算法金 | LSTM 原作者带队,一个强大的算法模型杀回来了

大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」

时间拉回 2019 年,有「计算机界诺贝尔奖」之称图灵奖获得者公布,深度学习三巨头:Yoshua Bengio、Geoffrey Hinton、Yann LeCun 众望所归。

图灵奖为何不颁给LSTM之父Jürgen Schmidhuber?作为AI界特立独行的人,Schmidhuber与深度学习三巨头有过口水战,并现场对质GAN的提出者,可谓得罪了一圈人。
20 世纪 90 年代,长短时记忆(LSTM)方法引入了恒定误差选择轮盘和门控的核心思想。三十多年来,LSTM 经受住了时间的考验,并为众多深度学习的成功案例做出了贡献。然而,以可并行自注意力为核心 Transformer 横空出世之后,LSTM 自身所存在的局限性使其风光不再。
当人们都以为 Transformer 在语言模型领域稳坐江山的时候,LSTM 又杀回来了 —— 这次,是以 xLSTM 的身份。

5 月 8 日,LSTM 提出者和奠基者 Sepp Hochreiter 在 arXiv 上传了 xLSTM 的预印本论文。

LSTM:「这次重生,我要夺回 Transformer 拿走的一切。」 今天,我们就来 说说 前任 - LSTM
(by Michael Phi)

各位[大侠],欢迎来到 LSTM 的世界。LSTM,全称 Long Short-Term Memory,是一种特殊的循环神经网络(RNN),旨在解决 RNN 中的长期依赖问题。它在时间序列预测、自然语言处理等领域有着广泛的应用。接下去我们从以下几个方面展开:
- LSTM 的定义和基本概念
- LSTM 的核心原理
- LSTM 的实现
- LSTM 的实际应用案例
1. LSTM 的定义和基本概念
1.1 基本定义
LSTM 是一种改进的循环神经网络(RNN),专门用于解决传统 RNN 中的长期依赖问题。RNN 在处理序列数据时,能够利用前面的信息,但是当序列过长时,信息会逐渐丢失。而 LSTM 通过引入记忆单元(Memory Cell)和门控机制(Gate Mechanisms),有效地解决了这一问题。
1.2 相关术语解释
- 记忆单元(Memory Cell):LSTM 的核心组件,用于存储长期信息。
- 输入门(Input Gate):控制哪些新的信息需要加入到记忆单元中。
- 遗忘门(Forget Gate):决定哪些信息需要从记忆单元中删除。
- 输出门(Output Gate):决定记忆单元的哪部分输出到下一个时间步。
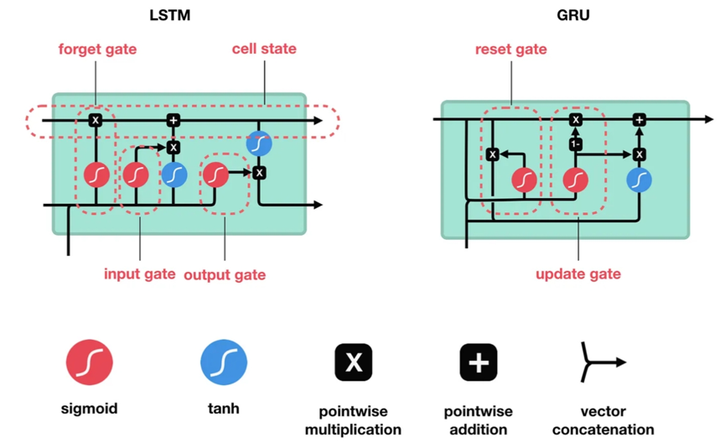
1.3 重要性和应用场景
LSTM 在许多领域有广泛的应用,包括但不限于:
- 自然语言处理(NLP):如文本生成、机器翻译和语音识别。
- 时间序列预测:如股市预测和气象预报。
- 机器人控制:处理连续的传感器数据,进行运动规划。
LSTM 的设计使其能够有效地捕捉和利用长期依赖关系,显著提高了序列数据处理的性能和效果。

2. LSTM 的核心原理
2.1 数学表达式
接下来我们看一下 LSTM 的数学表达式。LSTM 包含三个门:输入门、遗忘门和输出门。每个门都有自己的权重和偏置,用于控制信息的流动。

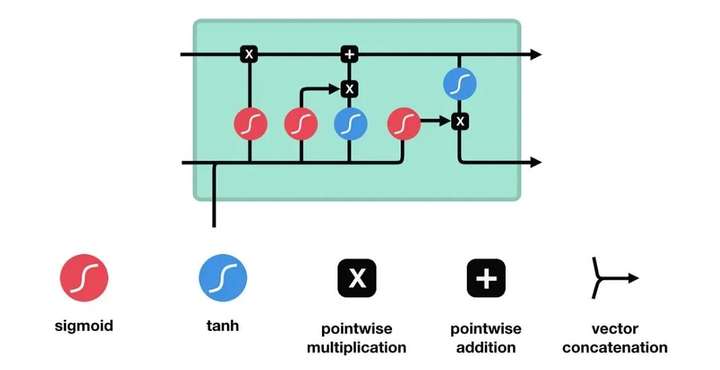
2.2 直观解释
- 输入门:决定当前输入信息中,哪些部分需要加入到记忆单元中。
- 遗忘门:决定当前记忆单元中的哪些信息需要丢弃。
- 输出门:决定记忆单元中的哪些信息需要输出到下一个时间步。
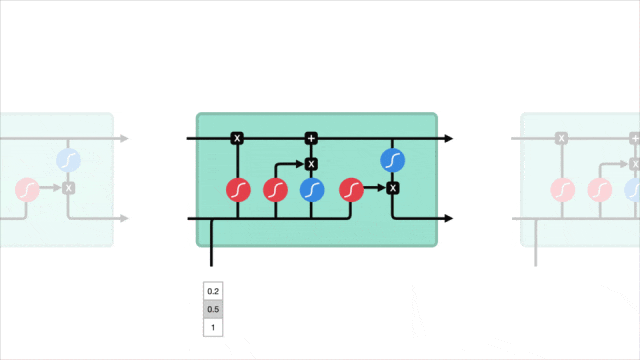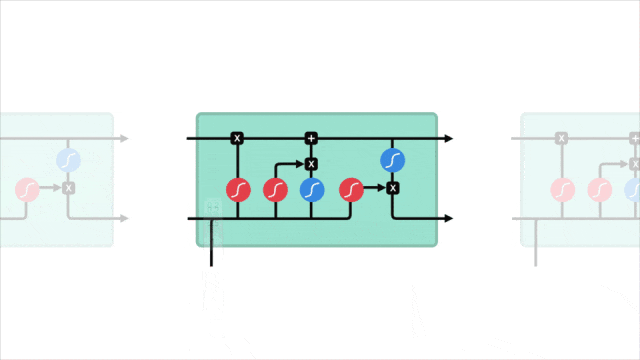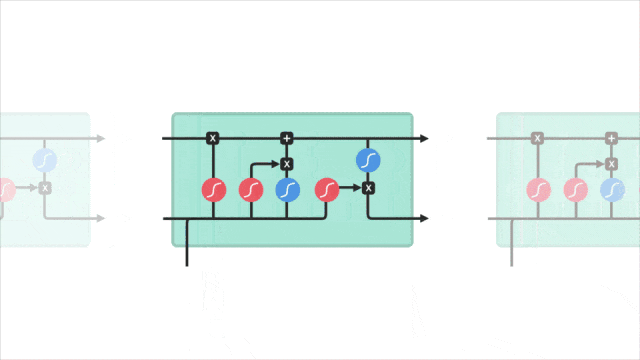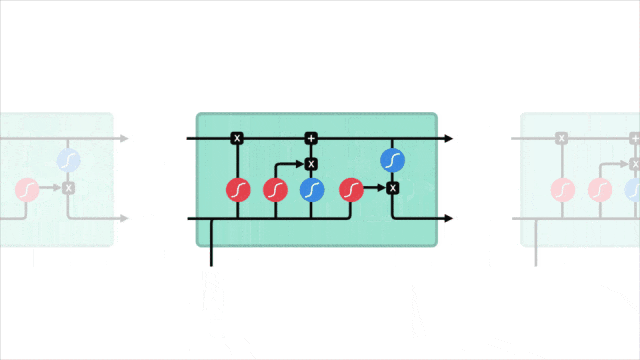
2.3 关键概念图示
让我们通过一个图示来直观地理解 LSTM 的工作原理。下图展示了 LSTM 单元的内部结构:
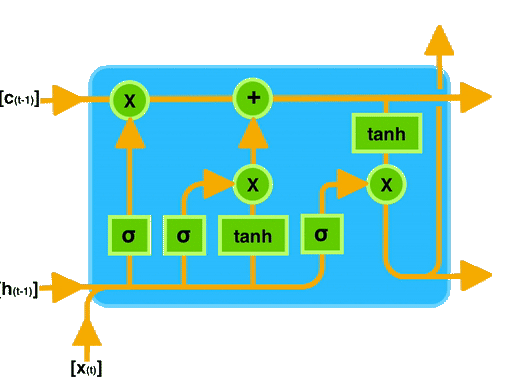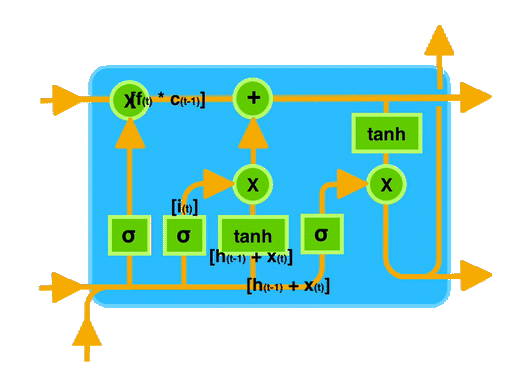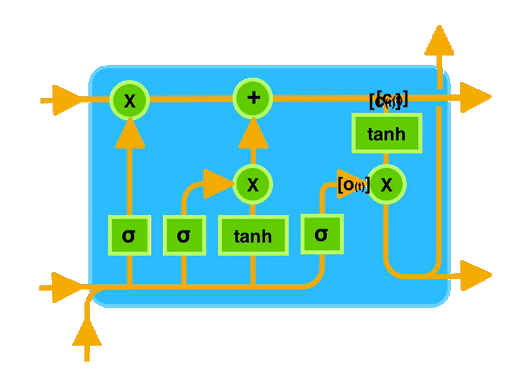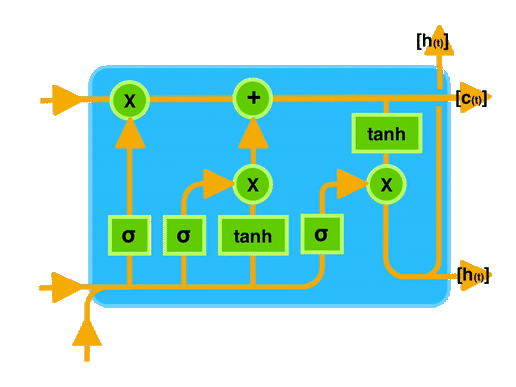
在图中可以看到,输入门、遗忘门和输出门共同作用于记忆单元,控制信息的存储和传递。
通过这种门控机制,LSTM 能够有效地记住长时间跨度的信息,从而在处理序列数据时表现出色。

3. LSTM 的实现
3.1 基础实现代码示范
现在我们来看看如何在 Python 中实现 LSTM。我们将使用 Keras 这个高层次神经网络库来进行实现。首先,我们需要准备数据集,这里我们自己造一个结合武侠元素的数据集。
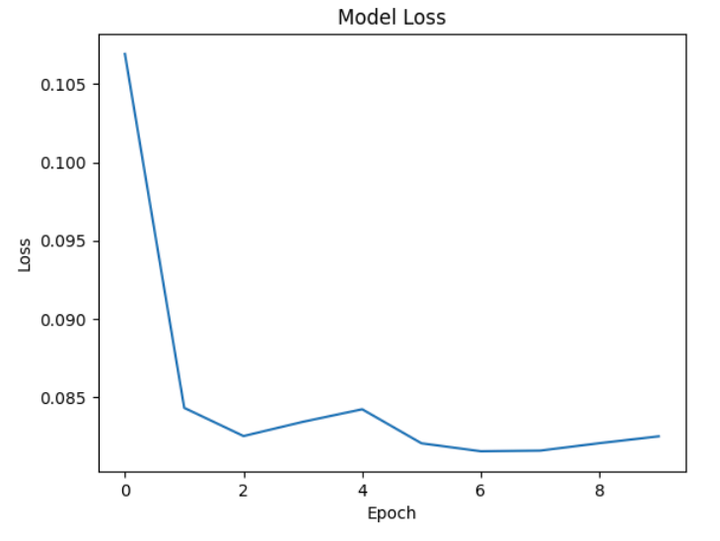
import numpy as npimport matplotlib.pyplot as pltfrom keras.models import Sequentialfrom keras.layers import LSTM, Densefrom keras.preprocessing.sequence import pad_sequences# 生成武侠元素的数据集def generate_data(num_sequences, sequence_length):data = []for _ in range(num_sequences):sequence = np.random.choice(['少林', '武当', '峨眉', '华山', '昆仑'], size=sequence_length)data.append(sequence)return data# 将文本数据转换为数字def text_to_numeric(data):mapping = {'少林': 0, '武当': 1, '峨眉': 2, '华山': 3, '昆仑': 4}numeric_data = []for sequence in data:numeric_data.append([mapping[item] for item in sequence])return numeric_data# 数据集生成data = generate_data(1000, 10)numeric_data = text_to_numeric(data)# 填充序列X = pad_sequences(numeric_data, maxlen=10)y = np.random.rand(1000, 1) # 随机生成一些标签# 构建 LSTM 模型model = Sequential()model.add(LSTM(50, input_shape=(10, 1)))model.add(Dense(1))model.compile(loss='mse', optimizer='adam')# 训练模型model.fit(X, y, epochs=10, batch_size=32)# 可视化训练结果loss = model.history.history['loss']plt.plot(loss)plt.title('Model Loss')plt.ylabel('Loss')plt.xlabel('Epoch')plt.show()
3.2 进阶实现
在基础实现的基础上,我们可以进一步优化 LSTM 模型,例如增加层数、调整超参数等。
3.3 常见问题及解决方法
- 过拟合:可以使用正则化、Dropout 等技术。
- 梯度消失:适当调整学习率,使用更高级的优化算法。
推荐阅读往期文章:
4. LSTM 的实际应用案例
4.1 案例一:文本生成
在这一部分,我们将展示如何使用 LSTM 进行文本生成。我们将继续使用武侠元素的数据集,通过训练 LSTM 来生成类似风格的文本。
import numpy as npfrom keras.models import Sequentialfrom keras.layers import LSTM, Dense, Embeddingfrom keras.preprocessing.text import Tokenizerfrom keras.preprocessing.sequence import pad_sequences# 生成武侠文本数据集texts = ["少林武当峨眉华山昆仑","武当少林昆仑华山峨眉","峨眉少林华山昆仑武当","昆仑峨眉少林武当华山","华山昆仑峨眉少林武当"]# 创建文本 Tokenizertokenizer = Tokenizer(char_level=True)tokenizer.fit_on_texts(texts)sequences = tokenizer.texts_to_sequences(texts)vocab_size = len(tokenizer.word_index) + 1# 准备数据X, y = [], []for sequence in sequences:for i in range(1, len(sequence)):X.append(sequence[:i])y.append(sequence[i])X = pad_sequences(X, maxlen=10)y = np.array(y)# 构建 LSTM 模型model = Sequential()model.add(Embedding(vocab_size, 50, input_length=10))model.add(LSTM(100))model.add(Dense(vocab_size, activation='softmax'))model.compile(loss='sparse_categorical_crossentropy', optimizer='adam')# 训练模型model.fit(X, y, epochs=200, verbose=2)# 文本生成函数def generate_text(model, tokenizer, seed_text, n_chars):result = seed_textfor _ in range(n_chars):encoded = tokenizer.texts_to_sequences([seed_text])[0]encoded = pad_sequences([encoded], maxlen=10, truncating='pre')predicted = np.argmax(model.predict(encoded), axis=-1)out_char = tokenizer.index_word[predicted[0]]seed_text += out_charresult += out_charreturn result# 生成新文本seed_text = "少林"generated_text = generate_text(model, tokenizer, seed_text, 20)print(generated_text)
在这个示例中,我们生成了一些武侠风格的文本。通过训练 LSTM 模型,我们可以生成类似风格的新文本,展示了 LSTM 在自然语言处理中的能力。

4.2 案例二:时间序列预测
在本例中,我们将使用 LSTM 进行时间序列预测,例如预测未来的天气状况。我们会先创建一个模拟的时间序列数据集,然后训练 LSTM 模型进行预测。
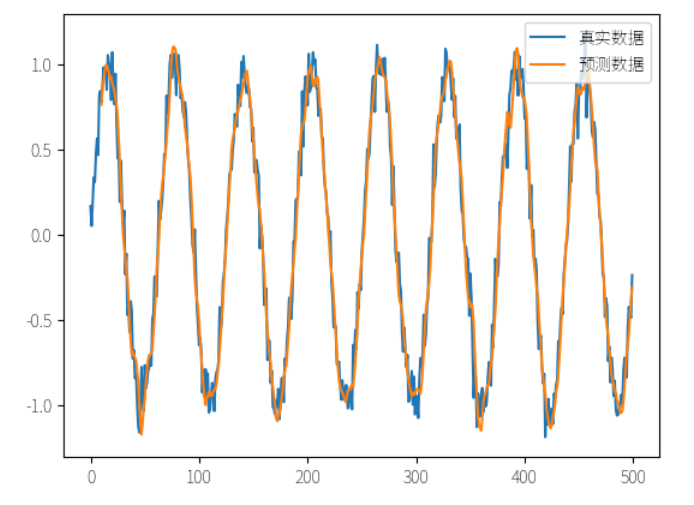
import numpy as npimport matplotlib.pyplot as pltfrom keras.models import Sequentialfrom keras.layers import LSTM, Dense# 生成模拟时间序列数据np.random.seed(7)data = np.sin(np.linspace(0, 50, 500)) + np.random.normal(0, 0.1, 500)sequence_length = 10# 准备数据X = []y = []for i in range(len(data) - sequence_length):X.append(data[i:i+sequence_length])y.append(data[i+sequence_length])X = np.array(X)y = np.array(y)# 调整数据形状X = np.reshape(X, (X.shape[0], X.shape[1], 1))# 构建 LSTM 模型model = Sequential()model.add(LSTM(50, input_shape=(sequence_length, 1)))model.add(Dense(1))model.compile(loss='mse', optimizer='adam')# 训练模型model.fit(X, y, epochs=20, batch_size=32, verbose=2)# 预测结果predicted = model.predict(X)# 可视化结果plt.plot(data, label='真实数据')plt.plot(np.arange(sequence_length, sequence_length + len(predicted)), predicted, label='预测数据')plt.legend()plt.show()
在这个例子中,我们使用 LSTM 模型预测未来的时间序列值。可以看到,通过训练 LSTM 模型,我们可以较为准确地预测未来的值。
[ 抱个拳,总个结 ]
在本文中,我们详细探讨了 LSTM 的定义、基本概念、核心原理、实现方法以及实际应用案例。
- 理解了 LSTM 的基本原理和数学表达式
- 掌握了 LSTM 的基础和进阶实现方法
- 了解了 LSTM 在文本生成和时间序列预测中的实际应
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵 内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如过觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
算法金 | LSTM 原作者带队,一个强大的算法模型杀回来了的更多相关文章
- 一个强大的jquery分页插件
点击这里查看效果 这个分页插件使用方便,引用keleyidivpager.js和keleyidivpager.css文件,然后在htm(或者php,aspx,jsp等)页面中对分页总数,参数名,前缀后 ...
- ZeroMQ接口函数之 :zmq_z85_decode – 从一个用Z85算法生成的文本中解析出二进制密码
ZeroMQ 官方地址 :http://api.zeromq.org/4-0:zmq_z85_decode zmq_z85_decode(3) ØMQ Manual - ØMQ/4.1 ...
- 深度剖析:如何实现一个 Virtual DOM 算法
本文转载自:https://github.com/livoras/blog/issues/13 目录: 1 前言 2 对前端应用状态管理思考 3 Virtual DOM 算法 4 算法实现 4.1 步 ...
- 一个UUID生成算法的C语言实现 --- WIN32版本 .
一个UUID生成算法的C语言实现——WIN32版本 cheungmine 2007-9-16 根据定义,UUID(Universally Unique IDentifier,也称GUID)在时 ...
- 一个由IsPrime算法引发的细节问题
//******************************* // // 2014年9月18日星期四,于宿舍撰写 // 作者:夏华林 // //******************* ...
- 一个简单的算法,定义一个长度为n的数组,随机顺序存储1至n的的全部正整数,不重复。
前些天看到.net笔试习题集上的一道小题,要求将1至100内的正整数随机填充到一个长度为100的数组,求一个简单的算法. 今天有空写了一下.代码如下,注释比较详细: using System; usi ...
- 十依据一个有用的算法来找到最小(最大)的k的数量-线性搜索算法
例如:进入1.2.3,4,5,6.7.8此8数字,最小的4图的1,2,3,4. 思路1:最easy想到的方法:先对这个序列从小到大排序.然后输出前面的最小的k个数就可以.假设选择高速排序法来进行排序, ...
- 毕加索的艺术——Picasso,一个强大的Android图片下载缓存库,OkHttpUtils的使用,二次封装PicassoUtils实现微信精选
毕加索的艺术--Picasso,一个强大的Android图片下载缓存库,OkHttpUtils的使用,二次封装PicassoUtils实现微信精选 官网: http://square.github.i ...
- Dubbo 泛化调用的参数解析问题及一个强大的参数解析工具 PojoUtils
排查了3个多小时,因为一个简单的错误,发现一个强大的参数解析工具,记录一下. 背景 Nodejs 通过 tether 调用 Java Dubbo 服务.请求类的某个参数对象 EsCondition 有 ...
- 手动实现一个虚拟DOM算法
发现一个好文:<深度剖析:如何实现一个 Virtual DOM 算法> 源码 文章写得非常详细,仔细看了一遍代码,加了一些注释.其实还有有一些地方看的不是很懂(毕竟我菜qaq 先码 有时间 ...
随机推荐
- 力扣217(java&python)-存在重复元素(简单)
题目: 给你一个整数数组 nums .如果任一值在数组中出现 至少两次 ,返回 true :如果数组中每个元素互不相同,返回 false . 示例 1: 输入:nums = [1,2,3,1]输出:t ...
- 龙蜥正式开源 SysOM:百万级实战经验打造!一站式运维管理平台 | 龙蜥技术
简介:SysOM集监控.告警.诊断.修复.安全能力于一体的操作系统运维平台. 文/系统运维 SIG 如果你被突如其来的 OOPS 和满屏奇怪的函数弄得满头问号?机器内存明明很大,却申请不出来内存 ...
- Serverless在游戏运营行业进行数据采集分析的最佳实践
简介: 这个架构不光适用于游戏运营行业,其实任何大数据采集传输的场景都是适用的,目前也已经有很多客户正在基于Serverless的架构跑在生产环境,或者正走在改造Serverless 架构的路上. 众 ...
- 技术干货 | 深度解构 Android 应用面临紧急发版时的救星方案:mPaaS 热修复——DexPatch
简介: 关于 Android 热修复方案--DexPatch 的介绍与使用说明 方案介绍 为了解决 Native 模块上线后的问题,mPaaS 提供了热修复功能,实现不发布客户端 apk 场景下的热修 ...
- DevOps发布策略简介
简介: DevOps追求更短的迭代周期.更高频的发布.但发布的次数越多,引入故障的可能性就越大.更多的故障将会降低服务的可用性,进而影响到客户体验.所以,为了保证服务质量,守好发布这个最后一道关,阿里 ...
- 阿里云混合云Apsara Stack 2.0发布 加速政企数智创新
简介: 2021年10月21日,杭州 – 今日,阿里云于云栖大会正式发布Apsara Stack 2.0,从面向单一私有云场景,升级为服务大型集团云&行业云场景.新一代Apsara Stac ...
- 前端关于获取网络时间的方法api
淘宝 http://api.m.taobao.com/rest/api3.do?api=mtop.common.getTimestamp 苏宁http://quan.suning.com/getSys ...
- 揭露 FileSystem 引起的线上 JVM 内存溢出问题
作者:来自 vivo 互联网大数据团队-Ye Jidong 本文主要介绍了由FileSystem类引起的一次线上内存泄漏导致内存溢出的问题分析解决全过程. 内存泄漏定义(memory leak):一个 ...
- .net 记录http请求
记录http请求 环境 .net7 一.过滤器(Filter) 这个过程用的的是操作过滤器(ActionFilter) 二. 2.1 继承IAsyncActionFilter 2.2 重写OnActi ...
- 启动docker某个image(镜像)的已经关闭的container(容器)
1.创建一个后台运行 ubuntu 容器 root@haima-PC:/home/haima/Desktop# docker run -d --name ubuntu-lnmp ubuntu bf24 ...