awk笔记
http://www.cnblogs.com/zhuyp1015/archive/2012/07/14/2591842.html awk实例练习
http://www.cnblogs.com/repository/archive/2011/05/13/2045927.html
awk是一种功能强大的文本操作和模式匹配语言
与 Perl(它起源于 AWK)一样,AWK 是一种解释性语言,所以 AWK 程序通常不需要进行编译。相反,在运行时将程序脚本传递给 AWK 解释器。
解释型语言:bash,awk,perl,php,python
调用方式
语法构成
模式样例
动作样例
复合样例
变量
函数 http://www.cnblogs.com/chengmo/archive/2010/10/08/1845913.html
数组
流控语句
具体应用
简介
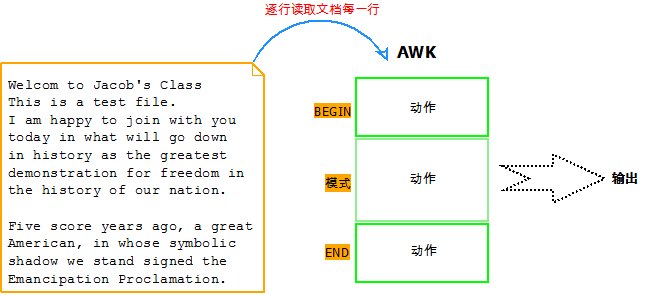
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。
awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母。实际上 AWK 的确拥有自己的语言: AWK 程序设计语言 , 三位创建者已将它正式定义为“样式扫描和处理语言”。它允许您创建简短的程序,这些程序读取输入文件、为数据排序、处理数据、对输入执行计算以及生成报 表,还有无数其他的功能。
使用方法
awk '{pattern + action}' {filenames}
尽管操作可能会很复杂,但语法总是这样,其中 pattern 表示 AWK 在数据中查找的内容,而 action 是在找到匹配内容时所执行的一系列命令。花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组。 pattern就是要表示的正则表达式,用斜杠括起来。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。
通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域
三种awk调用方式
1.命令行方式
awk [-F field-separator] 'commands' input-file(s)
其中,commands 是真正awk命令,[-F域分隔符]是可选的。 input-file(s) 是待处理的文件。
在awk中,文件的每一行中,由域分隔符分开的每一项称为一个域。通常,在不指名-F域分隔符的情况下,默认的域分隔符是空格。
2.shell脚本方式
将所有的awk命令插入一个文件,并使awk程序可执行,然后awk命令解释器作为脚本的首行,一遍通过键入脚本名称来调用。
相当于shell脚本首行的:#!/bin/sh
可以换成:#!/bin/awk
3.将所有的awk命令插入一个单独文件,然后调用:
awk -f awk-script-file input-file(s)
其中,-f选项加载awk-script-file中的awk脚本,input-file(s)跟上面的是一样的。
ifconfig|awk '/RX/{print $3}' 这种是awk+pattern+action的使用示例。
ifconfig|awk '/RX/ {print $3}' 空格可有可无,有的话看起来清楚一点。
awk -F: '/^root/' /etc/passwd 这种是awk+pattern的使用示例,匹配了pattern(这里是root)的行才会执行action(没有指定action,默认输出每行的内容)。
cat /etc/passwd |awk -F ':' '{print $3}' 这种是awk+action的示例,每行都会执行action{print $1}。
cat /etc/passwd |awk -F ':' '{print $1"\t"$7}' 输出以tab分隔
cat /etc/passwd |awk -F ':' 'BEGIN {print "name,shell"} {print $1","$7} END {print "blue,/bin/nosh"}' 头加一行,尾加一行,输出以逗号分隔
awk内置变量
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。
此外,$0变量是指整条记录。$1表示当前行的第一个域,$2表示当前行的第二个域,......以此类推。
ARGC 命令行参数个数
ARGV 数组,保存的是命令行所给定的各参数。
ENVIRON 支持队列中系统环境变量的使用
FILENAME awk浏览的文件名
NF 浏览记录的域的个数
NR 已读的记录数
FNR 文件的记录数
FS 输入域分隔符
OFS 输出域分隔符
RS 输入记录分隔符
ORS 输出记录分隔符
记录分隔符是换行符,\n
域(字段)分隔符是空白符
下面这二者是不一样的,
awk '{print NF}' /etc/fstab 输出每一行的字段数
awk '{print $NF}' /etc/fstab 输出每一行的最后一个字段
fgy@fgy-QTH6:~$ awk 'BEGIN{print ARGC}' /etc/os-release
2
fgy@fgy-QTH6:~$ awk 'BEGIN{print ARGV[0]}' /etc/os-release
awk
fgy@fgy-QTH6:~$ awk 'BEGIN{print ARGV[1]}' /etc/os-release
/etc/os-release
FNR表示当前文件的记录数 NR表示到此为止的记录数
对于单个文件NR 和FNR 的输出结果一样的,但是对于多个文件是不一样的
awk '{print NR,$0}' file1
awk '{print FNR,$0}' file1
awk '{print NR,$0}' file1 file2
awk '{print FNR,$0}' file1 file2
$n 当前记录的第n个字段,字段间由FS分隔。
$0 完整的输入记录。
ARGC 命令行参数的数目。
ARGIND 命令行中当前文件的位置(从0开始算)。
ARGV 包含命令行参数的数组。
CONVFMT 数字转换格式(默认值为%.6g)
ENVIRON 环境变量关联数组。
ERRNO 最后一个系统错误的描述。
FIELDWIDTHS 字段宽度列表(用空格键分隔)。
FILENAME 当前文件名。
FNR 同NR,但相对于当前文件。
FS 字段分隔符(默认是任何空格)。
IGNORECASE 如果为真,则进行忽略大小写的匹配。
NF 当前记录中的字段数。
NR 当前记录数(行号)。
OFMT 数字的输出格式(默认值是%.6g)。
OFS 输出字段分隔符(默认值是一个空格)。
ORS 输出记录分隔符(默认值是一个换行符)。
RLENGTH 由match函数所匹配的字符串的长度。
RS 记录分隔符(默认是一个换行符)。
RSTART 由match函数所匹配的字符串的第一个位置。
SUBSEP 数组下标分隔符(默认值是\034)。
awk -F ':' '{print "filename:" FILENAME ",linenumber:" NR ",columns:" NF ",linecontent:"$0}' /etc/passwd
使用printf替代print,可以让代码更加简洁,易读
awk -F ':' '{printf("filename:%10s,linenumber:%s,columns:%s,linecontent:%s\n",FILENAME,NR,NF,$0)}' /etc/passwd
awk中同时提供了print和printf两种打印输出的函数。
其中print函数的参数可以是变量、数值或者字符串。字符串必须用双引号引用,参数用逗号分隔。如果没有逗号,参数就串联在一起而无法区分。这里,逗号的作用与输出文件的分隔符的作用是一样的,只是后者是空格而已。
printf函数,其用法和c语言中printf基本相似,可以格式化字符串,输出复杂时,printf更加好用,代码更易懂。
print要点
print items,items,...
1、items可以是字符串,数值,变量,表达式
2、items之间用逗号分隔。
3、如省略items,则输出$0
fgy@fgy-QTH6:~$ grep -v "^#" /etc/fstab|awk '{print "hello",$2,$4,7}'
hello / errors=remount-ro 7
hello /boot defaults 7
hello none sw 7
awk -v FS=':' '{print $1}' /etc/passwd
awk -F: '{print $1}" /etc/passwd
printf
格式化输出
printf FORMAT,items1,items2,...
要点
1、不会自动换行,需要加\n
2、format 需要分别为后面每一个items指定一个格式化符号
格式符
%%,显示%本身
%s,显示字符串
%d
%f
%c,显示ascii码
修饰符
#[.#]固定多少个字符宽度 %20s
-左对齐,默认右对齐 %-20s
+显示数值的符号,正负
fgy@fgy-QTH6:~/Documents$ awk -F: '{printf "username:%20s,uid:%10s\n",$1,$3}' /etc/passwd
fgy@fgy-QTH6:~/Documents$ awk -F: '{printf "username:%-20s,uid:%10s\n",$1,$3}' /etc/passwd
fgy@fgy-QTH6:~/Documents$ awk -F: '{printf "username:%-20s,uid:%d\n",$1,$3}' /etc/passwd
fgy@fgy-QTH6:~/Documents$ awk -F: '{printf "username:%-20s\n",$1} END{printf "ascii:%c\n",108}' /etc/passwd
除了awk的内置变量,awk还可以自定义变量
引用变量不需要加$符号
1、-v var=name
2、直接在program中引用
如果不需要对文件处理,就不加文件参数了
awk -v test="hello" 'BEGIN{print test}'
fgy@fgy-QTH6:~$ awk 'BEGIN{test="hello";print test}'
hello
函数调用
fun_name()如果有参数要传递,可以在括号中传递
条件表达式
expression?if true:if false
fgy@fgy-QTH6:~$ awk -F: '{$3>1000?usertype="common user":usertype="system user";printf "%20s:%s\n",$1,usertype}' /etc/passwd
用bash实现以上功能比较困难,而用awk就很简单,代码也清晰
所以针对不同的需求,选用合适的工具,能达到事半功倍的效果
每一行对每一个字段单独统计字符数量是多少
awk '/BEGIN/{for(i=1;i<=NF;i++) {print $i,length($i)}}' /etc/grub2.cfg
for的特殊用法
遍历数组中的每一个元素
for (var in array){for body}
[root@localhost ~]# ss -na|awk '/^tcp/{state[$2]++} END{for (i in state) {print i,state[i]}}'
LISTEN 4
ESTAB 1
[root@aster2 ~]# ss -na|awk '{state[$1]++} END{for (i in state) {print i,state[i]}}'
LISTEN 7
ESTAB 37
State 1
FIN-WAIT-1 1
统计ip出现的次数
[root@rac02 log]# awk '{ip[$1]++}END{for (i in ip) {print i,ip[i]}}' /var/log/httpd/access_log
行内字段遍历
统计指定文件每个单词出现的次数
awk '{for (i=1;i<=NF;i++){count[$i]++}}END{for (i in count){print i,count[i]}}' /etc/passwd
函数
fgy@fgy-QTH6:~$ awk 'BEGIN{print rand()}'
0.202347
fgy@fgy-QTH6:~$ awk 'BEGIN{print rand()}'
0.465422
fgy@fgy-QTH6:~$ awk 'BEGIN{print rand()}'
0.728498
下面统计/etc/passwd的账户人数
awk '{count++;print $0;} END{print "user count is ", count}' /etc/passwd
count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开。
这里没有初始化count,虽然默认是0,但是妥当的做法还是初始化为0:
awk 'BEGIN {count=0;print "[start]user count is ", count} {count=count+1;print $0;} END{print "[end]user count is ", count}' /etc/passwd
条件语句
awk中的条件语句是从C语言中借鉴来的,见如下声明方式:
if(表达式) #if (Variable in Array )
语句1
else
语句2
格式中"语句1"可以是多个语句,如果你为了方便Unix awk判断也方便你自已阅读,你最好将多个语句用{}括起来。每条命令语句后面可以用“;”号结尾。
Unix awk分枝结构允许嵌套,其格式为: if(表达式)
{语句1}
else if(表达式)
{语句2}
else
{语句3} [root@-shiyan awk]# cat pa.awk
{
if($>=)
print $,"very good"
else if($>=&&$<)
print $,"good"
else
print $,"no pass"
}
[root@-shiyan awk]# awk -f pa.awk grade.txt
very good
no pass
good
no pass
good
循环语句
awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd 这里使用for循环遍历数组
数组
因为awk中数组的下标可以是数字和字母,数组的下标通常被称为关键字(key)。值和关键字都存储在内部的一张针对key/value应用hash的表格里。由于hash不是顺序存储,因此在显示数组内容时会发现,它们并不是按照你预料的顺序显示出来的。数组和变量一样,都是在使用时自动创建的,awk也同样会自动判断其存储的是数字还是字符串。一般而言,awk中的数组用来从记录中收集信息,可以用于计算总和、统计单词以及跟踪模板被匹配的次数等等。
如果不指明采取什么动作,awk默认打印出所有浏览出的记录,与{print $0}是一样的
模式和动作两者是可选的,如果没有模式,则action应用到全部记录,如果没有action,则输出匹配全部记录。默认情况下,每一个输入行都是一条记录,但用户可通过RS变量指定不同的分隔符进行分隔。
6. 记录和域
6.1. 记录
awk把每一个以换行符结束的行称为一个记录。
记录分隔符:默认的输入和输出的分隔符都是回车,保存在内建变量ORS和RS中。
$0变量:它指的是整条记录。如$ awk '{print $0}' test将输出test文件中的所有记录。
变量NR:一个计数器,每处理完一条记录,NR的值就增加1。如$ awk '{print NR,$0}' test将输出test文件中所有记录,并在记录前显示记录号。
6.2. 域
记录中每个单词称做“域”,默认情况下以空格或tab分隔。awk可跟踪域的个数,并在内建变量NF中保存该值。如$ awk '{print $1,$3}' test将打印test文件中第一和第三个以空格分开的列(域)。
6.3. 域分隔符
内建变量FS保存输入域分隔符的值,默认是空格或tab。我们可以通过-F命令行选项修改FS的值。如$ awk -F: '{print $1,$5}' test将打印以冒号为分隔符的第一,第五列的内容。
可以同时使用多个域分隔符,这时应该把分隔符写成放到方括号中,如$awk -F'[:\t]' '{print $1,$3}' test,表示以空格、冒号和tab作为分隔符。
输出域的分隔符默认是一个空格,保存在OFS中。
awk中的next用法
举个例子:
cat file
1 a
2 b
3 c
4 d
awk '/^3/{print $2;next}{print $0}' file
1 a
2 b
c
4 d
如果匹配不到开头为3的记录,就打印$0
如果匹配到了开头为3的记录,就打印$2,这里如果没有next,会继续再打印$0
awk '/^3/{print $2}{print $0}'
1 a
2 b
c
3 c
4 d
next就是读取下一条记录,再从头执行代码
awk中删除重复行(转)
1.去除部分字段重复的行
sort+uniq也可以完成,但是awk真的很强大。两者的差异还在于,awk保持了文件中原本的每行的顺序,而sort必须排序,这样就变成按字母或某种其他规则的排序了。
less num.list |awk '$1~/84[0-9]/'|awk '!a[$1]++'
2.去除记录重复的行 awk去除重复行,思路是以每一行的$0为key,创建一个hash数组,后续碰到的行,如果数组里已经有了,就不再print了,否则将其print
在awk中,可以用!a[$0]++做为条件,对重复出现的行进行处理。
1.如果仅仅是删除内容完全一样的重复行
则可以使用sort先进行排序 然后使用 uniq进行删除重复数据即可,uniq 去除重复(必须先进行排序,否则uniq无法去除重复 uniq 是比较前后两行的数据,如果相邻两行数据不同则认为数据不同)
sort CUST.TXT | uniq > Target.TXT
2.根据指定列进行去除重复行
这里的重复是指如果两行的某一列数据相同,则认为是重复数据,现在我们如何去除列相同的重复项
第一步:sort进行排序
第二步:用awk对相邻两行数据进行比较如果第一列的数据相同则去除重复行(保留第一个相同的行)
这里的去除重复行并不是真正的删除重复行而是利用unix shell管道对重复行的不进行重定向输出
sort -t,-k1 CUST.TXT | awk -F, '
$1 == CUST_ID {
}
$1 != CUST_ID {
CUST_ID = $1;
print $0;
}' > Target.TXT
sort -t, -k1
-t,指定文件记录域分隔符为","
-k1是指根据第1列进行排序
-F, 指定域分隔符为","
$1 == CUST_ID 判断 第一列是否与变量 CUST_ID相等(不必要担心CUST_ID变量的值在初始化时awk为CUST_ID 赋值为""),如果相等什么多不做
$1 != CUST_ID { CUST_ID = $1 ;print $0;}如果一列不等于 CUST_ID 变量的值将$1赋值为 CUST_ID
然后打印这行数据,然后进行下一行比较下一行数据与上一行数据的CUST_ID 是否相等 相等 什么都不做,也就是说不打印这一行 如果不相等则打印这一行从而起到去除重复数据的作用
awk中RS,ORS,FS,OFS区别与联系(转)
awk文件合并方法(转载)
执行 shell 的 date 命令,并通过管道输出给 getline ,然后再把输出赋值给自定义变量 d ,并打印它。
awk 'BEGIN{ "date" | getline d; print d}'
awk中next以及getline用法示例
执行 shell 的 date 命令,并通过管道输出给 getline ,然后 getline 从管道中读取并将输入赋值给d , split 函数把变量 d 转化成数组 mon ,然后打印数组 mon 的第二个元素。
awk 'BEGIN{"date" | getline d; split(d,mon); print mon[2]}'
命令 ls 的输出传递给 getline 作为输入,循环使 getline 从 ls 的输出中读取一行,并把它打印到屏幕。这里没有输入文件,因为 BEGIN 块在打开输入文件前执行,所以可以忽略输入文件。
awk 'BEGIN{while( "ls" | getline) print}'
awk 'BEGIN{n1=124.113;n2=-1.224;n3=1.2345; printf("%.2f\n%.2u\n%.2g\n%X\n%o\n",n1,n2,n3,n1,n1);}'
awk 'BEGIN{while("cat /etc/passwd"|getline){print $0;};close("/etc/passwd");}'
awk 'BEGIN{while(getline < "/etc/passwd"){print $0;};close("/etc/passwd");}'
awk 'BEGIN{print "Enter your name:";getline name;print name;}'
awk 'BEGIN{b=system("ls -al");print b;}'
awk 'BEGIN{tstamp=mktime("2001 01 01 12 12 12");print strftime("%c",tstamp);}'
awk 'BEGIN{tstamp1=mktime("2001 01 01 12 12 12");tstamp2=mktime("2001 02 01 0 0 0");print tstamp2-tstamp1;}'
awk 'BEGIN{tstamp1=mktime("2001 01 01 12 12 12");tstamp2=systime();print tstamp2-tstamp1;}'
awk笔记的更多相关文章
- Sed&awk笔记之sed篇
http://blog.csdn.net/a81895898/article/details/8482387 Sed是什么 <sed and awk>一书中(1.2 A Stream Ed ...
- Sed&awk笔记之sed篇(转)
Sed是什么 <sed and awk>一书中(1.2 A Stream Editor)是这样解释的: Sed is a "non-interactive" strea ...
- Sed&awk笔记之awk篇
http://blog.csdn.net/a81895898/article/details/8482333 Awk是什么 Awk.sed与grep,俗称Linux下的三剑客,它们之间有很多相似点,但 ...
- awk笔记1
grep: 文本过滤器 grep 'pattern' input_file ... sed:流编辑器 awk: 报告生成器 格式化以后,显示 AWK a.k.a. Aho, Kernigh ...
- Sed&awk笔记之awk篇(转)
Awk是什么 Awk.sed与grep,俗称Linux下的三剑客,它们之间有很多相似点,但是同样也各有各的特色,相似的地方是它们都可以匹配文本,其中sed和awk还可以用于文本编辑,而grep则不具备 ...
- 【Linux】awk笔记
awk是一种处理文本文件的语言,是一个强大的文本分析工具. 实例 ①显示文件行中匹配项 # 每行按空格或TAB分割,输出文本中的1.4项 yunduo@yunduo-ThinkCentre-XXXX: ...
- awk-实践
实际中遇到的问题 字符串截取函数 substr #!/usr/bin/awk #author:zhaoyingnan #filename:substr.awk #substr 函数 #|awk -f ...
- sed原理及使用
前言 环境:centos6.5 sed版本:GNU sed version 4.2.1 本文的代码都是在这个环境下验证的. 一.简介 sed(Stream Editor)意为流编辑器,是Unix常见的 ...
- sed替换换行符“\n”
linux sed命令,如何替换换行符“\n” 在一次sed使用中,执行命令: sed "s/\n//g" file 1 发现,没起到任何效果. 后来,经查sed官方用户手册,才得 ...
随机推荐
- PHP中的文件下载
文件下载:用<a href="链接"></a>这种是下载,但对于浏览器能解释的文件类型此下载非彼下载.向服务器请求的时候:1.协议和版本2.头信息3.请求的 ...
- 【LeetCode OJ】Sum Root to Leaf Numbers
# Definition for a binary tree node # class TreeNode: # def __init__(self, x): # self.val = x # self ...
- 20145210 《Java程序设计》第09周学习总结
教材学习内容总结 第十六章 整合数据库 •JDBC(Java DataBase Connectivity) •JDBC是用于执行SQL的解决方案 •JDBC全名Java DataBase Connec ...
- LeetCode Binary Tree Paths(简单题)
题意: 给出一个二叉树,输出根到所有叶子节点的路径. 思路: 直接DFS一次,只需要判断是否到达了叶子,是就收集答案. /** * Definition for a binary tree node. ...
- BS模式的模型结构详解
编号:1004时间:2016年4月12日16:59:17功能:BS模式的模型结构详解 URL:http://blog.csdn.net/icerock2000/article/details/4000 ...
- 《JS高程》实现继承的6种方式(完整版)
许多OO语言都支持 两种继承方式: (1)接口继承:只继承方法签名: (2)实现继承:继承实际的方法. ECMAScript 由于函数没有签名,无法实现接口继承,因此只支持实现继承,而且主要是依靠原型 ...
- 【Sublime Text 3】
- 高手C++学习忠告~~[转载]
1.把C++当成一门新的语言学习(和C没啥关系!真的.): 2.看<Thinking In C++>,不要看<C++变成死相>: 3.看<The C++ Programm ...
- JAVA学习之Ecplise IDE 使用技巧(1)第一章:我的地盘我做主,工作空间
麦子学院/Andriod应用开发/第一阶段 Android 学前准备 第三课:Eclipse IDE 使用技巧 由马一鸣老师讲解.感谢麦子学院免费开放这部分视频资源. Eclipse由IBM开发的,2 ...
- 六 JSP 和 Servlet 的系统调优技巧
方法一:在 Servlet 的 init() 函数中申请缓冲数据 方法二:禁止 Servlet 和 JSP 的自动重载: Servlet/JSP 提供了一个实用的技术,即自动重载技术,它为开发人员提供 ...