在 Windows 上利用Qwen大模型搭建一个 ChatGPT 式的问答小助手
本文首发于公众号:Hunter后端
原文链接:在 Windows 上利用Qwen大模型搭建一个 ChatGPT 式的问答小助手
最近 ChatGPT 式的聊天机器人比较火,可以提供各种问答功能,阿里最近推出了 Qwen1.5 系列的大模型,提供了各个参数版本的大模型,其中有一些参数量较小的模型,比较适合我们这种穷* 用于尝试一下手动运行大模型。
今天我们就使用 Qwen1.5 大模型来尝试一下,自己搭建一个问答小助手。
1、配置
首先介绍一下搭建的环境,8g 内存,4g GPU 显存,win10系统,所以如果配置等于或高于我这个环境的也可以轻松实现这一次的搭建过程。
下面是搭建成功后一些问答的效果展示:


其中,因为显存限制,我这边分别使用 Qwem1.5-0.5B-Chat 和 Qwem1.5-1.8B-Chat 进行测试,0.5B 版本占用显存不到 2g,1.8B 版本显存占用不到 4g,这个 B 表示的是模型使用的参数量,在我电脑上 0.5B 的版本推理速度要比 1.8B 的速度要快很多,但是某些问题的准确性没有 1.8B 高。
接下来正式介绍搭建过程。
2、环境安装
使用 Qwen 这个大模型需要用到 CUDA 相关驱动以及几个 Python 库,torch,transformers,accelerate 等。
1. CUDA
首先,确认 Windows 机器上是否有相关驱动,这里我们可以在 cmd 里输入 nvidia-smi 查看相应输出,比如我的输入如下:
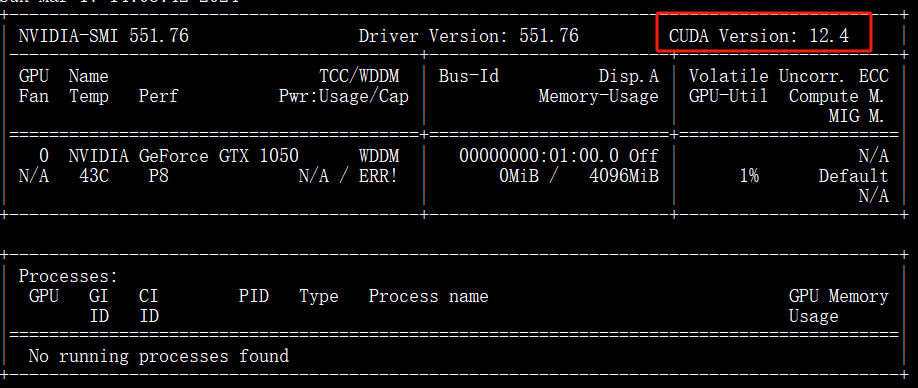
然后上张图里截出来的 CUDA Version 去下面这个地址下载 CUDA Toolkit:https://developer.nvidia.com/cuda-toolkit-archive
到这一步完成,相应的 CUDA 准备工作就 OK 了。
建议可以先看下下面这个链接,里面有完整的安装示意流程:Windows下CUDA安装
2. conda 环境准备
这里为了方便,我新建了一个 conda 环境,使用的 Python 3.10 版本
conda create -n qwen python=3.10
3. torch 库
为了使用 GPU,torch 库的版本需要是 cuda 版本的,在 Windows 版本下我直接安装其 whl 包,可以在下面的地址找到对应的版本:https://download.pytorch.org/whl/torch_stable.html。
这里我下载的是文件名是 torch-2.2.1+cu121-cp310-cp310-win_amd64.whl。
torch-2.2.1 表示的是 torch 的版本
cu121 表示的是 cuda 版本是 12.1,我们实际的 CUDA Version 是 12.4,没有最新的但是也能兼容
cp310 是 Python 的版本 3.10
win_amd64 则是 Windows 版本。
whl 包比较大,有 2 个多 g,下载后直接到对应的目录下执行下面的操作即可:
pip3 install torch-2.2.1+cu121-cp310-cp310-win_amd64.whl
4. transformers 库
transformers 库是使用大模型的基础库,这里注意下,Qwen1.5 版本的大模型是最近才出来的,所以 transformers 库需要比较新的才能支持,需要 >= 4.37.0
这里我们直接 pip3 install transformers 就会自动为我们安装最新的库,也可以直接指定这个版本。
5. accelerate 库
我在操作的过程中,还需要用到 accelerate 这个库,所以额外安装下:
pip3 install accelerate -i https://mirrors.aliyun.com/pypi/simple/
到这一步,我们的环境就安装好了,我们可以尝试一下是否可以正常使用 CUDA:
import torch
print(torch.cuda.is_available())
# True
输出为 True 则表示可以正常使用 CUDA。
3、下载模型
所有大模型的下载官方都会发布在 huggingface 网站上:https://huggingface.co/。
我们可以在上面搜索到目前所有发布的大模型,包括 Qwen 系列,百川系列,ChatGLM 系列,Llama 系列等。
我们可以下载下一步执行代码的时候直接指定模型名称,会自动为我们下载,但是我习惯于先将其下载下来,然后在本地指定路径进行调用。
这里我们可以去这两个地址下载对应的文件:
https://huggingface.co/Qwen/Qwen1.5-0.5B-Chat/tree/main
https://huggingface.co/Qwen/Qwen1.5-1.8B-Chat/tree/main
分别是 Qwen1.5 的 0.5B Chat 版本和 1.8B Chat 版本。
其中,最主要的文件是 model.safetensors,这个就是大模型本身,也就是我们运行的时候需要加载的文件,可以看到这两个地址的这个文件分别是 1g 多和 3g 多。
除此之外,还有一些必要的配置文件比如 config.json,一些词表的文件用于加载的时候做映射操作。
注意:上面的网址可能需要一些魔法操作,如果你没有魔法的途径,可以去魔搭社区找对应的版本,https://www.modelscope.cn/search?search=Qwen1.5
这里,下载的大模型文件列表如下图所示:

至此,我们所有的准备工作就完成了,接下来我们可以开始写代码进行问答操作了。
4、对话代码
我们需要先加载大模型:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
path = r"F:\\models\\Qwen1.5-0.5B-Chat"
model = AutoModelForCausalLM.from_pretrained(
path,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(path)
这里的 path 就是我们下载的大模型的本地文件路径。
接下来下面的代码就是进行对话的操作了:
prompt = "你是谁"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
# 我是来自阿里云的超大规模语言模型,我叫通义千问。我是一个能够回答问题、创作文字,还能表达观点、撰写代码的 人工智能模型。如果您有任何问题或需要帮助,请随时告诉我,我会尽力提供支持和解答。
1. 封装成函数
我们可以将上面下部分代码封装成函数,这样就可以每次直接调用函数来进行问答操作了:
def get_response(prompt):
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
然后可以直接调用函数进行问答:
get_response("如何学习Python?")
2. 保存历史进行多轮对话
接下来我们可以保存对话历史来进行多轮对话,以下是代码:
def run_qwen_with_history():
messages = [
{"role": "system", "content": "You are a helpful assistant."},
# {"role": "user", "content": prompt}
]
while True:
new_question = input("请输入你的问题:")
if new_question == "clear":
messages = [messages[0]]
continue
messages.append({"role": "user", "content": new_question})
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
messages.append({"role": "system", "content": response})
在这里执行这个函数之后,会在命令行里输出 请输入你的问题:,然后我们可以输入我们的问题,之后可以连续多轮输出,后台会记住我们之前的对话,从而实现多轮对话的功能。
5、总结
经过分别使用 0.5B 版本和 1.8B 的版本,在我电脑的配置里,0.5B 版本的输出会快一些,但是在某些问题回答的质量上不如 1.8B。
而 1.8B 版本答案质量相对较高,但是速度在 4g 显存的情况下,则非常慢。
以上就是本次使用 Qwen1.5 在 Windows 上搭建问答小助手的全过程,之后还可以将大模型提供接口操作,将其应用到 web 页面上,从而实现一个真正的 ChatGPT 式问答助手。
对于以上这些操作是直接使用的大模型,而真正要将其应用于生产,还需要对大模型进行微调,训练等一系列操作,使其更适用于实际场景,这些以后有机会再学习介绍吧。
如果想获取更多后端相关文章,可扫码关注阅读:

在 Windows 上利用Qwen大模型搭建一个 ChatGPT 式的问答小助手的更多相关文章
- 【数据库开发】在Windows上利用C++开发MySQL的初步
[数据库开发]在Windows上利用C++开发MySQL的初步 标签(空格分隔): [编程开发] Windows上在上面配置环境的基础上开展一个小demo链接数据库,没想到中间也出现了这么多的问题,简 ...
- 利用git+hugo+markdown 搭建一个静态网站
利用git+hugo+markdown 搭建一个静态网站 一直想要有一个自己的文档管理系统: 可以很方便书写,而且相应的文档很容易被分享 很方便的存储.管理.历史记录 比较方面的浏览和查询 第一点用M ...
- 利用Wamp在本地搭建一个wordpress站点
原文链接:利用Wamp在本地搭建一个wordpress站点 有时候我们会想搭建一个自己的站点,可是由于只是想自己访问,就不是很想为这个站点在买一个服务器和域名,那我们可能首先就想到把自己电脑当做服务器 ...
- 利用vue-cli配合vue-router搭建一个完整的spa流程
好文章备忘录: 转自:https://segmentfault.com/a/1190000009160934?_ea=1849098 demo源码:https://github.com/1590123 ...
- 技术人如何利用 github+Jekyll ,搭建一个独立免费的技术博客
上次有人留言说,技术博客是程序员的标配,但据我所知绝大部分技术同学到现在仍然没有自己的技术博客.原因有很多,有的是懒的写,有的是怕写不好,还有的是一直想憋个大招,幻想做到完美再发出来,结果一直胎死腹中 ...
- 利用@keyframe及animation做一个页面Loading时的小动画
前言 利用@keyframe规则和animation常用属性做一个页面Loading时的小动画. 1 @keyframe规则简介 @keyframes定义关键帧,即动画每一帧执行什么. 要使用关键帧 ...
- windows上利用dhcpsrv搭建DHCP服务器
起因是一个很奇葩的需求:乙方要远程升级仪器,用TeamViewer远程控制并ssh到仪器,但仪器内部IP地址没有写死,靠DHCP服务器获取.那么就要在PC建立DHCP服务器,用网线连接仪器,然后才能看 ...
- windows上JSP开发环境全搭建
JSP开发环境全搭建 最近需要用到JSP做项目,所以要配置JSP的开发环境,总结一下配置步骤以备以后再配置需要. 配置JAVA开发环境,配置JDK 下载JDK,在这里下载开发所需的JDK,可以根据自己 ...
- Windows上IOCP Socket事件模型管理
1.IOCP 2.使用IOCP 1)创建完成端口CreateIoCompletionPort: 2)向完成端口添加管理句柄与管理用户数据: 3)异步发送一个管理的事件请求: 4)开启工作线程来处理I ...
- NLP实践!文本语法纠错模型实战,搭建你的贴身语法修改小助手 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
随机推荐
- 关于行结束符(CR、LF)、回车、换行
CR(Carriage Return)表示回车 LF(Line Feed)表示换行 Dos和Windows采用回车+换行(CR+LF)表示下一行而UNIX/Linux采用换行符(LF)表示下一行苹果机 ...
- MySQL执行函数时报错:Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) for operation 'find_in_set'
执行函数时报错: Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8mb4_0900_ai_ci,IMPLICIT) f ...
- Python实现希尔排序、快速排序、归并排序
快速排序 快速排序(英语:Quicksort),又称划分交换排序(partition-exchange sort),通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所 ...
- 收集 VSCode 常用快捷键
快速复制行 Shift + Alt + ↑/↓ 都是往下复制行,区别是:按↓复制时光标会跟着向下移动,按↑复制时光标不移动. 向上/向下移动一行 Alt + ↑/↓ 删除整行 Ctrl + Shift ...
- diffstat命令
diffstat命令 diffstat命令根据diff的比较结果,统计各文件的插入.删除.修改等差异计量. 语法 diffstat [options] [files] 参数 -c: 输出的每一行都以# ...
- centos 安装nacos 并以后台服务形式启动
一.下载解压nacos tar -xvf nacos-server-1.2.0.tar.gz 二.持久化配置(mysql) 修改nacos/conf/application.properties文件, ...
- macOS搭建SonarQube
目录 前言 准备环境 下载安装包 解压路径:/usr/local 创建数据库 修改配置文件 配置环境变量 启动SonarQube 扫描项目 项目报告介绍 总结 前言 初到新公司,接手8-10个java ...
- 【Azure Function】在Function执行中遇见Timeout错误
问题描述 在Function执行中遇见Timeout错误: Microsoft.Azure.WebJobs.Host.FunctionTimeoutException /Timeout value o ...
- 【Azure 应用服务】App Service For Linux 环境中,如何修改 Nginx 配置中 server_name的默认值 example.com
问题描述 在App Service for Linux环境中,部署PHP应用,使用Nginx服务器.因为PHP应用中所有静态资源的URL使用的默认域名为 https://example.com:808 ...
- gopkg.in/go-playground/validator中比较有用的标签
- 忽略| 或omitempty 有则验证,空值则不验证dive 潜入到切片.数组.映射中,例如 NumList []int `validate:"len=2,dive,gt=18&q ...