python下载网页转化成pdf
最近在学习一个网站补充一下cg基础。但是前几天网站突然访问不了了,同学推荐了waybackmachine这个网站,它定期的对网络上的页面进行缓存,但是好多图片刷不出来,很憋屈。于是网站恢复访问后决定把网页爬下来存成pdf。
两点收获:
1.下载网页时图片、css等文件也下载下来,并且修改html中的路径。
2. beautifulsoup、wkhtmltopdf很强大,用起来很舒心
前期准备工作:
0.安装python
1.安装pip
下载pip的安装包get-pip.py,下载地址:https://pip.pypa.io/en/latest/installing.html#id7
然后在get-pip.py所在的目录下运行get-pip.py
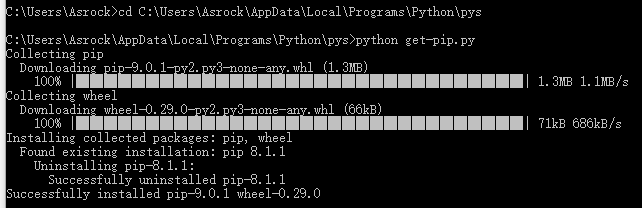
执行完成后,在python的安装目录下的Scripts子目录下,可以看到pip.exe
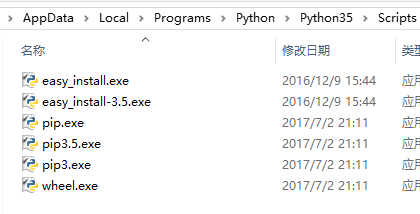
升级的话用 python -m pip install -U pip
2. 安装wkhtmltopdf : 适用于多平台的 html 到 pdf 的转换工具
3. install requests、beautifulsoup、pdfkit.
pdfkit 是 wkhtmltopdf 的Python封装包
beautifulsoup用于操纵html内容。
2.代码实现
from _ssl import PROTOCOL_TLSv1
from functools import wraps
import os
from ssl import SSLContext
import ssl
from test.test_tools import basepath
import urllib
from urllib.parse import urlparse # py3 from bs4 import BeautifulSoup
import requests
import urllib3 def sslwrap(func):
@wraps(func)
def bar(*args, **kw):
kw['ssl_version'] = ssl.PROTOCOL_TLSv1
return func(*args, **kw)
return bar def save(url,cls,outputDir,outputFile):
print("saving " + url);
response = urllib.request.urlopen(url,timeout=500)
soup = BeautifulSoup(response,"html5lib")
#set css
#save imgs #save html
if(os.path.exists(outputDir+outputFile)):
os.remove(outputDir+outputFile);
if(cls!=""):
body = soup.find_all(class_=cls)[0]
with open(outputDir+outputFile,'wb') as f:
f.write(str(body).encode(encoding='utf_8'))
else:
with open(outputDir+outputFile,'wb') as f:
f.write(str(soup.find_all("html")).encode(encoding='utf_8'))
print("finish!");
return soup; def crawl(base,outDir):
ssl._create_default_https_context = ssl._create_unverified_context
heads = save(base+"/index.php?redirect","central-column",outDir,"/head.html");
for link in heads.find_all('a'):
pos = str(link.get('href'))
if(pos.startswith('/lessons')==True):
curDir = outDir+pos;
if(os.path.exists(curDir)==False):
makedirs(curDir)
else:
print("already exist " + curDir);
continue
counter = 1;
while(True):
body = save(base+pos,"",curDir,"/"+str(counter)+".html")
counter+=1;
hasNext = False;
for div in body.find_all("div",class_="footer-prev-next-cell"):
if(div.get("style")=="text-align: right;"):
hrefs = div.find_all("a");
if(len(hrefs)>0):
hasNext = True;
pos = hrefs[0]['href'];
print(">>next is at:"+pos)
break;
if(hasNext==False):
break; if __name__ == '__main__':
crawl("https://www.***.com", "E:/Documents/CG/***");
print("finish")
python下载网页转化成pdf的更多相关文章
- Python下载网页的几种方法
get和post方式总结 get方式:以URL字串本身传递数据参数,在服务器端可以从'QUERY_STRING'这个变量中直接读取,效率较高,但缺乏安全性,也无法来处理复杂的数据(只能是字符串,比如在 ...
- 下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject. 这个需求是最近帮一个妹子处理一下各大高校网站里的 PDF 文档下载, ...
- python下载网页上公开数据集
URL很简单,数据集分散开在一个URL页面上,单个用手下载很慢,这样可以用python辅助下载: 问题:很多国外的数据集,收到网络波动的影响很大,最好可以添加一个如果失败就继续请求的逻辑,这里还没有实 ...
- python下载网页视频
因网站不同需要修改. 下载 mp4 连接 from bs4 import BeautifulSoup import requests import urllib import re import js ...
- python下载网页源码 写入文本
import urllib.request,io,os,sysreq=urllib.request.Request("http://echophp.sinaapp.com/uncategor ...
- Python下载网页图片
有时候不如不想输入路径,那就需要用os模块来修改当前路径 下面是从其他地方看到的一个例子,就是把图片url中的图片名字修改,然后就可以循环保存了,不过也是先确定了某个url 来源:http://www ...
- 使用python把html网页转成pdf文件
我们看到一些比较写的比较好文章或者博客的时候,想保存下来到本地当一个pdf文件,当做自己的知识储备,以后即使这个博客或者文章的连接不存在了,或者被删掉,咱们自己也还有. 当然咱们作为一个coder,这 ...
- Python入门小练习 002 批量下载网页链接中的图片
我们常常需要下载网页上很多喜欢的图片,但是面对几十甚至上百张的图片,一个一个去另存为肯定是个很差的体验. 我们可以用urllib包获取html的源码,再以正则表达式把匹配的图片链接放入一个list中, ...
- Python + Selenium +Chrome 批量下载网页代码修改【新手必学】
Python + Selenium +Chrome 批量下载网页代码修改主要修改以下代码可以调用 本地的 user-agent.txt 和 cookie.txt来达到在登陆状态下 批量打开并下载网页, ...
随机推荐
- PHP配置优化:php-fpm配置解读
PHP-FPM是一个PHP FastCGI管理器,php-fpm.conf配置文件用于控制PHP-FPM管理进程的相关参数,比如工作子进程的数量.运行权限.监听端口.慢请求等等. 我们在编译安装PHP ...
- redux原理
Redux实现原理 不同组件需要依赖同一个数据的时候,就需要状态提升至这些组件的根组件. redux是状态统一管理工具,需要使用它的原因是: 组件之间通信统一管理,方便代码维护. React中有一个特 ...
- DOM基础知识(概念、节点树、事件、Document)
1. DOM概念 全称为 Document Object Model,译为文档对象模型 D:文档 - DOM将HTML页面解析为一个文档 —> document对象 O:对象 - DOM将H ...
- 路飞学城Python-Day32
36-进程池线程池 开多线程实现并发的效率是高的,当用户没有那么多的时候,服务器是可以承受压力的 但是一定要以某种方式来设置并发数,让服务器能够实现稳定的运行,控制服务器的线程数 设置池,往里面放池的 ...
- [NOIP补坑计划]NOIP2016 题解&做题心得
感觉16年好难啊QAQ,两天的T2T3是不是都放反了啊…… 场上预计得分:100+80+100+100+65+100=545(省一分数线280) ps:loj没有部分分,部分分见洛咕 题解: D1T1 ...
- HDU 2604 Queuing( 递推关系 + 矩阵快速幂 )
链接:传送门 题意:一个队列是由字母 f 和 m 组成的,队列长度为 L,那么这个队列的排列数为 2^L 现在定义一个E-queue,即队列排列中是不含有 fmf or fff ,然后问长度为L的E- ...
- $attr和$listeners is readonly
https://www.jb51.net/article/132371.htm 出现这个问题的原因,主要是因为在使用的时候出现了A组件调用B组件,B组件再调用了C组件.而直接使用了A组件修改C组件的数 ...
- IT同行请教我如何培养读书习惯,结果就是“读了1本书,并写下'读《成交》有感'一文”
前段时间,我把CSDN博客的签名加上了"读过100+本经典书籍". 一个经常关注我CSDN博客的老乡,问我是如何做到的. 该老乡,准确来说是前辈,该前辈买了很多技术读物却没有耐心读 ...
- %02x与%2x之间的区别
输出最小宽度用十进制整数来表示输出的最少位数.若实际位数多于定义的宽度,则按实际位数输出,若实际位数少于定义的宽度则补以空格或0(当最小宽度数值以0开头时). X 表示以十六进制形式输出02表示不足两 ...
- react中的跨域问题
react中的跨域问题