IEEE Trans 2006 使用K-SVD构造超完备字典以进行稀疏表示(稀疏分解)
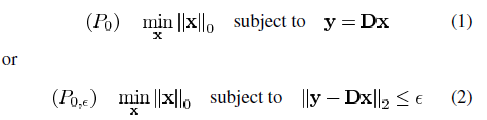
 存在字典D,对于每一个yk,通过求解公式(1)中的问题,我们能得到它的稀疏表示xk。
存在字典D,对于每一个yk,通过求解公式(1)中的问题,我们能得到它的稀疏表示xk。 ,每一个样本能被唯一一个描述性向量表示。(和该样本距离最近的原子,距离的计算通常是欧式距离)。K-means的流程大致可分为两步:i)给定,找到与训练信号距离最近的原子,将信号分成该原子所在的聚类;ii)根据i中的结果,更新dk以更好的近似训练信号。我们可以把这种情况认为是在稀疏表示只能用一个原子来近似原信号的特殊情况,在这种情况下,对应的近似原子的稀疏系数也只有一个。而在稀疏表示中,每个信号是用dk中的某几个原子的线性组合来表示的,所以我们可以认为稀疏表示问题是聚类算法K-means的一种广义泛化。
,每一个样本能被唯一一个描述性向量表示。(和该样本距离最近的原子,距离的计算通常是欧式距离)。K-means的流程大致可分为两步:i)给定,找到与训练信号距离最近的原子,将信号分成该原子所在的聚类;ii)根据i中的结果,更新dk以更好的近似训练信号。我们可以把这种情况认为是在稀疏表示只能用一个原子来近似原信号的特殊情况,在这种情况下,对应的近似原子的稀疏系数也只有一个。而在稀疏表示中,每个信号是用dk中的某几个原子的线性组合来表示的,所以我们可以认为稀疏表示问题是聚类算法K-means的一种广义泛化。 ,考虑似然函数P(Y|D),找到合适的使得似然函数最大的字典矩阵D。首先我们假设yi之间是互相独立的,则我们可将似然函数写成:
,考虑似然函数P(Y|D),找到合适的使得似然函数最大的字典矩阵D。首先我们假设yi之间是互相独立的,则我们可将似然函数写成: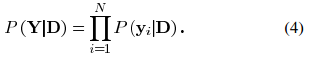
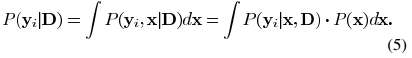
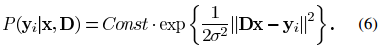
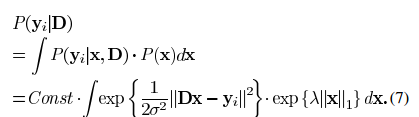
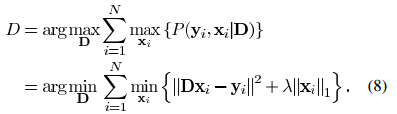

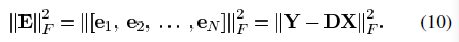

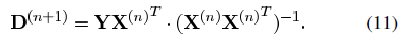
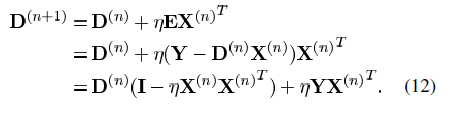
.png) 足够小,则我们能得到公式(11)中所更新的矩阵一样的结果。但是该方法在迭代过程中的结果只是当前最佳解的近似解,而MOD方法在每次迭代中都能达到最优的结果。上述两种方法都需要字典矩阵的列进行标准化。
足够小,则我们能得到公式(11)中所更新的矩阵一样的结果。但是该方法在迭代过程中的结果只是当前最佳解的近似解,而MOD方法在每次迭代中都能达到最优的结果。上述两种方法都需要字典矩阵的列进行标准化。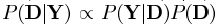 ,则我们可以继续使用似然函数的形式,并将先验概率作为一个新的项加入到式子中。
,则我们可以继续使用似然函数的形式,并将先验概率作为一个新的项加入到式子中。
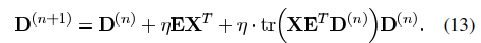
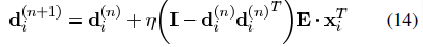

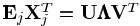 的奇异值分解,设已知系数为Xj,误差为Ej,计算最小二乘约束
的奇异值分解,设已知系数为Xj,误差为Ej,计算最小二乘约束 得到第j个正交基为Dj=UVT。Dj必须为正交的,用更新的基来重新表示数据矩阵Y,带入残差矩阵中,使得误差较少,通过这种方式分别独立更新D的每一项。(N≥K)。根据信号周围最近的代码字的选择,我们可以轻松的将Rn中的信号进行压缩或者描述为多个聚类。基于预期的最大化进程,K-means方法可以将协方差矩阵模糊分配给每个聚类,则信号可以抽象为混合高斯模型。
得到第j个正交基为Dj=UVT。Dj必须为正交的,用更新的基来重新表示数据矩阵Y,带入残差矩阵中,使得误差较少,通过这种方式分别独立更新D的每一项。(N≥K)。根据信号周围最近的代码字的选择,我们可以轻松的将Rn中的信号进行压缩或者描述为多个聚类。基于预期的最大化进程,K-means方法可以将协方差矩阵模糊分配给每个聚类,则信号可以抽象为混合高斯模型。
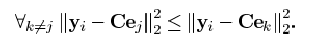
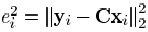 ,则总的MSE为:
,则总的MSE为: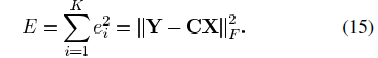



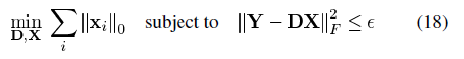

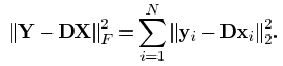
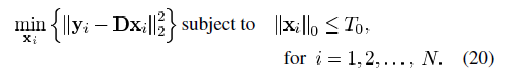
 (即为矩阵X的第k行,不同于X的第k列xk),则我们将式(19)中的惩罚项重写为
(即为矩阵X的第k行,不同于X的第k列xk),则我们将式(19)中的惩罚项重写为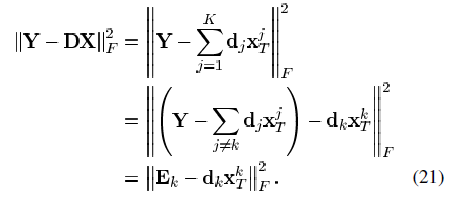
.png) 为使用dk的信号元素{yi}的索引,也就是
为使用dk的信号元素{yi}的索引,也就是.png) 非零项所在的位置。
非零项所在的位置。
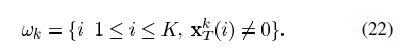
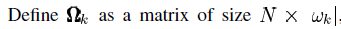 除了(ωk(i),i)th 的项其他都是0。则
除了(ωk(i),i)th 的项其他都是0。则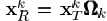 去除了零元素,是对行向量XTK的收缩后的结果。行向量XRK的长度为ωk。同理
去除了零元素,是对行向量XTK的收缩后的结果。行向量XRK的长度为ωk。同理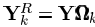 为n×ωk的矩阵,包含了使用了dk原子的信号的集合。同样我们有
为n×ωk的矩阵,包含了使用了dk原子的信号的集合。同样我们有 为除去没有用到dk原子的信号,并且不包含dk原子的误差。
为除去没有用到dk原子的信号,并且不包含dk原子的误差。现在我们返回到式(21),我们的目标是找到dk和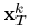 使得式(21)中的目标函数最小,我们令
使得式(21)中的目标函数最小,我们令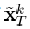 与原信号有同样的支撑集,则最小化可以等价为
与原信号有同样的支撑集,则最小化可以等价为
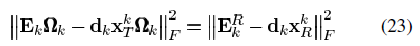
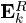 分解为
分解为 ,我们定义
,我们定义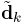 为矩阵U的第一列,
为矩阵U的第一列,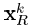 为矩阵V的第一列乘上Δ(1,1)。注意式(23)的求解需要:i)D中的列标准化;ii)得到的稀疏表示要么保持不变要么值减少。
为矩阵V的第一列乘上Δ(1,1)。注意式(23)的求解需要:i)D中的列标准化;ii)得到的稀疏表示要么保持不变要么值减少。
 的计算变为:
的计算变为: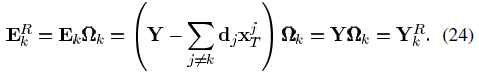
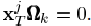 则SVD是直接对ωk中的信号进行操作的,D中的K列的更新之间也是相互独立的,类似于一个顺序更新过程或者说是平行过程,如同K-means更新聚类的中心一样。除了限制T0=1,我们还可以进一步限制X的非零项为1,此时问题完全变成了之前所说的经典的聚类问题。在这种情况下,都是1,也就是=1T。K-SVD方法需要用秩为1的矩阵dk·1T来近似误差矩阵
则SVD是直接对ωk中的信号进行操作的,D中的K列的更新之间也是相互独立的,类似于一个顺序更新过程或者说是平行过程,如同K-means更新聚类的中心一样。除了限制T0=1,我们还可以进一步限制X的非零项为1,此时问题完全变成了之前所说的经典的聚类问题。在这种情况下,都是1,也就是=1T。K-SVD方法需要用秩为1的矩阵dk·1T来近似误差矩阵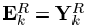 。求出的结果是
。求出的结果是 的平均值。如同K-means方法所做的那样。K-SVD算法容易陷入局部最小解,本文实验证明在下述变量满足的情况下,可避免此种情况的发生。
的平均值。如同K-means方法所做的那样。K-SVD算法容易陷入局部最小解,本文实验证明在下述变量满足的情况下,可避免此种情况的发生。
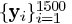 ,每一个都有字典中的三个不同的原子组成,互相独立,满足均匀分布。系数随机并且处在独立的位置,不同SNR的白高斯噪声将叠加在结果数据信号中。
,每一个都有字典中的三个不同的原子组成,互相独立,满足均匀分布。系数随机并且处在独立的位置,不同SNR的白高斯噪声将叠加在结果数据信号中。

IEEE Trans 2006 使用K-SVD构造超完备字典以进行稀疏表示(稀疏分解)的更多相关文章
- 对比学习下的跨模态语义对齐是最优的吗?---自适应稀疏化注意力对齐机制 IEEE Trans. MultiMedia
论文介绍:Unified Adaptive Relevance Distinguishable Attention Network for Image-Text Matching (统一的自适应相关性 ...
- 【转】IP协议详解之子网寻址、子网掩码、构造超网
子网寻址 1. 从两级IP地址到三级IP地址 <1>. IP地址利用率有时很低. <2>. 给每一个物理网络分配一个网络号会使路由表变得太大而使网络性能变坏. <3> ...
- IEEE Trans 2007 Signal Recovery From Random Measurements via OMP
看了一篇IEEE Trans上的关于CS图像重构的OMP算法的文章,大部分..看不懂,之前在看博客的时候对流程中的一些标号看不太懂,看完论文之后对流程有了一定的了解,所以在这里解释一下流程,其余的如果 ...
- IEEE Trans 2009 Stagewise Weak Gradient Pursuits论文学习
论文在第二部分先提出了贪婪算法框架,如下截图所示: 接着根据原子选择的方法不同,提出了SWOMP(分段弱正交匹配追踪)算法,以下部分为转载<压缩感知重构算法之分段弱正交匹配追踪(SWOMP)&g ...
- (转)IP协议详解之子网寻址、子网掩码、构造超网
原文网址:http://www.cnblogs.com/way_testlife/archive/2010/10/05/1844399.html 子网寻址 1. 从两级IP地址到三级IP地址 < ...
- 机器学习进阶-疲劳检测(眨眼检测) 1.dist.eculidean(计算两个点的欧式距离) 2.dlib.get_frontal_face_detector(脸部位置检测器) 3.dlib.shape_predictor(脸部特征位置检测器) 4.Orderdict(构造有序的字典)
1.dist.eculidean(A, B) # 求出A和B点的欧式距离 参数说明:A,B表示位置信息 2.dlib.get_frontal_face_detector()表示脸部位置检测器 3.dl ...
- 【Redis】命令学习笔记——列表(list)+集合(set)+有序集合(sorted set)(17+15+20个超全字典版)
本篇基于redis 4.0.11版本,学习列表(list)和集合(set)和有序集合(sorted set)相关命令. 列表按照插入顺序排序,可重复,可以添加一个元素到列表的头部(左边)或者尾部(右边 ...
- 【Redis】命令学习笔记——哈希(hash)(15个超全字典版)
本篇基于redis 4.0.11版本,学习哈希(hash)相关命令. hash 是一个string类型的field和value的映射表,特别适合用于存储对象. 序号 命令 描述 实例 返回 HSET ...
- 【Redis】命令学习笔记——字符串(String)(23个超全字典版)
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). 本篇基于redis 4.0.11版本,学习字符串( ...
随机推荐
- 【stl学习笔记】deques
deque双向队列是一种双向开口的连续线性空间,可以高效的在头尾两端插入和删除元素,deque在接口上和vector非常相似.deque的实现比较复杂,内部会维护一个map(注意!不是STL中的map ...
- [PythonCode]扫描局域网的alive ip地址
内网的主机都是自己主动分配ip地址,有时候须要查看下有那些ip在使用,就写了个简单的脚本. linux和windows下都能够用,用多线程来ping1-255全部的地址,效率不高.2分钟左右. 先凑合 ...
- win8系统 如何不显示这台电脑的文件夹
在win8系统中,默认有下面这种文件夹 只要打开注册表编辑器,找到下面所示的项目,删除所有子文件夹即可(最后剩下一个DelegateFolders不用管) [HKEY_LOCAL_MACHINE\ ...
- eclipse Alt+/ 不能提示
普通情况下alt+/有代码提示作用,还有代码提示的快捷代码也不是alt+/,因此要恢复代码提示用alt+/.须要做两件事. 在 Window - Preferences - General - Ke ...
- 微信小程序 自定义组件(stepper)
项目目录: 步骤一:创建组件 声明这一组文件为自定义组件 stepper.json { "component": true, "usingComponents" ...
- Tcl学习之--列表|字典
[列表|字典] Tcl使用列表来处理各种集合,比方一个目录中的全部文件,以及一个组件的全部选项.最简单的列表就是包括由随意个空格.制表符.换行符.分隔的随意多个元素的字符串.比方: JerryAlic ...
- ecshop广告宽度值必须在1到1024之间的解决方法
ecshop加广告出现广告位的宽度值必须在1到1024之间的解决方法,这个问题是今天刚刚发现的,我就郁闷了,如今1024宽度的广告能做什么.你看看京东,天猫,非常多都是大型的横幅广告,这点ecshop ...
- 找不到方法 Void Newtonsoft.Json.JsonConvert.set_DefaultSettings
找不到方法 Void Newtonsoft.Json.JsonConvert.set_DefaultSettings 因为 Newtonsoft.Json.dll 的版本号问题: C:\Program ...
- test_action
[TOP] 为什么百度校招数据挖掘工程师的笔试题目是跟数据挖掘关系不大? - 研究生生活交流 - 王道论坛,专注于计算机考研的点点滴滴! http://www.cskaoyan.com/thread- ...
- caution
做好需求更改的准备,提高代码的扩展性和可维护性:预留出修改bug和需求的时间:对需求理解透彻再开始写代码:代码不要写死,防止需求变动.