win10 下的YOLOv3 训练 wider_face 数据集检测人脸
1、数据集下载
(1)wider_face 数据集网址为 http://shuoyang1213.me/WIDERFACE/index.html
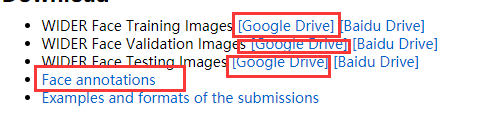
下载以上几项文件(这里推荐 google Drive 百度云在没有会员的情况下,下载太慢)
(2)将文件解压到各自独立的文件夹

2、数据集简介
WIDER FACE 数据集是一个人脸检测基准(benchmark)数据集,图片选取自 WIDER(Web Image Dataset for Event Recognition) 数据集。图片数 32,203 张,人脸数 393,703 个,在大小(scale)、位置(pose)、遮挡(occlusion)等不同形式中,人脸是高度变换的。WIDER FACE 数据集是基于61个事件类别,每个事件类别,随机选取训练40%、验证10%、测试50%。训练和测试含有边框(bounding box)真值(ground truth),而验证不含。
这里主要使用训练集和验证集,他们对应的标签文件分别为 wider_face_split/wider_face_train_bbx_gt.txt 和 wider_face_split/wider_face_val_bbx_gt.txt
在 wider_face_train_bbx_gt.txt 文件中
数据如下所示:
0--Parade/0_Parade_marchingband_1_849.jpg
1
449 330 122 149 0 0 0 0 0 0
第一行代表图片路径
第二行是图片中目标个数(人脸个数)
第三行是具体的图片中人脸标注的相关参数(具体含义可以在 readme.txt 中看到)
从左到右的含义分别是 x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
(1)x1, y1, w, h, 分别代表 左下点坐标 及宽长
(2)blur:模糊程度,0——> 清晰 ,1——> 一般模糊 , 2——> 严重模糊
(3)expression: 表情 0——> 正常 , 1——> 夸张
(4)illumination:光源(应该是曝光程度)0——> 正常 , 1——>极度
(5)occlusion:遮挡 0——> 没有遮挡 , 1——> 部分遮挡 , 2——> 严重遮挡
(6)pose: 姿势 0——> 正常姿势 , 1——非正常姿势
(7)invalid: 无效图片 0——否, 1——> 是
3、数据集转换
YOLO v3 需要的 标签格式为
0 0.498046875 0.292057761732852 0.119140625 0.1075812274368231 #type x y w h
从左到右的含义分别为 目标类型 (这里只有一种类型,所以都是0 ) 目标框中心点的(x,y)坐标 目标框的宽度和高度 (这里的数据都是单位数据 即 x—— 中心点实际x / 图片宽度 , y—— 中心点实际y / 图片高度)
这里可以直接把 wider_face 标签转成 yolo 标签,也可以先转成 voc 格式标签再转成 yolo 标签。考虑到官方有将VOC 格式转成 yolo 格式的代码 voc_label.py 于是先转成 VOC 格式 的标注
(1)转成VOC 格式
# -*- coding: utf-8 -*- import shutil
import random
import os
import string
from skimage import io headstr = """\
<annotation>
<folder>VOC2007</folder>
<filename>%06d.jpg</filename>
<source>
<database>My Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>company</name>
</owner>
<size>
<width>%d</width>
<height>%d</height>
<depth>%d</depth>
</size>
<segmented>0</segmented>
"""
objstr = """\
<object>
<name>%s</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>%d</xmin>
<ymin>%d</ymin>
<xmax>%d</xmax>
<ymax>%d</ymax>
</bndbox>
</object>
""" tailstr = '''\
</annotation>
''' def writexml(idx, head, bbxes, tail):
filename = ("Annotations/%06d.xml" % (idx))
f = open(filename, "w")
f.write(head)
for bbx in bbxes:
f.write(objstr % ('face', bbx[0], bbx[1], bbx[0] + bbx[2], bbx[1] + bbx[3]))
f.write(tail)
f.close() def clear_dir():
if shutil.os.path.exists(('Annotations')):
shutil.rmtree(('Annotations'))
if shutil.os.path.exists(('ImageSets')):
shutil.rmtree(('ImageSets'))
if shutil.os.path.exists(('JPEGImages')):
shutil.rmtree(('JPEGImages')) shutil.os.mkdir(('Annotations'))
shutil.os.makedirs(('ImageSets/Main'))
shutil.os.mkdir(('JPEGImages')) def excute_datasets(idx, datatype): f = open(('ImageSets/Main/' + datatype + '.txt'), 'a')
f_bbx = open(('wider_face_split/wider_face_' + datatype + '_bbx_gt.txt'), 'r') while True:
filename = f_bbx.readline().strip('\n') if not filename:
break im = io.imread(('WIDER_' + datatype + '/images/' + filename))
head = headstr % (idx, im.shape[1], im.shape[0], im.shape[2])
nums = f_bbx.readline().strip('\n')
bbxes = []
if nums=='':
bbx_info= f_bbx.readline()
continue
for ind in range(int(nums)):
bbx_info = f_bbx.readline().strip(' \n').split(' ')
bbx = [int(bbx_info[i]) for i in range(len(bbx_info))]
# x1, y1, w, h, blur, expression, illumination, invalid, occlusion, pose
if bbx[7] == 0:
bbxes.append(bbx)
writexml(idx, head, bbxes, tailstr)
shutil.copyfile(('WIDER_' + datatype + '/images/' + filename), ('JPEGImages/%06d.jpg' % (idx)))
f.write('%06d\n' % (idx))
idx += 1
f.close()
f_bbx.close()
return idx if __name__ == '__main__':
clear_dir()
idx = 1
idx = excute_datasets(idx, 'train')
idx = excute_datasets(idx, 'val')
print('Complete...')
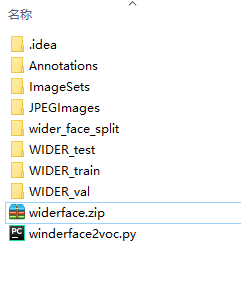
wider_face 转成VOC
目录格式为
(2)VOC 格式转成 yolo 需要的格式
将 上述步骤生成的 三个文件夹 即 Annotations ImageSets JPEGImages 放到之前编译好的 \darknet-master\build\darknet\x64\data\voc\VOCdevkit\VOCface 目录中
将voc_label.py 放入 \darknet-master\build\darknet\x64\data\voc\ 目录下
打开 voc_label.py 文件
将7 、8左右的代码改成如下所示:
# sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007_test', 'test')]#
sets=[('face', 'train'), ('face', 'val')]#
#
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
classes = ["face"]
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join # sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007_test', 'test')]#
sets=[('face', 'train'), ('face', 'val')]#
#
# classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"] classes = ["face"] def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h) def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text) for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') if __name__=='__main__':
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/' % (year)):
os.makedirs('VOCdevkit/VOC%s/labels/' % (year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
list_file = open('%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
VOC_label.py
运行 voc_label.py 结束后 将会在 voc 目录下生成 face_train.txt 和 face_val.txt
至此前期数据准备工作完成。
4、修改配置文件
(1)配置 cfg 文件
将 darknet-master\build\darknet\x64\cfg\yolov3.cfg 文件 复制一份 并重命名为 yolov3-obj.cfg
打开 yolov3-obj.cfg 将 第三行第四行注释掉 将第七行和第八行注释取消
将 batch 设为 batch=64 (第6行)
将 subdivisions 设为 subdivisions=8 (第7行)
如果显卡内存较小(即后面运行时报 out of memory 的错时) 可以 将 batch 改成 32 16 8 等 (保证 batch 是 subdivisions 的整数倍),同时取消多尺度训练 即 设置 random = 0 ( 第 615、701、788 行 )
将 max_batches 改为 max_batches = 2000 (第20行)max_batches 的数量为检测的目标数 * 2000
将 steps 改为 steps=1600,1800 (第22行)steps =max_batches *0.8 ,0.9
将 classes 改为 classes =1 (第 610 、696、783 行)
将 filters 改为 filters =18 (只改三个 yolo 层的上一层的 filters 即 第 603、689 、776 行 )
(2)配置 obj.data 和 obj.names 文件
可以 复制 voc.data 和obj.names 文件并重命名,也可以自己新建两个文件
obj.data 文件中 内容为
classes= 1
train = data/voc/face_train.txt
valid = data/voc/face_val.txt
#difficult = data/difficult_2007_test.txt
names = data/obj.names
backup = backup/
obj.names 的内容为 face (只有这一行)
face
(3)配置 \darknet-master\Makefile 文件 (在有 GPU 和 CUDNN 的情况下)
将第 1 行 GPU=0 改成 GPU=1
将第 2 行 CUDNN=0 改成 CUDNN=1
将第 58 行 改为 NVCC=C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.0/bin (自己的cuda 安装目录)
将 88 —— 108 行的内容改成如下所示 (即 将对应目录 改成)
ifeq ($(GPU), 1)
COMMON+= -DGPU -I/C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.0/include
CFLAGS+= -DGPU
ifeq ($(OS),Darwin) #MAC
LDFLAGS+= -L/usr/local/cuda/lib -lcuda -lcudart -lcublas -lcurand
else
LDFLAGS+= -L/C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.0/lib/x64 -lcuda -lcudart -lcublas -lcurand
endif
endif ifeq ($(CUDNN), 1)
COMMON+= -DCUDNN
ifeq ($(OS),Darwin) #MAC
CFLAGS+= -DCUDNN -I/usr/local/cuda/include
LDFLAGS+= -L/usr/local/cuda/lib -lcudnn
else
CFLAGS+= -DCUDNN -IC:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.0/include
LDFLAGS+= -L/C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v10.0/lib/x64 -lcudnn
endif
endif
(4)下载 预训练文件 https://pjreddie.com/media/files/darknet53.conv.74 放到 \darknet-master\build\darknet\x64 目录中
5、开始训练
在 \darknet-master\build\darknet\x64 目录下打开 powershell
运行命令 ./darknet.exe detector train data/obj.data cfg/yolov3-obj.cfg darknet53.conv.74 开始训练
如果报 CUDA Error: out of memory
则 将 batch 改成 32 16 8 等 (保证 batch 是 subdivisions 的整数倍),同时取消多尺度训练 即 设置 random = 0 ( 第 615、701、788 行 ) (我是都改成 8 才可以)
6、训练过程中的 输出参数解释

表示所有训练图片中的一个批次(batch),批次大小的划分根据在cfg/yolov3-obj.cfg中设定的, 批次大小的划分根据我们在 .cfg 文件中设置的subdivisions参数。在我使用的 .cfg 文件中 batch = 8 ,subdivision = 8,所以在训练输出中,训练迭代包含了8组(8组 Region 82, Region 94, Region 106),每组又包含了1张图片,跟设定的batch和subdivision的值一致。( 也就是说每轮迭代会从所有训练集里随机抽取 batch = 8 个样本参与训练,所有这些 batch 个样本又被均分为 subdivision = 8 次送入网络参与训练,以减轻内存占用的压力)
(1) Region 82 ,Region 94 , Region 106 代表三个 训练尺度 82 为最大尺度 用来预测较小目标, 106 为最小尺度 用来预测较大目标,94 为 中间尺度 在每个尺度 中的数据 会出现大量的 nan 数据 是正常现象,只有迭代的 avg loss 出现 nan 值才说明训练出错。
(2)Avg IOU:表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交并比 越接近1 越好
(3)Class:标注物体分类的正确率, 期望该值趋近于1;
(4)Obj:越接近 1 越好
(5)No Obj:越来越小,但不为 0
(6).5R:以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本
(7).75R: 以IOU=0.75为阈值时候的recall; recall = 检出的正样本/实际的正样本
(8)count:count后的值表示所有的当前subdivision图片(本例中一张)中包含正样本的图片的数量。
(9)最后一行
11:指当前训练的迭代次数
640.579651:总体的 loss
647.46337 avg loss :平均的loss 在这个数字到达 0.05-3 之间 可以停止训练(当该数字 变化趋于平稳,波动不大时停止 )
0.00000 rate: 代表当前的学习率,在.cfg文件中定义了它的初始值和调整策略。刚开始出现的值很有可能时 0 是正常情况
3.38700 seconds:当前批次的训练时间
88 images:代表已参与训练的图片的数量
7、训练完成与测试
本次训练用的是破显卡(750 ti),训练不到两小时就我就停下了 avg loss 在 3.8 左右,测试下训练效果
将cfg 文件的 batch 和 subdivisions 换成 1
打开 powershell
输入命令 ./darknet.exe detector test data/obj.data cfg/yolov3-obj.cfg backup/yolov3-obj_last.weights -i 0 -thresh 0.25
放几张从网上随便找的照片,测试结果。初步结果还可以
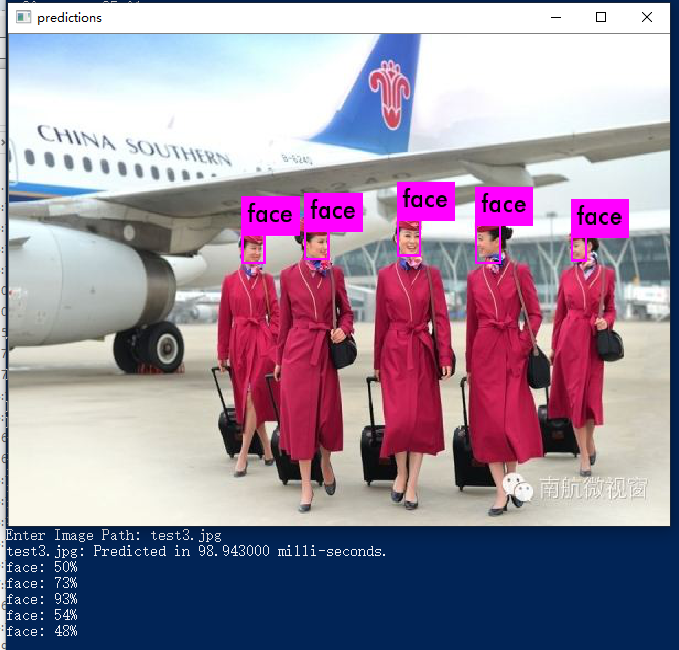
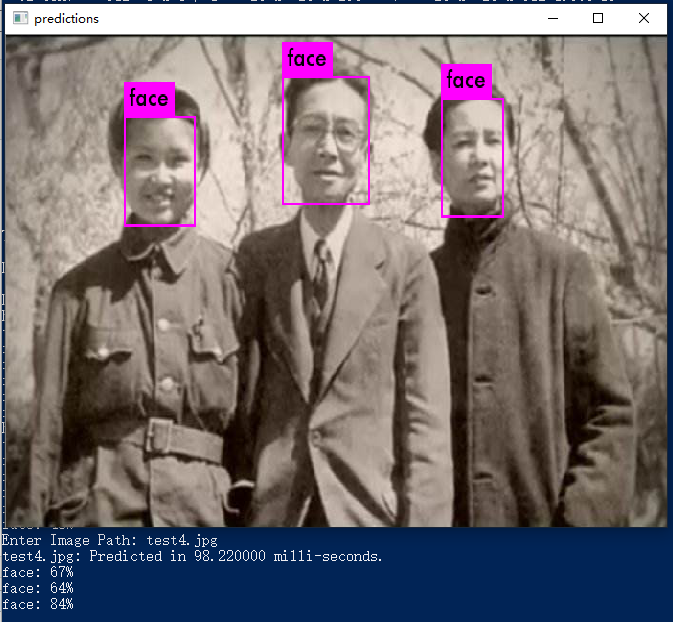

win10 下的YOLOv3 训练 wider_face 数据集检测人脸的更多相关文章
- pytorch版yolov3训练自己数据集
目录 1. 环境搭建 2. 数据集构建 3. 训练模型 4. 测试模型 5. 评估模型 6. 可视化 7. 高级进阶-网络结构更改 1. 环境搭建 将github库download下来. git cl ...
- Win10 + YOLOv3训练VOC数据集-----How to train Pascal VOC Data
How to train (Pascal VOC Data): Download pre-trained weights for the convolutional layers (154 MB): ...
- win10 caffe python Faster-RCNN训练自己数据集(转)
一.制作数据集 1. 关于训练的图片 不论你是网上找的图片或者你用别人的数据集,记住一点你的图片不能太小,width和height最好不要小于150.需要是jpeg的图片. 2.制作xml文件 1)L ...
- YOLOV3 训练WIDER_FACE
1. dowload the img and labels : http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/index.html 2.
- 目标检测算法SSD在window环境下GPU配置训练自己的数据集
由于最近想试一下牛掰的目标检测算法SSD.于是乎,自己做了几千张数据(实际只有几百张,利用数据扩充算法比如镜像,噪声,切割,旋转等扩充到了几千张,其实还是很不够).于是在网上找了相关的介绍,自己处理数 ...
- 第十一节,利用yolov3训练自己的数据集
1.环境配置 tensorflow1.12.0 Opencv3.4.2 keras pycharm 2.配置yolov3 下载yolov3代码:https://github.com/qqwweee/k ...
- win10 Faster-RCNN训练自己数据集遇到的问题集锦 (转)
题注: 在win10下训练实在是有太多坑了,在此感谢网上的前辈和大神,虽然有的还会把你引向另一个坑~~. 最近,用faster rcnn跑一些自己的数据,数据集为某遥感图像数据集——RSOD,标注格式 ...
- 如何使用yolov3训练自己的数据集
博客主要结构 1. 如何在ubuntu18.04上安装yolo 2 .如何配置yolov3 3 .如何制作自己的训练集测试集 4 .如何在自己的数据集上运行yolov3 1. 在ubuntu18.04 ...
- YOLOV4在linux下训练自己数据集(亲测成功)
最近推出了yolo-v4我也准备试着跑跑实验看看效果,看看大神的最新操作 这里不做打标签工作和配置cuda工作,需要的可以分别百度搜索 VOC格式数据集制作,cuda和cudnn配置 我们直接利用 ...
随机推荐
- 多线程编程 CreateThread(解释了TContext)
function CreateThread( lpThreadAttributes: Pointer; {安全设置} dwStackSize: DWORD; ...
- Session Redis Nginx
Session + Redis + Nginx 一.Session 1.Session 介绍 我相信,搞Web开发的对Session一定再熟悉不过了,所以我就简单的介绍一下. Session:在计算机 ...
- FZU Problem 2062 Suneast & Yayamao
http://acm.fzu.edu.cn/problem.php?pid=2062 标题效果: 给你一个数n,要求求出用多少个数字能够表示1~n的全部数. 思路: 分解为二进制. 对于一个数n.看它 ...
- Delphi 获取外部程序句柄与发送消息
--记录下来备以后用 [打开外部程序.消息.句柄],技术有限,希望不要误人子弟了. 源码unit Unit1; interface uses Windows, Messages, SysUtils, ...
- DDD实战3 领域层的设计
1.新建一个解决方案文件夹 取名Product 2.在Product解决方案文件夹下面创建一个.net core 类库项目 取名Product.Domain,引用项目DDD.Base项目 3.在类库下 ...
- Linux性能测试 tcpdump命令
用简单的话来定义tcpdump,就是:dump the traffic on a network,根据使用者的定义对网络上的数据包进行截获的包分析工具. tcpdump可以将网络中传送的数据包的“头” ...
- silverlight,WPF动画终极攻略之白云飘,坐车去旅游篇(Blend 4开发)
原文:silverlight,WPF动画终极攻略之白云飘,坐车去旅游篇(Blend 4开发) 这章有点长,所以我分成了两章.这一章主要是准备工作,差不多算美工篇吧,这章基本不会介绍多少动画效果,主要讲 ...
- DWZ使用注意事项
DWZ使用注意事项 一.前言 在最近的一个项目,介绍DWZ丰富client框架,可以尝试一下.另外,在遇到的很多问题.十一终于攻克. 特别说明本文的. 本人用的是dwz-ria-1.4 ...
- MQTT协议学习及实践(Linux服务端,Android客户端的例子)
前言 MQTT(Message Queuing Telemetry Transport),是一个物联网传输协议,它被设计用于轻量级的发布/订阅式消息传输,旨在为低带宽和不稳定的网络环境中的物联网设备提 ...
- WPF特效-绘图
原文:WPF特效-绘图 WPF玩起来还是挺炫酷的.我实现的效果:不同色块交叉,交叉部分颜色叠加显示.(叠加部分暂时用随机颜色代替).单独色块点击弹出以色块颜色为主的附 ...