥。创建admin 证书签名请求:
$ cat > admin-csr.json <<EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
- 后续
kube-apiserver使用RBAC 对客户端(如kubelet、kube-proxy、Pod)请求进行授权 kube-apiserver预定义了一些RBAC 使用的RoleBindings,如cluster-admin 将Groupsystem:masters与Rolecluster-admin绑定,该Role 授予了调用kube-apiserver所有API 的权限- O 指定了该证书的Group 为
system:masters,kubectl使用该证书访问kube-apiserver时,由于证书被CA 签名,所以认证通过,同时由于证书用户组为经过预授权的system:masters,所以被授予访问所有API 的劝降 - hosts 属性值为空列表
生成admin 证书和私钥:
$ cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem \
-ca-key=/etc/kubernetes/ssl/ca-key.pem \
-config=/etc/kubernetes/ssl/ca-config.json \
-profile=kubernetes admin-csr.json | cfssljson -bare admin
$ ls admin
admin.csr admin-csr.json admin-key.pem admin.pem
$ sudo mv admin*.pem /etc/kubernetes/ssl/
创建kubectl kubeconfig 文件
# 设置集群参数
$ kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER}
# 设置客户端认证参数
$ kubectl config set-credentials admin \
--client-certificate=/etc/kubernetes/ssl/admin.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/ssl/admin-key.pem \
--token=${BOOTSTRAP_TOKEN}
# 设置上下文参数
$ kubectl config set-context kubernetes \
--cluster=kubernetes \
--user=admin
# 设置默认上下文
$ kubectl config use-context kubernetes
admin.pem证书O 字段值为system:masters,kube-apiserver预定义的 RoleBindingcluster-admin将 Groupsystem:masters与 Rolecluster-admin绑定,该 Role 授予了调用kube-apiserver相关 API 的权限- 生成的kubeconfig 被保存到
~/.kube/config文件
分发kubeconfig 文件
将~/.kube/config文件拷贝到运行kubectl命令的机器的~/.kube/目录下去。
5. 部署Flannel 网络
kubernetes 要求集群内各节点能通过Pod 网段互联互通,下面我们来使用Flannel 在所有节点上创建互联互通的Pod 网段的步骤。
需要在所有的Node节点安装。
环境变量
$ export NODE_IP=192.168.1.137 # 当前部署节点的IP
# 导入全局变量
$ source /usr/k8s/bin/env.sh
创建TLS 密钥和证书
etcd 集群启用了双向TLS 认证,所以需要为flanneld 指定与etcd 集群通信的CA 和密钥。
创建flanneld 证书签名请求:
$ cat > flanneld-csr.json <<EOF
{
"CN": "flanneld",
"hosts": [],
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
生成flanneld 证书和私钥:
$ cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem \
-ca-key=/etc/kubernetes/ssl/ca-key.pem \
-config=/etc/kubernetes/ssl/ca-config.json \
-profile=kubernetes flanneld-csr.json | cfssljson -bare flanneld
$ ls flanneld*
flanneld.csr flanneld-csr.json flanneld-key.pem flanneld.pem
$ sudo mkdir -p /etc/flanneld/ssl
$ sudo mv flanneld*.pem /etc/flanneld/ssl
向etcd 写入集群Pod 网段信息
该步骤只需在第一次部署Flannel 网络时执行,后续在其他节点上部署Flanneld 时无需再写入该信息
$ etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/etc/kubernetes/ssl/ca.pem \
--cert-file=/etc/flanneld/ssl/flanneld.pem \
--key-file=/etc/flanneld/ssl/flanneld-key.pem \
set ${FLANNEL_ETCD_PREFIX}/config '{"Network":"'${CLUSTER_CIDR}'", "SubnetLen": 24, "Backend": {"Type": "vxlan"}}'
# 得到如下反馈信息
{"Network":"172.30.0.0/16", "SubnetLen": , "Backend": {"Type": "vxlan"}}
- 写入的 Pod 网段(${CLUSTER_CIDR},172.30.0.0/16) 必须与
kube-controller-manager的--cluster-cidr选项值一致;
安装和配置flanneld
前往flanneld release页面下载最新版的flanneld 二进制文件:
$ mkdir flannel
$ wget https://github.com/coreos/flannel/releases/download/v0.9.0/flannel-v0.9.0-linux-amd64.tar.gz
$ tar -xzvf flannel-v0.9.0-linux-amd64.tar.gz -C flannel
$ sudo cp flannel/{flanneld,mk-docker-opts.sh} /usr/k8s/bin
创建flanneld的systemd unit 文件
$ cat > flanneld.service << EOF
[Unit]
Description=Flanneld overlay address etcd agent
After=network.target
After=network-online.target
Wants=network-online.target
After=etcd.service
Before=docker.service
[Service]
Type=notify
ExecStart=/usr/k8s/bin/flanneld \\
-etcd-cafile=/etc/kubernetes/ssl/ca.pem \\
-etcd-certfile=/etc/flanneld/ssl/flanneld.pem \\
-etcd-keyfile=/etc/flanneld/ssl/flanneld-key.pem \\
-etcd-endpoints=${ETCD_ENDPOINTS} \\
-etcd-prefix=${FLANNEL_ETCD_PREFIX}
ExecStartPost=/usr/k8s/bin/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker
Restart=on-failure
[Install]
WantedBy=multi-user.target
RequiredBy=docker.service
EOF
mk-docker-opts.sh脚本将分配给flanneld 的Pod 子网网段信息写入到/run/flannel/docker文件中,后续docker 启动时使用这个文件中的参数值为 docker0 网桥- flanneld 使用系统缺省路由所在的接口和其他节点通信,对于有多个网络接口的机器(内网和公网),可以用
--iface选项值指定通信接口(上面的 systemd unit 文件没指定这个选项)
启动flanneld
$ sudo cp flanneld.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable flanneld
$ sudo systemctl start flanneld
$ systemctl status flanneld
检查flanneld 服务
ifconfig flannel.
检查分配给各flanneld 的Pod 网段信息
$ # 查看集群 Pod 网段(/)
$ etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/etc/kubernetes/ssl/ca.pem \
--cert-file=/etc/flanneld/ssl/flanneld.pem \
--key-file=/etc/flanneld/ssl/flanneld-key.pem \
get ${FLANNEL_ETCD_PREFIX}/config
{ "Network": "172.30.0.0/16", "SubnetLen": , "Backend": { "Type": "vxlan" } }
$ # 查看已分配的 Pod 子网段列表(/)
$ etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/etc/kubernetes/ssl/ca.pem \
--cert-file=/etc/flanneld/ssl/flanneld.pem \
--key-file=/etc/flanneld/ssl/flanneld-key.pem \
ls ${FLANNEL_ETCD_PREFIX}/subnets
/kubernetes/network/subnets/172.30.77.0-
$ # 查看某一 Pod 网段对应的 flanneld 进程监听的 IP 和网络参数
$ etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/etc/kubernetes/ssl/ca.pem \
--cert-file=/etc/flanneld/ssl/flanneld.pem \
--key-file=/etc/flanneld/ssl/flanneld-key.pem \
get ${FLANNEL_ETCD_PREFIX}/subnets/172.30.77.0-
{"PublicIP":"192.168.1.137","BackendType":"vxlan","BackendData":{"VtepMAC":"62:fc:03:83:1b:2b"}}
确保各节点间Pod 网段能互联互通
在各个节点部署完Flanneld 后,查看已分配的Pod 子网段列表:
$ etcdctl \
--endpoints=${ETCD_ENDPOINTS} \
--ca-file=/etc/kubernetes/ssl/ca.pem \
--cert-file=/etc/flanneld/ssl/flanneld.pem \
--key-file=/etc/flanneld/ssl/flanneld-key.pem \
ls ${FLANNEL_ETCD_PREFIX}/subnets /kubernetes/network/subnets/172.30.19.0-
/kubernetes/network/subnets/172.30.30.0-
/kubernetes/network/subnets/172.30.77.0-
/kubernetes/network/subnets/172.30.41.0-
/kubernetes/network/subnets/172.30.83.0-
当前五个节点分配的 Pod 网段分别是:172.30.77.0-24、172.30.30.0-24、172.30.19.0-24、172.30.41.0-24、172.30.83.0-24。
6. 部署master 节点
kubernetes master 节点包含的组件有:
- kube-apiserver
- kube-scheduler
- kube-controller-manager
目前这3个组件需要部署到同一台机器上:(后面再部署高可用的master)
kube-scheduler、kube-controller-manager和kube-apiserver三者的功能紧密相关;- 同时只能有一个
kube-scheduler、kube-controller-manager进程处于工作状态,如果运行多个,则需要通过选举产生一个 leader;
master 节点与node 节点上的Pods 通过Pod 网络通信,所以需要在master 节点上部署Flannel 网络。
环境变量
$ export NODE_IP=192.168.1.137 # 当前部署的master 机器IP
$ source /usr/k8s/bin/env.sh
下载最新版本的二进制文件
在kubernetes changelog 页面下载最新版本的文件:
$ wget https://dl.k8s.io/v1.8.2/kubernetes-server-linux-amd64.tar.gz
$ tar -xzvf kubernetes-server-linux-amd64.tar.gz
将二进制文件拷贝到/usr/k8s/bin目录
$ sudo cp -r server/bin/{kube-apiserver,kube-controller-manager,kube-scheduler} /usr/k8s/bin/
创建kubernetes 证书
创建kubernetes 证书签名请求:
$ cat > kubernetes-csr.json <<EOF
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"${NODE_IP}",
"${MASTER_URL}",
"${CLUSTER_KUBERNETES_SVC_IP}",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- 如果 hosts 字段不为空则需要指定授权使用该证书的 IP 或域名列表,所以上面分别指定了当前部署的 master 节点主机 IP 以及apiserver 负载的内部域名
- 还需要添加 kube-apiserver 注册的名为
kubernetes的服务 IP (Service Cluster IP),一般是 kube-apiserver--service-cluster-ip-range选项值指定的网段的第一个IP,如 “10.254.0.1”
生成kubernetes 证书和私钥:
$ cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem \
-ca-key=/etc/kubernetes/ssl/ca-key.pem \
-config=/etc/kubernetes/ssl/ca-config.json \
-profile=kubernetes kubernetes-csr.json | cfssljson -bare kubernetes
$ ls kubernetes*
kubernetes.csr kubernetes-csr.json kubernetes-key.pem kubernetes.pem
$ sudo mkdir -p /etc/kubernetes/ssl/
$ sudo mv kubernetes*.pem /etc/kubernetes/ssl/
6.1 配置和启动kube-apiserver
创建kube-apiserver 使用的客户端token 文件
kubelet 首次启动时向kube-apiserver 发送TLS Bootstrapping 请求,kube-apiserver 验证请求中的token 是否与它配置的token.csv 一致,如果一致则自动为kubelet 生成证书和密钥。
$ # 导入的 environment.sh 文件定义了 BOOTSTRAP_TOKEN 变量
$ cat > token.csv <<EOF
${BOOTSTRAP_TOKEN},kubelet-bootstrap,,"system:kubelet-bootstrap"
EOF
$ sudo mv token.csv /etc/kubernetes/
创建kube-apiserver 的systemd unit文件
$ cat > kube-apiserver.service <<EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
ExecStart=/usr/k8s/bin/kube-apiserver \\
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,DefaultStorageClass,ResourceQuota \\
--advertise-address=${NODE_IP} \\
--bind-address=0.0.0.0 \\
--insecure-bind-address=${NODE_IP} \\
--authorization-mode=Node,RBAC \\
--runtime-config=rbac.authorization.k8s.io/v1alpha1 \\
--kubelet-https=true \\
--experimental-bootstrap-token-auth \\
--token-auth-file=/etc/kubernetes/token.csv \\
--service-cluster-ip-range=${SERVICE_CIDR} \\
--service-node-port-range=${NODE_PORT_RANGE} \\
--tls-cert-file=/etc/kubernetes/ssl/kubernetes.pem \\
--tls-private-key-file=/etc/kubernetes/ssl/kubernetes-key.pem \\
--client-ca-file=/etc/kubernetes/ssl/ca.pem \\
--service-account-key-file=/etc/kubernetes/ssl/ca-key.pem \\
--etcd-cafile=/etc/kubernetes/ssl/ca.pem \\
--etcd-certfile=/etc/kubernetes/ssl/kubernetes.pem \\
--etcd-keyfile=/etc/kubernetes/ssl/kubernetes-key.pem \\
--etcd-servers=${ETCD_ENDPOINTS} \\
--enable-swagger-ui=true \\
--allow-privileged=true \\
--apiserver-count= \\
--audit-log-maxage= \\
--audit-log-maxbackup= \\
--audit-log-maxsize= \\
--audit-log-path=/var/lib/audit.log \\
--audit-policy-file=/etc/kubernetes/audit-policy.yaml \\
--event-ttl=1h \\
--logtostderr=true \\
--v=
Restart=on-failure
RestartSec=
Type=notify
LimitNOFILE=
[Install]
WantedBy=multi-user.target
EOF
- 如果你安装的是1.9.x版本的,一定要记住上面的参数
experimental-bootstrap-token-auth,需要替换成enable-bootstrap-token-auth,因为这个参数在1.9.x里面已经废弃掉了 - kube-apiserver 1.6 版本开始使用 etcd v3 API 和存储格式
--authorization-mode=RBAC指定在安全端口使用RBAC 授权模式,拒绝未通过授权的请求- kube-scheduler、kube-controller-manager 一般和 kube-apiserver 部署在同一台机器上,它们使用非安全端口和 kube-apiserver通信
- kubelet、kube-proxy、kubectl 部署在其它 Node 节点上,如果通过安全端口访问 kube-apiserver,则必须先通过 TLS 证书认证,再通过 RBAC 授权
- kube-proxy、kubectl 通过使用证书里指定相关的 User、Group 来达到通过 RBAC 授权的目的
- 如果使用了 kubelet TLS Boostrap 机制,则不能再指定
--kubelet-certificate-authority、--kubelet-client-certificate和--kubelet-client-key选项,否则后续 kube-apiserver 校验 kubelet 证书时出现 ”x509: certificate signed by unknown authority“ 错误 --admission-control值必须包含ServiceAccount,否则部署集群插件时会失败--bind-address不能为127.0.0.1--service-cluster-ip-range指定 Service Cluster IP 地址段,该地址段不能路由可达--service-node-port-range=${NODE_PORT_RANGE}指定 NodePort 的端口范围- 缺省情况下 kubernetes 对象保存在
etcd/registry路径下,可以通过--etcd-prefix参数进行调整 - kube-apiserver 1.8版本后需要在
--authorization-mode参数中添加Node,即:--authorization-mode=Node,RBAC,否则Node 节点无法注册 - 注意要开启审查日志功能,指定
--audit-log-path参数是不够的,这只是指定了日志的路径,还需要指定一个审查日志策略文件:--audit-policy-file,我们也可以使用日志收集工具收集相关的日志进行分析。
审查日志策略文件内容如下:(/etc/kubernetes/audit-policy.yaml)
apiVersion: audit.k8s.io/v1beta1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"] # Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"] # Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"] # Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version" # Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"] # Log configmap and secret changes in all other namespaces at the Metadata level.
- level: Metadata
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"] # Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included. # A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
审查日志的相关配置可以查看文档了解:https://kubernetes.io/docs/tasks/debug-application-cluster/audit/
启动kube-apiserver
$ sudo cp kube-apiserver.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable kube-apiserver
$ sudo systemctl start kube-apiserver
$ sudo systemctl status kube-apiserver
6.2 配置和启动kube-controller-manager
创建kube-controller-manager 的systemd unit 文件
$ cat > kube-controller-manager.service <<EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/k8s/bin/kube-controller-manager \\
--address=127.0.0.1 \\
--master=http://${MASTER_URL}:8080 \\
--allocate-node-cidrs=true \\
--service-cluster-ip-range=${SERVICE_CIDR} \\
--cluster-cidr=${CLUSTER_CIDR} \\
--cluster-name=kubernetes \\
--cluster-signing-cert-file=/etc/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/etc/kubernetes/ssl/ca-key.pem \\
--service-account-private-key-file=/etc/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/etc/kubernetes/ssl/ca.pem \\
--leader-elect=true \\
--v=
Restart=on-failure
RestartSec=
[Install]
WantedBy=multi-user.target
EOF
--address值必须为127.0.0.1,因为当前 kube-apiserver 期望 scheduler 和 controller-manager 在同一台机器--master=http://${MASTER_URL}:8080:使用http(非安全端口)与 kube-apiserver 通信,需要下面的haproxy安装成功后才能去掉8080端口。--cluster-cidr指定 Cluster 中 Pod 的 CIDR 范围,该网段在各 Node 间必须路由可达(flanneld保证)--service-cluster-ip-range参数指定 Cluster 中 Service 的CIDR范围,该网络在各 Node 间必须路由不可达,必须和 kube-apiserver 中的参数一致--cluster-signing-*指定的证书和私钥文件用来签名为 TLS BootStrap 创建的证书和私钥--root-ca-file用来对 kube-apiserver 证书进行校验,指定该参数后,才会在Pod 容器的 ServiceAccount 中放置该 CA 证书文件--leader-elect=true部署多台机器组成的 master 集群时选举产生一处于工作状态的kube-controller-manager进程
启动kube-controller-manager
$ sudo cp kube-controller-manager.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable kube-controller-manager
$ sudo systemctl start kube-controller-manager
$ sudo systemctl status kube-controller-manager
6.3 配置和启动kube-scheduler
创建kube-scheduler 的systemd unit文件
$ cat > kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
[Service]
ExecStart=/usr/k8s/bin/kube-scheduler \\
--address=127.0.0.1 \\
--master=http://${MASTER_URL}:8080 \\
--leader-elect=true \\
--v=
Restart=on-failure
RestartSec=
[Install]
WantedBy=multi-user.target
EOF
--address值必须为127.0.0.1,因为当前 kube-apiserver 期望 scheduler 和 controller-manager 在同一台机器--master=http://${MASTER_URL}:8080:使用http(非安全端口)与 kube-apiserver 通信,需要下面的haproxy启动成功后才能去掉8080端口--leader-elect=true部署多台机器组成的 master 集群时选举产生一处于工作状态的kube-controller-manager进程
启动kube-scheduler
$ sudo cp kube-scheduler.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable kube-scheduler
$ sudo systemctl start kube-scheduler
$ sudo systemctl status kube-scheduler
6.4 验证master 节点
$ kubectl get componentstatuses
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd- Healthy {"health": "true"}
etcd- Healthy {"health": "true"}
etcd- Healthy {"health": "true"}
7. kube-apiserver 高可用
按照上面的方式在master01与master02机器上安装kube-apiserver、kube-controller-manager、kube-scheduler,但是现在我们还是手动指定访问的6443和8080端口的,因为我们的域名k8s-api.virtual.local对应的master01节点直接通过http 和https 还不能访问,这里我们使用haproxy 来代替请求。
明白什么意思吗?就是我们需要将http默认的80端口请求转发到
apiserver的8080端口,将https默认的443端口请求转发到apiserver的6443端口,所以我们这里使用haproxy来做请求转发。
安装haproxy
$ yum install -y haproxy
配置haproxy
由于集群内部有的组建是通过非安全端口访问apiserver 的,有的是通过安全端口访问apiserver 的,所以我们要配置http 和https 两种代理方式,配置文件 /etc/haproxy/haproxy.cfg:
listen stats
bind *:
mode http
stats enable
stats hide-version
stats uri /stats
stats refresh 30s
stats realm Haproxy\ Statistics
stats auth Admin:Password frontend k8s-api
bind 192.168.1.137:
mode tcp
option tcplog
tcp-request inspect-delay 5s
tcp-request content accept if { req.ssl_hello_type }
default_backend k8s-api backend k8s-api
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise fall slowstart 60s maxconn maxqueue weight
server k8s-api- 192.168.1.137: check
server k8s-api- 192.168.1.138: check frontend k8s-http-api
bind 192.168.1.137:
mode tcp
option tcplog
default_backend k8s-http-api backend k8s-http-api
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise fall slowstart 60s maxconn maxqueue weight
server k8s-http-api- 192.168.1.137: check
server k8s-http-api- 192.168.1.138: check
通过上面的配置文件我们可以看出通过https的访问将请求转发给apiserver 的6443端口了,http的请求转发到了apiserver 的8080端口。
启动haproxy
$ sudo systemctl start haproxy
$ sudo systemctl enable haproxy
$ sudo systemctl status haproxy
然后我们可以通过上面9000端口监控我们的haproxy的运行状态(192.168.1.137:9000/stats):
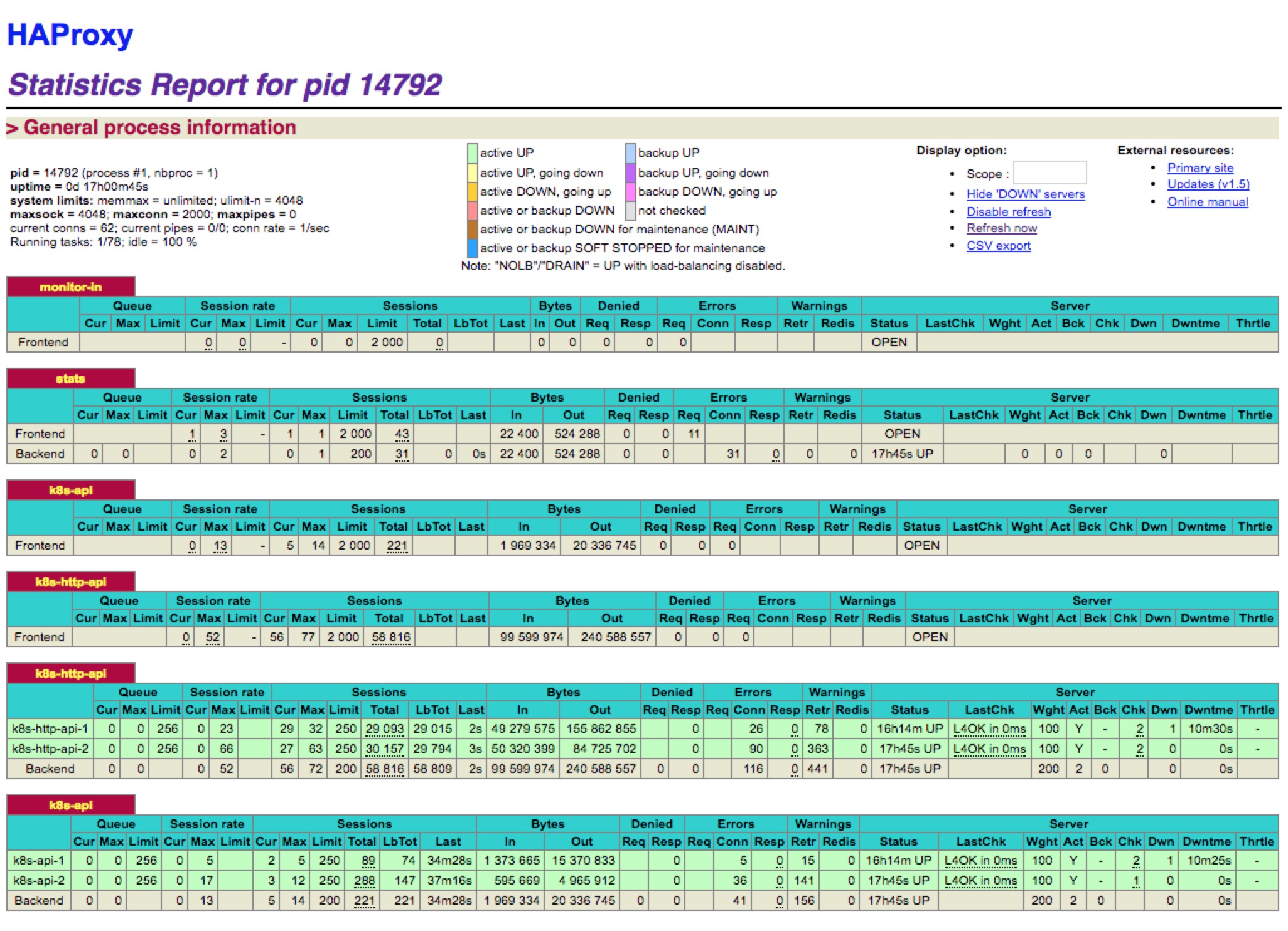 haproxy stats
haproxy stats
问题
上面我们的haproxy的确可以代理我们的两个master 上的apiserver 了,但是还不是高可用的,如果master01 这个节点down 掉了,那么我们haproxy 就不能正常提供服务了。这里我们可以使用两种方法来实现高可用
方式1:使用阿里云SLB
这种方式实际上是最省心的,在阿里云上建一个内网的SLB,将master01 与master02 添加到SLB 机器组中,转发80(http)和443(https)端口即可(注意下面的提示)
注意:阿里云的负载均衡是四层TCP负责,不支持后端ECS实例既作为Real Server又作为客户端向所在的负载均衡实例发送请求。因为返回的数据包只在云服务器内部转发,不经过负载均衡,所以在后端ECS实例上去访问负载均衡的服务地址是不通的。什么意思?就是如果你要使用阿里云的SLB的话,那么你不能在
apiserver节点上使用SLB(比如在apiserver 上安装kubectl,然后将apiserver的地址设置为SLB的负载地址使用),因为这样的话就可能造成回环了,所以简单的做法是另外用两个新的节点做HA实例,然后将这两个实例添加到SLB机器组中。
方式2:使用keepalived
KeepAlived 是一个高可用方案,通过 VIP(即虚拟 IP)和心跳检测来实现高可用。其原理是存在一组(两台)服务器,分别赋予 Master、Backup 两个角色,默认情况下Master 会绑定VIP 到自己的网卡上,对外提供服务。Master、Backup 会在一定的时间间隔向对方发送心跳数据包来检测对方的状态,这个时间间隔一般为 2 秒钟,如果Backup 发现Master 宕机,那么Backup 会发送ARP 包到网关,把VIP 绑定到自己的网卡,此时Backup 对外提供服务,实现自动化的故障转移,当Master 恢复的时候会重新接管服务。非常类似于路由器中的虚拟路由器冗余协议(VRRP)
开启路由转发,这里我们定义虚拟IP为:192.168.1.139
$ vi /etc/sysctl.conf
# 添加以下内容
net.ipv4.ip_forward =
net.ipv4.ip_nonlocal_bind = # 验证并生效
$ sysctl -p
# 验证是否生效
$ cat /proc/sys/net/ipv4/ip_forward
安装keepalived:
$ yum install -y keepalived
我们这里将master01 设置为Master,master02 设置为Backup,修改配置:
$ vi /etc/keepalived/keepalived.conf
! Configuration File for keepalived global_defs {
notification_email {
}
router_id kube_api
} vrrp_script check_haproxy {
# 自身状态检测
script "killall -0 haproxy"
interval
weight
} vrrp_instance haproxy-vip {
# 使用单播通信,默认是组播通信
unicast_src_ip 192.168.1.137
unicast_peer {
192.168.1.138
}
# 初始化状态
state MASTER
# 虚拟ip 绑定的网卡 (这里根据你自己的实际情况选择网卡)
interface eth0
# 此ID 要与Backup 配置一致
virtual_router_id
# 默认启动优先级,要比Backup 大点,但要控制量,保证自身状态检测生效
priority
advert_int
authentication {
auth_type PASS
auth_pass
}
virtual_ipaddress {
# 虚拟ip 地址
192.168.1.139
}
track_script {
check_haproxy
}
} virtual_server 192.168.1.139 {
delay_loop
lvs_sched wlc
lvs_method NAT
persistence_timeout
protocol TCP real_server 192.168.1.137 {
weight
TCP_CHECK {
connect_port
connect_timeout
}
}
} virtual_server 192.168.1.139 {
delay_loop
lvs_sched wlc
lvs_method NAT
persistence_timeout
protocol TCP real_server 192.168.1.137 {
weight
TCP_CHECK {
connect_port
connect_timeout
}
}
}
统一的方式在master02 节点上安装keepalived,修改配置,只需要将state 更改成BACKUP,priority更改成99,unicast_src_ip 与unicast_peer 地址修改即可。
启动keepalived:
$ systemctl start keepalived
$ systemctl enable keepalived
# 查看日志
$ journalctl -f -u keepalived
验证虚拟IP:
# 使用ifconfig -a 命令查看不到,要使用ip addr
$ ip addr
: lo: <LOOPBACK,UP,LOWER_UP> mtu qdisc noqueue state UNKNOWN qlen
link/loopback ::::: brd :::::
inet 127.0.0.1/ scope host lo
valid_lft forever preferred_lft forever
: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu qdisc pfifo_fast state UP qlen
link/ether ::3e:::c1 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.137/ brd 192.168.1.255 scope global dynamic eth0
valid_lft 31447746sec preferred_lft 31447746sec
inet 192.168.1.139/ brd 192.168.1.255 scope global secondary eth0-vip
valid_lft forever preferred_lft forever
到这里,我们就可以将上面的6443端口和8080端口去掉了,可以手动将
kubectl生成的config文件(~/.kube/config)中的server 地址6443端口去掉,另外kube-controller-manager和kube-scheduler的–master参数中的8080端口去掉了,然后分别重启这两个组件即可。
验证apiserver:关闭master01 节点上的kube-apiserver 进程,然后查看虚拟ip是否漂移到了master02 节点。
然后我们就可以将第一步在/etc/hosts里面设置的域名对应的IP 更改为我们的虚拟IP了
master01 与master 02 节点都需要安装keepalived 和haproxy,实际上我们虚拟IP的自身检测应该是检测haproxy,脚本大家可以自行更改
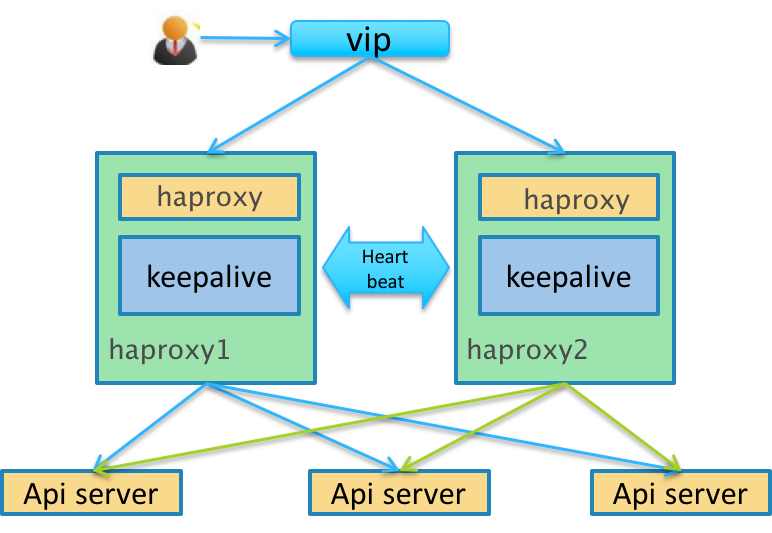 kube-apiserver ha
kube-apiserver ha
这样我们就实现了接入层apiserver 的高可用了,一个部分是多活的apiserver 服务,另一个部分是一主一备的haproxy 服务。
kube-controller-manager 和kube-scheduler 的高可用
Kubernetes 的管理层服务包括kube-scheduler和kube-controller-manager。kube-scheduler和kube-controller-manager使用一主多从的高可用方案,在同一时刻只允许一个服务处以具体的任务。Kubernetes中实现了一套简单的选主逻辑,依赖Etcd实现scheduler和controller-manager的选主功能。如果scheduler和controller-manager在启动的时候设置了leader-elect参数,它们在启动后会先尝试获取leader节点身份,只有在获取leader节点身份后才可以执行具体的业务逻辑。它们分别会在Etcd中创建kube-scheduler和kube-controller-manager的endpoint,endpoint的信息中记录了当前的leader节点信息,以及记录的上次更新时间。leader节点会定期更新endpoint的信息,维护自己的leader身份。每个从节点的服务都会定期检查endpoint的信息,如果endpoint的信息在时间范围内没有更新,它们会尝试更新自己为leader节点。scheduler服务以及controller-manager服务之间不会进行通信,利用Etcd的强一致性,能够保证在分布式高并发情况下leader节点的全局唯一性。整体方案如下图所示:
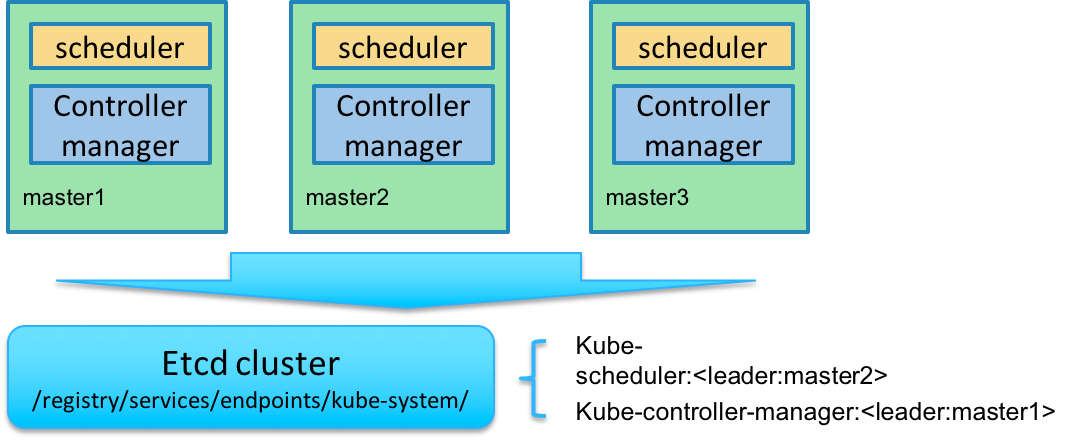 img
img
当集群中的leader节点服务异常后,其它节点的服务会尝试更新自身为leader节点,当有多个节点同时更新endpoint时,由Etcd保证只有一个服务的更新请求能够成功。通过这种机制sheduler和controller-manager可以保证在leader节点宕机后其它的节点可以顺利选主,保证服务故障后快速恢复。当集群中的网络出现故障时对服务的选主影响不是很大,因为scheduler和controller-manager是依赖Etcd进行选主的,在网络故障后,可以和Etcd通信的主机依然可以按照之前的逻辑进行选主,就算集群被切分,Etcd也可以保证同一时刻只有一个节点的服务处于leader状态。
8. 部署Node 节点
kubernetes Node 节点包含如下组件:
- flanneld
- docker
- kubelet
- kube-proxy
环境变量
$ source /usr/k8s/bin/env.sh
$ export KUBE_APISERVER="https://${MASTER_URL}" // 如果你没有安装`haproxy`的话,还是需要使用6443端口的哦
$ export NODE_IP=192.168.1.170 # 当前部署的节点 IP
按照上面的步骤安装配置好flanneld
开启路由转发
修改/etc/sysctl.conf文件,添加下面的规则:
net.ipv4.ip_forward=
net.bridge.bridge-nf-call-iptables=
net.bridge.bridge-nf-call-ip6tables=
执行下面的命令立即生效:
$ sysctl -p
配置docker
你可以用二进制或yum install 的方式来安装docker,然后修改docker 的systemd unit 文件:
$ cat /usr/lib/systemd/system/docker.service # 用systemctl status docker 命令可查看unit 文件路径
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target [Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issues still
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
EnvironmentFile=-/run/flannel/docker
ExecStart=/usr/bin/dockerd --log-level=info $DOCKER_NETWORK_OPTIONS
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting.
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd and above support this version.
#TasksMax=infinity
TimeoutStartSec=
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=
StartLimitInterval=60s [Install]
WantedBy=multi-user.target
dockerd 运行时会调用其它 docker 命令,如 docker-proxy,所以需要将 docker 命令所在的目录加到 PATH 环境变量中
flanneld 启动时将网络配置写入到
/run/flannel/docker文件中的变量DOCKER_NETWORK_OPTIONS,dockerd 命令行上指定该变量值来设置 docker0 网桥参数如果指定了多个
EnvironmentFile选项,则必须将/run/flannel/docker放在最后(确保 docker0 使用 flanneld 生成的 bip 参数)不能关闭默认开启的
--iptables和--ip-masq选项如果内核版本比较新,建议使用
overlay存储驱动docker 从 1.13 版本开始,可能将 iptables FORWARD chain的默认策略设置为DROP,从而导致 ping 其它 Node 上的 Pod IP 失败,遇到这种情况时,需要手动设置策略为
ACCEPT:
$ sudo iptables -P FORWARD ACCEPT
如果没有开启上面的路由转发(net.ipv4.ip_forward=1),则需要把以下命令写入/etc/rc.local文件中,防止节点重启iptables FORWARD chain的默认策略又还原为DROP(下面的开机脚本我测试了几次都没生效,不知道是不是方法有误,所以最好的方式还是开启上面的路由转发功能,一劳永逸)
sleep && /sbin/iptables -P FORWARD ACCEPT
- 为了加快 pull image 的速度,可以使用国内的仓库镜像服务器,同时增加下载的并发数。(如果 dockerd 已经运行,则需要重启 dockerd 生效。)
$ cat /etc/docker/daemon.json
{
"max-concurrent-downloads":
}
启动docker
$ sudo systemctl daemon-reload
$ sudo systemctl stop firewalld
$ sudo systemctl disable firewalld
$ sudo iptables -F && sudo iptables -X && sudo iptables -F -t nat && sudo iptables -X -t nat
$ sudo systemctl enable docker
$ sudo systemctl start docker
- 需要关闭 firewalld(centos7)/ufw(ubuntu16.04),否则可能会重复创建 iptables 规则
- 最好清理旧的 iptables rules 和 chains 规则
- 执行命令:docker version,检查docker服务是否正常
安装和配置kubelet
kubelet 启动时向kube-apiserver 发送TLS bootstrapping 请求,需要先将bootstrap token 文件中的kubelet-bootstrap 用户赋予system:node-bootstrapper 角色,然后kubelet 才有权限创建认证请求(certificatesigningrequests):
kubelet就是运行在Node节点上的,所以这一步安装是在所有的Node节点上,如果你想把你的Master也当做Node节点的话,当然也可以在Master节点上安装的。
$ kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap
--user=kubelet-bootstrap是文件/etc/kubernetes/token.csv中指定的用户名,同时也写入了文件/etc/kubernetes/bootstrap.kubeconfig
另外1.8 版本中还需要为Node 请求创建一个RBAC 授权规则:
$ kubectl create clusterrolebinding kubelet-nodes --clusterrole=system:node --group=system:nodes
然后下载最新的kubelet 和kube-proxy 二进制文件(前面下载kubernetes 目录下面其实也有):
$ wget https://dl.k8s.io/v1.8.2/kubernetes-server-linux-amd64.tar.gz
$ tar -xzvf kubernetes-server-linux-amd64.tar.gz
$ cd kubernetes
$ tar -xzvf kubernetes-src.tar.gz
$ sudo cp -r ./server/bin/{kube-proxy,kubelet} /usr/k8s/bin/
创建kubelet bootstapping kubeconfig 文件
$ # 设置集群参数
$ kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=bootstrap.kubeconfig
$ # 设置客户端认证参数
$ kubectl config set-credentials kubelet-bootstrap \
--token=${BOOTSTRAP_TOKEN} \
--kubeconfig=bootstrap.kubeconfig
$ # 设置上下文参数
$ kubectl config set-context default \
--cluster=kubernetes \
--user=kubelet-bootstrap \
--kubeconfig=bootstrap.kubeconfig
$ # 设置默认上下文
$ kubectl config use-context default --kubeconfig=bootstrap.kubeconfig
$ mv bootstrap.kubeconfig /etc/kubernetes/
--embed-certs为true时表示将certificate-authority证书写入到生成的bootstrap.kubeconfig文件中;- 设置 kubelet 客户端认证参数时没有指定秘钥和证书,后续由
kube-apiserver自动生成;
创建kubelet 的systemd unit 文件
$ sudo mkdir /var/lib/kubelet # 必须先创建工作目录
$ cat > kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/var/lib/kubelet
ExecStart=/usr/k8s/bin/kubelet \\
--fail-swap-on=false \\
--cgroup-driver=cgroupfs \\
--address=${NODE_IP} \\
--hostname-override=${NODE_IP} \\
--experimental-bootstrap-kubeconfig=/etc/kubernetes/bootstrap.kubeconfig \\
--kubeconfig=/etc/kubernetes/kubelet.kubeconfig \\
--require-kubeconfig \\
--cert-dir=/etc/kubernetes/ssl \\
--cluster-dns=${CLUSTER_DNS_SVC_IP} \\
--cluster-domain=${CLUSTER_DNS_DOMAIN} \\
--hairpin-mode promiscuous-bridge \\
--allow-privileged=true \\
--serialize-image-pulls=false \\
--logtostderr=true \\
--v=
Restart=on-failure
RestartSec=
[Install]
WantedBy=multi-user.target
EOF
请仔细阅读下面的注意事项,不然可能会启动失败。
--fail-swap-on参数,这个一定要注意,Kubernetes 1.8开始要求关闭系统的Swap,如果不关闭,默认配置下kubelet将无法启动,也可以通过kubelet的启动参数–fail-swap-on=false来避免该问题--cgroup-driver参数,kubelet 用来维护主机的的 cgroups 的,默认是cgroupfs,但是这个地方的值需要你根据docker 的配置来确定(docker info |grep cgroup)-address不能设置为127.0.0.1,否则后续 Pods 访问 kubelet 的 API 接口时会失败,因为 Pods 访问的127.0.0.1指向自己而不是 kubelet- 如果设置了
--hostname-override选项,则kube-proxy也需要设置该选项,否则会出现找不到 Node 的情况 --experimental-bootstrap-kubeconfig指向 bootstrap kubeconfig 文件,kubelet 使用该文件中的用户名和 token 向 kube-apiserver 发送 TLS Bootstrapping 请求- 管理员通过了 CSR 请求后,kubelet 自动在
--cert-dir目录创建证书和私钥文件(kubelet-client.crt和kubelet-client.key),然后写入--kubeconfig文件(自动创建--kubeconfig指定的文件) - 建议在
--kubeconfig配置文件中指定kube-apiserver地址,如果未指定--api-servers选项,则必须指定--require-kubeconfig选项后才从配置文件中读取 kue-apiserver 的地址,否则 kubelet 启动后将找不到 kube-apiserver (日志中提示未找到 API Server),kubectl get nodes不会返回对应的 Node 信息 --cluster-dns指定 kubedns 的 Service IP(可以先分配,后续创建 kubedns 服务时指定该 IP),--cluster-domain指定域名后缀,这两个参数同时指定后才会生效
启动kubelet
$ sudo cp kubelet.service /etc/systemd/system/kubelet.service
$ sudo systemctl daemon-reload
$ sudo systemctl enable kubelet
$ sudo systemctl start kubelet
$ systemctl status kubelet
通过kubelet 的TLS 证书请求
kubelet 首次启动时向kube-apiserver 发送证书签名请求,必须通过后kubernetes 系统才会将该 Node 加入到集群。查看未授权的CSR 请求:
$ kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr--k3G2G1EoM4h9w1FuJRjJjfbIPNxa551A8TZfW9dG-g 2m kubelet-bootstrap Pending
$ kubectl get nodes
No resources found.
通过CSR 请求:
$ kubectl certificate approve node-csr--k3G2G1EoM4h9w1FuJRjJjfbIPNxa551A8TZfW9dG-g
certificatesigningrequest "node-csr--k3G2G1EoM4h9w1FuJRjJjfbIPNxa551A8TZfW9dG-g" approved
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.1.170 Ready <none> 48s v1.8.1
自动生成了kubelet kubeconfig 文件和公私钥:
$ ls -l /etc/kubernetes/kubelet.kubeconfig
-rw------- root root Nov : /etc/kubernetes/kubelet.kubeconfig
$ ls -l /etc/kubernetes/ssl/kubelet*
-rw-r--r-- root root Nov : /etc/kubernetes/ssl/kubelet-client.crt
-rw------- root root Nov : /etc/kubernetes/ssl/kubelet-client.key
-rw-r--r-- root root Nov : /etc/kubernetes/ssl/kubelet.crt
-rw------- root root Nov : /etc/kubernetes/ssl/kubelet.key
配置kube-proxy
创建kube-proxy 证书签名请求:
$ cat > kube-proxy-csr.json <<EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size":
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "System"
}
]
}
EOF
- CN 指定该证书的 User 为
system:kube-proxy kube-apiserver预定义的 RoleBindingsystem:node-proxier将Usersystem:kube-proxy与 Rolesystem:node-proxier绑定,该 Role 授予了调用kube-apiserverProxy 相关 API 的权限- hosts 属性值为空列表
生成kube-proxy 客户端证书和私钥
$ cfssl gencert -ca=/etc/kubernetes/ssl/ca.pem \
-ca-key=/etc/kubernetes/ssl/ca-key.pem \
-config=/etc/kubernetes/ssl/ca-config.json \
-profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
$ ls kube-proxy*
kube-proxy.csr kube-proxy-csr.json kube-proxy-key.pem kube-proxy.pem
$ sudo mv kube-proxy*.pem /etc/kubernetes/ssl/
创建kube-proxy kubeconfig 文件
$ # 设置集群参数
$ kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.kubeconfig
$ # 设置客户端认证参数
$ kubectl config set-credentials kube-proxy \
--client-certificate=/etc/kubernetes/ssl/kube-proxy.pem \
--client-key=/etc/kubernetes/ssl/kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=kube-proxy.kubeconfig
$ # 设置上下文参数
$ kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=kube-proxy.kubeconfig
$ # 设置默认上下文
$ kubectl config use-context default --kubeconfig=kube-proxy.kubeconfig
$ mv kube-proxy.kubeconfig /etc/kubernetes/
- 设置集群参数和客户端认证参数时
--embed-certs都为true,这会将certificate-authority、client-certificate和client-key指向的证书文件内容写入到生成的kube-proxy.kubeconfig文件中 kube-proxy.pem证书中 CN 为system:kube-proxy,kube-apiserver预定义的 RoleBindingcluster-admin将Usersystem:kube-proxy与 Rolesystem:node-proxier绑定,该 Role 授予了调用kube-apiserverProxy 相关 API 的权限
创建kube-proxy 的systemd unit 文件
$ sudo mkdir -p /var/lib/kube-proxy # 必须先创建工作目录
$ cat > kube-proxy.service <<EOF
[Unit]
Description=Kubernetes Kube-Proxy Server
Documentation=https://github.com/GoogleCloudPlatform/kubernetes
After=network.target
[Service]
WorkingDirectory=/var/lib/kube-proxy
ExecStart=/usr/k8s/bin/kube-proxy \\
--bind-address=${NODE_IP} \\
--hostname-override=${NODE_IP} \\
--cluster-cidr=${SERVICE_CIDR} \\
--kubeconfig=/etc/kubernetes/kube-proxy.kubeconfig \\
--logtostderr=true \\
--v=
Restart=on-failure
RestartSec=
LimitNOFILE=
[Install]
WantedBy=multi-user.target
EOF
--hostname-override参数值必须与 kubelet 的值一致,否则 kube-proxy 启动后会找不到该 Node,从而不会创建任何 iptables 规则--cluster-cidr必须与 kube-apiserver 的--service-cluster-ip-range选项值一致- kube-proxy 根据
--cluster-cidr判断集群内部和外部流量,指定--cluster-cidr或--masquerade-all选项后 kube-proxy 才会对访问 Service IP 的请求做 SNAT --kubeconfig指定的配置文件嵌入了 kube-apiserver 的地址、用户名、证书、秘钥等请求和认证信息- 预定义的 RoleBinding
cluster-admin将Usersystem:kube-proxy与 Rolesystem:node-proxier绑定,该 Role 授予了调用kube-apiserverProxy 相关 API 的权限
启动kube-proxy
$ sudo cp kube-proxy.service /etc/systemd/system/
$ sudo systemctl daemon-reload
$ sudo systemctl enable kube-proxy
$ sudo systemctl start kube-proxy
$ systemctl status kube-proxy
验证集群功能
定义yaml 文件:(将下面内容保存为:nginx-ds.yaml)
apiVersion: v1
kind: Service
metadata:
name: nginx-ds
labels:
app: nginx-ds
spec:
type: NodePort
selector:
app: nginx-ds
ports:
- name: http
port:
targetPort:
---
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nginx-ds
labels:
addonmanager.kubernetes.io/mode: Reconcile
spec:
template:
metadata:
labels:
app: nginx-ds
spec:
containers:
- name: my-nginx
image: nginx:1.7.
ports:
- containerPort:
创建 Pod 和服务:
$ kubectl create -f nginx-ds.yml
service "nginx-ds" created
daemonset "nginx-ds" created
执行下面的命令查看Pod 和SVC:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-ds-f29zt / Running 23m 172.17.0.2 192.168.1.170
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx-ds NodePort 10.254.6.249 <none> :/TCP 24m
可以看到:
- 服务IP:10.254.6.249
- 服务端口:80
- NodePort端口:30813
在所有 Node 上执行:
$ curl 10.254.6.249
$ curl 192.168.1.170:
执行上面的命令预期都会输出nginx 欢迎页面内容,表示我们的Node 节点正常运行了。
9. 部署kubedns 插件
官方文件目录:kubernetes/cluster/addons/dns
使用的文件:
$ ls *.yaml *.base
kubedns-cm.yaml kubedns-sa.yaml kubedns-controller.yaml.base kubedns-svc.yaml.base
系统预定义的RoleBinding
预定义的RoleBinding system:kube-dns将kube-system 命名空间的kube-dnsServiceAccount 与 system:kube-dns Role 绑定,该Role 具有访问kube-apiserver DNS 相关的API 权限:
$ kubectl get clusterrolebindings system:kube-dns -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
creationTimestamp: --06T10::59Z
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-dns
resourceVersion: ""
selfLink: /apis/rbac.authorization.k8s.io/v1/clusterrolebindings/system%3Akube-dns
uid: 83a25fd9-c2e0-11e7--00163e0055c1
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-dns
subjects:
- kind: ServiceAccount
name: kube-dns
namespace: kube-system
kubedns-controller.yaml中定义的 Pods 时使用了kubedns-sa.yaml文件定义的kube-dnsServiceAccount,所以具有访问 kube-apiserver DNS 相关 API 的权限;
配置kube-dns ServiceAccount
无需更改
配置kube-dns 服务
$ diff kubedns-svc.yaml.base kubedns-svc.yaml
30c30
< clusterIP: __PILLAR__DNS__SERVER__
---
> clusterIP: 10.254.0.2
- 需要将 spec.clusterIP 设置为集群环境变量中变量
CLUSTER_DNS_SVC_IP值,这个IP 需要和 kubelet 的—cluster-dns参数值一致
配置kube-dns Deployment
$ diff kubedns-controller.yaml.base kubedns-controller.yaml
88c88
< - --domain=__PILLAR__DNS__DOMAIN__.
---
> - --domain=cluster.local
128c128
< - --server=/__PILLAR__DNS__DOMAIN__/127.0.0.1#
---
> - --server=/cluster.local/127.0.0.1#
,161c160,
< - --probe=kubedns,127.0.0.1:,kubernetes.default.svc.__PILLAR__DNS__DOMAIN__,,A
< - --probe=dnsmasq,127.0.0.1:,kubernetes.default.svc.__PILLAR__DNS__DOMAIN__,,A
---
> - --probe=kubedns,127.0.0.1:,kubernetes.default.svc.cluster.local,,A
> - --probe=dnsmasq,127.0.0.1:,kubernetes.default.svc.cluster.local,,A
--domain为集群环境变量CLUSTER_DNS_DOMAIN的值- 使用系统已经做了 RoleBinding 的
kube-dnsServiceAccount,该账户具有访问 kube-apiserver DNS 相关 API 的权限
执行所有定义文件
$ pwd
/home/ych/k8s-repo/kube-dns
$ ls *.yaml
kubedns-cm.yaml kubedns-controller.yaml kubedns-sa.yaml kubedns-svc.yaml
$ kubectl create -f .
检查kubedns 功能
新建一个Deployment
$ cat > my-nginx.yaml<<EOF
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: my-nginx
spec:
replicas:
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx:1.7.
ports:
- containerPort:
EOF
$ kubectl create -f my-nginx.yaml
deployment "my-nginx" created
Expose 该Deployment,生成my-nginx 服务
$ kubectl expose deploy my-nginx
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.254.0.1 <none> /TCP 1d
my-nginx ClusterIP 10.254.32.162 <none> /TCP 56s
然后创建另外一个Pod,查看/etc/resolv.conf是否包含kubelet配置的--cluster-dns 和--cluster-domain,是否能够将服务my-nginx 解析到上面显示的CLUSTER-IP 10.254.32.162上
$ cat > pod-nginx.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.
ports:
- containerPort:
EOF
$ kubectl create -f pod-nginx.yaml
pod "nginx" created
$ kubectl exec nginx -i -t -- /bin/bash
root@nginx:/# cat /etc/resolv.conf
nameserver 10.254.0.2
search default.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:
root@nginx:/# ping my-nginx
PING my-nginx.default.svc.cluster.local (10.254.32.162): data bytes
^C--- my-nginx.default.svc.cluster.local ping statistics ---
packets transmitted, packets received, % packet loss root@nginx:/# ping kubernetes
PING kubernetes.default.svc.cluster.local (10.254.0.1): data bytes
^C--- kubernetes.default.svc.cluster.local ping statistics ---
packets transmitted, packets received, % packet loss root@nginx:/# ping kube-dns.kube-system.svc.cluster.local
PING kube-dns.kube-system.svc.cluster.local (10.254.0.2): data bytes
^C--- kube-dns.kube-system.svc.cluster.local ping statistics ---
packets transmitted, packets received, % packet loss
10. 部署Dashboard 插件
官方文件目录:kubernetes/cluster/addons/dashboard
使用的文件如下:
$ ls *.yaml
dashboard-controller.yaml dashboard-rbac.yaml dashboard-service.yaml
- 新加了
dashboard-rbac.yaml文件,定义 dashboard 使用的 RoleBinding。
由于 kube-apiserver 启用了 RBAC 授权,而官方源码目录的 dashboard-controller.yaml 没有定义授权的 ServiceAccount,所以后续访问 kube-apiserver 的 API 时会被拒绝,前端界面提示:
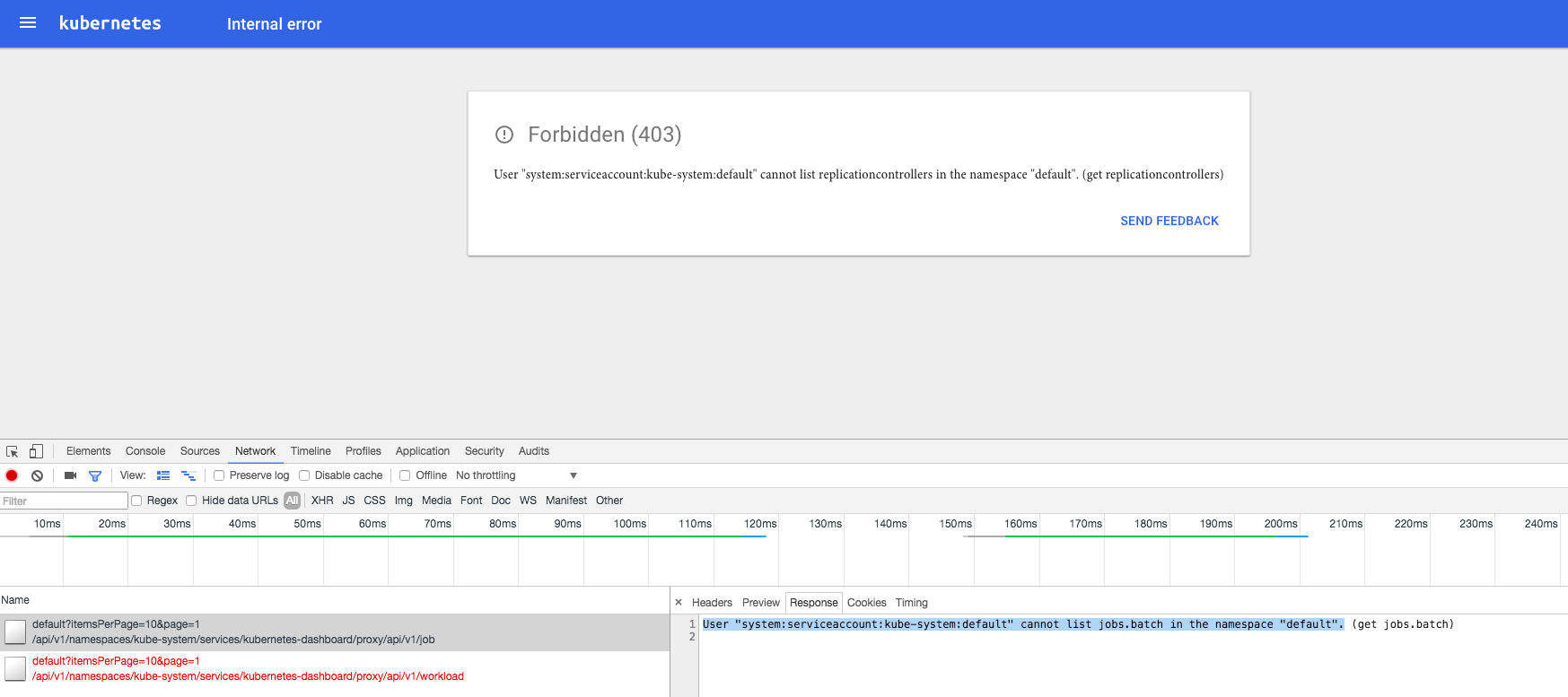 403
403
解决办法是:定义一个名为dashboard 的ServiceAccount,然后将它和Cluster Role view 绑定:
$ cat > dashboard-rbac.yaml<<EOF
apiVersion: v1
kind: ServiceAccount
metadata:
name: dashboard
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1alpha1
metadata:
name: dashboard
subjects:
- kind: ServiceAccount
name: dashboard
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
EOF
配置dashboard-controller
20a21
> serviceAccountName: dashboard
- 使用名为 dashboard 的自定义 ServiceAccount
配置dashboard-service
$ diff dashboard-service.yaml.orig dashboard-service.yaml
10a11
> type: NodePort
- 指定端口类型为 NodePort,这样外界可以通过地址 nodeIP:nodePort 访问 dashboard
执行所有定义文件
$ pwd
/home/ych/k8s-repo/dashboard
$ ls *.yaml
dashboard-controller.yaml dashboard-rbac.yaml dashboard-service.yaml
$ kubectl create -f .
检查执行结果
查看分配的 NodePort
$ kubectl get services kubernetes-dashboard -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard NodePort 10.254.104.90 <none> :/TCP 1m
- NodePort 31202映射到dashboard pod 80端口;
检查 controller
$ kubectl get deployment kubernetes-dashboard -n kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard 3m $ kubectl get pods -n kube-system | grep dashboard
kubernetes-dashboard-6667f9b4c-4xbpz / Running 3m
访问dashboard
- kubernetes-dashboard 服务暴露了 NodePort,可以使用
http://NodeIP:nodePort地址访问 dashboard - 通过 kube-apiserver 访问 dashboard
- 通过 kubectl proxy 访问 dashboard
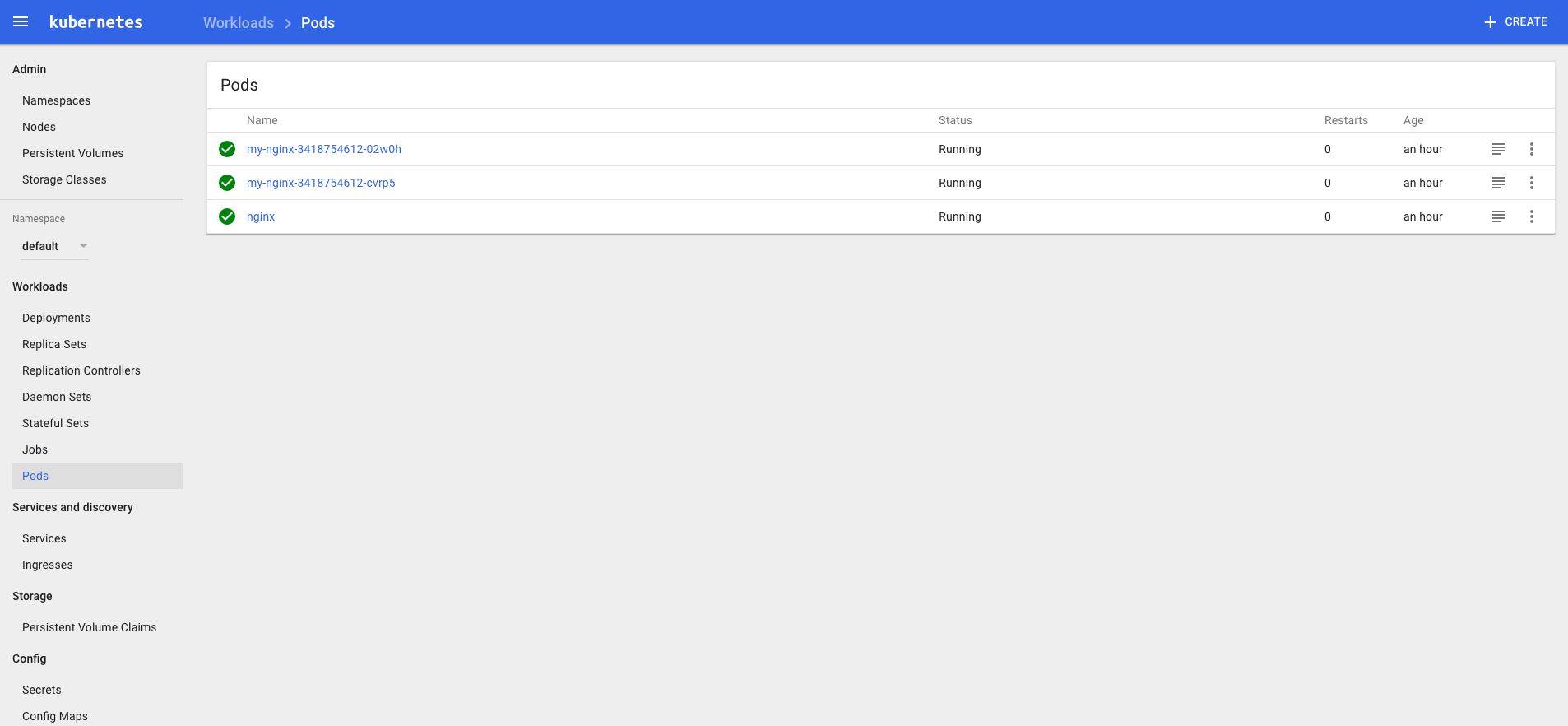 dashboard ui
dashboard ui
由于缺少 Heapster 插件,当前 dashboard 不能展示 Pod、Nodes 的 CPU、内存等 metric 图形
注意:如果你的后端
apiserver是高可用的集群模式的话,那么Dashboard的apiserver-host最好手动指定,不然,当你apiserver某个节点挂了的时候,Dashboard可能不能正常访问,如下配置
image: gcr.io/google_containers/kubernetes-dashboard-amd64:v1.7.1
ports:
- containerPort:
protocol: TCP
args:
- --apiserver-host=http://<api_server_ha_addr>:8080
11. 部署Heapster 插件
到heapster release 页面下载最新版的heapster
$ wget https://github.com/kubernetes/heapster/archive/v1.4.3.tar.gz
$ tar -xzvf v1.4.3.tar.gz
部署相关文件目录:/home/ych/k8s-repo/heapster-1.4.3/deploy/kube-config
$ ls influxdb/ && ls rbac/
grafana.yaml heapster.yaml influxdb.yaml
heapster-rbac.yaml
为方便测试访问,将grafana.yaml下面的服务类型设置为type=NodePort
执行所有文件
$ kubectl create -f rbac/heapster-rbac.yaml
clusterrolebinding "heapster" created
$ kubectl create -f influxdb
deployment "monitoring-grafana" created
service "monitoring-grafana" created
serviceaccount "heapster" created
deployment "heapster" created
service "heapster" created
deployment "monitoring-influxdb" created
service "monitoring-influxdb" created
检查执行结果
检查 Deployment
$ kubectl get deployments -n kube-system | grep -E 'heapster|monitoring'
heapster 2m
monitoring-grafana 2m
monitoring-influxdb 2m
检查 Pods
$ kubectl get pods -n kube-system | grep -E 'heapster|monitoring'
heapster-7cf895f48f-p98tk / Running 2m
monitoring-grafana-c9d5cd98d-gb9xn / CrashLoopBackOff 2m
monitoring-influxdb-67f8d587dd-zqj6p / Running 2m
我们可以看到monitoring-grafana的POD 是没有执行成功的,通过查看日志可以看到下面的错误信息:
Failed to parse /etc/grafana/grafana.ini, open /etc/grafana/grafana.ini: no such file or directory
要解决这个问题(heapster issues)我们需要将grafana 的镜像版本更改成:gcr.io/google_containers/heapster-grafana-amd64:v4.0.2,然后重新执行,即可正常。
访问 grafana
上面我们修改grafana 的Service 为NodePort 类型:
$ kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
monitoring-grafana NodePort 10.254.34.89 <none> :/TCP 28m
则我们就可以通过任意一个节点加上上面的30191端口就可以访问grafana 了。
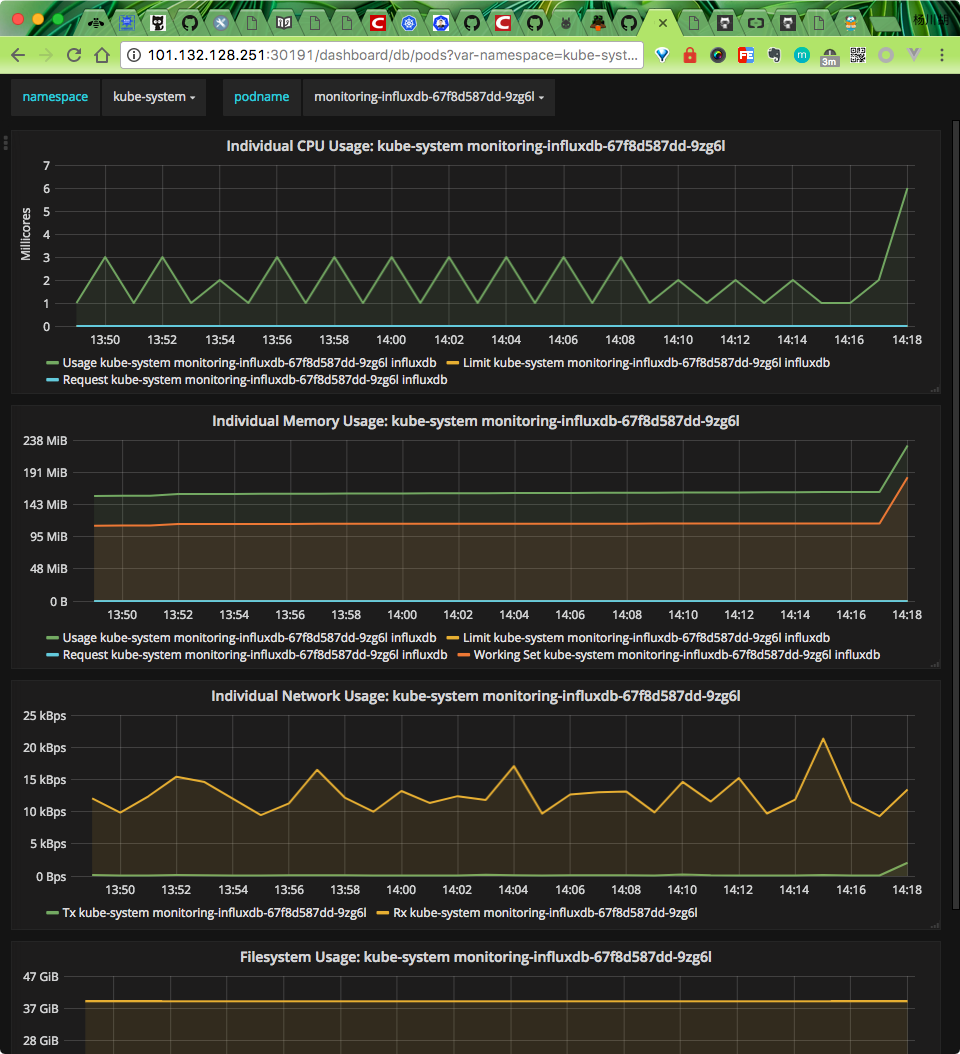 grafana ui
grafana ui
heapster 正确安装后,我们便可以回去看我们的dashboard 是否有图表出现了:
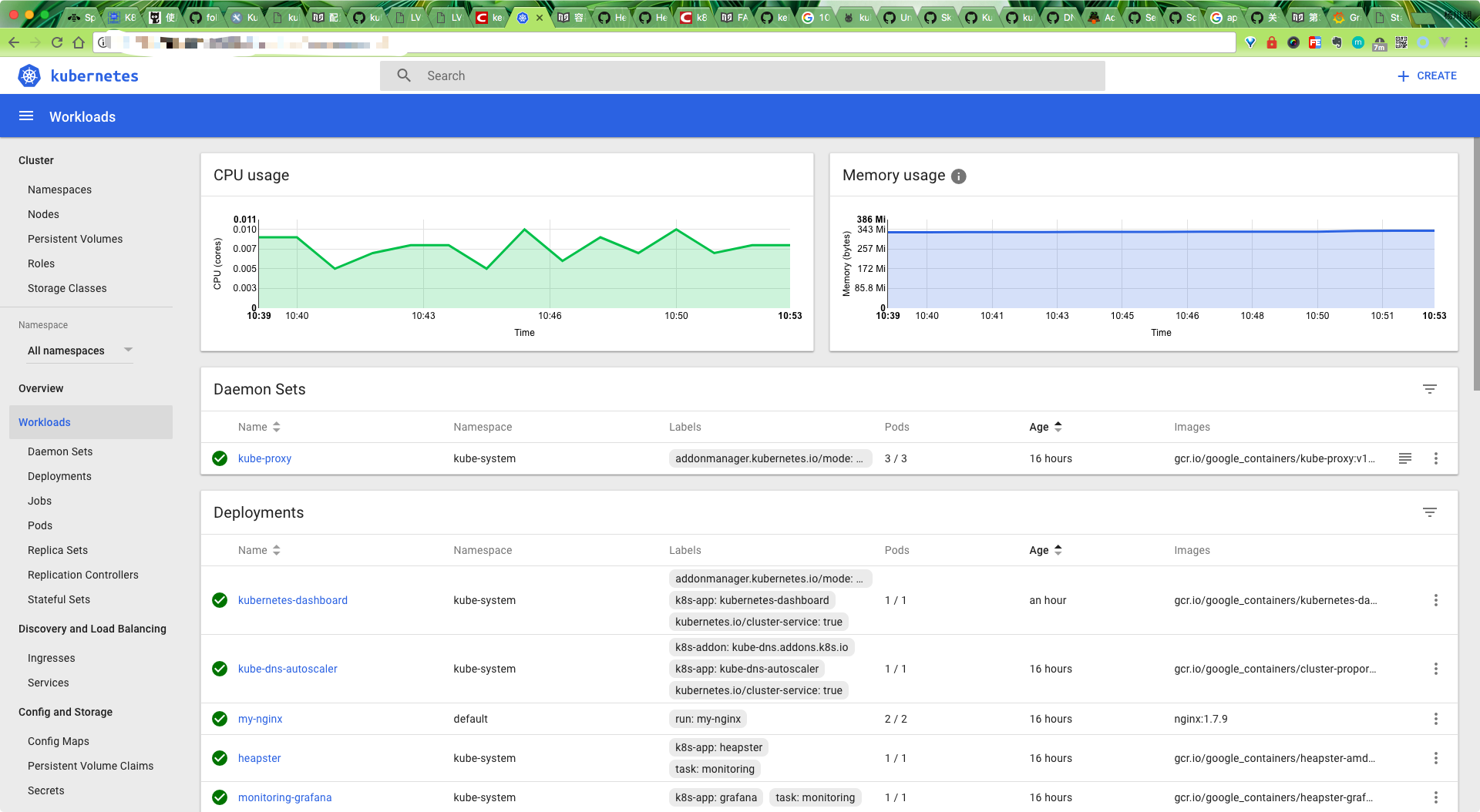 dashboard
dashboard
12. 安装Ingress
Ingress其实就是从kuberenets集群外部访问集群的一个入口,将外部的请求转发到集群内不同的Service 上,其实就相当于nginx、apache 等负载均衡代理服务器,再加上一个规则定义,路由信息的刷新需要靠Ingress controller来提供
Ingress controller可以理解为一个监听器,通过不断地与kube-apiserver打交道,实时的感知后端service、pod 等的变化,当得到这些变化信息后,Ingress controller再结合Ingress的配置,更新反向代理负载均衡器,达到服务发现的作用。其实这点和服务发现工具consul的consul-template非常类似。
部署traefik
Traefik是一款开源的反向代理与负载均衡工具。它最大的优点是能够与常见的微服务系统直接整合,可以实现自动化动态配置。目前支持Docker、Swarm、Mesos/Marathon、 Mesos、Kubernetes、Consul、Etcd、Zookeeper、BoltDB、Rest API等等后端模型。
 traefik
traefik
创建rbac
创建文件:ingress-rbac.yaml,用于service account验证
apiVersion: v1
kind: ServiceAccount
metadata:
name: ingress
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: ingress
subjects:
- kind: ServiceAccount
name: ingress
namespace: kube-system
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
DaemonSet 形式部署traefik
创建文件:traefik-daemonset.yaml,为保证traefik 总能提供服务,在每个节点上都部署一个traefik,所以这里使用DaemonSet 的形式
kind: ConfigMap
apiVersion: v1
metadata:
name: traefik-conf
namespace: kube-system
data:
traefik-config: |-
defaultEntryPoints = ["http","https"]
[entryPoints]
[entryPoints.http]
address = ":80"
[entryPoints.http.redirect]
entryPoint = "https"
[entryPoints.https]
address = ":443"
[entryPoints.https.tls]
[[entryPoints.https.tls.certificates]]
CertFile = "/ssl/ssl.crt"
KeyFile = "/ssl/ssl.key" ---
kind: DaemonSet
apiVersion: extensions/v1beta1
metadata:
name: traefik-ingress
namespace: kube-system
labels:
k8s-app: traefik-ingress
spec:
template:
metadata:
labels:
k8s-app: traefik-ingress
name: traefik-ingress
spec:
terminationGracePeriodSeconds:
restartPolicy: Always
serviceAccountName: ingress
containers:
- image: traefik:latest
name: traefik-ingress
ports:
- name: http
containerPort:
hostPort:
- name: https
containerPort:
hostPort:
- name: admin
containerPort:
args:
- --configFile=/etc/traefik/traefik.toml
- -d
- --web
- --kubernetes
- --logLevel=DEBUG
volumeMounts:
- name: traefik-config-volume
mountPath: /etc/traefik
- name: traefik-ssl-volume
mountPath: /ssl
volumes:
- name: traefik-config-volume
configMap:
name: traefik-conf
items:
- key: traefik-config
path: traefik.toml
- name: traefik-ssl-volume
secret:
secretName: traefik-ssl
注意上面的yaml 文件中我们添加了一个名为traefik-conf的ConfigMap,该配置是用来将http 请求强制跳转成https,并指定https 所需CA 文件地址,这里我们使用secret的形式来指定CA 文件的路径:
$ ls
ssl.crt ssl.key
$ kubectl create secret generic traefik-ssl --from-file=ssl.crt --from-file=ssl.key --namespace=kube-system
secret "traefik-ssl" created
创建ingress
创建文件:traefik-ingress.yaml,现在可以通过创建ingress文件来定义请求规则了,根据自己集群中的service 自己修改相应的serviceName 和servicePort
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: traefik-ingress
spec:
rules:
- host: traefik.nginx.io
http:
paths:
- path: /
backend:
serviceName: my-nginx
servicePort:
执行创建命令:
$ kubectl create -f ingress-rbac.yaml
serviceaccount "ingress" created
clusterrolebinding "ingress" created
$ kubectl create -f traefik-daemonset.yaml
configmap "traefik-conf" created
daemonset "traefik-ingress" created
$ kubectl create -f traefik-ingress.yaml
ingress "traefik-ingress" created
Traefik UI
创建文件:traefik-ui.yaml,
apiVersion: v1
kind: Service
metadata:
name: traefik-ui
namespace: kube-system
spec:
selector:
k8s-app: traefik-ingress
ports:
- name: web
port:
targetPort:
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: traefik-ui
namespace: kube-system
spec:
rules:
- host: traefik-ui.local
http:
paths:
- path: /
backend:
serviceName: traefik-ui
servicePort: web
测试
部署完成后,在本地/etc/hosts添加一条配置:
# 将下面的xx.xx.xx.xx替换成任意节点IPxx.xx.xx.xx master03 traefik.nginx.io traefik-ui.local
配置完成后,在本地访问:traefik-ui.local,则可以访问到traefik的dashboard页面:
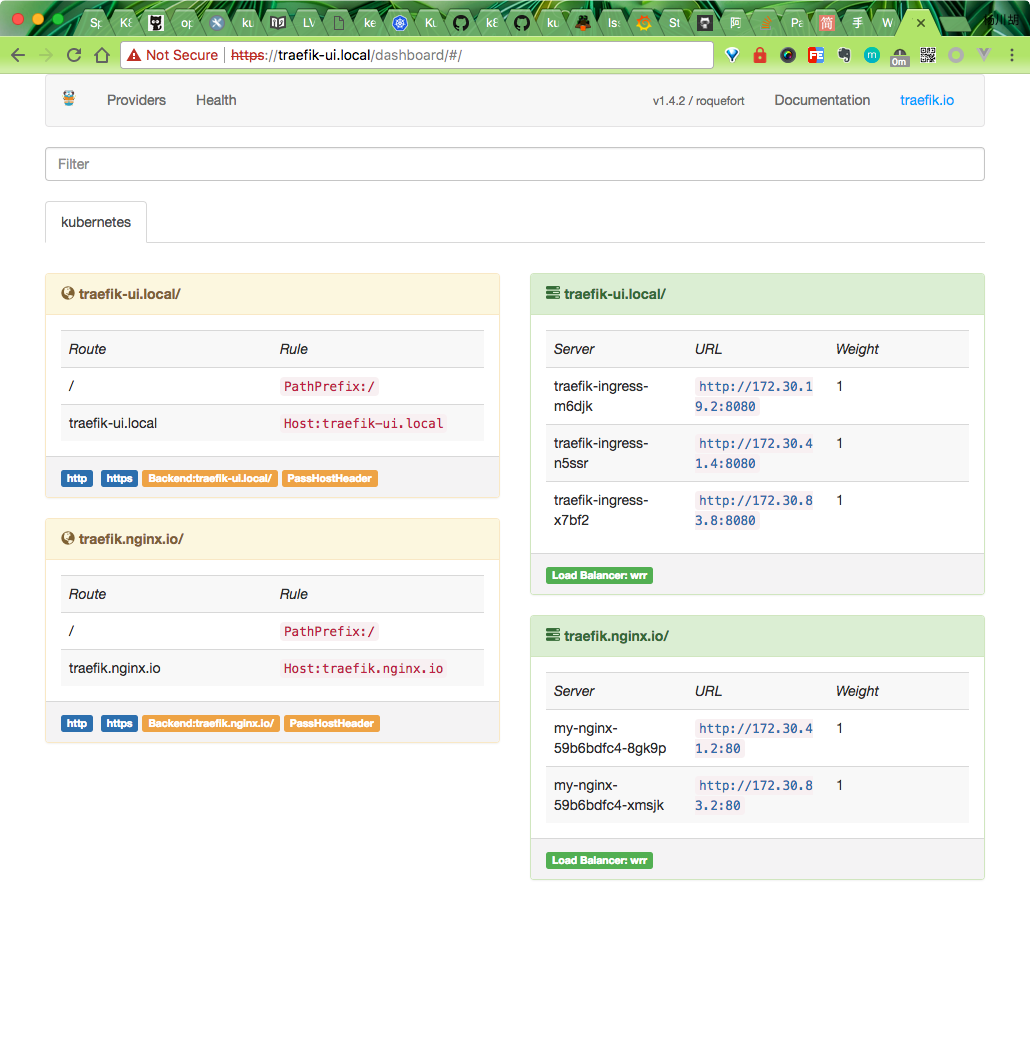 traefik dashboard
traefik dashboard
同样的可以访问traefik.nginx.io,得到正确的结果页面:
 WX20171110-140306
WX20171110-140306
上面配置完成后,就可以将我们的所有节点加入到一个SLB中,然后配置相应的域名解析到SLB即可。
13. 日志收集
参考文章kubernetes 日志收集方案
14. 私有仓库harbor 搭建
参考文章在kubernetes 上搭建docker 私有仓库Harbor
15. 问题汇总
15.1 dashboard无法显示监控图
dashboard 和heapster influxdb都部署完成后 dashboard依旧无法显示监控图 通过排查 heapster log有超时错误
`$ kubectl logs -f pods/heapster--58d9r -n kube-system E0630 ::47.339987 reflector.go:] k8s.io/heapster/metrics/sources/kubelet/kubelet.go:: Failed to list *api.Node: Get http://kubernetes.default/api/v1/nodes?resourceVersion=0: dial tcp: i/o timeout E0630 17:23:47.340274 1 reflector.go:203] k8s.io/heapster/metrics/heapster.go:319: Failed to list *api.Pod: Get http://kubernetes.default/api/v1/pods?resourceVersion=0: dial tcp: i/o timeout E0630 17:23:47.340498 1 reflector.go:203] k8s.io/heapster/metrics/processors/namespace_based_enricher.go:84: Failed to list *api.Namespace: Get http://kubernetes.default/api/v1/namespaces?resourceVersion=0: dial tcp: lookup kubernetes.default on 10.254.0.2:53: dial udp 10.254.0.2:53: i/o timeout E0630 17:23:47.340563 1 reflector.go:203] k8s.io/heapster/metrics/heapster.go:327: Failed to list *api.Node: Get http://kubernetes.default/api/v1/nodes?resourceVersion=0: dial tcp: lookup kubernetes.default on 10.254.0.2:53: dial udp 10.254.0.2:53: i/o timeout E0630 17:23:47.340623 1 reflector.go:203] k8s.io/heapster/metrics/processors/node_autoscaling_enricher.goKubernetes集群安装(自己搭过,已搭好)的更多相关文章
- Kubernetes集群部署史上最详细(一)Kubernetes集群安装
适用部署结构以及版本 本系列中涉及的部署方式和脚本适用于1.13.x和1.14,而且采取的是二进制程序部署方式. 脚本支持的部署模式 最小部署模式 3台主机,1台为k8s的master角色,其余2台为 ...
- Kubernetes 集群安装部署
etcd集群配置 master节点配置 1.安装kubernetes etcd [root@k8s ~]# yum -y install kubernetes-master etcd 2.配置 etc ...
- 【Kubernetes学习之二】Kubernetes集群安装
环境 centos 7 Kubernetes有三种安装方式:yum.二进制.kubeadm,这里演示kubeadm. 一.准备工作1.软件版本 软件 版本 kubernetes v1.15.3 Cen ...
- Kubernetes集群安装
一.环境介绍 主机名 IP地址 master 192.168.0.100 node1 192.168.0.101 node2 192.168.0.102 1.1.操作系统: CensOS8.4.210 ...
- kubernetes 集群安装etcd集群,带证书
install etcd 准备证书 https://www.kubernetes.org.cn/3096.html 在master1需要安装CFSSL工具,这将会用来建立 TLS certificat ...
- centos7.5下kubeadm安装kubernetes集群安装
文章是按https://blog.csdn.net/Excairun/article/details/88962769,来进行操作并记录相关结果 版本:k8s V14.0,docker-ce 18.0 ...
- [转] Kubernetes集群安装文档-v1.6版本
[From] https://www.kubernetes.org.cn/1870.html http://jimmysong.io/kubernetes-handbook
- 基于Containerd安装部署高可用Kubernetes集群
转载自:https://blog.weiyigeek.top/2021/7-30-623.html 简述 Kubernetes(后续简称k8s)是 Google(2014年6月) 开源的一个容器编排引 ...
- Kubernetes集群的监控报警策略最佳实践
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/M2l0ZgSsVc7r69eFdTj/article/details/79652064 本文为Kub ...
随机推荐
- Java基础(八 前面补充)
1.笔记 1.局部内部类 如果一个类是定义在一个方法内部的,那么这就是一个局部内部类. “局部”:只有当前所属的方法才能使用它,出了这个方法外面就不能用了. 定义格式: 修饰符 class 外部类名称 ...
- Making Huge Palindromes LightOJ - 1258
题目链接:LightOJ - 1258 1258 - Making Huge Palindromes PDF (English) Statistics Forum Time Limit: 1 se ...
- 微信硬件平台(十) 1 ESP8266通过mqtt交互消息
//----------------------------------------------------------------------------------------// //----- ...
- gin内置验证器使用
gin内置验证器使用 func TopicUrl(f1 validator.FieldLevel) bool { return true //返回true表示验证成功 } func main(){ r ...
- pgloader 学习(七) 从归档文件加载数据
我们可以直接从zip,tar,gzip 文件获取内容 command file 参考格式 LOAD ARCHIVE FROM /Users/dim/Downloads/GeoLiteCity-late ...
- hasura skor 构建安装
hasura skor 前边有介绍过是一个挺不错的event trigger 插件,我们可以用来进行事件通知处理 官方有提供构建的方法,但是有些还是会有点问题,所以结合构建碰到的问题,修改下 clon ...
- 3-STM32物联网开发WIFI(ESP8266)+GPRS(Air202)系统方案升级篇(HTTP介绍,TCP实现HTTP下载文件)
https://www.cnblogs.com/yangfengwu/p/10357564.html 看了好多文章.....唉,还是自己亲自动手用网络监控软件测试吧 先看这个节安装WEB服务器.... ...
- 使用 css/less 动态更换主题色(换肤功能)
前言 说起换肤功能,前端肯定不陌生,其实就是颜色值的更换,实现方式有很多,也各有优缺点 一.看需求是什么 一般来说换肤的需求分为两种: 1. 一种是几种可供选择的颜色/主题样式,进行选择切换,这种可供 ...
- Codevs 3322 时空跳跃者的困境(组合数 二项式定理)
3322 时空跳跃者的困境 时间限制: 1 s 空间限制: 64000 KB 题目等级 : 钻石 Diamond 题目描述 Description 背景:收集完能量的圣殿战士suntian开始了他的追 ...
- Eclipse各个版本及其对应代号、下载地址列表【转】
Eclipse各个版本及其对应代号.下载地址列表 Eclipse各个版本及其对应代号.下载地址列表版本号 代码 日期 下载地址Eclipse 3.1 IO[木卫一,伊奥] 2005 http://ar ...