Stacked Autoencoders
转自:http://www.cnblogs.com/tornadomeet/archive/2013/03/25/2980357.html
如果使用多层神经网络的话,那么将可以得到对输入更复杂的函数表示,因为神经网络的每一层都是上一层的非线性变换。当然,此时要求每一层的activation函数是非线性的,否则就没有必要用多层了。
Deep networks的优点:
一、比单层神经网络能学习到更复杂的表达。比如说用k层神经网络能学习到的函数(且每层网络节点个数时多项式的)如果要用k-1层神经网络来学习,则这k-1层神经网络节点的个数必须是指数级庞大的数字。
二、不同层的网络学习到的特征是由最底层到最高层慢慢上升的。比如在图像的学习中,第一个隐含层层网络可能学习的是边缘特征,第二隐含层就学习到的是轮廓什么的,后面的就会更高级有可能是图像目标中的一个部位,也就是是底层隐含层学习底层特征,高层隐含层学习高层特征。
三、这种多层神经网络的结构和人体大脑皮层的多层感知结构非常类似,所以说有一定的生物理论基础。
Deep networks的缺点:
一、网络的层次越深,所需的训练样本数越多,如果是用有监督学习的话,那么这些样本就更难获取,因为要进行各种标注。但是如果样本数太少的话,就很容易产生过拟合现象。
二、因为多层神经网络的参数优化问题是一个高阶非凸优化问题,这个问题通常收敛到一个比较差的局部解,普通的优化算法一般都效果不好。也就是说,参数的优化问题是个难点。
三、梯度扩散问题。因为当网络层次比较深时,在计算损失函数的偏导时一般需要使用BP算法,但是这些梯度值随着深度慢慢靠前而显著下降,这样导致前面的网络对最终的损失函数的贡献很小。这样的话前面的权值更新速度就非常非常慢了。一个理论上比较好的解决方法是将后面网络的结构的神经元的个数提高非常多,以至于它不会影响前面网络的结构的学习。但这样岂不是和低深度的网络结构一样了吗?所以不妥。
所以一般都是采用的层次贪婪训练方法来训练网络的参数,即先训练网络的第一个隐含层,然后接着训练第二个,第三个…最后用这些训练好的网络参数值作为整体网络参数的初始值。这样的好处是数据更容易获取,因为前面的网络层次基本都用无监督的方法获得,很容易,只有最后一个输出层需要有监督的数据。另外由于无监督学习其实隐形之中已经提供了一些输入数据的先验知识,所以此时的参数初始化值一般都能得到最终比较好的局部最优解
A stacked autoencoder is a neural network consisting of multiple layers of sparse autoencoders in which the outputs of each layer is wired to the inputs of the successive layer.
Formally, consider a stacked autoencoder with n layers. Using notation from the autoencoder section, let W(k,1),W(k,2),b(k,1),b(k,2) denote the parameters W(1),W(2),b(1),b(2) for kth autoencoder. Then the encoding step for the stacked autoencoder is given by running the encoding step of each layer in forward order:
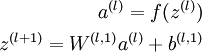
The decoding step is given by running the decoding stack of each autoencoder in reverse order:
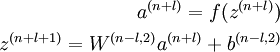
The information of interest is contained within a(n), which is the activation of the deepest layer of hidden units. This vector gives us a representation of the input in terms of higher-order features. —— 高层次特征
Training
A good way to obtain good parameters for a stacked autoencoder is to use greedy layer-wise training. To do this, first train the first layer on raw input to obtain parameters W(1,1),W(1,2),b(1,1),b(1,2). Use the first layer to transform the raw input into a vector consisting of activation of the hidden units, A. Train the second layer on this vector to obtain parametersW(2,1),W(2,2),b(2,1),b(2,2). Repeat for subsequent layers, using the output of each layer as input for the subsequent layer.
This method trains the parameters of each layer individually while freezing parameters for the remainder of the model. To produce better results, after this phase of training is complete,fine-tuning using backpropagation can be used to improve the results by tuning the parameters of all layers are changed at the same time.
Example
To give a concrete example, suppose you wished to train a stacked autoencoder with 2 hidden layers for classification of MNIST digits
First, you would train a sparse autoencoder on the raw inputs x(k) to learn primary features h(1)(k) on the raw input.
Next, you would feed the raw input into this trained sparse autoencoder, obtaining the primary feature activations h(1)(k)for each of the inputs x(k). You would then use these primary features as the "raw input" to another sparse autoencoder to learn secondary features h(2)(k) on these primary features.
Following this, you would feed the primary features into the second sparse autoencoder to obtain the secondary feature activations h(2)(k) for each of the primary features h(1)(k) (which correspond to the primary features of the corresponding inputs x(k)). You would then treat these secondary features as "raw input" to a softmax classifier, training it to map secondary features to digit labels.
Finally, you would combine all three layers together to form a stacked autoencoder with 2 hidden layers and a final softmax classifier layer capable of classifying the MNIST digits as desired.
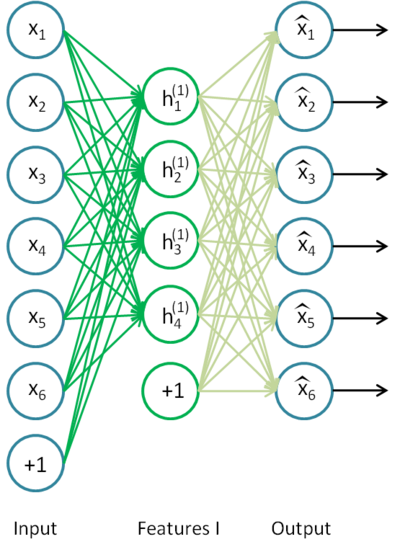
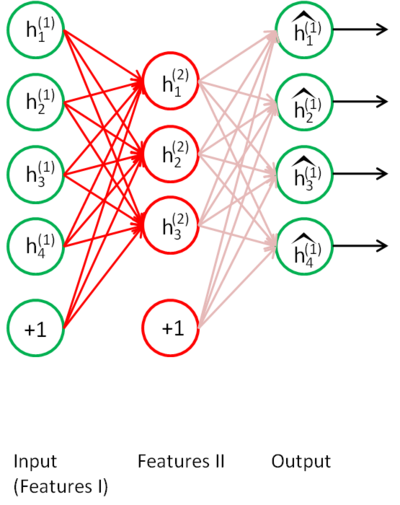
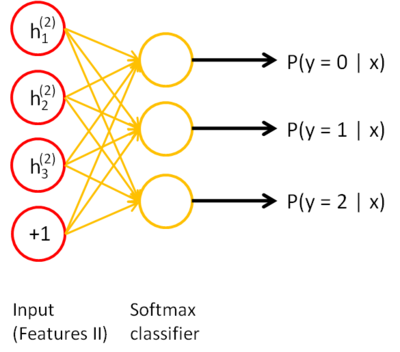
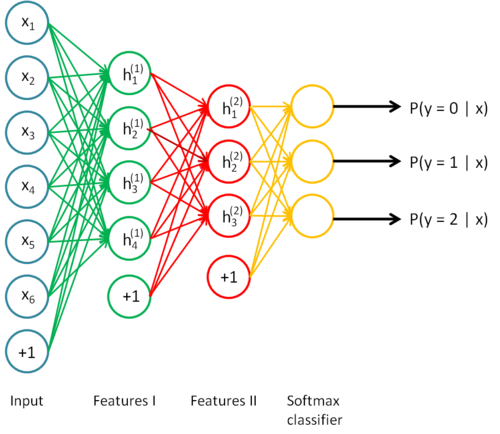
由此,层层深入,从发掘简单特征到发掘复杂特征,识别~~
Stacked Autoencoders的更多相关文章
- 论文翻译:2018_Artificial Bandwidth Extension with Memory Inclusion using Semi-supervised Stacked Auto-encoders
论文地址:使用半监督堆栈式自动编码器实现包含记忆的人工带宽扩展 作者:Pramod Bachhav, Massimiliano Todisco and Nicholas Evans 博客作者:凌逆战 ...
- 第十五章——自编码器(Autoencoders)
自编码器是一种能够通过无监督学习,学到输入数据高效表示的人工神经网络.输入数据的这一高效表示称为编码(codings),其维度一般远小于输入数据,使得自编码器可用于降维(查看第八章).更重要的是,自编 ...
- matlab 实现 stacked Autoencoder 解决图像分类问题
Train Stacked Autoencoders for Image Classification 1. 加载数据到内存 [train_x, train_y] = digitTrainCellAr ...
- NLP&数据挖掘基础知识
Basis(基础): SSE(Sum of Squared Error, 平方误差和) SAE(Sum of Absolute Error, 绝对误差和) SRE(Sum of Relative Er ...
- [Machine Learning] 机器学习常见算法分类汇总
声明:本篇博文根据http://www.ctocio.com/hotnews/15919.html整理,原作者张萌,尊重原创. 机器学习无疑是当前数据分析领域的一个热点内容.很多人在平时的工作中都或多 ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Top Deep Learning Projects in github
Top Deep Learning Projects A list of popular github projects related to deep learning (ranked by sta ...
- FAQ: Machine Learning: What and How
What: 就是将统计学算法作为理论,计算机作为工具,解决问题.statistic Algorithm. How: 如何成为菜鸟一枚? http://www.quora.com/How-can-a-b ...
- paper 53 :深度学习(转载)
转载来源:http://blog.csdn.net/fengbingchun/article/details/50087005 这篇文章主要是为了对深度学习(DeepLearning)有个初步了解,算 ...
随机推荐
- [UVa11549]Calculator Conundrum
题目大意:有一个只能显示n位数字的计算器,当溢出时只显示最高的n位. 输入k,要你不断平方,问你计算器显示的最大数是多少. 解题思路:这题的示数肯定会循环,那么我们关键就是找什么时候循环了. 可以用F ...
- 移动端(手机端)页面自适应解决方案—rem布局篇
移动端(手机端)页面自适应解决方案-rem布局 假设设计妹妹给我们的设计稿尺寸为750 * 1340.结合网易.淘宝移动端首页html元素上的动态font-size属性.设计稿尺寸.前端与设计之间协作 ...
- 介绍静态链接库和动态链接库的差别,及在VC++6.0中的建立和使用
首先介绍一下链接库:链接库分为动态链接库和静态链接库两种 LIB是静态链接库,在程序编译连接的时候是静态链接,其相应的文件格式是.lib. 即当程序採用静态链接库的时候..lib文件里的函数被链接到终 ...
- thinkphp里面使用原生php
thinkphp里面使用原生php Php代码可以和标签在模板文件中混合使用,可以在模板文件里面书写任意的PHP语句代码 ,包括下面两种方式: 使用php标签 例如: {php}echo 'Hello ...
- Python(十) 函数式编程: 匿名函数、高阶函数、装饰器
一.lambda表达式 lambda parameter_list: expression # 匿名函数 def add(x,y): return x+y print(add(1,2)) f = la ...
- linux和Windows双系统让 Windows 把硬件时间当作 UTC
linux和Windows双系统让 Windows 把硬件时间当作 UTC Windows设置如下:开 始->运行->CMD,打开命令行程序(Vista则要以管理员方式打开命令行程序方可有 ...
- JS构造函数、对象工厂、原型模式
1.对象创建的3中方法 1.1.对象字面量 var obj = { name: "mingzi", work: function () { console.log("wo ...
- angularCli打包遇到的一些问题
有时在运行项目或者打包项目的时候会遇到报错信息:found version 4, expected 3, 这个大概意思是说该插件需要的依赖当前不支持,需要提高依赖的版本. 比如:@angular/co ...
- vim7.4官方源码在vs2013的编译方法及问题总结
vim7.4发布也有一段时候了,也该是把之前编译的7.3重新编译一下了,于是考虑着到最新的visual studio 2013编译一下,也顺便看看有没有其它问题. 1.安装vs2013,这个应该不用说 ...
- PHP获取上周五时间简单写法
1.echo date('Y-m-d',strtotime('last friday')); 2.echo date("Y-m-d H:i:s",mktime(0, 0 , 0,d ...