DP的各种优化小结
动态规划算法(简称动规,DP),是IO中最为常见的,也是最为重要的算法之一。这也就意味着,在各种题目与比赛中它会有很多稀奇古怪的算法和优化,时不时地在你的面前出现一个TLE,MLE和RE来搞你的心态。
所以,对于DP的优化是尤为重要的。
那么首先我们要看一看我们DP都做了些什么:
DP(个人认为所有的算法都是这样)就是统一处理相同的情况、统一省去不可能的情况。最典型的例子——过河卒,就是把能够走到每一个坐标的情况统一处理,对于会走到马的位置的不可能的情况统一省去。
那么显然,对于DP的优化也都是在统一处理相同情况和统一省去不可能情况这两个方面进行的优化了
单调队列
单调队列优化DP是一种十分常见的优化方式,假如我们现在的转移方程如下
\(f_i=A*\min\limits_{0<j<i}\{f_j+F(j)\}+G(i)\)
其中 \(A\) 是某个常数, \(F(x)\) 和 \(G(x)\) 关于 \(x\) 的函数,我们会发现,在枚举 \(j\) 的时候,其实与 \(i\) 并没有必然关系,即对于所有的 \(j\) 无论在枚举多少的时候,都是一样的——这就是相同的情况。
相同情况统一处理,所以我们在每次处理了一个 \(i\) 之后,我们就可以把它统一维护在一个最小值 \(minn\) 里面,之后的每一个 \(i\) 只需要调用 \(minn\) 即可。
然后,我们再来思考另一种情况,如果 \(j\) 多出了一个限制:
\(f_i=A*\min\limits_{h(i)<j<i}\{f_j+F(j)\}+G(i)\)
\(h(x)\) 是关于 \(x\) 的单增函数。这是,如果我们还是想之前一样一个最小值,我们会意识到,到后面我们的 \(j\) 会小于 \(h(i)\) 的范围,所以,我们不能单纯的这样维护答案了
这时候,单调队列就派上用场了,我们在队列里面维护所有的 \(f_i\) 但我们只维护其中单调递减,队头的 \(i\) 值如果已经超过了可行的范围,把它弹出去即可。
斜率优化
斜率优化就是单调队列的升级版,解决的转移方程形如
\(f_i=A*\min\limits_{h(i)<j<i}\{f_j+F(j)+F'(i)*G'(j)\}+G(i)\)
我们多了两个函数,保证 \(F'(i)\) 单调同时 \(G'(j)\) 单增,\(j\) 的值也和 \(i\) 有关了,不能单纯的使用单调队列优化了。这时候,需要想一些其他的方法,而这种方法,就叫做斜率优化。
我们考虑前面的单调队列,之所以能够用这种贪心的做法,是因为转移方程在某种意义上是和 \(i\) 无关的,比如我们记 \(g_j=f_i-G(i)\) ,就可以发现,整个转移变成了至于 \(j\) 有关的了。
但是我们上述的转移方程似乎不行,因为你找不到一个方式,使得转移方程只和 \(j\) 有关。
其实,要说有,还是有一些的,也就是 \(f_j+F(j)\) ,唯一阻碍我们的,是后面的 \(F'(i)*G'(j)\) 在妨碍这我们,那我们先从数学的角度来看看这个式子:
加入对于某一个值 \(x\) ,是在转移 \(f_i\) 时的最小值,也就是说 \(\forall h(i)<x'<i,x' \ne x:f_{x'}+F(x')+F'(i)*G'(x')>f_x+F(x)+F'(i)*G'(x)\)
令 \(F''(x)=f_x+F(x)\)
移项得 \(F'(i)*[G'(x)-G'(x')]<F''(x')-F''(x)\)
当 \(x'<x\) 时,\(F'(i)<\frac {F''(x')-F''(x)}{G'(x)-G'(x')}\)
当 \(x'>x\) 时,\(F'(i)>\frac {F''(x')-F''(x)}{G'(x)-G'(x')}\)
我们观察上面个的式子,由于前提说 \(F(i)\) 是单调的,也就意味着如果对于某个 \(x\) ,它在 \(i\) 时因为 \(x+1\) 更优不是最小值,那么在后面的 \(i+1,i+2,\dots\) 都不会成为最小值,因为它至少都会被 \(x+1\) 限制。这一点和上面的单调队列是一样的,也就意味着,这种情况下的转移方程有可能可以用单调队列维护。
可能不是很明显,但我们把式子两遍取负:
\(\begin{cases}-F'(i)>\frac {F''(x')-F''(x)}{G'(x')-G'(x)},x'<x\\-F'(i)<\frac {F''(x')-F''(x)}{G'(x')-G'(x)},x'>x\end{cases}\)
再回过头来看看上面的式子—— \(\frac {F''(x')-F''(x)}{G'(x')-G'(x)}\) ,长得像什么,很像一次函数的斜率: \(k=\frac {y_1-y_2}{x_1-x_2}\) ,那么前面两个不等式中右式,就可以看作是 \((G'(x),F''(x))\) , \((G'(x'),F''(x'))\) 这两个点所在的直线的斜率。
这时候我们就可以考虑把这些点在平面直角坐标系里面画出来(假设都在一象限)
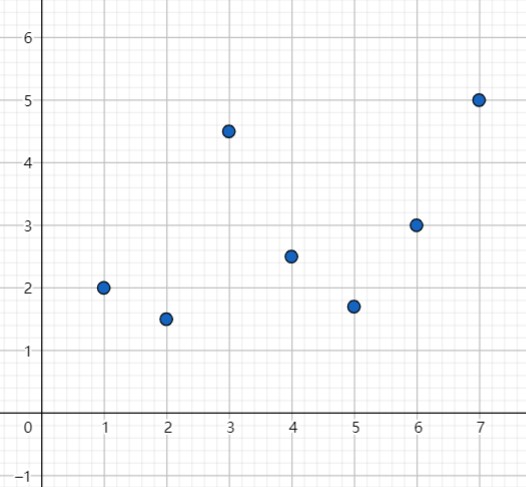
就不如说这 \(7\) 个点,它们之间会存在 \(21\) 条直线,如果是 \(n\) 个点,一般情况下也就是 \(\frac {n(n-1)}{2}\) 条不同的斜率,那我们应该怎么维护呢?
既然我们都已经使用了图像,我们就接着拿图像来考虑这道题。
如果要满足转化出来的不等式它的斜率应该要满足一个区间,例如图中的点 \((5,1.7)\) ,我们将和它和其他六个点连起来:
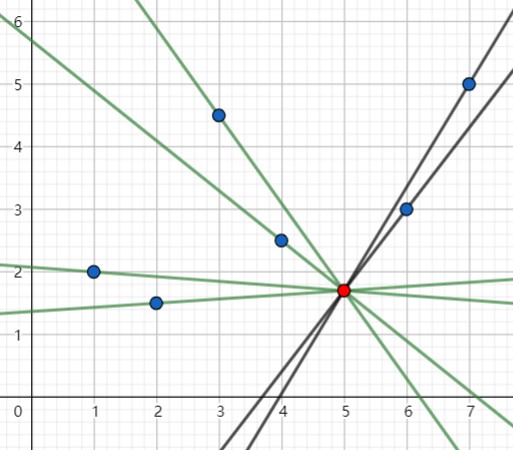
所有满足条件的 \(F'(i)\) ,斜率要大于所有绿色的线,小于所有黑色的线
我们会发现两点:这个区间应该是一个连续的,不可能是几段不连续区间的并;它的区间只会和某两条线段有关,这两条线段对应的点必然在 \(x\) 的左右各有一个。
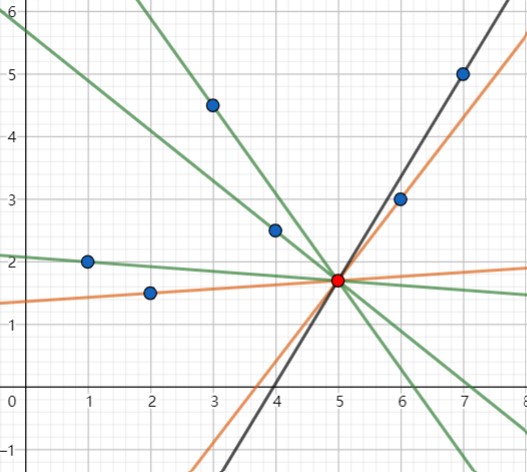
对于上图就是这两条标橙的直线。对于没有标橙的点,将 \(-F'(i)\) 与它们比较是没有意义的,和它们比较并不能够代表 \(x\) 是否符合条件;但是标为橙色的线段却可以,因为它俩就是 \(-F'(i)\) 满足条件的上下界呀!
显然,这两个值就会是 \(x\) 与比它小的 \(x'\) 构成的斜率中最大的( \(\max\limits_{x'<x}\{\frac {F''(x')-F''(x)}{G'(x')-G'(x)},x'<x\}\) ),和 \(x\) 与比它大的 \(x'\) 构成的斜率中最小的( \(\min\limits_{x<x'}\{\frac {F''(x')-F''(x)}{G'(x')-G'(x)}\}\) )
那么,我们只要能够快速地维护每个点地这两个值,我们就可以快速的判断 \(x\) 是不是我们需要转移的来源。
对于某些点,无论如何都轮不到它们,也就是当上下界构成不了区间的,也就是当满足 \(\max\limits_{x'<x}\{\frac {F''(x')-F''(x)}{G'(x')-G'(x)},x'<x\}>\min\limits_{x<x'}\{\frac {F''(x')-F''(x)}{G'(x')-G'(x)}\}\) 的时候
就比如里面的点 \((4,2.5)\) ,不存在一个斜率,比所有的绿色直线大,比所有黑色直线小,那么他必然不能成为转移的来源

现在,我们就需要考虑有哪些点是不能够成为转移的来源,那些是可以成为转移的来源的。
比如说 \((4,2.5)\) ,找到理应成为他的“上下界”的两条直线对应的两个点——他们的连线是在 \((4,2.5)\) 下方的。
对于所有的点,都可以试一下,所有不可能的都是这种情况。
假设我们把所有线都连起来,那么能够成为转移的,就是它的下方没有其他连线的点,而这些点,会构成一个下凸壳:
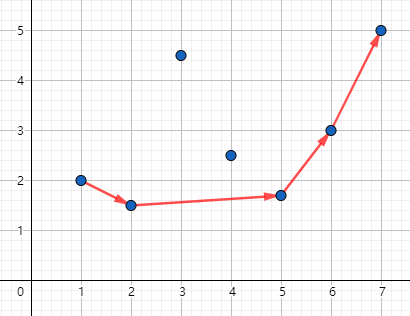
那么,我们要维护的就是一个下凸壳了
这就是斜率规划的思想,剩下的就是代码实现
栗子:CF311B Cats Transport,Luogu P2120 [ZJOI2007] 仓库建设,Luogu P1721 [NOI2016] 国王饮水记
四边形不等式
这个我还不会
矩阵加速DP
这个东西只要会出现在图上DP和数位DP中,主要是处理重复出现的大量转移。
先抽象地看,如果转移方程是
\(f_{i,j}=\sum\limits_{k=1}^n a_{k,j}*f_{i-1,k}\)
发现转移方程中唯一的数 \(a_{j,k}\) 与我们目前转移的次数 \(i\) 无关,而且我们可能需要求的是 \(f_{n,10^{12}}\) 一个一个枚举时间直接起飞了。
我们可以思考一个事情:既然我们知道每一次的转移都是固定的,那可不可以用什么神奇的技巧来批量地处理他们呢?
有什么东西是可以从 \(n\) 个数转移到 \(n\) 个数,还能够满足统一处理的呢——矩阵。
如果我们把所有 \(f_{i,j},1\leqslant j\leqslant n\) 用矩阵乘法的形式表示出来,会怎么样呢?
\(\begin{pmatrix}f_{i,1}&f_{i,2}&\dots&f_{i,n}\end{pmatrix}=\begin{pmatrix}f_{i-1,1}&f_{i-1,2}&\dots&f_{i-1,n}\end{pmatrix}\begin{pmatrix}a_{1,1}&a_{1,2}&\dots&a_{1,n}\\a_{2,1}&a_{2,2}&\dots&a_{2,n}\\\dots&\dots&\dots&\dots\\a_{n,1}&a_{n,2}&\dots&a_{n,n}\end{pmatrix}\)
那么我们应该怎么批量处理呢?众所周知,矩阵满足结合律,但不满足交换律
如果我们即、记\(F_i=\begin{pmatrix}f_{i,1}&f_{i,2}&\dots&f_{i,n}\end{pmatrix}\),\(A=\begin{pmatrix}a_{1,1}&a_{1,2}&\dots&a_{1,n}\\a_{2,1}&a_{2,2}&\dots&a_{2,n}\\\dots&\dots&\dots&\dots\\a_{n,1}&a_{n,2}&\dots&a_{n,n}\end{pmatrix}\)
那么 \(F_n=F_1*A*A*\dots*A(n-1个A)=F_i*A^{n-1}\)
\(A^{n-1}\) 就用矩阵快速幂就可以了
举几个栗子
Luogu P6772 [NOI2020] 美食家
首先不考虑美食节,发现地点小于 \(50\) 个,可以用邻接矩阵来存,邻接矩阵就是矩阵。但是在图上面跑矩阵快速幂,我们需要保证每一条边长度均为 \(1\) ,不然不能满足我们上面的公式——从 \(F_i\) 推到 \(F_{i+1}\) ,因为对于长度为 \(w\) 的边,是可以从 \(F_i\) 直接推到 \(F_{i+w}\) 的。
发现数据中的边长均为 \(1\) 到 \(5\) 如果我们能把大于 \(1\) 的边拆成若干个长为 \(1\) 的边——拆点!!!
每一个点我们看做 \(5\) 个点,他们之间有 \(4\) 条长为 \(1\) 的边,这不就全是长度为 \(1\) 的边了吗?
剩下的就是矩阵快速幂的问题了。
然后考虑美食节:我们可以从初始时间到第一个美食节,从第一个美食节到第二个美食节……以此类推。
Luogu P2106 Sam数
这种题目和其他的数位DP是不一样的,因为你的main函数不会是这样的:
int main()
{
scanf("%lld %lld",&l,&r);
cout<<solve(r)-solve(l-1);
return 0;
}
他只让你求长度为 \(len\) 的Sam数!
我们想要求解有 \(i\) 位,最高位为 \(j\) 的Sam数有多少个(可以有前导零)。所以我们就可以设计出这样的10阶矩阵了。
Lougu P3193 [HNOI2008]GT考试
这是数位DP+KMP的神奇算法
我们考虑什么样的准考证号是吉利的——就是匹配不到不吉利的字串,什么样的准考证号匹配不到不吉利的字串的,如果我们用字符串匹配的思维去考虑,就是在匹配的过程中一直在失配,直到匹配串的最后,都没有匹配成功。那么对于匹配串到第 \(i\) 位,模式串匹配到第 \(j\) 位的所有情况,在后面的处理中就是完全一样的——相同的情况统一处理,我们就的状态就出来了: \(f_{i,j}\) 表示匹配串扫到了第 \(i\) 位,模式串匹配到第 \(j\) 位的所有情况。
这个失配和适配的过程可以提前处理成一个 \(len(M)\) 阶矩阵,过程就是假设模式串匹配到第 \(j\) 位,下一位的匹配串是 \(k\) ,它会跳到哪里。
然后就是快速幂了
树形DP合并子树的优化
在树形DP的问题中,都会是处理了每个节点的子树之后,通过子树的DP值来得到父亲节点的DP值
但是如果在处理了所有的字串之后,我们再去求父节点的DP值,这样子很容易TLE,因为这样子会有很多冗余的枚举
比如就拿背包问题为例,如果统一处理所有的状态,转移方程会是这样的:
\(f_{i,u}=\sum\limits_{\sum\limits_{l=1}^nk_l=i}\prod\limits_{i=1}^n f_{k_l,v}\)
从这个炸掉了的公式之中,我们不难发现,这个方法是极劣的,它的复杂度是 \(O(k^n)\) 的,其中 \(k\) 是背包容量, \(n\) 是子树个数
这其中我们会发现有很多重复的部分,如果我们这个节点有 \(4\) 个子树,我们前 \(2\) 个子树选 \(i\) 重量的物品和后 \(2\) 个子树选 \(j\) 重量的物品,这两个状态数量是相对独立的,不会受到对方的影响,但是,在上面的公式中,很显然被处理了很多次,这不符合我们重复的情况统一处理的思想。
如果我们先合并两个子树,也就意味着这两个子树的状态会在后面的处理之中被统一起来,对于后面的处理他们就可以被看做数一颗子树,不用再分开了。
我们可以把节点的DP状态的描述修改一下,从“以这个节点为根节点的子树中……的数量/最大值/……”变成“到目前位置,根节点以及所有它遍历过的子树中……的数量/最大值/……”
这样,我们每次合并的子树数量从 \(n\) 下降到了 \(2\),重复进行 \(n\) 次,复杂度降到了 \(O(nk^2)\)
栗子:Luogu P4362 [NOI2002] 贪吃的九头龙
线段树合并
上面的树形DP优化中,有的时候那个复杂度并不是很优,对于有些树形DP,这样的复杂度难以接受的。
我们来看其中的一种,后面的转移都将会是两个子树的合并。
考虑合并根为 \(u\) 和 \(v\) 的子树的时候,如果得到这样的转移方程:
\(f_{u+v,i}=f_{u,i}(sum_{v,i}+A)+f_{v,i}(sum_{u,i}+B)\)
其中 \(sum_{t,k}=\sum\limits_{i=1}^kf_{t,i}\)
也就是一半满足 \(/max\) 卷积或是 \(/min\) 卷积时。
我们要在顺序合并的过程之中维护两个前缀和,这样的复杂度将会是 \(O(nk)\) , \(n\) 为子树大小, \(k\) 为DP第二位上界。
同时,这样的问题都会有一个特点:每一个初始有值的叶子,它一般都会只有一个有值,其他的都是 \(0\) 。
由于初始值的稀疏,在合并子树的时候,我们可能会遇到一段转移中, \(f_{u,i}\) 和 \(f_{v,i}\) 中只有一个有值,另一个是 \(0\) 。
加入某一段中 \(f_{v,i}=0\) ,转移方程就会退化,变成 \(f_{u+v,i}=f_{u,i}(sum_{v,i}+A)+0\) 。如果是如此,这一整段的转移变成了——给 \(f_{u,i}\) 乘一个 \((sum_{v,i}+A)\) ,与此同时,因为在这一段里面,所有的 \(f_{v,i}=0\) ,前缀和的每一更新都只会加上一个 \(0\) ,也就是说,在这一整段里面,我们给每个 \(f_{u,i}\) 乘上的系数应该是相等的。如果我们能用一次操作来完成整个相乘的过程,那么时间复杂度就大大优化了。
我们就需要考虑用一个数据结构来维护区间乘——这不就是线段树么,线段树似乎也同时解决了前缀和的问题。
顺水推舟,我们能不能也用线段树来维护,或者说是优化子树的合并问题——这不就是线段树合并么?
我们来简略思考一下合并的过程:
如果两棵线段树在某处都有值,说明在这个区间里面存在 \(f_{u,i}\) 和 \(f_{v,j}\) 有值,那我们就递归它的左右孩子
如果只有一个线段树有值,说明另一个子树的DP值在这一段均为 \(0\),可以直接打上有值的那一部分需要的系数
我们先合并左孩子,再合并右孩子。这样在合并的过程就能够同时处理掉前缀和。
最后一个问题,空间怎么办?动态开点的思想即可。
栗子:Lougu P6773 [NOI2020] 命运,Lougu P5298 [PKUWC2018]Minimax
WQS二分
这个知识点并不仅局限于DP,在很多次数限制类题目里都可以使用
我们来思考几个问题:
- 在一个序列中取出若干段,使得加和最大。
很显然,这题是一个简单的贪心,因为我们没有对段做出任何其他的要求。 - 将一个非负序列分成若干段,最小化 \(\sum\limits_{j=1}^k\left(\sum\limits_{i=l_j}^{r_j}a_i+1\right)^2\) 。
这就是斜率优化的板子类题目 - 求一棵树的最小生成树。
Kruskal即可
这些问题都很好解决,但是给他们加上了一些条件之后,就不一样了:
- 在一个序列中取出m段,使得加和最大。
- 将一个非负序列分成m段,最小化 \(\sum\limits_{j=1}^k\left(\sum\limits_{i=l_j}^{r_j}a_i+1\right)^2\) 。
- 求一棵树的最小生成树,其中点1的度数为m。
是不是一下子不知道怎么搞了,
前两个还可以给DP加上一维,在时间复杂度上多出一个m,还能勉强搞一搞,但第三个是真的不好下手。
那我们先来分析一下为什么在加了“m段”这个限制之后,题目变难了很多呢?
不难发现,我们原来的三个题目的算法都是和分的段数或点的度数无关的,或者说是默认不定的。因为在这些处理的过程中,我们并没有维护段数,也没有办法维护段数。
而这些情况下,我们的做法往往是贪心的算法或者优化,因为不需要维护段数是无后效性最典型的特点之一。
但一旦加了段数,也就意味着前面去了很多段的时候看起来很优,但是当我们继续推进下去的时候,可能就有因为前面取得太多而付出代价。
有了后效性,就被迫让我们再加一维来层层计算,去掉段数的干扰。
我们现在需要思考的就是如何能让段数加入我们的贪心,使得它不会有后效性。
假如我们每取一段,需要额外付出一个远大于其他变量的常数,则只取1的时候远优于只取2的时候,我们就可以把段数锁定到1;
假如我们每取一段,就会付出一个远大于其他变量的常数的相反数,则每多取一段,就一定由于少去一段,我们就可以把段数固定到最大。
这是不是意味着,我们能够找到一个常数 \(k\) ,使得 \(Ans+p\times k\) 在 \(p=m\) 时最优,其中 \(Ans\) 为不加段数限制的答案, \(p\) 为这个答案对应的段数。
答案是可以,但它仍然要满足某些条件。
我们再来观察一下刚才想象的那个式子: \(Ans+p\times k\) 一个数加上另外两个数的乘积——一次函数!
那让我们请出计算几何:假设对于分成 \(i\) 段,我们有最小的答案 \(g(i)\) ,我们考虑所有点 \((i,g(i))\) 构成的凸壳(如果不是凸壳就会存在某一个点,导致它无论 \(k\) 为多少都不能取到最值)。
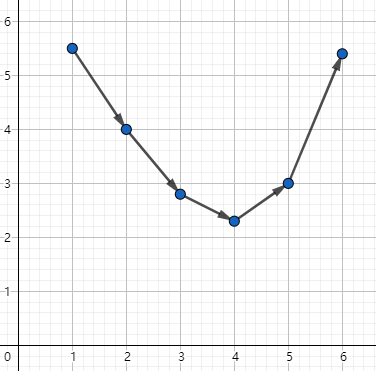
我们先假定每分一段的代价是 \(p\) ,那么对于分成 \(i\) 段,它的最小值就是 \(Ans_i+p\times i\) ,那么对于所有 \(i\) 中的最大值,一定是可以在短时间内求解,同时得到它的段数,如图:
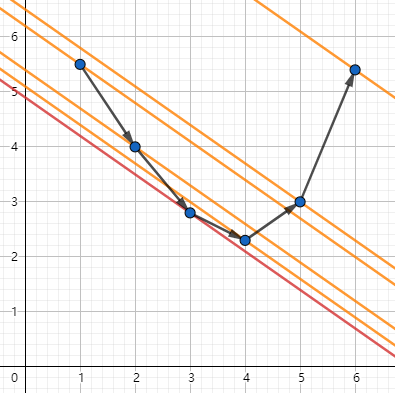
在这里面,取过每个点且斜率为 \(-k\) 的直线,每一个橙色直线的截距对应的值就是 \(g(i)+k\times i\) ,而其中最小值对应的就是红色的直线,那么我们就能够轻松地知道对于这个 \(i_0\) 的 \(g(i_0)\) 了。
由于凸壳的性质,每一个 \(i\) ,也就是每一个顶点都会对应在某一段斜率里面为所有中的最小值,这是我们只要想办法找到合适的斜率让这个对应的最小值刚好是我们要求的 \(m\) 段即可。
那么显而易见 \(m\) 会在目前的 \(i_0\) 的左侧或右侧。
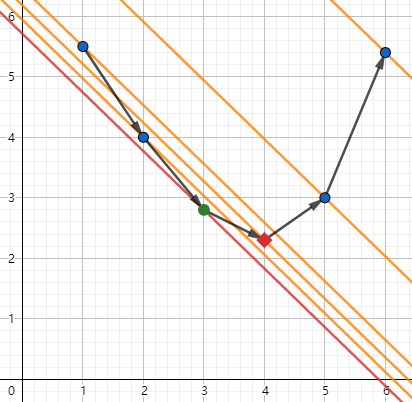
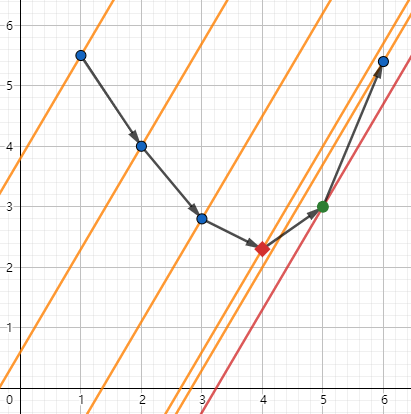
那么很直观,我们确定了 \(m\) 和 \(i_0\) 的大小关系,就能够确定 \(k\) 和目标区间 \([L,R]\) 的关系了,接下来就是二分查找了。
它的复杂度是 \(O(单次DP\times log(精度))\) 的,绝大多数情况下优于加一维DP。
栗子:Luogu P4983 忘情,[国家集训队]Tree I(WQS二分,非DP)
FFT优化
加入对于这样一个问题:在以 \(i\) 为根的子树中取 \(j\) 个点的包含根节点的连通块的方案数 \(f_{i,j}\) 。
考虑两个孩子 \(u,v\) 到父亲 \(fa\) 的转移:\(f_{fa,j}=\sum\limits_{i=0}^{j-1}f_{u,i}\times f_{v,j-i-1}\) 。
这就是很显然的卷积形式,所以我们考虑母函数( \(k\) 为上界,可能是题目要求的选树大小,或是整棵树的大小): \(F_{i}(x)=\sum\limits_{j=0}^kf_{i,j}x^j\) 。
那么 $ F_{fa}(x)=F_u(x)\times F_v(x)\times x+x $ 这个过程可以用FFT优化,单次转移时间复杂度为 \(O(klogk)\) ,那么有 \(n\) 次合并,时间复杂度就是 \(O(nklogk)\) 的。
这在可以FFT的题目里比前面 \(O(nk^2)\) 的更进了一步。
其他
有的时候,DP的过程之中挂掉的不是时间,而是空间,这一类题目又会有一个特点——有很多没有用的空间,想一想也是,如果时间能够但是空间过不了,而空间又被成分利用了,这基本上就不是DP的题了,不然就是状态设计的不好。
那么这种时候,我们可以考虑动态的开空间,哪一个位置要填,我们就给它开一个,具体的实现方法有三种:STL,链表和动态开点线段树
栗子:Lougu P5468 [NOI2019] 回家路线
这道题目是一道明显的斜率优化的题目,状态设计有两位 \(f_{i,t}\) 表示第 \(t\) 时刻在 \(i\) 车站烦躁值的最小值,空间复杂度是 \(O(nt)\) 的,反手看一眼数据范围 \(n\leqslant 10^6\) \(t\leqslant 10^3\) 空间是 \(10^9\) 的量级, \(4*10^9Byte\approx3814.7MB\),你可以优雅地MLE了。
但是,因为可行的转移只会有 \(2*10^5\) 次,所以我们可以用链表或者STL来处理掉这个问题。
剩下的就是细节问题了。
DP的各种优化小结的更多相关文章
- Luogu 2627 修建草坪 (动态规划Dp + 单调队列优化)
题意: 已知一个序列 { a [ i ] } ,求取出从中若干不大于 KK 的区间,求这些区间和的最大值. 细节: 没有细节???感觉没有??? 分析: 听说有两种方法!!! 好吧实际上是等价的只是看 ...
- [poj3017] Cut the Sequence (DP + 单调队列优化 + 平衡树优化)
DP + 单调队列优化 + 平衡树 好题 Description Given an integer sequence { an } of length N, you are to cut the se ...
- dp的斜率优化
对于刷题量我觉得肯定是刷的越多越好(当然这是对时间有很多的人来说. 但是在我看来我的确适合刷题较多的那一类人,应为我对知识的应用能力并不强.这两天学习的内容是dp的斜率优化.当然我是不太会的. 这个博 ...
- HDU 2829 区间DP & 前缀和优化 & 四边形不等式优化
HDU 2829 区间DP & 前缀和优化 & 四边形不等式优化 n个节点n-1条线性边,炸掉M条边也就是分为m+1个区间 问你各个区间的总策略值最少的炸法 就题目本身而言,中规中矩的 ...
- DP的四边形优化
DP的四边形优化 一.进行四边形优化需要满足的条件 1.状态转移方程如下: m(i,j)表示对应i,j情况下的最优值. w(i,j)表示从i到j的代价. 例如在合并石子中: m(i,j)表示从第i堆石 ...
- CSP 201612-4 压缩编码 【区间DP+四边形不等式优化】
问题描述 试题编号: 201612-4 试题名称: 压缩编码 时间限制: 3.0s 内存限制: 256.0MB 问题描述: 问题描述 给定一段文字,已知单词a1, a2, …, an出现的频率分别t1 ...
- Codevs 3002 石子归并 3(DP四边形不等式优化)
3002 石子归并 3 时间限制: 1 s 空间限制: 256000 KB 题目等级 : 钻石 Diamond 题目描述 Description 有n堆石子排成一列,每堆石子有一个重量w[i], 每次 ...
- [Codeforces712D] Memory and Scores(DP+前缀和优化)(不用单调队列)
[Codeforces712D] Memory and Scores(DP+前缀和优化)(不用单调队列) 题面 两个人玩游戏,共进行t轮,每人每轮从[-k,k]中选出一个数字,将其加到自己的总分中.已 ...
- T2980 LR棋盘【Dp+空间/时间优化】
Online Judge:未知 Label:Dp+滚动+前缀和优化 题目描述 有一个长度为1*n的棋盘,有一些棋子在上面,标记为L和R. 每次操作可以把标记为L的棋子,向左移动一格,把标记为R的棋子, ...
- T2988 删除数字【状压Dp+前缀和优化】
Online Judge:从Topcoder搬过来,具体哪一题不清楚 Label:状压Dp+前缀和优化 题目描述 给定两个数A和N,形成一个长度为N+1的序列,(A,A+1,A+2,...,A+N-1 ...
随机推荐
- 机器学习-无监督机器学习-主成分分析PCA-23
目录 1. 降维的方式 2. PCA的一般步骤 3. 思想2 最小化投影距离 4. Kernelized PCA 1. 降维的方式 对于维度灾难.数据冗余,这些在数据处理中常见的场景,我们不得不进一步 ...
- Python Code_02
author : 写bug的盼盼 development time : 2021/8/27 19:59 变量定义 name = '阿哈' print(name) print('标识',id(name) ...
- Oracle 监控客户端的连接数量趋势
Oracle 监控客户端的连接数量趋势 背景 前期简单总结了table方式将表信息展示出来的方法 但是感觉这样非常不直观. 想着能够做出一个趋势来. 时序数据库的最佳的使用方式. 之前的确是太靠自己的 ...
- [转帖]使用 TiUP 部署 TiDB 集群
https://docs.pingcap.com/zh/tidb/stable/production-deployment-using-tiup TiUP 是 TiDB 4.0 版本引入的集群运维工具 ...
- [转帖]jemalloc 性能测试
https://wenfh2020.com/2020/07/30/jemalloc/ jemalloc 是一个优秀的内存分配器,通过与系统默认的内存分配器进行比较:jemalloc 内存分配性能比 ...
- 【转帖】训练中文LLaMA大规模语言模型
https://zhuanlan.zhihu.com/p/612752963?utm_id=0 https://github.com/CVI-SZU/Linlygithub.com/CVI-SZU/ ...
- [转帖]linux性能优化-内存回收
linux文件页.脏页.匿名页 缓存和缓冲区,就属于可回收内存.它们在内存管理中,通常被叫做文件页(File-backed Page). 通过内存映射获取的文件映射页,也是一种常见的文件页.它也可以被 ...
- 简单定位占用最高CPU的java进程信息
公司里面一个应用不小心点击就会导致系统性能下降很明显. 性能组的同事定位到了, 我这里以学习的态度重现一下这个过程. 1. 问题再现 产品一个非常大数据量的帮助, 点击之后就会占用非常多的cpu 因为 ...
- rfc7230 Message Syntax and Routing
rfc7230 目录 rfc7230 2 Architecture 2.6 Protocol Versioning 3 Message Format 3.1 Start Line 3.1.1 Requ ...
- js 保留两位小数不进行四舍五入
保留两位小数不进行四舍五入 // 保留小数n位,不进行四舍五入 // num你传递过来的数字, // decimal你保留的几位,默认保留小数后两位 app.config.globalProperti ...