python_way ,day5 模块,模块3 ,双层装饰器,字符串格式化,生成器,递归,模块倒入,第三方模块倒入,序列化反序列化,日志处理
python_way.day5
1、模块3
time,datetime, json,pickle
2、双层装饰器
3、字符串格式化
4、生成器
5、递归
6、模块倒入
7、第三方模块倒入
8、序列化反序列化
9、日志处理
1、模块
1、time
time:
time.time()
1465120729.18217 1987.1.1 0:0分 开始以秒计时 time.ctime()
Mon Jun 6 22:56:53 2016 当前系统时间
time.ctime(time.time()-86400)
Sun Jun 5 22:58:27 2016 | Mon Jun 6 22:58:27 2016 ctime模块支持传入参数,传入一个减去一天的秒数,获得的就是昨天的日期时间
time.gmtime(time.time()-86640) gmtime 得到的是utc时间
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=5, tm_hour=14, tm_min=56, tm_sec=53, tm_wday=6, tm_yday=157, tm_isdst=0)
#将时间戳转换为struct 模式 ,也支持传值 #作用是可以拿到里面每一个值
time_obj = time.gmtime()
print(time.obj.tm_mon,tome.obj.tm_yday)
6 157
time.localtime(time.time()-86400) #这个得到的 是本地时间,也可以加方法
#得到的也是一个 struct 对象
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=6, tm_hour=23, tm_min=11, tm_sec=41, tm_wday=0, tm_yday=158, tm_isdst=0) time.mktime(time.localtime()) #将struct_time 模块转变成时间戳
time.strftime("%Y-%m-%d %H:%M:%S",time.localtime()/time.gmtime) #将struct 转换成自定义格式
time.strptime("2016-01-28","%Y-%m-%d") #将2016-01-28 转换成 struct模式
time.struct_time(tm_year=2016, tm_mon=1, tm_mday=28, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=28, tm_isdst=-1)
time.strptime("2016-01-28 15:06","%Y-%m-%d %H:%M")
time.struct_time(tm_year=2016, tm_mon=1, tm_mday=28, tm_hour=23, tm_min=36, tm_sec=0, tm_wday=3, tm_yday=28, tm_isdst=-1)
需求:将字符串格式的时间转换成时间戳:
2015-06-06 05:23:40 转为1348129312.12 这种时间戳
a = time.strptime("2016-06-06 23:47:60","%Y-%m-%d %H:%M:%S")
b = time.mktime(a)
· 1465228080.0
time.sleep(4) #使程序睡眠4秒钟,可使用程序的阻塞 datetime: datetime.date.today() #显示当前的日期
2016-06-07
datetime.date.fromtimestamp(time.time()-864400) #将时间戳转换成日期格式,并且可以再time的时间戳出进行计算
2016-05-28
current_time = datetime.datetime.now() #返回当前时间以
print(current_time)
2016-06-20 13:30:25.719642
print(current_time.timetuple()) #将当前时间转换为struct_time 格式
time.struct_time(tm_year=2016, tm_mon=6, tm_mday=20, tm_hour=13, tm_min=31, tm_sec=52, tm_wday=0, tm_yday=172, tm_isdst=-1)
str_to_date = datetime.datetime.strptime("20/06/16 16:30","%d/%m/%y %H:%M") #将字符串转换成日期格式
print(str_to_date)
2016-06-20 16:30:00
时间的加减
new_date = datetime.timedelta(days=10)
print(new_date)
10 days, 0:00:00
new_date = datetime.datetime.now() + datetime.timedelta(days=10) #比现在的时间多10天
print(new_date)
2016-06-21 15:00:17.295504
new_date = datetime.datetime.now() + datetime.timedelta(hours=1) #比现在多一小时
print(new_date)
2016-06-20 16:00:17.295504
new_date = datetime.datetime.now() + datetime.timedelta(seconds=1) #比现在多一120s
print(new_date)
2016-06-20 16:00:17.295504
new_date = datetime.datetime.now()
a = new_date.replace(year=2016,month=9, day=22) + datetime.timedelta(days=20) #把当前你时间datetime.datetime.now() 替换成 2016-9-22日,然后在往后加20天
print(a)
2016-10-12 14:34:46.644348
time模块常用取时间戳,datetime取日期
2、json
特点:支持python基本数据类型,list dict tuple set str int float True Fales
可以再跨语言,跨平台进行数据的传输交互
json.dumps #将python的基本类型转换成字符串 import json li = [12,33,22]
r = json.dumps(li)
print(r,type(r))
[12, 33, 22] <class 'str'>
json.loads #将字符串形式的列表反序列化成为python的基本数据类型 反序列化时 [] 里面要用 “” 双引号,这样在跨语言传输时才不会出错 r_li = json.loads(r)
print(r_li,type(r_li))
[12, 33, 22] <class 'list'> json.dump #将字符串进行序列化后再存入文件
li = [12,33,22]
json.dump(li,open("json.db","w")) json.load #读取文件中序列化
r = json.load(open("json.db",'r'))
print(r)
[12, 33, 22]
3、pickle
特点,pickle序列化只能python自己使用,但是pickle可以支持任何数据类型
可以对python所有类型做操作,比如可以存储类,函数
在python版本不同可能pickle反序列化失败
import pickle
pickle.dumps #将字符串序列化后存入内存 li = [11,22,33] r = pickle.dumps(li)
print(r)
b'\x80\x03]q\x00(K\x0bK\x16K!e.'
pickle.loads #读取序列化后的内容
a = pickle.loads(r)
print(a)
[11, 22, 33] #就是原来的列表
pickle.dump #系列化后存入文件
li = [11,22,33]
pickle.dump(li,open("db","wb"))
pickle.load #读取文件中的序列化字符串
a = pickle.load(open("db","rb"))
print(a)
[11, 22, 33]
4、requests
获取页面信息的
r = requests.get("http://wthrcdn.etouch.cn/weather_mini?city=北京")
r.encoding = "utf-8"
print(r.text)
拿到的r.text 就是json字符串格式
就可以对json后的dict进行处理了。
2、双层装饰器
更牛逼的装饰器
http://www.cnblogs.com/wupeiqi/articles/4980620.html
3、字符串格式化
format & %
特点:占位符填充任何字符,%,可以居中,#可以显示出来二进制 十进制的标志位
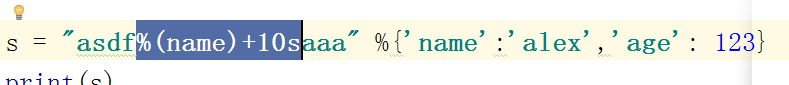
1、 s2 = "------{name:*^30,d}========".format(name=12344321)
-----**********12,344,321**********========
2、 s2 = "------{test:#b}========".format(test=123) #将10进制转换成2进制 #就是在二进制数字前面加上0b标志
------0b========
3、s2 = "------{test:.2%}========".format(test=0.123)
------12.30%========
填充:只能用一个字符填充
^:内容靠中间对其
<:内容左对齐
>:内容右对齐
=:内容右对齐,将符号放置在填充字符的左侧,且只能对数字类型有效。即:符号+填充物+数字
sign:有无符号
+:正好加正,符号加负
—:正好不变,符号加负
空格,正好空格,负号加负
#:对于二进制,八进制,十六进制 如果加上#,会显示 0b/0o/0x,否则不显示
,: 位数字添加分隔符
.precison : 小数保留精度
type 格式化类型

format支持直接传入一个列表
a = ["han",123]
s2 = "my name is {} my age is {} ".format(*a)
my name is han my age is 123
a = ["han","shi"]
b = ["28",""]
s2 = "my name is {0[]} my age is {1[]} ".format(a,b) my name is shi my age is 31
format还支持传入一个字典
c={"name":"han","age":123}
s2 = "my name is {name} my age is {age} ".format(**c)
my name is han my age is 123
4、生成器
li = [11,22,33,44]
result = filter(lambda x : x>22,li)
result 的结果再2.7中直接是一个列表,但是在3.0中是一个可迭代的对象
还有
range(10) 直接生成 [0,1,2,3,4,5,6,7,8,9]
a = xrange(10) a 是一个课得迭代对象
上面两个例子有什么区别?
直接生成所有数字的会占用大量内存,但是生成一个可迭代对象的占用的很小,在你需要他的时候去循环遍历它就可以了
生成器是使用函数创造的
普通函数:
def fun():
return 123
ret = func()
具有生成能力的函数
def func():
print("start")
yield 1
yield 2
yield3
func() 此时却不执行
此时func是一个对象
a = func()
print(a,type(a))
<generator object f1 at 0x000000DF258F1A40> <class 'generator'>
是一个生成器对象
for i in a:
print(i)
start
1
2
3
过程:在for的时候每次都会进入这个函数里面去取yiled后面的值,并且赋值给for的参数,下次循环再到函数中找到上次的位置向下再找一个yield。
r1 = a.__next__() ,进入函数中找到yield,获取yield后面的数据 ,并且出来
print(r1)
def f1():
print(111)
yield 1
print(222)
yield 2
print(333)
yield 3
a = f1()
a1 = a.__next__()
print(a1)
a2 = a.__next__()
print(a2)
a3 = a.__next__()
print(a3) 111
1
222
2
333
3
#每次__next__时都会去f1函数中执行里面的操作,并去找yield后面的值,一旦遇到yield就会取到后面的值退出,
yield __next__ 生成器原理
9、日志处理:
import logging
logging.warning("user[xxx]attempted wrong password more than 3 time")
logging.critical("server is down")
这样就把 warning 和 critical中的信息输出到了屏幕上
WARNING:root:user[xxx]attempted wrong password more than 3 time
CRITICAL:root:server is down
但是info debug都不能输出
默认是用管理员权限输出的日志
日志级别:
DEBUG
INFO
WARNING
ERROR
CRITICAL 如果想把日志输出到文件中
import logging
logging.basicConfig(filename='test.log',level=logging.INFO)
注册日志的格式,等级,日志名称(也可以设置时间,一会再说) logging.debug("debuy")
logging.info("info")
logging.warning("wraning")
这样输出的日志的等级就要在info以上,所以此时的debug不会输出
此时日志输入没有日期。
怎么加日期哪??
logging.basicConfig(filename='test.log',level=logging.INFO,format='%(asctime)s %(name)s %(message)s',datefmt='%m-%d-%Y %I:%M:%S %p')
#这样就把更多的信息注册到了basicconfig中了
#filename = 定义日志输出到日志中,如果没有这个就会把日志输出到屏幕上。
level = 设置日志输出的等级
format = 设置日志输出内容的格式 asctime 时间的占位符 name用户名的占位符 message 信息的占位符
datefmt = format中asctime时间输入的格式 %H:24小时制 %I:8小时制 logging.debug("==debuy==")
logging.info("==info==")
logging.warning("==wraning==")
06-11-2016 10:39:31 AM root ==info==
06-11-2016 10:39:31 AM root ==wraning==
format中的参数:
%(name)s Name of the logger (logging channel)
%(levelno)s Numeric logging level for the message (DEBUG, INFO,
WARNING, ERROR, CRITICAL)
%(levelname)s Text logging level for the message ("DEBUG", "INFO",
"WARNING", "ERROR", "CRITICAL")
%(pathname)s Full pathname of the source file where the logging
call was issued (if available)
%(filename)s Filename portion of pathname
%(module)s Module (name portion of filename)
%(lineno)d Source line number where the logging call was issued
(if available)
%(funcName)s Function name
%(created)f Time when the LogRecord was created (time.time()
return value)
%(asctime)s Textual time when the LogRecord was created
%(msecs)d Millisecond portion of the creation time
%(relativeCreated)d Time in milliseconds when the LogRecord was created,
relative to the time the logging module was loaded
(typically at application startup time)
%(thread)d Thread ID (if available)
%(threadName)s Thread name (if available)
%(process)d Process ID (if available)
%(message)s The result of record.getMessage(), computed just as
the record is emitted
混合模式,既输出到屏幕上,又放到文件中
log模块中包含了:loggers , handlers,filters,formatters
loggers,是应用程序直接调用的
handlers:把日志发送到不同的地方
filters:过滤 提供了一些日志过滤的功能(日志中包括了什么特殊字符,就把日志输出出来)
formatters: 格式化输出
import logging
#create logger
logger = logging.getLogger('TEST-LOG')
#指定谁发的日志,默认是root的位置
#先获取到logger对象
logger.setLevel(logging.DEBUG)
#设置全局的日志级别
# create console handler and set level to debug
#把设置好的等级和位置就可以注册给后面的 handler 了
ch = logging.StreamHandler()
#StreamHandler把日志打印到屏幕,如果想往屏幕输出,
ch.setLevel(logging.DEBUG)
#设置往屏幕输入时候的级别
# create file handler and set level to warning
#往文件中输出
fh = logging.FileHandler("access.log",encoding="utf-8")
fh.setLevel(logging.WARNING)
#设置往文件中输出的等级
# create formatter
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
#设置输出的格式
# add formatter to ch and fh
#定义往屏幕输出的格式
ch.setFormatter(formatter)
#定义往问价你输出的格式
fh.setFormatter(formatter)
# add ch and fh to logger
logger.addHandler(ch)
#将往屏幕输出的格式赋值给logger
logger.addHandler(fh)
#将往文件输出的格式赋值给logger
# 'application' code
logger.debug('debug message')
logger.info('info message')
logger.warn('warn message')
logger.error('error message')
logger.critical('critical message')
全局日志级别和局部日志级别这两个级别以全局日志为底线,局部的日志日志级别不能低于全局。
python_way ,day5 模块,模块3 ,双层装饰器,字符串格式化,生成器,递归,模块倒入,第三方模块倒入,序列化反序列化,日志处理的更多相关文章
- python-学习笔记之-Day5 双层装饰器 字符串格式化 python模块 递归 生成器 迭代器 序列化
1.双层装饰器 #!/usr/bin/env python # -*- coding: utf-8 -*- # author:zml LOGIN_INFO = False IS_ADMIN = Fal ...
- python- 双层装饰器 字符串格式化 python模块 递归 生成器 迭代器 序列化
1.双层装饰器 #!/usr/bin/env python3 # -*- coding: utf-8 -*- # author:zml LOGIN_INFO = False IS_ADMIN = Fa ...
- 第四天 内置函数2 随机码 装饰器 迭代器、生成器 递归 冒泡算法 JSON
关于函数的return li = [11,22,33,44] def f1(arg): arg.append(55) li = f1(li) print(li) 因为li = f1(li) 实际赋值的 ...
- 模块调用,datetime,time,logging,递归,双层装饰器, json,pickle迭代器和生成器
一.python模块(导入,内置,自定义,开源) 1.模块简介 模块是一个包含所有你定义的函数和变量的文件,其后缀名是.py.模块可以被别的程序引入,以使用该模块中的函数等功能.这也是使用python ...
- Day5 双层装饰器、字符串格式化、生成器、迭代器、递归
双层装饰器实现用户登录和权限认证 #!/usr/bin/env python# -*- coding: utf-8 -*-# Author: WangHuafeng USER_INFO = {} de ...
- Python装饰器、迭代器&生成器、re正则表达式、字符串格式化
Python装饰器.迭代器&生成器.re正则表达式.字符串格式化 本章内容: 装饰器 迭代器 & 生成器 re 正则表达式 字符串格式化 装饰器 装饰器是一个很著名的设计模式,经常被用 ...
- Python(四)装饰器、迭代器&生成器、re正则表达式、字符串格式化
本章内容: 装饰器 迭代器 & 生成器 re 正则表达式 字符串格式化 装饰器 装饰器是一个很著名的设计模式,经常被用于有切面需求的场景,较为经典的有插入日志.性能测试.事务处理等.装饰器是解 ...
- s14 第4天 关于python3.0编码 函数式编程 装饰器 列表生成式 生成器 内置方法
python3 编码默认为unicode,unicode和utf-8都是默认支持中文的. 如果要python3的编码改为utf-8,则或者在一开始就声明全局使用utf-8 #_*_coding:utf ...
- Python学习基础(三)——装饰器,列表生成器,斐波那契数列
装饰器——闭包 # 装饰器 闭包 ''' 如果一个内部函数对外部(非全局)的变量进行了引用,那么内部函数被认为是闭包 闭包 = 函数块 + 定义时的函数环境 ''' def f(): x = 100 ...
随机推荐
- 为 Macbook 增加锁屏热键技巧
第一步,找到“系统偏好设置”下的“安全性与隐私”,在“通用”页里勾上“进入睡眠或开始屏幕保护程序后立即要求输入密码”. 第二步,要用快捷键启动屏幕保护程序,相对复杂一点.在“应用程序”里找到“Auto ...
- 160912、工具类:spring+springmvc自定义编码转换
一.自定义的类(注意其中的属性,web.xml中的配置就是根据这个类的) import org.springframework.web.filter.OncePerRequestFilter; imp ...
- JProfiler入门笔记
看链接:http://blog.csdn.net/chendc201/article/details/22897999 收集一下.
- Spring的javaMail邮件发送(带附件)
项目中经常用到邮件功能,在这里简单的做一下笔记,方便日后温习. 首先需要在配置文件jdbc.properties添加: #------------ Mail ------------ mail.smt ...
- linux下xargs命令用法详解 【转】
转自:http://blog.chinaunix.net/uid-128922-id-289992.html xargs在linux中是个很有用的命令,它经常和其他命令组合起来使用,非常的灵活. xa ...
- ant 使用指南---java模块化编译【转】
转自:http://www.cnblogs.com/hoojo/archive/2013/06/14/java_ant_project_target_task_run.html 一.概述 ant 是一 ...
- Verilog HDL基础语法讲解之模块代码基本结构
Verilog HDL基础语法讲解之模块代码基本结构 本章主要讲解Verilog基础语法的内容,文章以一个最简单的例子"二选一多路器"来引入一个最简单的Verilog设计文件的 ...
- for DEMO
举例一: [xiluhua@vm-xiluhua][~/shell_script]$ cat forDemo1.sh #======================================== ...
- editPlus,3.7V 注册码
editPlus,3.7V 注册码: username:linzhihui password:5A2B6-69740-D9CDE-79702-C9CCD
- C#:简单线程样例
1.定义线程类及内部事件 using System; using System.Collections.Generic; using System.Text; using System.Threadi ...