C语言笔记(一)
笑话一枚:
程序员 A:“哥们儿,最近手头紧,借点钱?”
程序员 B:“成啊,要多少?”
程序员 A:“一千行不?”
程序员 B:“咱俩谁跟谁!给你凑个整,1024,拿去吧。”
========================= 我 是 分 割 线 =========================
前言
C语言允许直接访问物理地址,可以直接对硬件进行操作,非常适合开发内核和硬件驱动。
书上看来一句话:普通人用 C 语言在 3 年之下,一般来说,还没掌握 C 语言;
5 年之下,一般来说还没熟悉 C 语言;10 年之下,谈不上精通。
学习一门语言最基本的还是要多码码,多调试,必要的时候可以用小黄鸭调试法。
多思考,遇到问题自己先尝试深入研究和解决。
下面的笔记来自《C语言深度解剖》
变量
定义、声明最重要的区别:定义创建了对象并为这个对象分配了内存,声明没有分配内存。
一般的变量使用驼峰命名法(CamelCase),加上必要的前后缀。
所有宏定义、枚举常数、只读变量全用大写字母命名,用下划线分割单词。
c语言有4种存储类型:auto, extern, register, static,定义变量的时候只能指定其中的一种类型。
而变量分配在内存存储空间的有:BSS区、数据区、栈区、堆区。
进程在内存中的结构
- 代码区:存放CPU执行的机器指令,代码区是可共享,并且是只读的。
- BSS区:存放的是未初始化的全局变量和静态变量。
- 数据区:存放已初始化的全局变量、静态变量(全局和局部)、常量数据。
- 栈区:由编译器自动分配释放,存放函数的参数值、返回值和局部变量,在程序运行过程中实时分配和释放,栈区由操作系统自动管理,无须程序员手动管理。
- 堆区:由malloc()函数分配的内存块,使用free()函数释放内存,堆的申请释放工作由程序员控制,容易产生内存泄漏。
也有变量不在内存中:register 变量可能不存放在内存中,所以不能用取址运算符“&”来获取 register 变量的地址。
static的2个作用
第一个作用:修饰变量。静态全局变量和静态局部变量,都存在内存的静态区。
静态全局变量,作用域仅限于变量被定义的文件中,其他文件即使用 extern 声明也没法使用他。
静态局部变量,在函数体里面定义的,就只能在这个函数里用了,同一个文档中的其他函数也用不了。
第二个作用:修饰函数。不是指存储方式,而是指对函数的作用域仅局限于本文件(所以又称内部函数)。
好处是:不同的人编写不同的函数时,不用担心自己定义的函数,是否会与其它文件中的函数同名。
sizeof关键字
int i=0;
A),sizeof(int); B),sizeof(i); C),sizeof int; D),sizeof i;
这里只有选项C是错误的,因为 sizeof 在计算变量所占空间大小时,括号可以省略,而计算类型大小时括号不能省略。
还有就是 sizeof 不怕地址越界,它只计算变量类型占空间大小,不会去访问变量的地址,也就不清楚人家存不存在了。
signed、unsigned 关键字
1.下面的代码输出是什么?为什么?
void foo(viod)
{
unsigned int a = ;
int b = -;
(a+b>)?puts(">6"):puts("<=6");
}
2.下面的代码的结果是多少?为什么?
int main()
{
char a[];
int i;
for(i=; i<; i++)
{
a[i] = --i;
}
printf("%d",strlen(a));
return ;
}
void 的字面意思是“空类型”,void *则为“空类型指针”,void *可以指向任何类型的数据。
任何类型的指针都可以直接赋值给 void *,无需进行强制类型转换:
void *p1;
int *p2;
p1 = p2;
case 后面的值只能是整型或字符型的常量或常量表达式。
定义 const 只读变量,具有不可变性。const 修饰的仍然是变量,只不过是只读属性罢了,不能当作常量使用。
const 修饰符也可以修饰函数的参数,当不希望这个参数值被函数体内意外改变时使用。
const的作用:节省空间,避免不必要的内存分配,同时提高效率
编译器通常不为普通 const 只读变量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的值,没有了存储与读内存的操作,使得它的效率也很高。
真时假亦真,假时真亦假
C语言中,0表示逻辑假,非0表示逻辑真。从数值上看,NULL、 '\0' 和 0 是一样的(注意和 '0' 的区别)。C语言不会黑白不分,只要不是假就是真,但是这样会不会太极端吗?
volatile
volatile修饰的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问。
先看看下面的例子:
inti=10;
intj = i;//(1)语句
intk = i;//(2)语句
这时候编译器对代码进行优化,因为在(1)、(2)两条语句中,i 没有被用作左值(没有被赋值)。这时候编译器认为 i 的值没有发生改变,所以在(1)语句时从内存中取出 i 的值赋给 j 之后,这个值并没有被丢掉,而是在(2)语句时继续用这个值给 k 赋值。编译器不会生成出汇编代码重新从内存里取 i 的值,这样提高了效率。
但要注意:(1)、(2)语句之间 i 没有被用作左值才行。
再看另一个例子:
volatile inti=10;
intj = i;//(3)语句
intk = i;//(4)语句
volatile 关键字告诉编译器 i 是随时可能发生变化的,每次使用它的时候必须从内存中取出 i 的值,因而编译器生成的汇编代码会重新从 i 的地址处读取数据放在 k 中。
什么时候要使用 volatile ?
如果 i 是一个寄存器变量或者表示一个端口数据或者是多个线程的共享数据,就容易出错,所以说 volatile 可以保证对特殊地址的稳定访问。
大小端模式
3.确认当前系统的存储模式?
int checkSystem{
union check
{
int i;
char ch;
}c;
c.i = ;
return(c.ch == );
}
若处理器是 Big_endian 的,则返回 0;若是 Little_endian 的,则返回 1。
大端模式(Big_endian) :字数据的 高字节 存储在 低地址中,而字数据的 低字节 则存放在 高地址中。
小端模式(Little_endian):字数据的 高字节 存储在 高地址中,而字数据的 低字节 则存放在 低地址中。

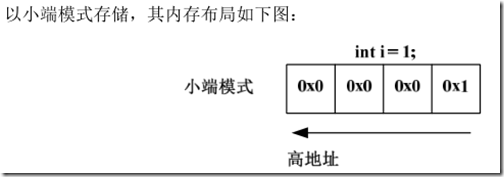
百度百科:
目前 Intel 的 80x86 系列芯片是唯一还在坚持使用小端的芯片,而 MIPS 和 ARM 等芯片要么采用全部大端的方式储存,要么提供选项支持在大小端之间切换。
另外,对于大小端的处理也和编译器的实现有关,在 C 语言中,默认是小端的(但在一些对于单片机的实现中却是基于大端,比如 Keil C51),Java 是平台无关的,默认是大端。在网络上传输数据普遍采用的都是大端。
4.p->i的值为多少?
union
{
int i;
char a[];
}*p,u;
p = &u;
p->a[] = 0x39;
p->a[] = 0x38;
union 型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始的。
5.在 x86 系统下,以下程序输出的值为多少?
#include <stdio.h>
int main(void)
{
int a[] = {,,,,};
int *ptr1 = (int *)(&a + );
int *ptr2 = (int *)((int)a + );
printf("%x,%x\n",ptr1[-],*ptr2);
return ;
}
结构体struct
6.下面2段代码有什么区别?
//代码(1)
structTestStruct1
{
char c1;
short s;
char c2;
int i;
};
//代码(2)
structTestStruct2
{
char c1;
char c2;
short s;
int i;
};
sizeof(TestStruct1)的值为 12
sizeof(TestStruct2)的值为 8
字,双字,和四字在自然边界上不需要在内存中对齐。(对字,双字,和四字来说,自然边界分别是偶数地址,可以被 4 整除的地址,和可以被 8 整除的地址。)无论如何,为了提高程序的性能,数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;然而,对齐的内存访问仅需要一次访问。
可以利用#pragma pack()来改变编译器的默认对齐方式:
#pragma pack(n) //n=1,2,4,8,16…
枚举类型enum
enum Color
{
GREEN = ,
RED, //2
BLUE, //3
GREEN_RED = ,
GREEN_BLUE //11
}ColorVal;
函数
至少的函数头部
// 功 能: 改变缓冲区大小
// 参 数: nNewSize 缓冲区新长度
// 返回值: 缓冲区当前长度
// 说 明: 保持原信息内容不变
完整的函数说明
/************************************************************************
* Function Name : nucFindThread
* Create Date : 2000/01/07
* Author/Corporation : your name/your company name
*
* Description : Find a proper thread in thread array.
* If it’s a new then search an empty.
*
* Param : ThreadNo : someParam description
* ThreadStatus : someParam description
*
* Return Code : Return Code description,eg:
ERROR_Fail: not find a thread
ERROR_SUCCEED: found
*
* Global Variable : DISP_wuiSegmentAppID
* File Static Variable : naucThreadNo
* Function Static Variable : None
*
*------------------------------------------------------------------------
* Revision History
* No. Date Revised by Item Description
* V0.5 2008/01/07 your name … …
************************************************************************/
static unsigned char nucFindThread(unsigned char ThreadNo,unsigned char ThreadStatus)
{
// TODO:...
}
//Blank Line
函数编写的一些注意:
- 保护性编程
- 缩进量统一使用4个字符
- 在一个函数体内,变量定义与函数语句之间要加空行
- 逻揖上密切相关的语句之间不加空行,其它地方应加空行分隔
- 复杂的函数中,在分支语句,循环语句结束之后需要适当的注释,方便区分各分支或循环体 //end“for(condition)”
- 使用 assert 宏做函数入口校验 assert(NULL != p);
- 递归的深度太大可能出现错误(比如栈溢出)
- return 语句不可返回指向“栈内存”的“指针”,因为该内存在函数体结束时被自动销毁
文件
文件命名:模块名缩写 + 小写字母名字
文件头部说明
/************************************************************************
* File Name : FN_FileName.c/ FN_FileName.h
* Copyright : 2003-2008 XXXX Corporation,All Rights Reserved.
* Module Name : DrawEngine/Display
*
* CPU : ARM7
* RTOS : Tron
*
* Create Date : 2008/10/01
* Author/Corporation : WhoAmI/yourcompany name
*
* AbstractDescription : Place some descriptionhere.
*
*-----------------------Revision History--------------------------------
* No Version Date Revised By Item Description
* 1 V0.95 08.05.18 WhoAmI abcdefghijklm WhatUDo
*
************************************************************************/
#ifndef __FN_FILENAME_H
#define __FN_FILENAME_H
#endif
// Debug Switch Section
// Include File Section
// Macro Define Section
// Structure Define Section
// Prototype Declare Section
// Global Variable Declare Section
// File Static Variable Define Section
// Function Define Section
之后的打算:
- 阅读《现代方法》(第2版)中关于预处理的部分
- 学习arm汇编
- 从汇编语言的层次理解C语言,姚新颜先生的《C语言:标准与实现》《C/C++深层探索》,关于X86汇编
C语言笔记(一)的更多相关文章
- R语言笔记
R语言笔记 学习R语言对我来说有好几个地方需要注意的,我觉得这样的经验也适用于学习其他的新的语言. 语言的目标 我理解语言的目标就是这个语言是用来做什么的,为什么样的任务服务的,也就是设计这个语言的动 ...
- R语言笔记4--可视化
接R语言笔记3--实例1 R语言中的可视化函数分为两大类,探索性可视化(陌生数据集,不了解,需要探索里面的信息:偏重于快速,方便的工具)和解释性可视化(完全了解数据集,里面的故事需要讲解别人:偏重全面 ...
- Scala语言笔记 - 第一篇
目录 Scala语言笔记 - 第一篇 1 基本类型和循环的使用 2 String相关 3 模式匹配相关 4 class相关 5 函数调用相关 Scala语言笔记 - 第一篇 最近研究了下scala ...
- Go 语言笔记
Go 语言笔记 基本概念 综述 Go 语言将静态语言的安全性和高效性与动态语言的易开发性进行有机结合,达到完美平衡. 设计者通过 goroutine 这种轻量级线程的概念来实现这个目标,然后通过 ch ...
- 014-预处理指令-C语言笔记
014-预处理指令-C语言笔记 学习目标 1.[掌握]枚举 2.[掌握]typedef关键字 3.[理解]预处理指令 4.[掌握]#define宏定义 5.[掌握]条件编译 6.[掌握]static与 ...
- 013-结构体-C语言笔记
013-结构体-C语言笔记 学习目录 1.[掌握]返回指针的函数 2.[掌握]指向函数的指针 3.[掌握]结构体的声明 4.[掌握]结构体与数组 5.[掌握]结构体与指针 6.[掌握]结构体的嵌套 7 ...
- 011-指针(上)-C语言笔记
011-指针(上)-C语言笔记 学习目标 1.[掌握]字符串常用函数 2.[掌握]指针变量的声明 3.[掌握]指针变量的初始化 4.[掌握]函数与指针 5.[掌握]指针的数据类型 6.[掌握]多级指针 ...
- 010-字符串-C语言笔记
010-字符串-C语言笔记 学习目标 1.[掌握]二维数组的声明和初始化 2.[掌握]遍历二维数组 3.[掌握]二维数组在内存中的存储 4.[掌握]二维数组与函数 5.[掌握]字符串 一.二维数组的声 ...
- 009-数组-C语言笔记
009-数组-C语言笔记 学习目标 1.[掌握]数组的声明 2.[掌握]数组元素的赋值和调用 3.[掌握]数组的初始化 4.[掌握]数组的遍历 5.[掌握]数组在内存中的存储 6.[掌握]数组长度计算 ...
- 008-进制-C语言笔记
008-进制-C语言笔记 学习目标 1.[掌握]include预处理指令 2.[掌握]多文件开发 3.[了解]认识进制 4.[掌握]进制之间的互相转换 5.[掌握]原码,反码,补码 6.[掌握]位运算 ...
随机推荐
- Delphi 10.3.2最新消息
官方已经发布消息,招内测人员了! https://www.barnsten.com/default/newsupdates/details?news_id=328 https://docs.googl ...
- [BZOJ 4999]This Problem Is Too Simple!
[BZOJ 4999]This Problem Is Too Simple! 题目 给您一颗树,每个节点有个初始值. 现在支持以下两种操作: 1. C i x(0<=x<2^31) 表示将 ...
- 车展(vijos P1459)
描述 遥控车是在是太漂亮了,韵韵的好朋友都想来参观,所以游乐园决定举办m次车展.车库里共有n辆车,从左到右依次编号为1,2,…,n,每辆车都有一个展台.刚开始每个展台都有一个唯一的高度h[i].主管已 ...
- hdu_1020_Encoding_201310172120
Encoding Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total S ...
- pthread2
下面我们来看看这个demo #include <stdio.h> #include <pthread.h> #include <unistd.h> #include ...
- saprk里面的action - aggregate
上一篇讲到了spark里面的action函数: Action列表: reduce collect count first take takeSample takeOrdered saveAsTextF ...
- Codeforces Round #305 (Div. 2) E题(数论+容斥原理)
E. Mike and Foam time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- 获取url地址
用JS获取地址栏参数的方法(超级简单) 采用正则表达式获取地址栏参数:( 强烈推荐,既实用又方便!) function GetQueryString(name) { var reg = new Reg ...
- Django訪问量和页面PV数统计
http://blog.csdn.net/pipisorry/article/details/47396311 以下是在模板中做一个简单的页面PV数统计.model阅读量统计.用户訪问量统计的方法 简 ...
- iOS 9 平台上 AFNetworking 框架 3.0 版本号解决的问题和问题解决
iOS 9 平台上 AFNetworking 框架 3.0 版本号解决的问题和问题解决 太阳火神的漂亮人生 (http://blog.csdn.net/opengl_es) 本文遵循"署名- ...