轻松复现一张AI图片
轻松复现一张AI图片
现在有一个非常漂亮的AI图片,你是不是想知道他是怎么生成的?
今天我会交给大家三种方法,学会了,什么图都可以手到擒来了。
需要的软件
在本教程中,我们将使用AUTOMATIC1111 stable diffusion WebUI。这是一款流行且免费的软件。您可以在Windows、Mac或Google Colab上使用这个软件。
方法1: 通过阅读PNG信息从图像中获取提示
如果AI图像是PNG格式,你可以尝试查看提示和其他设置信息是否写在了PNG元数据字段中。
首先,将图像保存到本地。
打开AUTOMATIC1111 WebUI。导航到PNG信息页面。
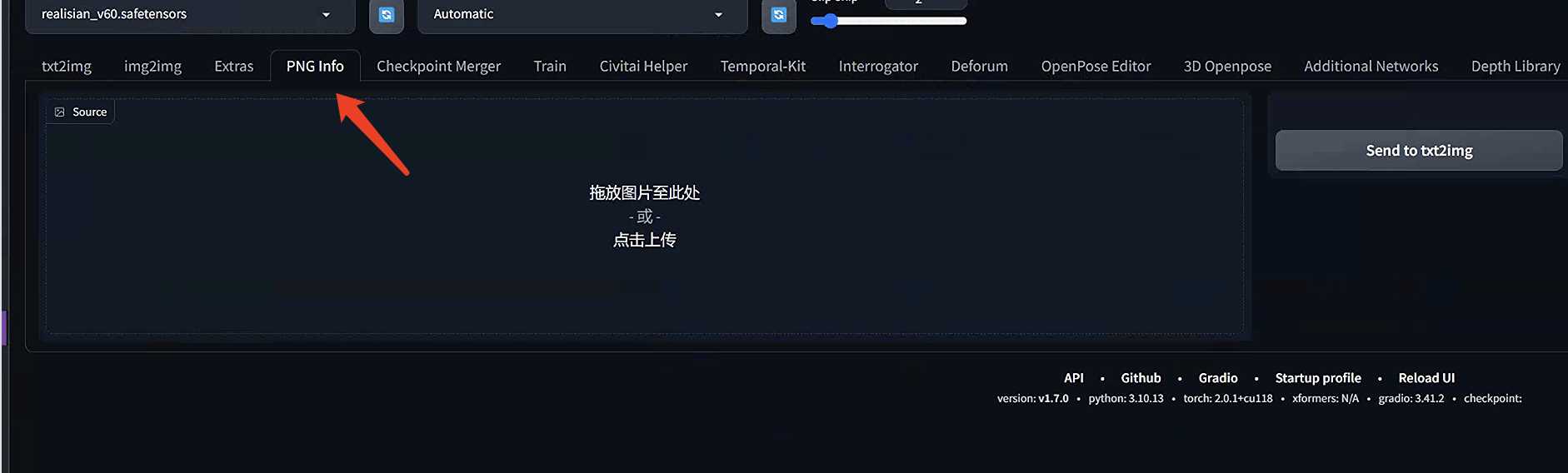
将图像拖放到左侧的源画布上。
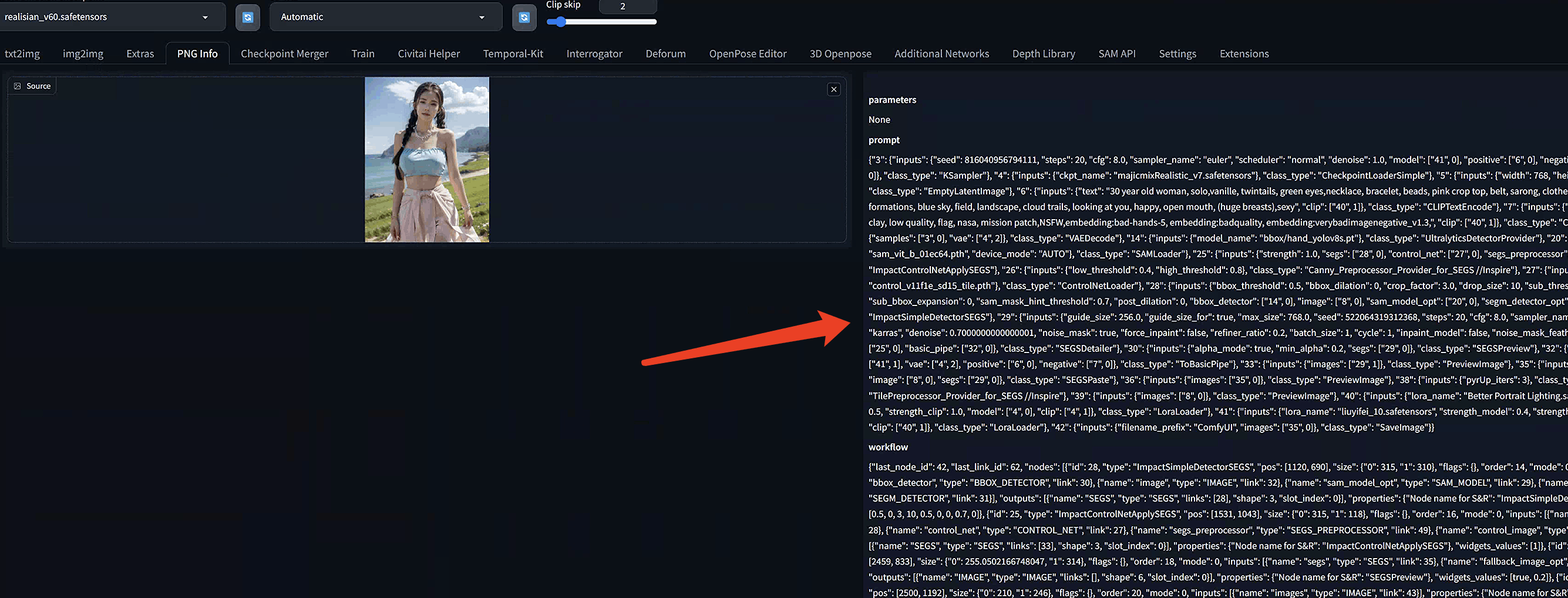
在右边你会找到关于提示词的有用信息。你还可以选择将提示和设置发送到txt2img、img2img、inpainting或者Extras页面进行放大。
方法2:使用CLIP interrogator从图像中推测Prompt
在处理图像信息时,我们常常会发现直接的方法并不总是有效。
有时候,信息并没有在最初就被记录在图像中,或者在后续的图像优化过程中被Web服务器去除。
也有可能这些信息并非由Stable diffusion这类AI技术生成。
面对这种情况,我们可以尝试使用CLIP interrogator作为替代方案。
CLIP interrogator是一种AI模型,它具备推测图像内容标题的能力。这个工具不仅适用于AI生成的图像,也能够应对各种类型的图像。通过这种方式,我们能够对图像内容进行更深入的理解和分析。
什么是CLIP?
CLIP(Contrastive Language–Image Pre-training)是一个神经网络,它将视觉概念映射到自然语言中。CLIP模型是通过大量的图像和图像信息对进行训练的。
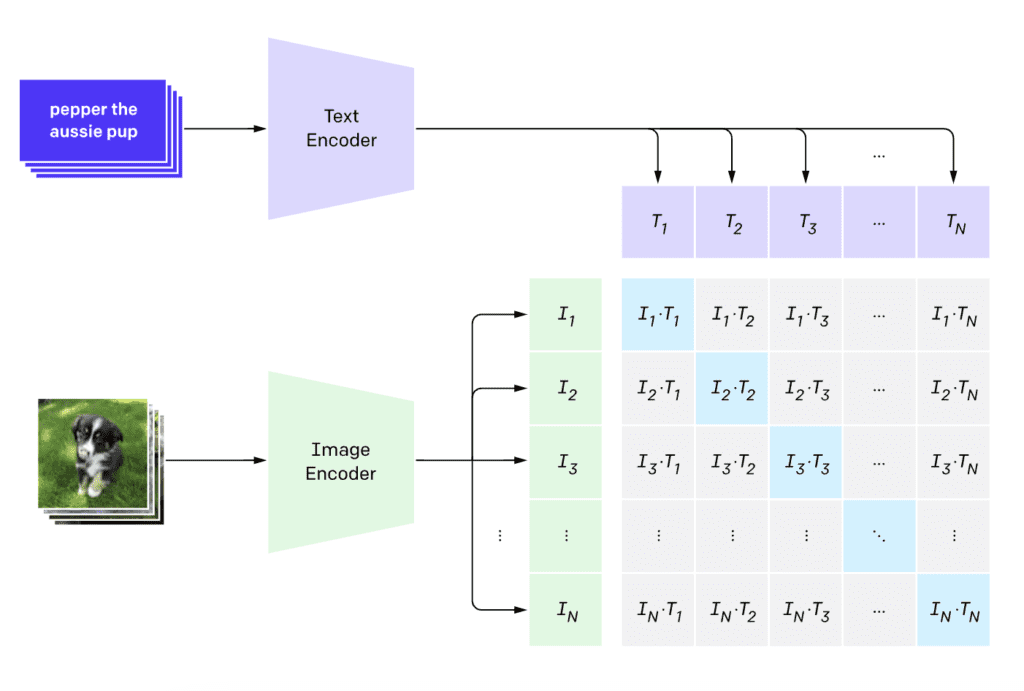
在我们的用例中,CLIP模型能够通过对给定图片的分析,推断出一个恰当的图片描述。
这个描述可以作为提示词,帮助我们进一步理解和描述图片的内容。CLIP模型通过学习大量的图像和相关文本数据,掌握了图像识别和语义理解的能力,因此它能够捕捉到图片中的关键元素,并将其转化为一个描述性的标题。
WebUI中自带的CLIP interrogator
如果你倾向于避免安装额外的扩展,可以选择使用AUTOMATIC1111提供的内置CLIP interrogator功能。
WebUI提供了两种识别图像信息的功能。一个是clip:这个功能底层基于BLIP模型,它是在论文《BLIP: 为统一的视觉语言理解和生成进行语言图像预训练》中由李俊楠以及其团队所提出的CLIP模型的一个变种。一个是DeepBooru, 这个比较适合识别二次元图片。
要利用这个内置的CLIP interrogator,你可以按照以下简单的步骤操作:
启动AUTOMATIC1111:首先,你需要打开AUTOMATIC1111的网站。
导航至img2img页面:在AUTOMATIC1111的界面中,找到并点击“img2img”这一选项。这是一个专门的页面,用于上传和处理图像。
上传图像到img2img画布:在这个页面上,你会找到一个用于上传图像的区域,通常被称为“画布”。点击上传按钮,选择你想要分析的图像文件,并将其上传到画布上。
上传之后在界面右边就可以找到两个interrogator工具了:
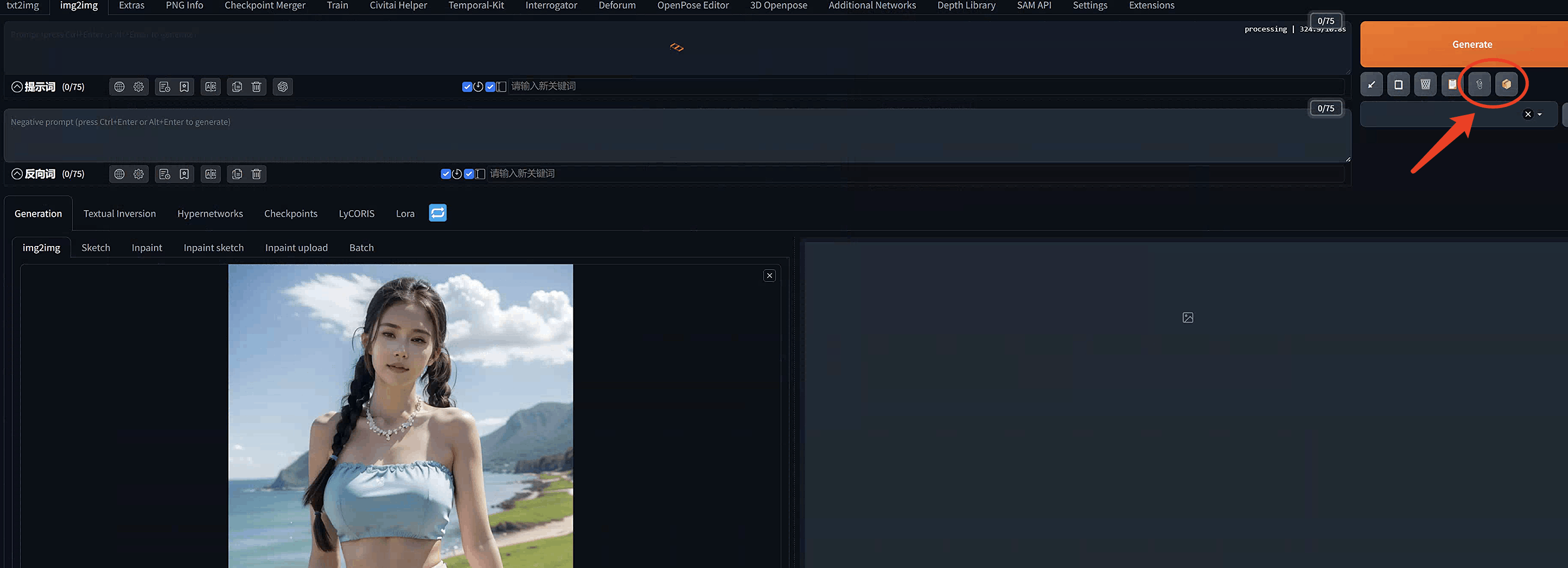
点击这两个按钮,就可以获得图像的描述信息了。
我们可以得到下面的信息:
a woman in a blue top and pink skirt standing on a hill near the ocean with a grassy area in the background,Ai Xuan,ocean,a statue,rococo,
我们用这段提示发到text2image中看看效果:

嗯....大体上还是有点相似的..... 因为图片跟我们的底模,种子还有采样多种因素有关。所以你想1比1复制,这个比较难。
CLIP扩展
如果您在使用AUTOMATIC1111的内置CLIP interrogator时发现其功能不足以满足您的需求,或者您希望尝试使用不同的CLIP模型来获得更多样化的结果,那么您可以考虑安装CLIP interrogator扩展。这个扩展将为您提供更多的选项和灵活性,以适应您特定的使用场景。
这个插件的下载地址如下:
https://github.com/pharmapsychotic/clip-interrogator-ext
要使用CLIP interrogator扩展。
打开AUTOMATIC1111 WebUI。
转到interrogator页面。
将图像上传到图像画布。
在CLIP模型下拉菜单中选择ViT-L-14-336/openai。这是Stable Diffusion v1.5中使用的语言嵌入模型。
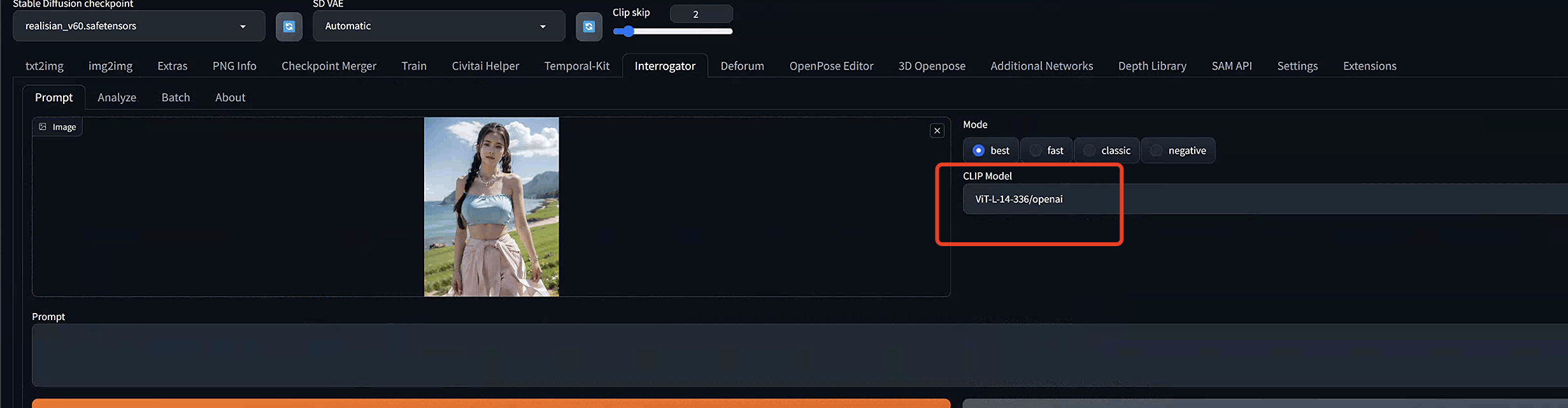
单击生成以生成提示。
对SDXL模型进行CLIP
如果你的目标是使用Stable Diffusion XL (SDXL)模型,那么我们需要选择不同的CLIP模型。
在“interrogator”页面上,你可以选择很多clip模型,如果要和SDXL模型一起工作的话,那么可以选择ViT-g-14/laion2b_s34b_b88k这个选项。
选择ViT-g-14/laion2b_s34b_b88k模型后,系统将会根据这个模型的特性生成相应的提示。你可以使用这个提示词作为SDXL的提示,从而可以更精确地生成与原始图像内容相符合的图像。
ViT-g-14/laion2b_s34b_b88k模型是一个基于Vision Transformer (ViT)架构的预训练模型,它在大型图像数据集laion2b上进行了训练,具有34亿个参数。这个模型在图像识别和理解方面表现出色,能够有效地捕捉图像的关键特征,并生成与原始图像内容紧密相关的提示。
通过这种方式,就可以确保在使用SDXL模型进行图像生成时,所得到的输出图像能够更好地反映原始图像的意图和风格。
总结一下
我们讲了三种方法来从图片信息中提取出对应的Prompt。
你应该首先尝试使用PNG信息方法。这种方法的优势在于,如果图像中包含了完整的元数据,那么您可以一次性获取到包括提示、使用的模型、采样方法、采样步骤等在内的所有必要信息。这对于重新创建图像非常有帮助。
如果PNG没有信息可用,那么可以考虑使用BLIP和CLIP模型。对于v1.5模型来说,ViT-g-14/laion2b_s34b_b88k模型可能是一个不错的选择,它不仅适用于SDXL模型,也可能在v1.5模型中表现出色。
另外,我们在构建提示词的时候,不要害怕对提示词进行修改。因为自动生成的提示可能并不完全准确,或者可能遗漏了一些图像中的关键对象。
所以需要根据自己的观察和需求,来修改提示词以确保它能准确地描述图像内容。这对于最终生成的图像质量和准确性至关重要。
同时,选择正确的checkpoint模型也非常关键。因为提示中可能并不总是包含正确的风格信息。
例如,如果您的目标是生成一个真实人物图像,那么你肯定不能选择一个卡通模型。
轻松复现一张AI图片的更多相关文章
- 1个小时!从零制作一个! AI图片识别WEB应用!
0 前言 近些年来,所谓的人工智能也就是AI. 在媒体的炒作下,变得神乎其神,但实际上,类似于图片识别的AI,其原理只不过是数学的应用. 线性代数,概率论,微积分(著名的反向传播算法). 大家觉得这些 ...
- Atitit.java图片图像处理attilax总结 BufferedImage extends java.awt.Image获取图像像素点image.getRGB(i, lineIndex); 图片剪辑/AtiPlatf_cms/src/com/attilax/img/imgx.javacutImage图片处理titit 判断判断一张图片是否包含另一张小图片 atitit 图片去噪算法的原理与
Atitit.java图片图像处理attilax总结 BufferedImage extends java.awt.Image 获取图像像素点 image.getRGB(i, lineIndex); ...
- Atitit 判断判断一张图片是否包含另一张小图片
Atitit 判断判断一张图片是否包含另一张小图片 1. keyword1 2. 模板匹配是在图像中寻找目标的方法之一(切割+图像相似度计算)1 3. 匹配效果2 4. 图片相似度的算法(感知哈希算 ...
- java图片处理——多张图片合成一张Gif图片并播放或Gif拆分成多张图片
1.多张jpg图合成gif动画 /** * 把多张jpg图片合成一张 * @param pic String[] 多个jpg文件名 包含路径 * @param newPic String 生成的gif ...
- 一张png图片 上面有多个图标,如何用CSS准确的知道其中某个图片的坐标
一张png图片 上面有多个图标,如何用CSS准确的知道其中某个图片的坐标 ,如下图 可以使用 background background:url(images/xx.png) 40px 10px n ...
- 【html+css3】在一张jpg图片上,显示多张透明的png图片
1.需求:在一个div布局里面放置整张jpg图片,然后在jpg图片上显示三张水平展示的透明png图片,且png外层用a标签包含菜单 2.效果图: 3.上图,底层使用蓝色jpg图片,[首页].[购物车] ...
- js将用户上传gif动图分解成多张帧图片
js将用户上传gif动图分解成多张帧图片 写在前面 工作中遇到一个这么一个需求:这是一个多图上传的场景,如果用户上传选择多张图片,则上传后直接展示多张图片,如果上传的图片是gif动图,则需要分解这张动 ...
- 用python爬取一张仓鼠图片
一. 找到一张仓鼠图片并复制一下它的url url='http://img.go007.com/2017/08/16/c407f5b732f4e748_2.jpg' 二. 调用urllib库 impo ...
- 小程序生成海报:通过 json 配置方式轻松制作一张海报图
背景 由于我们无法将小程序直接分享到朋友圈,但分享到朋友圈的需求又很多,业界目前的做法是利用小程序的 Canvas 功能生成一张带有二维码的图片,然后引导用户下载图片到本地后再分享到朋友圈.而小程序 ...
- 读取多张MNIST图片与利用BaseEstimator基类创建分类器
读取多张MNIST图片 在读取多张MNIST图片之前,我们先来看下读取单张图片如何实现 每张数字图片大小都为28 * 28的,需要将数据reshape成28 * 28的,采用最近邻插值,如下 def ...
随机推荐
- 新版idea配置maven注意点!!
1. maven配置 首先是按要求配置了maven,关闭所有项目->自定义->所有设置 配置完成之后发现新建项目下方还是显示从官方源下载maven包装器,而且在项目中出现这个配置文件 可以 ...
- Android 线性布局平分宽度item的隐藏问题
原文:Android 线性布局平分宽度item的隐藏问题 - Stars-One的杂货小窝 一直只使用layout_weight来平分布局,但是如果隐藏了某个item,会导致其他item宽高有所变化 ...
- CSharp的lambda表达式匿名类扩展方法
c#的lamba表达式 之前已经写过一些关于委托还有事件的文章,今天就来介绍一下lambda表达式. 首先定义需要的函数以及委托 { public delegate void DoNothingDel ...
- 一个简易的ORM框架的实现(二)
框架目标 什么是框架,框架能做到什么? 把一个方向的技术研发做封装,具备通用性,让使用框架的开发者用起来很轻松. 属性: 通用性 健壮性 稳定性 扩展性 高性能 组件化 跨平台 从零开始-搭建框架 建 ...
- PyQt5 GUI编程
一.PyQt5简介 PyQt5是一个用于创建图形用户界面(GUI)应用程序的跨平台工具集,它将Qt库(广泛用于C++编程语言中创建丰富的GUI应用程序)的功能包装给Python使用者.PyQt5是由R ...
- Install fail! SyntaxError: Unexpected token 'h', "hub.com>","... is not valid JSON (file: C:\Users\Admin\Documents\uirecorder_test\node_modules\_mocha@5.2.0@mocha\package.json)
uirecorder初始化时解析错误: PS C:\Users\Admin\Documents\uirecorder_test> PS C:\Users\Admin\Documents\uire ...
- ssm整合简单配置
最近由于系统重装,之前已经写好了的框架都被我删的一干二净,于是自己动手重新搭了个简单的ssm(spring springmvc mybatis) 运行环境 (java1.8,Tomcat8.5,mav ...
- KingbaseES Returning 的用法
概述 数据表更新时,如果需要对修改前后的数据进行记录或比较,需要返回更新前后的数据.KingbaseES 可以通过 UPDATE语句是否能直接返回影响的数据. KingbaseES支持insert,d ...
- KingbaseES 实现 MYSQL 的 delete limit 写法
使用MySQL的用户可能会比较熟悉这样的用法,更新或删除时可以指定限制更新或删除多少条记录. update tl set xxx=xxx where xxx limit 10; delete from ...
- 第十三届蓝桥杯大赛软件赛省赛【Java 大学B 组】试题D: 最少刷题数
1 import java.util.ArrayList; 2 import java.util.Scanner; 3 4 public class Main { 5 public static vo ...