python语言(八)多线程、多进程、虚拟环境、unittest、生成测试报告
一、多线程
进程与线程
进程:进程是资源(CPU、内存等)分配的最小单位,进程有独立的地址空间与系统资源,一个进程可以包含一个或多个线程
线程:线程是CPU调度的最小单位,是进程的一个执行流,线程依赖于进程而存在,线程共享所在进程的地址空间和系统资源,每个线程有自己的堆栈和局部变量
并发与并行
并发:当系统只有一个CPU时,想执行多个线程,CPU就会轮流切换多个线程执行,当有一个线程被执行时,其他线程就会等待,但由于CPU调度很快,所以看起来像多个线程同时执行
并行:当系统有多个CPU时,执行多个线程,就可以分配到多个CPU上同时执行
同步与异步
同步:调用者调用一个功能时,必须要等到这个功能执行完返回结果后,才能再调用其他功能
异步:调用者调用一个功能时,不会立即得到结果,而是在调用发出后,被调用功能通过状态、通知来通告调用者,或通过回调函数处理这个调用
多线程模块 threading模块
threading模块常用函数
- threading.current_thread(): 返回当前的线程对象。
- threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.active_count(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
Thread类
通过threading.Thread()创建线程对象
主要参数:
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
- group 默认为 None,为了日后扩展 ThreadGroup 类实现而保留。
- target 是用于 run() 方法调用的可调用对象。默认是 None,表示不需要调用任何方法。
- name 是线程名称。默认情况下,由 "Thread-N" 格式构成一个唯一的名称,其中 N 是小的十进制数
- args 是用于调用目标函数的参数元组。默认是 ()
- kwargs 是用于调用目标函数的关键字参数字典。默认是 {}。
- daemon表示线程是不是守护线程。
Thread类常用方法与属性
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join(timeout=None): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
- name:线程对象名字
- setDaemon():设置是否为守护线程
1.1 创建线程
import threading # 导入线程模块
import time
# 线程是多个资源的集合
# 线程就是进程里面具体干活的
# 线程和线程之间是互相独立的
def down_load():
time.sleep(5) # 假设线程要执行5秒结束
print('运行完了')
def movie():
print('movie')
for i in range(10): # 启动10个线程
t = threading.Thread(target=down_load) # 实例化线程
t.start() # 启动它
for i in range(10): # 启动10个线程
t = threading.Thread(target=movie)
t.start()
movie movie movie movie movie movie movie movie movie movie 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了
2.2查看当前线程数、当前线程
import threading # 导入线程模块
import time
def down_load():
print(threading.current_thread()) # 显示当前线程
time.sleep(5) # 假设线程要执行5秒结束
print('运行完了')
def movie():
print('movie')
for i in range(10): # 启动10个线程
t = threading.Thread(target=down_load)
t.start()
for i in range(10): # 启动10个线程
t = threading.Thread(target=movie)
t.start()
print(threading.activeCount()) # 查看当前线程数
print(threading.current_thread()) # 查看当前线程
<Thread(Thread-1, started 20128)> <Thread(Thread-2, started 9024)> <Thread(Thread-3, started 20484)> <Thread(Thread-4, started 20488)> <Thread(Thread-5, started 20492)> <Thread(Thread-6, started 20496)> <Thread(Thread-7, started 20500)> <Thread(Thread-8, started 20504)> <Thread(Thread-9, started 20508)> <Thread(Thread-10, started 20512)> movie movie movie movie movie movie movie movie movie movie 11 <_MainThread(MainThread, started 1900)> 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了 运行完了
2.3 实现线程同步join()
import threading # 导入线程模块
import time
def down_load():
print(threading.current_thread()) # 显示当前线程
time.sleep(5) # 假设线程要执行5秒结束
print('运行完了')
def movie():
print('movie')
for i in range(10): # 启动10个线程
t = threading.Thread(target=down_load)
t.start()
t.join() # 使用join() 来实现线程同步
for i in range(10): # 启动10个线程
t = threading.Thread(target=movie)
t.start()
t.join()
使用join()需等上一个线程执行完,才会开始执行
针对上述,我希望:在所有线程都执行完后,一起结束
使用thread_list[]来解决
import threading # 导入线程模块
import time
def down_load():
print(threading.current_thread()) # 显示当前线程
time.sleep(5) # 假设线程要执行5秒结束
print('运行完了')
def movie():
print('movie')
thread_list = []
for i in range(5): # 启动10个线程
t = threading.Thread(target=down_load)
t.start()
thread_list.append(t) #把每个线程加入列表
print('thread_list',thread_list)
for thread in thread_list:
thread.join() # 等待子线程结束,然后同时结束
for i in range(10): # 启动10个线程
t = threading.Thread(target=movie)
t.start()
t.join()
或者
for i in range(5): # 启动10个线程
t = threading.Thread(target=movie)
t.start()
while threading.activeCount()!=1: # 当执行线程数=1时,线程循环结束
pass
2.4 多线程下载图片
先不用多线程
import requests
import time
from hashlib import md5
def down_load_pic(url):
req = requests.get(url)
m = md5(url.encode())
with open(m.hexdigest() + '.png', 'wb') as fw:
fw.write(req.content)
url_list = ['http://www.nnzhp.cn/wp-content/uploads/2019/11/b23755cdea210cfec903333c5cce6895.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/11/481b5135e75c764b32b224c5650a8df5.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/11/542824dde1dbd29ec61ad5ea867ef245.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/10/f410afea8b23fa401505a1449a41a133.png']
start_time = time.time()
for url in url_list:
down_load_pic(url)
end_time = time.time()
print(end_time - start_time)
然后用多线程下载
import requests
import time
import threading
from hashlib import md5
def down_load_pic(url):
req = requests.get(url)
m = md5(url.encode())
with open(m.hexdigest() + '.png', 'wb') as fw:
fw.write(req.content)
url_list = ['http://www.nnzhp.cn/wp-content/uploads/2019/11/b23755cdea210cfec903333c5cce6895.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/11/481b5135e75c764b32b224c5650a8df5.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/11/542824dde1dbd29ec61ad5ea867ef245.png',
'http://www.nnzhp.cn/wp-content/uploads/2019/10/f410afea8b23fa401505a1449a41a133.png']
start_time = time.time()
for url in url_list:
t = threading.Thread(
target=down_load_pic, args=(
url,)) # 如果只有一个参数的话,url后面要加一个逗号
t.start()
while threading.activeCount != 1:
pass
end_time = time.time()
print(end_time - start_time)
2.4 守护线程
无论是进程还是线程,都遵循:守护xx会等待主xx运行完毕后被销毁。需要强调的是:运行完毕并非终止运行。
- 对主进程来说,运行完毕指的是主进程代码运行完毕
- 对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕
详细解释
主进程在其代码结束后就已经算运行完毕了(守护进程在此时就被回收),然后主进程会一直等非守护的子进程都运行完毕后回收子进程的资源(否则会产生僵尸进程),才会结束。
主线程在其他非守护线程运行完毕后才算运行完毕(守护线程在此时就被回收)。因为主线程的结束意味着进程的结束,进程整体的资源都将被回收,而进程必须保证非守护线程都运行完毕后才能结束。
.setDaemon(True) # 设置子线程为守护线程
# 主线程结束,守护线程立马死掉
import threading,time
def down_load():
print(threading.current_thread()) # 显示当前线程
time.sleep(5) # 假设线程要执行5秒结束
print('运行完了')
for i in range(5): # 启动10个线程
t = threading.Thread(target=down_load)
t.setDaemon(True) # 设置子线程为守护线程
t.start() # 把子守护线程设置在主线程前
print('over')# 主线程结束,守护线程立马结束
二、多进程
进程:正在进行的一个过程或者说一个任务,二负责执行任务则是cpu。
import multiprocessing
import time
def down_load():
time.sleep(5)
print("运行完了")
# windows系统要求写 __main__
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=down_load)
p.start()
print(multiprocessing.current_process())
多线程 适用于IO密集型任务(网络下载、等待...) 网络IO 磁盘IO 多进程 适用于CPU密集型任务(查询、排序、计算、分析...)
import multiprocessing
import time
def down_load():
time.sleep(5)
print("运行完了")
# windows系统要求写 __main__
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=down_load)
p.start()
while len(multiprocessing.active_children())!=0: # 等待子进程结束
pass
print(multiprocessing.current_process())
print('end')
<_MainProcess(Process-3, started)> end <_MainProcess(Process-1, started)> end <_MainProcess(Process-2, started)> end <_MainProcess(Process-4, started)> end <_MainProcess(Process-5, started)> end 运行完了 运行完了 运行完了 运行完了 运行完了 <_MainProcess(MainProcess, started)> end
三、虚拟环境


.png)

python虚拟环境
3.1、在电脑上创建一个目录
3.2 cmd命令进入到该目录

3.3 运行命令:virtualenv UTP(在该目录下创建一个叫UTP的虚拟环境)

四、搭建测试环境
一、搭建测试环境
1、申请服务器 2、安装依赖软件:jdk1.8\redis\mysql\tomcat等等 3、获取代码,修改配置文件,(编译、打包) 4、导入基础数据(建表、导入数据) 5、代码放到服务器上,启动 二、日常部署 1、拉去最新代码,修改配置文件(编译、打包) 2、如果右边的sql,执行 3、服务器上代码替换成最新的,重启
五、单元测试
TestCase 也就是测试用例
TestSuite 多个测试用例集合在一起,就是TestSuite
TestLoader 是用来加载TestCase到TestSuite中的
TestRunner 是来执行测试用例的,测试的结果会保存到TestResult实例中,包括运行了多少测试用例,成功了多少,失败了多少等信息
import unittest
import HTMLTestRunner
def add(a, b):
return a + b
class AddTest(unittest.TestCase): # unittest.TestCase 副类
@classmethod
def setUpClass(cls): # 所有用例执行前,执行它
print("setUpClass")
@classmethod
def tearDownClass(cls): # 所有用例执行完,执行它
print("tearDownClass")
def setUp(self): # 每条用例执行前,执行它
print('setUP')
def tearDown(self): # 每条用例执行后,执行它
print('tearDown')
def test_normal(self): # 用例必须以test 开头运行
result = add(1, 1)
self.assertEqual(1, result)
def test_error(self):
result = add(1, 1)
self.assertEqual(1, result, '结果计算错误') # 可以传错误提示参数
if __name__ == '__main__':
file = open('report.html', 'wb')
runner = HTMLTestRunner.HTMLTestRunner(file, title='测试报告')
test_suite = unittest.makeSuite(AddTest) # 变成测试集合
runner.run(test_suite)

六、BeautifulReport
生成HTML测试报告的BeautifulReport 源码Clone地址为 https://github.com/TesterlifeRaymond/BeautifulReport,其中BeautifulReport.py和其template是我们需要的关键。
BeautifulReport.py
import os
import sys
from io import StringIO as StringIO
import time
import json
import unittest
import platform
import base64
from distutils.sysconfig import get_python_lib
import traceback
from functools import wraps
__all__ = ['BeautifulReport']
HTML_IMG_TEMPLATE = """
<a href="data:image/png;base64, {}">
<img src="data:image/png;base64, {}" width="800px" height="500px"/>
</a>
<br></br>
"""
class OutputRedirector(object):
""" Wrapper to redirect stdout or stderr """
def __init__(self, fp):
self.fp = fp
def write(self, s):
self.fp.write(s)
def writelines(self, lines):
self.fp.writelines(lines)
def flush(self):
self.fp.flush()
stdout_redirector = OutputRedirector(sys.stdout)
stderr_redirector = OutputRedirector(sys.stderr)
SYSSTR = platform.system()
SITE_PAKAGE_PATH = get_python_lib()
FIELDS = {
"testPass": 0,
"testResult": [
],
"testName": "",
"testAll": 0,
"testFail": 0,
"beginTime": "",
"totalTime": "",
"testSkip": 0
}
class PATH:
""" all file PATH meta """
# config_tmp_path = SITE_PAKAGE_PATH + '/BeautifulReport/template/template'
# config_tmp_path = SITE_PAKAGE_PATH + '/BeautifulReport/template/template'
config_tmp_path = os.path.dirname(os.path.abspath(__file__)) + '/template/template'
class MakeResultJson:
""" make html table tags """
def __init__(self, datas: tuple):
"""
init self object
:param datas: 拿到所有返回数据结构
"""
self.datas = datas
self.result_schema = {}
def __setitem__(self, key, value):
"""
:param key: self[key]
:param value: value
:return:
"""
self[key] = value
def __repr__(self) -> str:
"""
返回对象的html结构体
:rtype: dict
:return: self的repr对象, 返回一个构造完成的tr表单
"""
keys = (
'className',
'methodName',
'description',
'spendTime',
'status',
'log',
)
for key, data in zip(keys, self.datas):
self.result_schema.setdefault(key, data)
return json.dumps(self.result_schema)
class ReportTestResult(unittest.TestResult):
""" override"""
def __init__(self, suite, stream=sys.stdout):
""" pass """
super(ReportTestResult, self).__init__()
self.begin_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
self.start_time = 0
self.stream = stream
self.end_time = 0
self.failure_count = 0
self.error_count = 0
self.success_count = 0
self.skipped = 0
self.verbosity = 1
self.success_case_info = []
self.skipped_case_info = []
self.failures_case_info = []
self.errors_case_info = []
self.all_case_counter = 0
self.suite = suite
self.status = ''
self.result_list = []
self.case_log = ''
self.default_report_name = '自动化测试报告'
self.FIELDS = None
self.sys_stdout = None
self.sys_stderr = None
self.outputBuffer = None
@property
def success_counter(self) -> int:
""" set success counter """
return self.success_count
@success_counter.setter
def success_counter(self, value) -> None:
"""
success_counter函数的setter方法, 用于改变成功的case数量
:param value: 当前传递进来的成功次数的int数值
:return:
"""
self.success_count = value
def startTest(self, test) -> None:
"""
当测试用例测试即将运行时调用
:return:
"""
unittest.TestResult.startTest(self, test)
self.outputBuffer = StringIO()
stdout_redirector.fp = self.outputBuffer
stderr_redirector.fp = self.outputBuffer
self.sys_stdout = sys.stdout
self.sys_stdout = sys.stderr
sys.stdout = stdout_redirector
sys.stderr = stderr_redirector
self.start_time = time.time()
def stopTest(self, test) -> None:
"""
当测试用力执行完成后进行调用
:return:
"""
self.end_time = '{0:.3} s'.format((time.time() - self.start_time))
self.result_list.append(self.get_all_result_info_tuple(test))
self.complete_output()
def complete_output(self):
"""
Disconnect output redirection and return buffer.
Safe to call multiple times.
"""
if self.sys_stdout:
sys.stdout = self.sys_stdout
sys.stderr = self.sys_stdout
self.sys_stdout = None
self.sys_stdout = None
return self.outputBuffer.getvalue()
def stopTestRun(self, title=None) -> dict:
"""
所有测试执行完成后, 执行该方法
:param title:
:return:
"""
FIELDS['testPass'] = self.success_counter
for item in self.result_list:
item = json.loads(str(MakeResultJson(item)))
FIELDS.get('testResult').append(item)
FIELDS['testAll'] = len(self.result_list)
FIELDS['testName'] = title if title else self.default_report_name
FIELDS['testFail'] = self.failure_count
FIELDS['beginTime'] = self.begin_time
end_time = int(time.time())
start_time = int(time.mktime(time.strptime(self.begin_time, '%Y-%m-%d %H:%M:%S')))
FIELDS['totalTime'] = str(end_time - start_time) + 's'
FIELDS['testError'] = self.error_count
FIELDS['testSkip'] = self.skipped
self.FIELDS = FIELDS
return FIELDS
def get_all_result_info_tuple(self, test) -> tuple:
"""
接受test 相关信息, 并拼接成一个完成的tuple结构返回
:param test:
:return:
"""
return tuple([*self.get_testcase_property(test), self.end_time, self.status, self.case_log])
@staticmethod
def error_or_failure_text(err) -> str:
"""
获取sys.exc_info()的参数并返回字符串类型的数据, 去掉t6 error
:param err:
:return:
"""
return traceback.format_exception(*err)
def addSuccess(self, test) -> None:
"""
pass
:param test:
:return:
"""
logs = []
output = self.complete_output()
logs.append(output)
if self.verbosity > 1:
sys.stderr.write('ok ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('.')
self.success_counter += 1
self.status = '成功'
self.case_log = output.split('\n')
self._mirrorOutput = True # print(class_name, method_name, method_doc)
def addError(self, test, err):
"""
add Some Error Result and infos
:param test:
:param err:
:return:
"""
logs = []
output = self.complete_output()
logs.append(output)
logs.extend(self.error_or_failure_text(err))
self.failure_count += 1
self.add_test_type('失败', logs)
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
self._mirrorOutput = True
def addFailure(self, test, err):
"""
add Some Failures Result and infos
:param test:
:param err:
:return:
"""
logs = []
output = self.complete_output()
logs.append(output)
logs.extend(self.error_or_failure_text(err))
self.failure_count += 1
self.add_test_type('失败', logs)
if self.verbosity > 1:
sys.stderr.write('F ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('F')
self._mirrorOutput = True
def addSkip(self, test, reason) -> None:
"""
获取全部的跳过的case信息
:param test:
:param reason:
:return: None
"""
logs = [reason]
self.complete_output()
self.skipped += 1
self.add_test_type('跳过', logs)
if self.verbosity > 1:
sys.stderr.write('S ')
sys.stderr.write(str(test))
sys.stderr.write('\n')
else:
sys.stderr.write('S')
self._mirrorOutput = True
def add_test_type(self, status: str, case_log: list) -> None:
"""
abstruct add test type and return tuple
:param status:
:param case_log:
:return:
"""
self.status = status
self.case_log = case_log
@staticmethod
def get_testcase_property(test) -> tuple:
"""
接受一个test, 并返回一个test的class_name, method_name, method_doc属性
:param test:
:return: (class_name, method_name, method_doc) -> tuple
"""
class_name = test.__class__.__qualname__
method_name = test.__dict__['_testMethodName']
method_doc = test.__dict__['_testMethodDoc']
return class_name, method_name, method_doc
class BeautifulReport(ReportTestResult, PATH):
img_path = 'img/' if platform.system() != 'Windows' else 'img\\'
def __init__(self, suites):
super(BeautifulReport, self).__init__(suites)
self.suites = suites
self.log_path = None
self.title = '自动化测试报告'
self.filename = 'report.html'
def report(self, description, filename: str = None, log_path='.'):
"""
生成测试报告,并放在当前运行路径下
:param log_path: 生成report的文件存储路径
:param filename: 生成文件的filename
:param description: 生成文件的注释
:return:
"""
if filename:
self.filename = filename if filename.endswith('.html') else filename + '.html'
if description:
self.title = description
self.log_path = os.path.abspath(log_path)
self.suites.run(result=self)
self.stopTestRun(self.title)
self.output_report()
text = '\n测试已全部完成, 可前往{}查询测试报告'.format(self.log_path)
print(text)
def output_report(self):
"""
生成测试报告到指定路径下
:return:
"""
template_path = self.config_tmp_path
# template_path = "D:\\PythonUnittest\\Template\\template"
override_path = os.path.abspath(self.log_path) if \
os.path.abspath(self.log_path).endswith('/') else \
os.path.abspath(self.log_path) + '/'
with open(template_path, 'rb') as file:
body = file.readlines()
with open(override_path + self.filename, 'wb') as write_file:
for item in body:
if item.strip().startswith(b'var resultData'):
head = ' var resultData = '
item = item.decode().split(head)
item[1] = head + json.dumps(self.FIELDS, ensure_ascii=False, indent=4)
item = ''.join(item).encode()
item = bytes(item) + b';\n'
write_file.write(item)
@staticmethod
def img2base(img_path: str, file_name: str) -> str:
"""
接受传递进函数的filename 并找到文件转换为base64格式
:param img_path: 通过文件名及默认路径找到的img绝对路径
:param file_name: 用户在装饰器中传递进来的问价匿名
:return:
"""
pattern = '/' if platform != 'Windows' else '\\'
with open(img_path + pattern + file_name, 'rb') as file:
data = file.read()
return base64.b64encode(data).decode()
def add_test_img(*pargs):
"""
接受若干个图片元素, 并展示在测试报告中
:param pargs:
:return:
"""
def _wrap(func):
@wraps(func)
def __wrap(*args, **kwargs):
img_path = os.path.abspath('{}'.format(BeautifulReport.img_path))
try:
result = func(*args, **kwargs)
except Exception:
if 'save_img' in dir(args[0]):
save_img = getattr(args[0], 'save_img')
save_img(func.__name__)
data = BeautifulReport.img2base(img_path, pargs[0] + '.png')
print(HTML_IMG_TEMPLATE.format(data, data))
sys.exit(0)
print('<br></br>')
if len(pargs) > 1:
for parg in pargs:
print(parg + ':')
data = BeautifulReport.img2base(img_path, parg + '.png')
print(HTML_IMG_TEMPLATE.format(data, data))
return result
if not os.path.exists(img_path + pargs[0] + '.png'):
return result
data = BeautifulReport.img2base(img_path, pargs[0] + '.png')
print(HTML_IMG_TEMPLATE.format(data, data))
return result
return __wrap
return _wrap
template
template文件是和BeautifulReport.py一起使用的,他将unittest的测试结果按照template的样式转换成HTML格式的报告
调用BeautifulReport
run_all_cases.py
import unittest
from BeautifulReport import BeautifulReport
if __name__ == '__main__':
test_suite = unittest.defaultTestLoader.discover('TestScripts', pattern='test*.py')
result = BeautifulReport(test_suite)
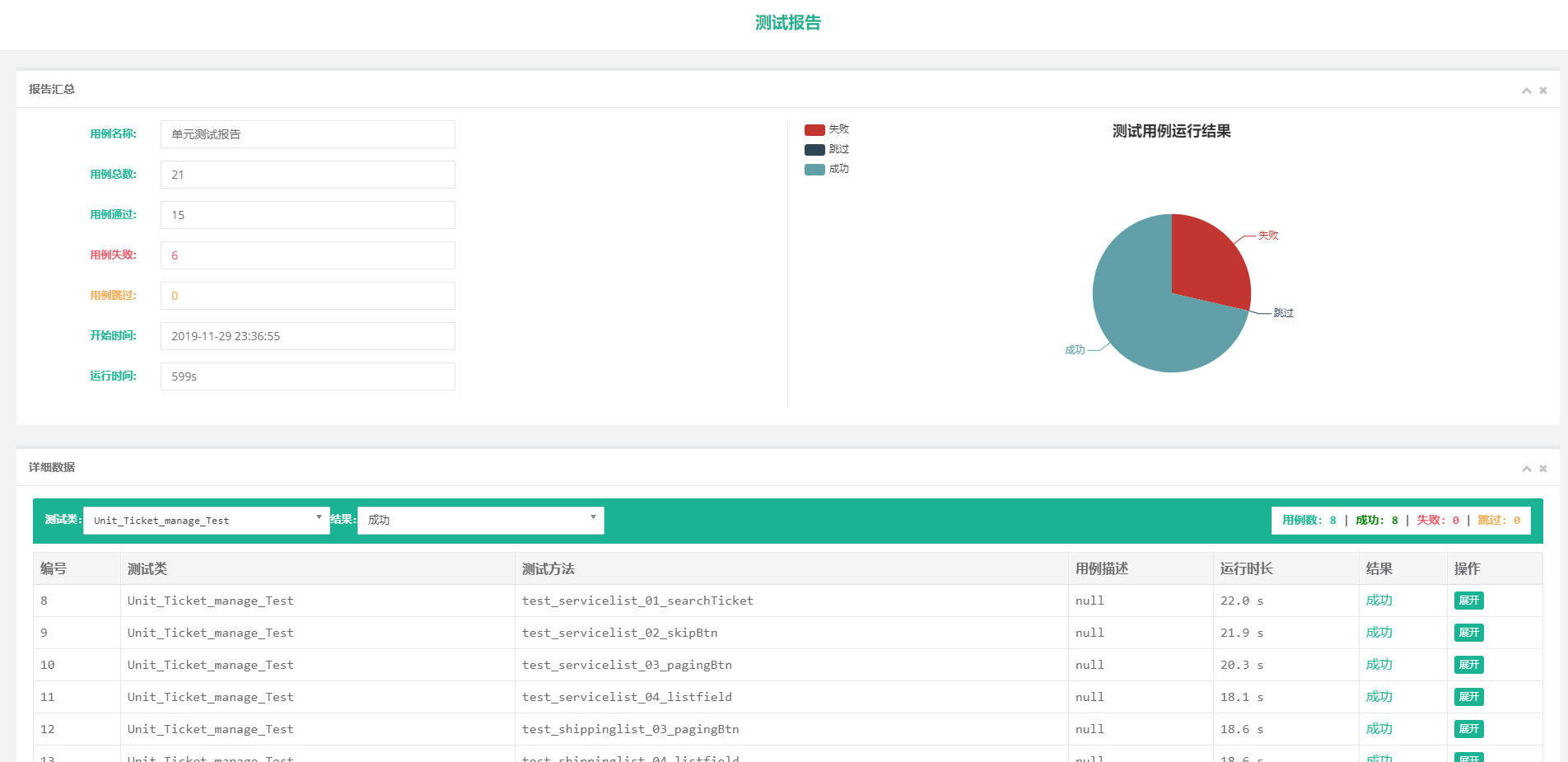
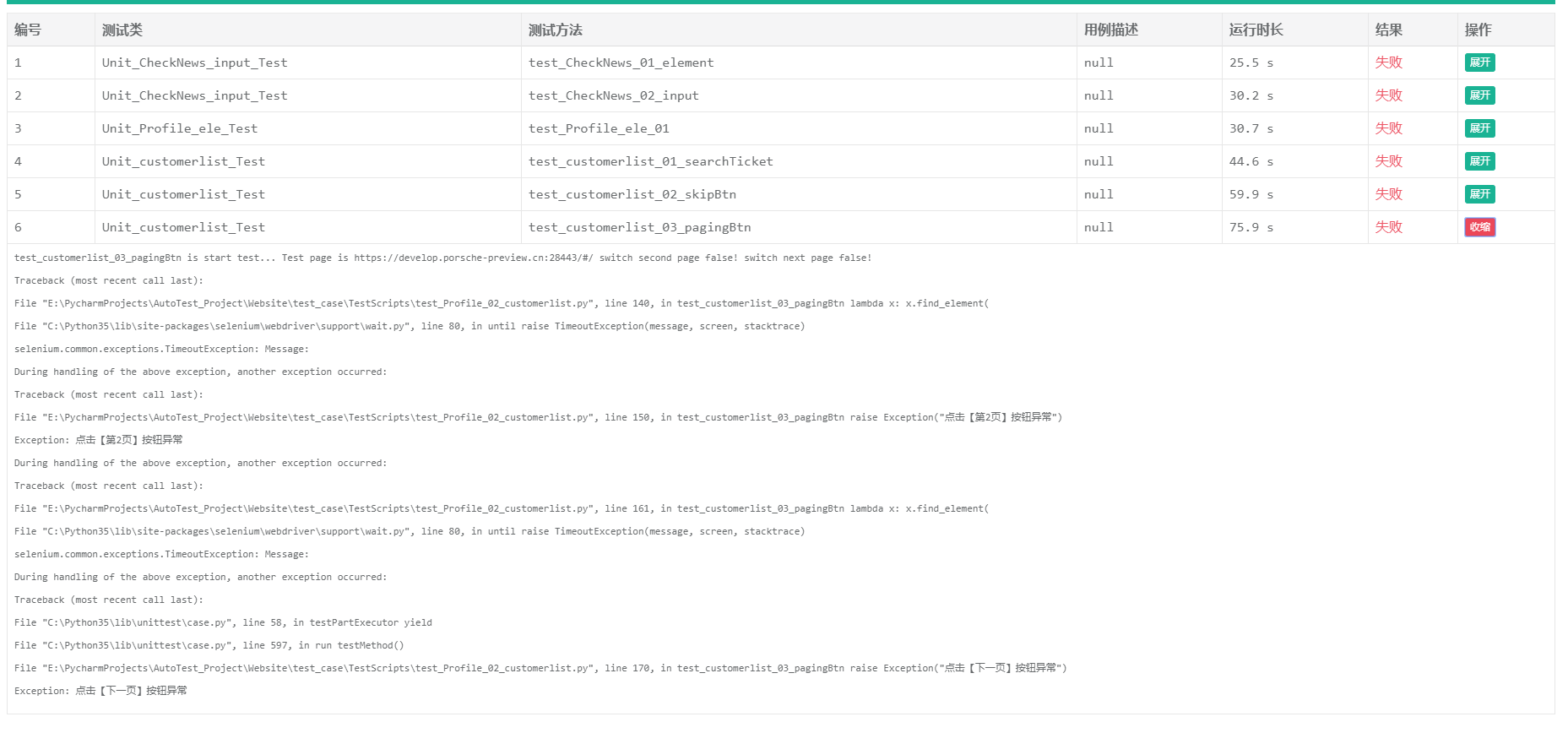
result.report(filename='HC_Unittest测试报告', description='单元测试报告')
python语言(八)多线程、多进程、虚拟环境、unittest、生成测试报告的更多相关文章
- python接口自动化测试(七)unittest 生成测试报告
用例的管理问题解决了后,接下来要考虑的就是报告我问题了,这里生成测试报告主要用到 HTMLTestRunner.py 这个模块,下面简单介绍一下如何使用: 一.下载HTMLTestRunner下载: ...
- 3.5 unittest生成测试报告HTMLTestRunner
3.5 unittest生成测试报告HTMLTestRunner 前言批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的.unittest里面是不 ...
- Python自动化 unittest生成测试报告(HTMLTestRunner)03
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Python+Selenium笔记(五):生成测试报告
#HTMLTestRunner代码修改参考 微微微笑 的说明,下面是链接,这个已经说的很详细了 https://www.cnblogs.com/miniren/p/5301081.html (一) 前 ...
- (appium+python)UI自动化_09_unittest批量运行测试用例&生成测试报告
前言 上篇文章[(appium+python)UI自动化_08_unittest编写测试用例]讲到如何使用unittets编写测试用例,并执行测试文件.接下来讲解下unittest如何批量执行测试文件 ...
- python学习之多线程多进程
python基础 进程&线程 进程是一组资源的集合,运行一个系统就是打开了一个进程,如果同时打开了两个记事本就是开启了两个进程,进程是一个笼统的概念,进程中由线程干活工作,由进程统一管理 一个 ...
- 记录python接口自动化测试--利用unittest生成测试报告(第四目)
前面介绍了是用unittest管理测试用例,这次看看如何生成html格式的测试报告 生成html格式的测试报告需要用到 HTMLTestRunner,在网上下载了一个HTMLTestRunner.py ...
- [b0022] python 归纳 (八)_多进程_基本使用
# -*- coding: UTF-8 -*- """ 测试进程使用 multiprocessing.Process 使用: 1. 准备一个函数<fun>,子 ...
- Python+request 测试结果结合unittest生成测试报告《四》
测试报告示例图: 目录结构介绍: 主要涉及更改的地方: 1.导入 Common.HTMLTestRunner2文件 2.run_test.py文件中新增测试报告相关的代码 具体代码实现: 1 ...
随机推荐
- java web开发入门十一(idea maven mybatis自动代码生成)基于intellig idea
6.idea maven mybatis逆向工程(代码生成器) 1.配置pom.xml 在plugins标签下添加mybatis-generator-maven-plugin <plugin&g ...
- mysql Duplicate entry '9223372036854775807' for key 'PRIMARY'
mysql插入数据报错提示: ERROR 1062(23000) Duplicate entry '9223372036854775807' for key 'PRIMARY' 发现问题果断 直接 ...
- nginx学习笔记2
nginx基础配置 一.nginx常用命令 nginx -s reload:在nginx已经启动的情况下重新加载配置文件(平滑重启) nginx -s reopen:重新打开日志文件 nginx -c ...
- asp.net core 2.1 容器中使用 System.Drawing.Common 的问题
- laravel中如何执行请求
laravel中如何执行request请求?本篇文章给大家介绍关于laravel中执行请求的方法,需要的朋友可以参考一下,希望对你有所帮助. 我们先来看一下request是什么? 客户端(例如Web浏 ...
- SQL ----------- 借助视图写多表查询
在多表查询中可能遇到两表.三表乃致四表查询,自己进行直接用sql 语句进行书写的话可能比较难,但是可以借助视图进行分析,书写 1.右击视图点击新建 选择需要的表点击添加,注意两个表之间要有相同的字段 ...
- c++小学期大作业攻略(一)环境配置
UPDATE at 2019/07/20 20:21 更新了Qt连接mysql的方法,但是是自己仿照连VS的方法摸索出来的,简单测试了一下能work但是不保证后期不会出问题.如果你在尝试过程中出现了任 ...
- jetbrain 公司2019年全套产品的破解方案
百度网盘下载地址是:链接:https://pan.baidu.com/s/1E4E76Oglfexed0iHNiXjEQ 密码:pehx ======================== ...
- Web应急:门罗币恶意挖矿
门罗币(Monero 或 XMR),它是一个非常注重于隐私.匿名性和不可跟踪的加密数字货币.只需在网页中配置好js脚本,打开网页就可以挖矿,是一种非常简单的挖矿方式,而通过这种恶意挖矿获取数字货币是黑 ...
- ASP.NET Core 3.0 WebApi 系列【1】创建ASP.NET Core WebApi 项目
目录 写在前面 一.运行环境 二.项目搭建 三.测试 API 四.基础知识 五.写在最后 写在前面 C#语言可以创建RESTful服务,被称作WebApi.在这里总结学习使用支持创建.读取.更新.删除 ...