K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化elkan K-Means算法和大数据情况下的优化Mini Batch K-Means算法。
1. K-Means原理初探
K-Means算法的思想很简单,对于给定的样本集,按照样本之间的距离大小,将样本集划分为K个簇。让簇内的点尽量紧密的连在一起,而让簇间的距离尽量的大。
如果用数据表达式表示,假设簇划分为$(C_1,C_2,...C_k)$,则我们的目标是最小化平方误差E:$$ E = \sum\limits_{i=1}^k\sum\limits_{x \in C_i} ||x-\mu_i||_2^2$$
其中$\mu_i$是簇$C_i$的均值向量,有时也称为质心,表达式为:$$\mu_i = \frac{1}{|C_i|}\sum\limits_{x \in C_i}x$$
如果我们想直接求上式的最小值并不容易,这是一个NP难的问题,因此只能采用启发式的迭代方法。
K-Means采用的启发式方式很简单,用下面一组图就可以形象的描述。
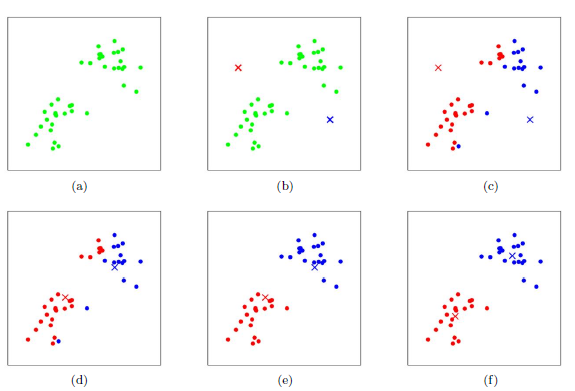
上图a表达了初始的数据集,假设k=2。在图b中,我们随机选择了两个k类所对应的类别质心,即图中的红色质心和蓝色质心,然后分别求样本中所有点到这两个质心的距离,并标记每个样本的类别为和该样本距离最小的质心的类别,如图c所示,经过计算样本和红色质心和蓝色质心的距离,我们得到了所有样本点的第一轮迭代后的类别。此时我们对我们当前标记为红色和蓝色的点分别求其新的质心,如图4所示,新的红色质心和蓝色质心的位置已经发生了变动。图e和图f重复了我们在图c和图d的过程,即将所有点的类别标记为距离最近的质心的类别并求新的质心。最终我们得到的两个类别如图f。
当然在实际K-Mean算法中,我们一般会多次运行图c和图d,才能达到最终的比较优的类别。
2. 传统K-Means算法流程
在上一节我们对K-Means的原理做了初步的探讨,这里我们对K-Means的算法做一个总结。
首先我们看看K-Means算法的一些要点。
1)对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2)在确定了k的个数后,我们需要选择k个初始化的质心,就像上图b中的随机质心。由于我们是启发式方法,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心,最好这些质心不能太近。
好了,现在我们来总结下传统的K-Means算法流程。
输入是样本集$D=\{x_1,x_2,...x_m\}$,聚类的簇树k,最大迭代次数N
输出是簇划分$C=\{C_1,C_2,...C_k\}$
1) 从数据集D中随机选择k个样本作为初始的k个质心向量: $\{\mu_1,\mu_2,...,\mu_k\}$
2)对于n=1,2,...,N
a) 将簇划分C初始化为$C_t = \varnothing \;\; t =1,2...k$
b) 对于i=1,2...m,计算样本$x_i$和各个质心向量$\mu_j(j=1,2,...k)$的距离:$d_{ij} = ||x_i - \mu_j||_2^2$,将$x_i$标记最小的为$d_{ij}$所对应的类别$\lambda_i$。此时更新$C_{\lambda_i} = C_{\lambda_i} \cup \{x_i\}$
c) 对于j=1,2,...,k,对$C_j$中所有的样本点重新计算新的质心$\mu_j = \frac{1}{|C_j|}\sum\limits_{x \in C_j}x$
e) 如果所有的k个质心向量都没有发生变化,则转到步骤3)
3) 输出簇划分$C=\{C_1,C_2,...C_k\}$
3. K-Means初始化优化K-Means++
在上节我们提到,k个初始化的质心的位置选择对最后的聚类结果和运行时间都有很大的影响,因此需要选择合适的k个质心。如果仅仅是完全随机的选择,有可能导致算法收敛很慢。K-Means++算法就是对K-Means随机初始化质心的方法的优化。
K-Means++的对于初始化质心的优化策略也很简单,如下:
a) 从输入的数据点集合中随机选择一个点作为第一个聚类中心$\mu_1$
b) 对于数据集中的每一个点$x_i$,计算它与已选择的聚类中心中最近聚类中心的距离$D(x) = arg\;min \sum\limits_{r=1}^{k_{selected}}||x_i- \mu_r||_2^2$
c) 选择一个新的数据点作为新的聚类中心,选择的原则是:$D(x)$较大的点,被选取作为聚类中心的概率较大
d) 重复b和c直到选择出k个聚类质心
e) 利用这k个质心来作为初始化质心去运行标准的K-Means算法
4. K-Means距离计算优化elkan K-Means
在传统的K-Means算法中,我们在每轮迭代时,要计算所有的样本点到所有的质心的距离,这样会比较的耗时。那么,对于距离的计算有没有能够简化的地方呢?elkan K-Means算法就是从这块入手加以改进。它的目标是减少不必要的距离的计算。那么哪些距离不需要计算呢?
elkan K-Means利用了两边之和大于等于第三边,以及两边之差小于第三边的三角形性质,来减少距离的计算。
第一种规律是对于一个样本点$x$和两个质心$\mu_{j_1}, \mu_{j_2}$。如果我们预先计算出了这两个质心之间的距离$D(j_1,j_2)$,则如果计算发现$2D(x,j_1) \leq D(j_1,j_2)$,我们立即就可以知道$D(x,j_1) \leq D(x, j_2)$。此时我们不需要再计算$D(x, j_2)$,也就是说省了一步距离计算。
第二种规律是对于一个样本点$x$和两个质心$\mu_{j_1}, \mu_{j_2}$。我们可以得到$D(x,j_2) \geq max\{0, D(x,j_1) - D(j_1,j_2)\}$。这个从三角形的性质也很容易得到。
利用上边的两个规律,elkan K-Means比起传统的K-Means迭代速度有很大的提高。但是如果我们的样本的特征是稀疏的,有缺失值的话,这个方法就不使用了,此时某些距离无法计算,则不能使用该算法。
5. 大样本优化Mini Batch K-Means
在统的K-Means算法中,要计算所有的样本点到所有的质心的距离。如果样本量非常大,比如达到10万以上,特征有100以上,此时用传统的K-Means算法非常的耗时,就算加上elkan K-Means优化也依旧。在大数据时代,这样的场景越来越多。此时Mini Batch K-Means应运而生。
顾名思义,Mini Batch,也就是用样本集中的一部分的样本来做传统的K-Means,这样可以避免样本量太大时的计算难题,算法收敛速度大大加快。当然此时的代价就是我们的聚类的精确度也会有一些降低。一般来说这个降低的幅度在可以接受的范围之内。
在Mini Batch K-Means中,我们会选择一个合适的批样本大小batch size,我们仅仅用batch size个样本来做K-Means聚类。那么这batch size个样本怎么来的?一般是通过无放回的随机采样得到的。
为了增加算法的准确性,我们一般会多跑几次Mini Batch K-Means算法,用得到不同的随机采样集来得到聚类簇,选择其中最优的聚类簇。
6. K-Means与KNN
初学者很容易把K-Means和KNN搞混,两者其实差别还是很大的。
K-Means是无监督学习的聚类算法,没有样本输出;而KNN是监督学习的分类算法,有对应的类别输出。KNN基本不需要训练,对测试集里面的点,只需要找到在训练集中最近的k个点,用这最近的k个点的类别来决定测试点的类别。而K-Means则有明显的训练过程,找到k个类别的最佳质心,从而决定样本的簇类别。
当然,两者也有一些相似点,两个算法都包含一个过程,即找出和某一个点最近的点。两者都利用了最近邻(nearest neighbors)的思想。
7. K-Means小结
K-Means是个简单实用的聚类算法,这里对K-Means的优缺点做一个总结。
K-Means的主要优点有:
1)原理比较简单,实现也是很容易,收敛速度快。
2)聚类效果较优。
3)算法的可解释度比较强。
4)主要需要调参的参数仅仅是簇数k。
K-Means的主要缺点有:
1)K值的选取不好把握
2)对于不是凸的数据集比较难收敛
3)如果各隐含类别的数据不平衡,比如各隐含类别的数据量严重失衡,或者各隐含类别的方差不同,则聚类效果不佳。
4) 采用迭代方法,得到的结果只是局部最优。
5) 对噪音和异常点比较的敏感。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
K-Means聚类算法原理的更多相关文章
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 【转】K-Means聚类算法原理及实现
k-means 聚类算法原理: 1.从包含多个数据点的数据集 D 中随机取 k 个点,作为 k 个簇的各自的中心. 2.分别计算剩下的点到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇.两 ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- OPTICS聚类算法原理
OPTICS聚类算法原理 基础 OPTICS聚类算法是基于密度的聚类算法,全称是Ordering points to identify the clustering structure,目标是将空间中 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理.这里我们再来看看另外一种常见的聚类算法BIRCH.BIRCH算法比较适合于数据量大,类别数K也 ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
随机推荐
- 死磕内存篇 --- JAVA进程和linux内存间的大小关系
运行个JAVA 用sleep去hold住 package org.hjb.test; public class TestOnly { public static void main(String[] ...
- jsp中出现onclick函数提示Cannot return from outside a function or method
在使用Myeclipse10部署完项目后,原先不出错的项目,会有红色的叉叉,JSP页面会提示onclick函数错误 Cannot return from outside a function or m ...
- Python的单元测试(二)
title: Python的单元测试(二) date: 2015-03-04 19:08:20 categories: Python tags: [Python,单元测试] --- 在Python的单 ...
- UWP开发之Template10实践二:拍照功能你合理使用了吗?(TempState临时目录问题)
最近在忙Asp.Net MVC开发一直没空更新UWP这块,不过有时间的话还是需要将自己的经验和大家分享下,以求共同进步. 在上章[UWP开发之Template10实践:本地文件与照相机文件操作的MVV ...
- SVD奇异值分解的基本原理和运用
SVD奇异值分解: SVD是一种可靠的正交矩阵分解法.可以把A矩阵分解成U,∑,VT三个矩阵相乘的形式.(Svd(A)=[U*∑*VT],A不必是方阵,U,VT必定是正交阵,S是对角阵<以奇异值 ...
- Git分布式版本控制教程
Git分布式版本控制Git 安装配置Linux&Unix平台 Debian/Ubuntu $ apt-get install git Fedora $ ) $ dnf and later) G ...
- ios 获取或修改网页上的内容
UIWebView是iOS最常用的SDK之一,它有一个stringByEvaluatingJavaScriptFromString方法可以将javascript嵌 入页面中,通过这个方法我们可 ...
- MongoDB学习笔记四—增删改文档下
$slice 如果希望数组的最大长度是固定的,那么可以将 $slice 和 $push 组合在一起使用,就可以保证数组不会超出设定好的最大长度.$slice 的值必须是负整数. 假设$slice的值为 ...
- webpack解惑:多入口文件打包策略
本文是我用webpack进行项目构建的实践心得,场景是这样的,项目是大型类cms型,技术选型是vue,只支持chrome,有诸多子功能模块,全部打包在一起的话会有好几MB,所以最佳方式是进行多入口打包 ...
- jar hell & elasticsearch ik 版本问题
想给es 安装一个ik 的插件, 我的es 是 2.4.0, 下载了一个版本是 1.9.5, [2016-10-09 16:56:26,248][INFO ][node ] [node-2] init ...