近数据处理(NDP)——GaussDB(for MySQL)性能提升的秘密
摘要:云堆栈的深度集成是释放云数据库力量的关键,华为云在实现这一目标方面处于领先地位,正如GaussDB(for MySQL)所证明的那样。
本文分享自华为云社区《近数据处理(NDP),为GaussDB(for MySQL)性能提升“加冕”》,作者: GaussDB 数据库。

在上一篇文章《首席科学家为您揭秘:GaussDB(for MySQL)云栈垂直集成的力量有多大》我们介绍了GaussDB(for MySQL)的体系架构,这篇文章我们将重点介绍GaussDB(for MySQL)如何将查询处理卸载到存储层,我们将这一特性称之为近数据处理(Near Data Processing),简称NDP。
NDP出现的契机
在计算节点实例上执行查询操作首先需要将数据页面加载到InnoDB缓冲池(buffer pool)。相对传统数据库使用本地存储,云数据库需要通过网络获取数据,因此从存储节点读取页面数据的延迟要高得多。相比社区版MySQL,GaussDB(for MySQL)支持并行查询,可通过多线程并行将数据读取到缓冲池中,但当表数据量较大(包含数百万甚至更多的数据行),分析查询需要扫描大量数据时,将所需数据全部加载到缓冲池中,IO成本将变得非常高。因此,我们需要一种更优的方法来解决此问题。
我们的解决方案是基于GaussDB(for MySQL) 计算节点与存储节点之间的紧密集成,将部分查询处理操作下推至靠近数据的分布式存储系统,数据库术语中称为算子下推。通过这种方式,我们可以利用多存储节点的总带宽。在云环境中,存储系统包含数百节点,我们希望充分利用存储系统的可扩展性,同时避免网络成为性能瓶颈点。NDP允许部分查询处理以大规模并行的方式在存储节点执行,并显著的减少网络IO。
NDP有诸多好处,包括:
- 利用多租户大规模分布式云存储系统,在多节点并行处理数据
- 显著减少网络IO,只返回满足WHERE条件的行(过滤)和查询涉及的列(投影)或聚合操作的结果,而不是将完整的数据页面从存储节点返回至计算节点
- 避免大数量扫描导致经常访问的数据页面从缓存池中移除
那么存储层是如何处理的呢?
算子下推通常适用于全表扫描、索引扫描、范围查询等场景。WHERE条件可下推至存储层,当前支持的数据类型包括:
- 数值类型(numeric, integer, float, double)
- 时间类型(date, time, timestamp)
- 字符串类型(char, varchar)等
算子下推可以与计算节点的并行查询完美结合,从概念上讲,一个查询首先在计算层(垂直扩展)拆分为多个worker线程并行处理,每个worker线程均可触发算子下推。由于分布式存储中数据分布的策略,每个worker线程的负载将分配至存储系统的多个节点上(水平扩展),每个存储节点都有线程池处理算子下推请求。
查询是否启用算子下推,是在查询优化阶段,优化器根据统计信息和执行计划自动决策的。此外用户还可以使用 hint 来控制查询操作是否开启算子下推。
算子下推可以很好地处理冷数据,然而,GaussDB(for MyQL)是一个OLTP系统,通常包含并发更新操作。当前计算下推实现,MVCC处理仅在计算节点进行,存储节点只处理可见的行,针对无法判断可见性的行,原样返回至计算节点,通过undo-log回放出对应的数据。
通过算子下推,我们将获得怎样的收益呢?
以TPC-H标准测试集(scale factor: 100)为例,CPU:16核,内存: 128GB,计算节点数据库缓冲池大小设置为80GB,采用冷数据进行验证。
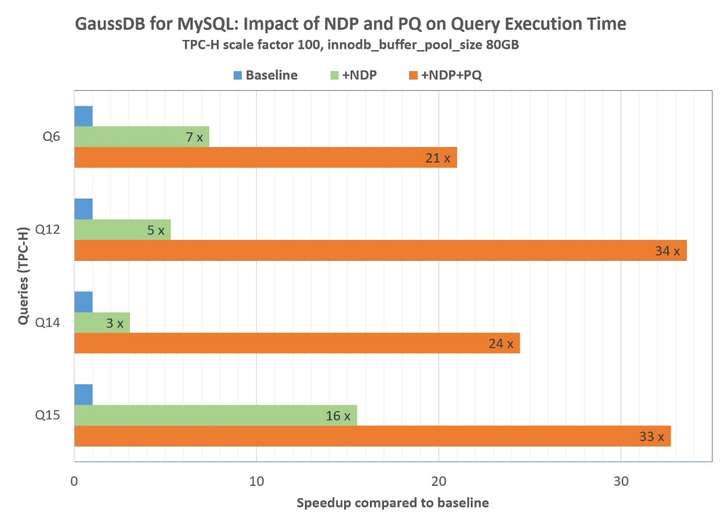
下图展示了TPC-H Q6, Q12, Q14, Q15 4 个Query的查询结果,均有20-40倍的性能提升。以Q12为例,只开启NDP,借助分布式存储算力和网络IO缩减,性能提升5倍,同时在计算节点开启并行查询,又获得7倍性能提升,总体提升约35倍,这个提升效果是非常显著的。
本文中提到的这些功能都可在实际生产环境中使用,而这只是开始,随着我们将更多计算推送到存储层,更多的查询将从此优化中受益,我们可以期待更大的性能提升。
如何启用NDP?
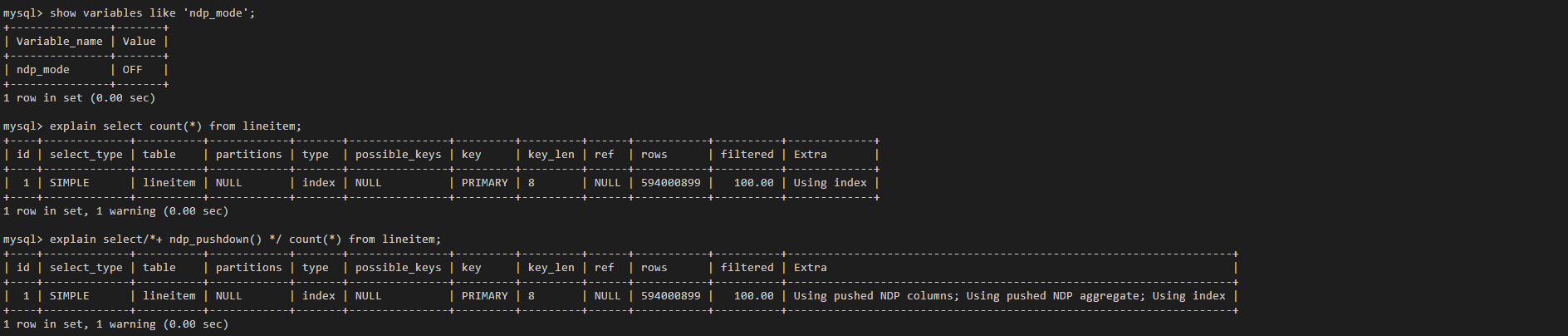
开启NDP开关,对当前Session生效,优化器自动判断是否进行计算下推。
mysql> show variables like 'ndp_mode';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| ndp_mode | ON |
+---------------+-------+
1 row in set (0.00 sec) mysql> explain select count(*) from lineitem;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
| 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using pushed NDP columns; Using pushed NDP aggregate; Using index |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)

通过hint方式,使NDP对当前Query生效。
mysql> show variables like 'ndp_mode';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| ndp_mode | OFF |
+---------------+-------+
1 row in set (0.00 sec) mysql> explain select count(*) from lineitem;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+
| 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using index |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------+
1 row in set, 1 warning (0.00 sec) mysql> explain select/*+ ndp_pushdown() */ count(*) from lineitem;
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
| 1 | SIMPLE | lineitem | NULL | index | NULL | PRIMARY | 8 | NULL | 594000899 | 100.00 | Using pushed NDP columns; Using pushed NDP aggregate; Using index |
+----+-------------+----------+------------+-------+---------------+---------+---------+------+-----------+----------+-------------------------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
挑战与今后方向
NDP有诸多好处,但它也有一些技术挑战需要我们解决。如分布式存储系统为多租户共享,为了避免不同租户对资源争抢使用,我们需要实现单租户级的资源管控。另外是优化器决策使用NDP的时机,需结合触发网络IO读取的数据量以及已缓存在缓冲池中的数据量综合考虑。
GaussDB(for MySQL)是一款云原生数据库,该体系结构支持极其强大和灵活的NDP框架。未来,我们计划利用此框架不仅仅是做查询处理,还将进一步扩展存储层中的数据库功能,这些功能可以与查询下推结合使用。我们相信,云堆栈的深度集成是释放云数据库力量的关键,华为云在实现这一目标方面处于领先地位,正如GaussDB(for MySQL)所证明的那样。
请大家保持关注,我们后续将会给大家带来更多精彩技术分享。也欢迎大家前往华为云官网,了解更多GaussDB(for MySQL)详情:https://www.huaweicloud.com/product/gaussdb_mysql.html
近数据处理(NDP)——GaussDB(for MySQL)性能提升的秘密的更多相关文章
- 【经验】GaussDB(for MySQL)性能优化 —— 日志的“快递驿站”
GaussDB(for MySQL)数据库在写入性能上,在业界同类产品中是最好的,这主要得益于GaussDB(for MySQL)在MySQL内核方面的诸多优化.其中有一项从“送快递”得来灵感的优化— ...
- 使用golang插入mysql性能提升经验
前言 golang可以轻易制造高并发,在某些场景很合适,比如爬虫的时候可以爬的更加高效.但是对应某些场景,如文件读写,数据库访问等IO为瓶颈的场合,就没有什么优势了. 前提基础 1.golang数据库 ...
- 10个提升MySQL性能的小技巧
从工作量分析到索引的三条规则,这些专家见解肯定会让您的MySQL服务器尖叫. 在所有的关系数据库中,MySQL已经被证明了完全是一头野兽,只要通知停止运行就绝对不会让你多等一秒钟,使你的应用置于困境之 ...
- paip.提升性能---mysql 性能 测试以及 参数调整.txt
paip.提升性能---mysql 性能 测试以及 参数调整.txt 作者Attilax 艾龙, EMAIL:1466519819@qq.com 来源:attilax的专栏 地址:http://b ...
- MySQL 8.0 —— CATS事务调度算法的性能提升
原文地址:https://mysqlserverteam.com/contention-aware-transaction-scheduling-arriving-in-innodb-to-boost ...
- nginx mysqlnd驱动引擎提升mysql性能
nginx mysqlnd驱动引擎提升mysql性能 前期要安装 mysql mysqli pdo_mysql libiconv 1 先去PHP官网下个 php-5.6.29.tar.gz wget ...
- huge page 能给MySQL 带来性能提升吗?
最近一直在做性能压测相关的事情,有公众号的读者朋友咨询有赞的数据库服务器有没有开启huge page,我听说过huge page会对性能有所提升,本文就一探究竟.对过程没有兴趣的可以直接看结论. 二 ...
- 我是如何将一个老系统的kafka消费者服务的性能提升近百倍的
☞☞☞ 我是如何将一个老系统的kafka消费者服务的性能提升近百倍的 ☜☜☜ ○○○○○○○○○○○○○○○ 大家好,又见面了~ kafka作为一种高吞吐量的分布式发布订阅消息系统,在业务系统中被广泛 ...
- 海量数据分析更快、更稳、更准。GaussDB(for MySQL) HTAP只读分析特性详解
本文作者康祥,华为云数据库内核开发工程师,研究生阶段主要从事SPARQL查询优化相关工作.目前在华为公司参与华为云GaussDB(for MySQL) HTAP只读内核功能设计和研发. 1. 引言 H ...
- kettle大数据量读写mysql性能优化
修改kettleDB连接设置 1. 增加批量写的速度:useServerPrepStmts=false rewriteBatchedStatements=true useCompressio ...
随机推荐
- CF B. Gardener and the Array
B. Gardener and the Array 思路:只要找到一个c他的每一位均在除了它的集合中出现过即可 这题T了2发,用来multiset,注意multiset大的时间复杂度是O(K + lo ...
- mac os 升级到13后,系统免密失败
# sudo vim /etc/ssh/ssh_config # 添加以下内容 PubkeyAcceptedKeyTypes +ssh-rsa
- P9481 [NOI2023] 贸易 题解
题目链接 题目要求我们求出任意两点间最短路径之和,由于图比较特殊,除树边外只有祖先到其子树内的边,我们首先考虑最短路径有没有什么特殊性质. 注意到两点之间的最短路分为一下三种: 节点到其祖先的最短路: ...
- C#.NET 国密SM4 CBC 对称加解密 与JAVA互通 ver:20231103
C#.NET 国密SM4 CBC 对称加解密 与JAVA互通 ver:20231103 .NET 环境:.NET6 控制台程序(.net core). JAVA 环境:JAVA8,带maven 的JA ...
- 聊聊魔塔社区MGeo模型的部署与运行
从现今与今后的发展来看,单一的业务不再仅仅依靠于传统的技术开发,而是应该结合AI模型来应用.实践.只有这样,才能更数智化,更高效化,更贴合时代的发展. 魔塔 社区就类似国外的Hugging Face, ...
- 学生开发者勇担青年使命,用AI守护少数人的“视界”
本文分享自华为云社区<[先锋开发者云上说]学生开发者勇担青年使命,用AI守护少数人的"视界">,作者:华为云社区精选 . 青年动人之处,在于他们的勇气,和非凡的创造探索 ...
- 一个小型markdown读写编辑器推荐
在作业完成时我和很多同学们发现并没有很好地利用博客园里面自带的markdown标记语法的形式完成作业 因此我在网上自己搜索发现了这款软件 下载地址 在帮助里可以学到一些简单的使用形式 可以方便编辑已有 ...
- Kubernetes 漫游:etcd
概述 etcd 是一个基于 Raft 协议实现.开源的.分布式的键值存储系统.主要用于在分布式系统中提供强一致性和高可用性的数据存储. etcd 在 Kubernetes 中的作用如下: 集群状态数据 ...
- MySQL-管理员root@'locahost' 丢失,怎么处理?
版权声明:原创作品,谢绝转载!否则将追究法律责任. ----- 作者:kirin 跳过授权表 ----> 不开启验证功能(无密码登录) --skip-grant-tables 阻止所有tcp/i ...
- 神经网络入门篇:详解核对矩阵的维数(Getting your matrix dimensions right)
核对矩阵的维数 当实现深度神经网络的时候,其中一个常用的检查代码是否有错的方法就是拿出一张纸过一遍算法中矩阵的维数. \(w\)的维度是(下一层的维数,前一层的维数),即\({{w}^{[l]}}\) ...