大数据基础之Kafka(1)简介、安装及使用
kafka2.0

一 简介
Kafka® is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
Kafka常用来构建实时数据管道或者流式应用。它支持水平扩展,容错,并且异常的快,已经在数千家公司的生产环境中使用。written in Scala by LinkedIn
A streaming platform has three key capabilities:
- Publish and subscribe to streams of records, similar to a message queue or enterprise messaging system.
- Store streams of records in a fault-tolerant durable way.
- Process streams of records as they occur.
关键能力:发布订阅、消息存储、实时处理
First a few concepts:
- Kafka is run as a cluster on one or more servers that can span multiple datacenters.
- The Kafka cluster stores streams of records in categories called topics.
- Each record consists of a key, a value, and a timestamp.
Kafka以集群方式运行在一台或台个服务器上,Kafka中存储消息记录的分类叫做topics,每一个消息记录都包含key、value和timestamp。
1 传统MQ局限
Messaging traditionally has two models: queuing and publish-subscribe. In a queue, a pool of consumers may read from a server and each record goes to one of them; in publish-subscribe the record is broadcast to all consumers. Each of these two models has a strength and a weakness. The strength of queuing is that it allows you to divide up the processing of data over multiple consumer instances, which lets you scale your processing. Unfortunately, queues aren't multi-subscriber—once one process reads the data it's gone. Publish-subscribe allows you broadcast data to multiple processes, but has no way of scaling processing since every message goes to every subscriber.
传统消息队列有两种模型:队列 和 发布订阅;
在队列模型中,有很多消费者可以从一台服务器上读消息,并且每条消息只会被一个消费者处理;
在发布订阅模型中,每条消息都会被广播到所有的消费者;
两者各有利弊,队列模型的优点是允许你把消息处理并行分布到多个消费者中,可以提升消息处理速度;缺点是一旦有消费者读到一条消息,这条消息就消失了;发布订阅模型优点是允许你广播一条消息给多个消费者;缺点是无法并行处理消息;
后边可以看到,Kafka兼具这两种模型的优点;
A traditional queue retains records in-order on the server, and if multiple consumers consume from the queue then the server hands out records in the order they are stored. However, although the server hands out records in order, the records are delivered asynchronously to consumers, so they may arrive out of order on different consumers. This effectively means the ordering of the records is lost in the presence of parallel consumption. Messaging systems often work around this by having a notion of "exclusive consumer" that allows only one process to consume from a queue, but of course this means that there is no parallelism in processing.
传统消息队列在服务器端保持消息的顺序,如果有多个消费者同时从队列中消费消息,服务器会按照消息的顺序派发消息;尽管如此,由于消费者消费消息时是异步的,所以在消费的时候极有可能是乱序的;这表明消息的顺序在并行消息处理中丢失了;此时,通常的做法是只允许一个消费者来消费消息来保证消息被处理时的顺序性;
2 Role & API

Kafka has five core APIs:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics.
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them.
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams.
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table.
- The AdminClient API allows managing and inspecting topics, brokers, and other Kafka objects.
Kafka中最常用的是Producer API(发送消息)和Consumer API(消费消息),另外还有Streams API、Connector API、AdminClient API;
In Kafka the communication between the clients and the servers is done with a simple, high-performance, language agnostic TCP protocol. This protocol is versioned and maintains backwards compatibility with older version. We provide a Java client for Kafka, but clients are available in many languages.
3 Topic & Partition
A topic is a category or feed name to which records are published. Topics in Kafka are always multi-subscriber; that is, a topic can have zero, one, or many consumers that subscribe to the data written to it.
topic是指消息记录的类别,发送的消息需要指定一个topic,同时一个topic可以被多个消费者消费;
For each topic, the Kafka cluster maintains a partitioned log that looks like this:
每一个topic都有一个或多个partition,每个partition对应一个log文件

Each partition is an ordered, immutable sequence of records that is continually appended to—a structured commit log.
The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
每个partition由顺序的消息组成,这些消息会顺序追加到一个log文件中;partition中的每条消息都有一个顺序id称为offset,来唯一定义一个partition中的一条消息;
The Kafka cluster durably persists all published records—whether or not they have been consumed—using a configurable retention period.
For example, if the retention policy is set to two days, then for the two days after a record is published, it is available for consumption, after which it will be discarded to free up space. Kafka's performance is effectively constant with respect to data size so storing data for a long time is not a problem.
Kafka集群会持久化所有的消息(无论它们是否被消费过),另外有一个保留时间配置,当保留时间设置为2天,这时一个消息发布后2天内都可以被消费到,超过2天它会被丢弃来释放空间;所以Kafka的性能与数据大小无关,即使存储很长时间的数据也没问题;
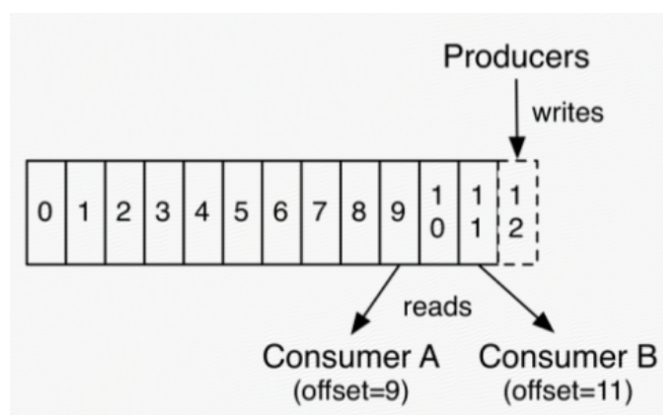
In fact, the only metadata retained on a per-consumer basis is the offset or position of that consumer in the log.
This offset is controlled by the consumer: normally a consumer will advance its offset linearly as it reads records, but, in fact, since the position is controlled by the consumer it can consume records in any order it likes.
For example a consumer can reset to an older offset to reprocess data from the past or skip ahead to the most recent record and start consuming from "now".
消费者端唯一的元数据就是目前消费到的每个partition的offset;offset是由消费者控制的,通常情况下一个消费者在它不断读消息的同时不断增加offset,一个消费者也可以通过修改offset来重新消费部分消息或者跳过部分消息;
The partitions in the log serve several purposes.
First, they allow the log to scale beyond a size that will fit on a single server.Each individual partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data.
Second they act as the unit of parallelism—more on that in a bit.
一个topic可以有多个partitions,这样有两个好处,一个是允许topic的数据量超过单机容量限制,一个是支持并发(包括发送和消费);
The partitions of the log are distributed over the servers in the Kafka cluster with each server handling data and requests for a share of the partitions.
Each partition is replicated across a configurable number of servers for fault tolerance.
partition分布在Kafka集群的所有服务器中的,每一台服务器都会处理一个或多个partition的请求,每个partition都会通过配置的数量进行服务器间备份来实现容错;
Each partition has one server which acts as the "leader" and zero or more servers which act as "followers".
The leader handles all read and write requests for the partition while the followers passively replicate the leader.
If the leader fails, one of the followers will automatically become the new leader. Each server acts as a leader for some of its partitions and a follower for others so load is well balanced within the cluster.
每个partition都有一个服务器称为leader,另外还有0个或多个服务器称为follower,这里的数量由副本数决定;
leader会处理该partition所有的读写请求,follower只是被动的同步leader的数据,如果leader挂了,其中一个follower会自动成为新的leader;
每个服务器都会作为一些partition的leader,同时也会作为另外一些partition的follower;
4 Producer & Consumer
Producers publish data to the topics of their choice. The producer is responsible for choosing which record to assign to which partition within the topic.
This can be done in a round-robin fashion simply to balance load or it can be done according to some semantic partition function (say based on some key in the record).
Consumers label themselves with a consumer group name, and each record published to a topic is delivered to one consumer instance within each subscribing consumer group.
Consumer instances can be in separate processes or on separate machines.
producer用来发送消息到topic,producer可以决定将消息发送到哪个partition,这里常用的是随机策略,另外也可以根据key来分区,即相同key的消息会被发送到一个partition;
consumer通过group来分组,topic里的每条消息只会被一个group中的一个consumer消费到;
If all the consumer instances have the same consumer group, then the records will effectively be load balanced over the consumer instances.
如果所有的consuemr都在一个group里,它们之间会自动做负载均衡;
If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumer processes.
如果所有consumer都在不同的group里,每条消息都会被广播到所有的consumer;
http://www.cnblogs.com/barneywill/p/9896945.html
大数据基础之Kafka(1)简介、安装及使用的更多相关文章
- 【原创】大数据基础之Kafka(1)简介、安装及使用
kafka2.0 http://kafka.apache.org 一 简介 Kafka® is used for building real-time data pipelines and strea ...
- 大数据系列之kafka监控kafkaoffsetmonitor安装
1.下载kafkaoffsetmonitor的jar包,可以到github搜索kafkaoffsetmonitor,第一个就是,里面可以下载编译好了的包. KafkaOffsetMonitor-ass ...
- 大数据基础环境--jdk1.8环境安装部署
1.环境说明 1.1.机器配置说明 本次集群环境为三台linux系统机器,具体信息如下: 主机名称 IP地址 操作系统 hadoop1 10.0.0.20 CentOS Linux release 7 ...
- CentOS6安装各种大数据软件 第八章:Hive安装和配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- 【原创】大数据基础之Zookeeper(2)源代码解析
核心枚举 public enum ServerState { LOOKING, FOLLOWING, LEADING, OBSERVING; } zookeeper服务器状态:刚启动LOOKING,f ...
- 【原创】大数据基础之Impala(1)简介、安装、使用
impala2.12 官方:http://impala.apache.org/ 一 简介 Apache Impala is the open source, native analytic datab ...
- 大数据平台搭建-kafka集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
随机推荐
- TEdit,TMemo背景透明(SetWindowLong(WS_EX_TRANSPARENT)增加透明风格)
The component below works perfectly, except for the following problem: 1) Saves the component below ...
- javascript对象属性为空的判断
zepto: $.isEmptyObject = function(obj) { var name for (name in obj) return false return true } $.isE ...
- TCL S960T刷机包 乐蛙OS5 稳定版 平滑 优化
ROM简介 乐蛙OS5完美的最终稳定版 Ver14.10.17 温馨提示:一定要明确系统双成一个完整的包画刷入前开发版,否则会造成系统异常,请务必备份手机刷机前的信息和数据,刷机过程中,为了避免因数据 ...
- iOS 注册或登录页面(UILable,UITextField,UIButton)
注册或登录页面 例如下面的附图 1,为了在这里展示UITextField文本框关联的键盘设置.在这里,"password"和"判定password"关联键盘被设 ...
- Java--基础命名空间和相关东西(JAVA工程师必须会,不然杀了祭天)
java.lang (提供利用 Java 编程语言进行程序设计的基础类)java.lang.annotation(提供了引用对象类,支持在某种程度上与垃圾回收器之间的交互)java.lang.inst ...
- MongoDB 通过自带工具命令进行备份表,再将备份表还原出数据
创建一个bat文件 在其中输入以下3行 第1行进入工具mongodump所在的目录 第2行 将Adam数据库里面的 第3行 将上面存在C:\Data\Dump\Adam\文件夹里面的TBLQuickS ...
- ASP.NET Core Identity 框架 - ASP.NET Core 基础教程 - 简单教程,简单编程
原文:ASP.NET Core Identity 框架 - ASP.NET Core 基础教程 - 简单教程,简单编程 ASP.NET Core Identity 框架 前面我们使用了 N 多个章节, ...
- ZOJ 3819 Average Score(数学 牡丹江游戏网站)
主题链接:problemId=5373">http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=5373 Bob is ...
- 莱杰:期刊进口流程(文件 ID 1591640.1)
文档内容 概要 _afrLoop=2068767096030752&id=1591640.1&_afrWindowMode=0&_adf.ctrl-state=qivv ...
- HDU4421 Bit Magic 【2-sat】
叙述性说明: 这给出了一个矩阵,原来的请求a排列 2-sat称号.对于每一位跑步边,跑31位可 详细的施工方 注意N=1的情况特判,还有检查对称元素是否同样 #include <stdio.h& ...