深入理解HBase Memstore
2013/08/09 转发自http://www.cnblogs.com/shitouer/archive/2013/02/05/configuring-hbase-memstore-what-you-should-know.html
深入理解HBase Memstore
个人小站,正在持续整理中,欢迎访问:http://shitouer.cn
小站博文地址:深入理解HBase Memstore: http://shitouer.cn/2013/02/configuring-hbase-memstore-what-you-should-know/
HBase Memstore
首先通过简单介绍HBase的读写过程来理解一下MemStore到底是什么,在何处发挥作用,如何使用到以及为什么要用MemStore。
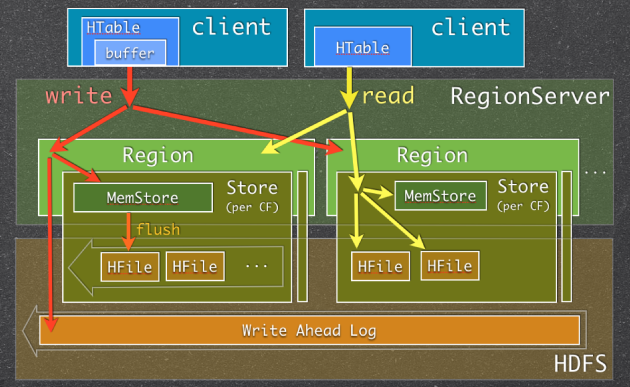
图一:Memstore Usage in HBase Read/Write Paths
当RegionServer(RS)收到写请求的时候(write request),RS会将请求转至相应的Region。每一个Region都存储着一些列(a set of rows)。根据其列族的不同,将这些列数据存储在相应的列族中(Column Family,简写CF)。不同的CFs中的数据存储在各自的HStore中,HStore由一个Memstore及一系列HFile组成。Memstore位于RS的主内存中,而HFiles被写入到HDFS中。当RS处理写请求的时候,数据首先写入到Memstore,然后当到达一定的阀值的时候,Memstore中的数据会被刷到HFile中。
用到Memstore最主要的原因是:存储在HDFS上的数据需要按照row key 排序。而HDFS本身被设计为顺序读写(sequential reads/writes),不允许修改。这样的话,HBase就不能够高效的写数据,因为要写入到HBase的数据不会被排序,这也就意味着没有为将来的检索优化。为了解决这个问题,HBase将最近接收到的数据缓存在内存中(in Memstore),在持久化到HDFS之前完成排序,然后再快速的顺序写入HDFS。需要注意的一点是实际的HFile中,不仅仅只是简单地排序的列数据的列表,详见Apache HBase I/O – HFile 。
除了解决“无序”问题外,Memstore还有一些其他的好处,例如:
- 作为一个内存级缓存,缓存最近增加数据。一种显而易见的场合是,新插入数据总是比老数据频繁使用。
- 在持久化写入之前,在内存中对Rows/Cells可以做某些优化。比如,当数据的version被设为1的时候,对于某些CF的一些数据,Memstore缓存了数个对该Cell的更新,在写入HFile的时候,仅需要保存一个最新的版本就好了,其他的都可以直接抛弃。
有一点需要特别注意:每一次Memstore的flush,会为每一个CF创建一个新的HFile。 在读方面相对来说就会简单一些:HBase首先检查请求的数据是否在Memstore,不在的话就到HFile中查找,最终返回merged的一个结果给用户。
HBase Memstore关注要点
迫于以下几个原因,HBase用户或者管理员需要关注Memstore并且要熟悉它是如何被使用的:
- Memstore有许多配置可以调整以取得好的性能和避免一些问题。HBase不会根据用户自己的使用模式来调整这些配置,你需要自己来调整。
- 频繁的Memstore flush会严重影响HBase集群读性能,并有可能带来一些额外的负载。
- Memstore flush的方式有可能影响你的HBase schema设计
接下来详细讨论一下这些要点:
Configuring Memstore Flushes
对Memstore Flush来说,主要有两组配置项:
- 决定Flush触发时机
- 决定Flush何时触发并且在Flush时候更新被阻断(block)
第一组是关于触发“普通”flush,这类flush发生时,并不影响并行的写请求。该类型flush的配置项有:
- hbase.hregion.memstore.flush.size
|
1
2
3
4
5
6
7
8
9
|
<property> <name>hbase.hregion.memstore.flush.size</name> <value>134217728</value> <description> Memstore will be flushed to disk if size of the memstore exceeds this number of bytes. Value is checked by a thread that runs every hbase.server.thread.wakefrequency. </description></property> |
- base.regionserver.global.memstore.lowerLimit
|
1
2
3
4
5
6
7
8
9
10
|
<property> <name>hbase.regionserver.global.memstore.lowerLimit</name> <value>0.35</value> <description>Maximum size of all memstores in a region server before flushes are forced. Defaults to 35% of heap. This value equal to hbase.regionserver.global.memstore.upperLimit causes the minimum possible flushing to occur when updates are blocked due to memstore limiting. </description></property> |
需要注意的是第一个设置是每个Memstore的大小,当你设置该配置项时,你需要考虑一下每台RS承载的region总量。可能一开始你设置的该值比较小,后来随着region增多,那么就有可能因为第二个设置原因Memstore的flush触发会变早许多。
第二组设置主要是出于安全考虑:有时候集群的“写负载”非常高,写入量一直超过flush的量,这时,我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻止(blocked)一直到memstore恢复到一个“可管理”(manageable)的大小。该类型flush配置项有:
- hbase.regionserver.global.memstore.upperLimit
|
1
2
3
4
5
6
7
8
9
|
<property> <name>hbase.regionserver.global.memstore.upperLimit</name> <value>0.4</value> <description>Maximum size of all memstores in a region server before new updates are blocked and flushes are forced. Defaults to 40% of heap. Updates are blocked and flushes are forced until size of all memstores in a region server hits hbase.regionserver.global.memstore.lowerLimit. </description></property> |
- hbase.hregion.memstore.block.multiplier
|
1
2
3
4
5
6
7
8
9
10
11
12
|
<property> <name>hbase.hregion.memstore.block.multiplier</name> <value>2</value> <description> Block updates if memstore has hbase.hregion.block.memstore time hbase.hregion.flush.size bytes. Useful preventing runaway memstore during spikes in update traffic. Without an upper-bound, memstore fills such that when it flushes the resultant flush files take a long time to compact or split, or worse, we OOME. </description></property> |
某个节点“写阻塞”对该节点来说影响很大,但是对于整个集群的影响更大。HBase设计为:每个Region仅属于一个RS但是“写负载”是均匀分布于整个集群(所有Region上)。有一个如此“慢”的节点,将会使得整个集群都会变慢(最明显的是反映在速度上)。
提示:严重关切Memstore的大小和Memstore Flush Queue的大小。理想情况下,Memstore的大小不应该达到hbase.regionserver.global.memstore.upperLimit的设置,Memstore Flush Queue 的size不能持续增长。
频繁的Memstore Flushes
要避免“写阻塞”,貌似让Flush操作尽量的早于达到触发“写操作”的阈值为宜。但是,这将导致频繁的Flush操作,而由此带来的后果便是读性能下降以及额外的负载。
每次的Memstore Flush都会为每个CF创建一个HFile。频繁的Flush就会创建大量的HFile。这样HBase在检索的时候,就不得不读取大量的HFile,读性能会受很大影响。
为预防打开过多HFile及避免读性能恶化,HBase有专门的HFile合并处理(HFile Compaction Process)。HBase会周期性的合并数个小HFile为一个大的HFile。明显的,有Memstore Flush产生的HFile越多,集群系统就要做更多的合并操作(额外负载)。更糟糕的是:Compaction处理是跟集群上的其他请求并行进行的。当HBase不能够跟上Compaction的时候(同样有阈值设置项),会在RS上出现“写阻塞”。像上面说到的,这是最最不希望的。
提示:严重关切RS上Compaction Queue 的size。要在其引起问题前,阻止其持续增大。
想了解更多HFile 创建和合并,可参看 Visualizing HBase Flushes And Compactions 。
理想情况下,在不超过hbase.regionserver.global.memstore.upperLimit的情况下,Memstore应该尽可能多的使用内存(配置给Memstore部分的,而不是真个Heap的)。下图展示了一张“较好”的情况:
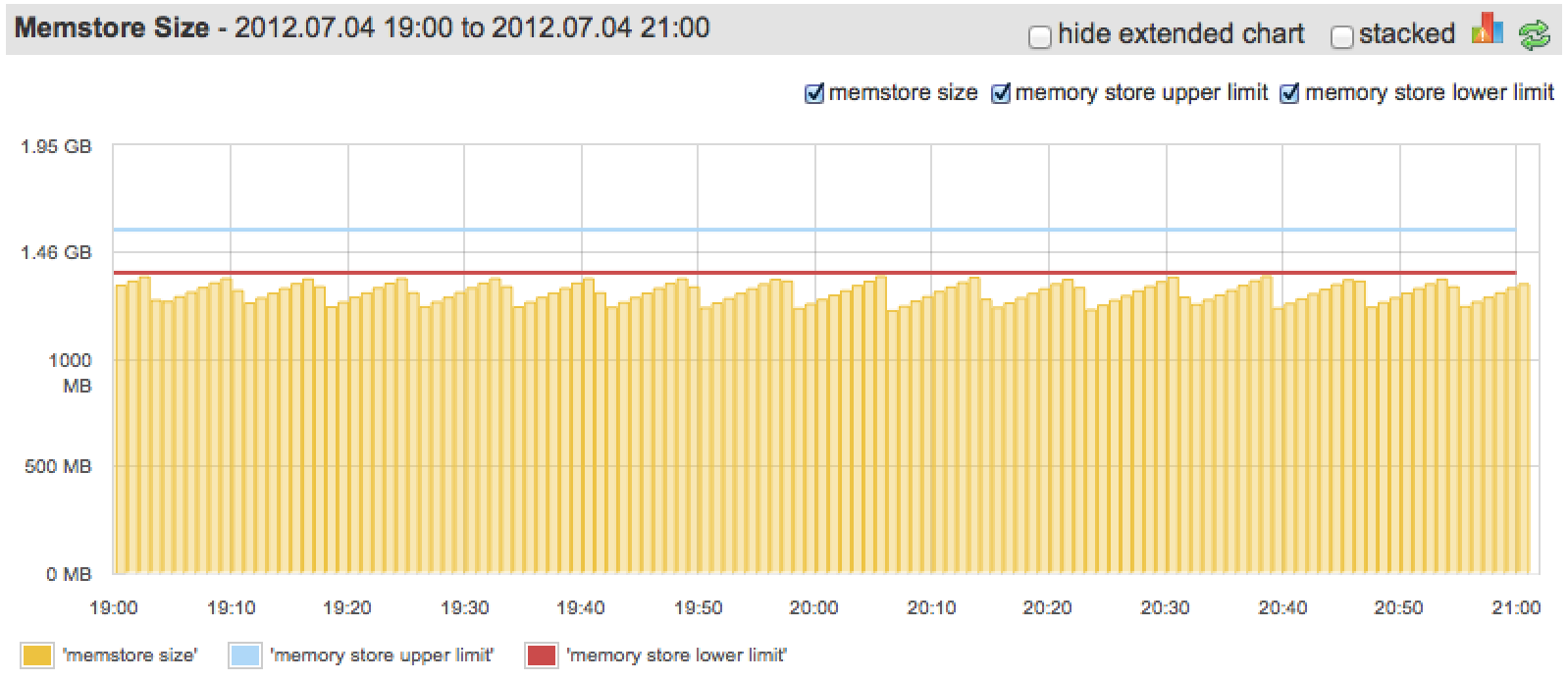
“Somewhat”, because we could configure lower limit to be closer to upper, since we barely ever go over it.
说是“较好”,是因为我们可以将“Lower limit”配置的更接近于“Upper limit”,我们几乎很少有超过它。
Multiple Column Families & Memstore Flush
每次Memstore Flush,会为每个CF都创建一个新的HFile。这样,不同CF中数据量的不均衡将会导致产生过多HFile:当其中一个CF的Memstore达到阈值flush时,所有其他CF的也会被flush。如上所述,太频繁的flush以及过多的HFile将会影响集群性能。
提示:很多情况下,一个CF是最好的设计。
HLog (WAL) Size & Memstore Flush
第一张HBase Read/Write path图中,你可能已经注意到当数据被写入时会默认先写入Write-ahead Log(WAL)。WAL中包含了所有已经写入Memstore但还未Flush到HFile的更改(edits)。在Memstore中数据还没有持久化,当RegionSever宕掉的时候,可以使用WAL恢复数据。
当WAL(在HBase中成为HLog)变得很大的时候,在恢复的时候就需要很长的时间。因此,对WAL的大小也有一些限制,当达到这些限制的时候,就会触发Memstore的flush。Memstore flush会使WAL 减少,因为数据持久化之后(写入到HFile),就没有必要在WAL中再保存这些修改。有两个属性可以配置:
- hbase.regionserver.hlog.blocksize
- hbase.regionserver.maxlogs
你可能已经发现,WAL的最大值由hbase.regionserver.maxlogs * hbase.regionserver.hlog.blocksize (2GB by default)决定。一旦达到这个值,Memstore flush就会被触发。所以,当你增加Memstore的大小以及调整其他的Memstore的设置项时,你也需要去调整HLog的配置项。否则,WAL的大小限制可能会首先被触发,因而,你将利用不到其他专门为Memstore而设计的优化。抛开这些不说,通过WAL限制来触发Memstore的flush并非最佳方式,这样做可能会会一次flush很多Region,尽管“写数据”是很好的分布于整个集群,进而很有可能会引发flush“大风暴”。
提示:最好将hbase.regionserver.hlog.blocksize * hbase.regionserver.maxlogs 设置为稍微大于hbase.regionserver.global.memstore.lowerLimit * HBASE_HEAPSIZE.
Compression & Memstore Flush
HBase建议压缩存储在HDFS上的数据(比如HFiles)。除了节省硬盘空间,同样也会显著地减少硬盘和网络IO。使用压缩,当Memstore flush并将数据写入HDFS时候,数据会被压缩。压缩不会减慢多少flush的处理过程,却会大大减少以上所述问题,例如因为Memstore变大(超过 upper limit)而引起的“写阻塞”等等。
提示:压缩库建议使用Snappy。有关Snappy的介绍及安装,可分别参考:《Hadoop压缩-SNAPPY算法 》和《Hadoop HBase 配置 安装 Snappy 终极教程
》
深入理解HBase Memstore的更多相关文章
- 深入理解HBase
深入理解HBase: https://www.jianshu.com/p/b23800d9b227
- 理解Hbase和BigTable(转)
add by zhj: 这篇文章写的通俗易懂,介绍了HBase最重要的几点特性. 英文原文:https://dzone.com/articles/understanding-hbase-and-big ...
- HBase MemStore与HStoreFile 的大小分析
Sumary: MemStore结构 KeyValue构成细节 HFile分析 Maven 项目例子使用了Maven来管理Dependency,要运行例子,需要有maven环境,后面提到的HFile, ...
- 理解HBase
1.HBase HBase: Hadoop Database,根据Google的Big Table设计 HBase是一个分布式.面向列族的开源数据库.HDFS为Hbase提供了底层的数据存储服务,Ma ...
- 深度预警:深入理解HBase的系统架构
HBase的构成 物理上来说,HBase是由三种类型的服务器以主从模式构成的.这三种服务器分别是:Region server,HBase HMaster,ZooKeeper. 其中Region ser ...
- 理解Hbase RowKey的字典排序;HBase Rowkey的散列与预分区设计
HBase是三维有序存储的,是指rowkey(行键),column key(column family和qualifier)和TimeStamp(时间戳)这个三个维度是依照ASCII码表排序的. HB ...
- 你想要的 HBase 原理都在这了
目录 一. 集群架构 集群角色 工作机制 二.存储机制 A. 存储模型 B. LSM 与 Compaction C. Region 分裂 D. 自动均衡 三.访问机制 四. 鉴权 五. 高可靠 1.集 ...
- Hbase框架原理及相关的知识点理解、Hbase访问MapReduce、Hbase访问Java API、Hbase shell及Hbase性能优化总结
转自:http://blog.csdn.net/zhongwen7710/article/details/39577431 本blog的内容包含: 第一部分:Hbase框架原理理解 第二部分:Hbas ...
- HBase学习之深入理解Memstore-6
MemStore是HBase非常重要的组成部分,深入理解MemStore的运行机制.工作原理.相关配置,对HBase集群管理以及性能调优有非常重要的帮助. HBase Memstore 首先通过简 ...
随机推荐
- 利用SOLR搭建企业搜索平台 之——Solr索引基本操作
来源:http://blog.csdn.net/zx13525079024/article/details/25367239 我们来看下通过界面来操作SOLR,包括SOLR索引的添加,查询等基本操作. ...
- php注册登录系统(一)-极简
序 登录注册系统是日常上网最普通的操作,我设了一个分类一步步完善注册登录系统,若有哪里错误请慧教 所用语言:php 数据库 :mysql 本次实现功能: 1.用户注册 2.用户登录 主要文件: 完整代 ...
- 收藏一些python的小技能
例子1:For .. else 语法 foo=[2,1] for i in foo: if i == 0: break else: print("i was never 0") 例 ...
- No resource found that matches the given name
XML里面明显已经定义了ID,可是android:layout_toLeftOf="@id/text_seller"报错,说没有定义,原来这玩意要写在相对位置对象声明的下面,是有顺 ...
- [置顶] Android Provision (Setup Wizard)
Android中很多框架性的设计都已经存在了,但在市场上的发布版本里却因为没有很好的理解Android的设计意图而进行自己的定制,或者自己又做一 个冗余的实现.Android中的Provision其实 ...
- Css中光标,DHTML,缩放的使用
Css中光标的使用: 属性名称 属性值 说明cursor ...
- C语言之宏
所谓的宏就是一种预处理命令,什么是与处理呢?即在编译过程之前先对程序代码做出的必要的转换处理.宏有两个作用: 1.当遇到需要将程序某个特定的数量在程序中出现的所有实例通通加以修改时,程序只需改动一处即 ...
- 免费的WebService
天气预报Web服务,数据来源于中国气象局 Endpoint : http://www.webxml.com.cn/WebServices/WeatherWebService.asmx Disc ...
- Eclipse 打开编辑文件所在文件夹方法
一个便捷的方法在eclipse的菜单中,依次点击Run->External Tools-> External Tools configurations添加一个新的工具 OpenContai ...
- 【转】Linux设备驱动之mmap设备操作
原文网址:http://www.cnblogs.com/geneil/archive/2011/12/08/2281222.html 1.mmap系统调用 void *mmap(void *addr, ...