[转帖]Linux-文本处理三剑客awk详解+企业真实案例(变量、正则、条件判断、循环、数组、分析日志)
https://developer.aliyun.com/article/885607?spm=a2c6h.24874632.expert-profile.313.7c46cfe9h5DxWK
文本处理 awk
1.awk简介
awk是一种编程语言,用于在Linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件,或其他命令的输出,它支持用户自定义函数和动态正则正则表达式等先进功能,是Linux/unix下的一个强大的编程工具。它在命令行中使用,但更多是作为脚本来使用。
awk的处理文本和数据的方式是这样的,它逐行扫描文件从第一行到最后一行,寻找匹配的特定模式的行,并在这些行上进行你想要的操作,如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕),如果没有指定模式,则所有被操作所指定的行都被处理。
2.awk的两种命令格式
awk [options] ‘commands’ filenames
awk [options] -f awk-scripts-file filenames
=options:===
-F 定义输入字段分隔符,默认的分隔符是空格或制表符
==command:
BEGIN{} {} END{}
行处理前 行处理 行处理后
awk 'BEGIN{print 1/2}{print "ok"}END{print "-----------"}' /etc/hosts
0.5
ok
ok
ok
---------
在行处理前执行1/2,在处理每一行后打印ok,在行处理后在打印--------,整个命令的原理:先进行行前处理,也就是打印出1/2的值也就是0.5,然后根据awk的原理,不指定处理哪一行默认都进行处理,因此每当处理一行后都会打印ok,最后在每一行都处理结束后打印-------------
BEGIN{}通常用于定义一些变量
awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' /etc/passwd //在BEGIN中定义FS的值以:进行分隔,FS表示输入时分隔符为xxx,
3.awk命令格式:
awk ‘pattern’ filename
示例
awk -F: '/root/' /etc/passwd
过滤出包含root的行
awk ‘{action}’ filename
示例
awk -F ":" '{print $1}' /etc/passwd
以分号分隔,打印出第一列
awk ‘pattern {action}’ filename
示例
awk -F ":" '/root/{print $1,$2}' /etc/passwd
以分号作为分隔符,打印出包含root的行并打印第一列
awk 'BEGIN{FS=":";OFS="---"} /root/{print $1,$2,$3}' passwd.txt
以BEGIN行前处理定义FS的分隔符,OFS定义输出分隔符,匹配包含root的行并打印1,2,3列
df | grep '/' | awk '$4>100000 {print $4,$(NF)}'
df命令列出磁盘空间后,使用grep命令过滤/的行,在使用awk过滤一下$4大于100000的行在打印第4列和最后一列
4.awk工作原理
awk -F: '{print $1,$2,$3}' /etc/passwd
1.awk使用一行作为输入,并将这然后一行赋给内部编码$0,每一行也可称为一个记录,以换行符结束
2.然后,行被:(默认为空格或者制表符,但是由于我们使用了-F也就是重新定义了分隔符,因此在这里为:)分解成字段(或域),每个字段存储在已经编号的变量中,从$1开始,最多达100个字段
3.awk如何知道用空格来分隔字段的呢?因为有一个内部变量FS来确定字段分隔符,初始时,FS赋为空格
4.awk打印字段时,将以设置的方法使用print函数打印,awk在打印的字段间加上空格,因为$1,$3之间有一个逗号,逗号比较特殊,它映射为另一个内部变量,称为输出字段分隔符OFS,OFS默认为空格
5.awk输出后,将文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字符串分隔成字段并进行处理,该过程将持续到所有行处理完毕
5.awk记录与字段相关内部变量
man awk可以看到所有的awk帮助信息
$0:awk变量$0保存当前记录的内容
awk -F":" '{print $0}' passwd.txt
NR:The total number of input records seen so far
显示行号总数,例如有两个文件同时输出到屏幕,行号会接着之前文件的继续加之,NR是总的
awk -F":" '{print NR,$0}' passwd.txt /etc/hosts
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
11 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
12 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
如果把NR放在了后面则在行尾加上行号
awk -F":" '{print $0,NR}' passwd.txt /etc/hosts
root:x:0:0:root:/root:/bin/bash 1
bin:x:1:1:bin:/bin:/sbin/nologin 2
daemon:x:2:2:daemon:/sbin:/sbin/nologin 3
adm:x:3:4:adm:/var/adm:/sbin/nologin 4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 5
sync:x:5:0:sync:/sbin:/bin/sync 6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
halt:x:7:0:halt:/sbin:/sbin/halt 8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 9
operator:x:11:0:operator:/root:/sbin/nologin 10
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 11
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 12
awk也可以结合sed命令来使用,sed命令不输出行号,所以可以结合awk来实现
awk -F":" '{print NR,$0}' passwd.txt |sed '1,3s/.*/#&/'
FNR:The input record number in the current input file
FNR的不像NR多个文件的行数都写在一块,FNR是当前输入文件的行号
awk -F":" '{print FNR,$0}' passwd.txt /etc/hosts
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
NF:保存记录的字段数,$1,$2,$3的个数
一般都会把NF放在最后,审美
NF与N F 的 区 别 : N F 是 打 印 字 段 的 个 数 , NF的区别:NF是打印字段的个数,NF的区别:NF是打印字段的个数,NF是打印最后一列
awk -F":" '{print NR,$0,NF}' passwd.txt
1 root:x:0:0:root:/root:/bin/bash 7
2 bin:x:1:1:bin:/bin:/sbin/nologin 7
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 7
4 adm:x:3:4:adm:/var/adm:/sbin/nologin 7
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 7
6 sync:x:5:0:sync:/sbin:/bin/sync 7
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7
8 halt:x:7:0:halt:/sbin:/sbin/halt 7
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 7
10 operator:x:11:0:operator:/root:/sbin/nologin 7
awk -F":" '{print NR,$0,NF,$NF}' passwd.txt
1 root:x:0:0:root:/root:/bin/bash 7 /bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin 7 /sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin 7 /sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin 7 /sbin/nologin
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin 7 /sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync 7 /bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown 7 /sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt 7 /sbin/halt
9 mail:x:8:12:mail:/var/spool/mail:/sbin/nologin 7 /sbin/nologin
10 operator:x:11:0:operator:/root:/sbin/nologin 7 /sbin/nologin
FS:输入字段分隔符,默认空格
awk -F":" '{print $1}' passwd.txt /etc/hosts
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
多重匹配分隔符[ :\t]表示以空格冒号制表符作为分隔符,出现对应的符号就进行分隔
awk -F"[ :\t]" '{print $1,$2,$3,$4}' passwd.txt /etc/hosts
root x 0 0
bin x 1 1
daemon x 2 2
adm x 3 4
lp x 4 7
sync x 5 0
shutdown x 6 0
halt x 7 0
mail x 8 12
operator x 11 0
127.0.0.1 localhost
1
也可以使用BEGIN作为分隔符
awk 'BEGIN{FS=":"} {print $1}' passwd.txt
awk -F: '/root/{print $1,$2,$3,$4}' passwd.txt
OFS:输出字段分隔符
awk 'BEGIN{FS=":";OFS="+++"}/root/{print $1,$2,$3}' passwd.txt
RS:输入记录分隔符,可以将一行换成多行
以冒号分隔
awk 'BEGIN{RS=":"}{print $0}' passwd.txt
以空格分隔
awk 'BEGIN{RS=" "}{print $0}' passwd.txt
ORS:输出记录分隔符,可以将多行合并成一行
awk 'BEGIN{ORS=""}{print $0}' passwd.txt
awk 'BEGIN{ORS=" "}{print $0}' passwd.txt
字段分隔符:FS OFS 默认空格或者制表符
记录分隔符:RS ORS 默然换行符
6.格式化输出
print函数
使用print函数时打印非变量的字符时一定要用引号引起来
输出当前的月份和年份
date | awk '{print "month: "$2 "\nyear: "$1}'
month:03月
year: 2020年 输出passwd.txt文件中的用户名和uid
awk -F":" '{print "username is: "$1 "\tuid is: "$3}' passwd.txt
awk -F":" '{print "username and uid: "$1,$3}' passwd.txt
printf 函数
awk -F ":" '{printf "%-15s %-10s %-15s\n",$1,$2,$3}' passwd.txt //设置字符长度
awk -F ":" '{printf "%-15s| %-10s| %-15s\n",$1,$2,$3}' passwd.txt
awk -F ":" '{printf "%-25s| %-20s| %-25s|\n","username:"$1,"userpass:"$2,"useruid:"$3}' passwd.txt
%s字符类型
%d数值类型
%f浮点类型
占15个字符
-表示左对齐,默认右对齐
printf默认不会再行尾自动换行,加\n
7.模式匹配
7.1正则表达式:
匹配记录(整行):
awk '/^root/' passwd.txt
awk '$0 ~ /^root/' passwd.txt //$0匹配root开头的行,~表示匹配
awk '!/^root/' passwd.txt //除了root的行
awk '$0 !~ /^root/' passwd.txt //$
匹配字段:匹配操作符(~ !~)
awk -F":" '$1 ~ /^root/' /etc/passwd //匹配
awk -F":" '$NF !~ /bash$/' /etc/passwd //非匹配
7.2关系运算符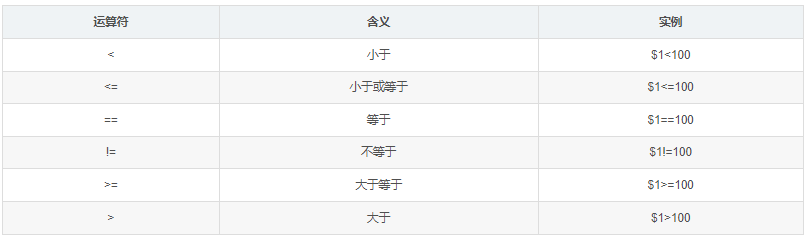
字符串建议用双引号引起来
awk -F ":" '$3 == 0' /etc/passwd //$3等于0
awk -F ":" '$3 < 10' /etc/passwd //$3小于10
awk -F ":" '$NF == "/bin/bash"' /etc/passwd //最后一列等于/bin/bash
awk -F ":" '$1 == "root"' /etc/passwd //$1等于root
awk -F ":" '$1 ~ /root/' /etc/passwd //$1匹配正则root的行
awk -F ":" '$1 !~ /root/' /etc/passwd //$1不匹配root,就是不包含
df | grep '/' |awk '$4 < 1000'
7.3条件表达式:
awk -F":" '$3>300 {print $0}' /etc/passwd //如果$3这一列大于300那么久打印整行
awk -F":" '{if($3>300) print $0}' /etc/passwd//如果$3这一列大于300那么久打印整行
awk -F":" '{if($3>300){print $3}else{print $1}}' /etc/passwd
7.4算术运算:+ - * / % ^
awk -F":" '{if($3 * 5 > 10){print $1,$3}}' passwd.txt //如果$3*5的结果大于10,那么就打印$1,$3
awk -F":" '{if($3 + 5 > 10){print $1,$3}}' passwd.txt
awk -F":" '{if($3 - 5 < 10){print $1,$3}}' passwd.txt
awk -F":" '{if($3 / 5 < 10){print $1,$3}}' passwd.txt
awk -F":" '{if($3^5 > 10){print $1,$3}}' passwd.txt
7.5逻辑操作符和复合模式
&& 逻辑与 a&&b
|| 逻辑或 a||b
! 逻辑非 !a
awk -F ":" '$1~/root/ && $3<=15' /etc/passwd
awk -F ":" '$1~/root/ || $3<=15' /etc/passwd
awk -F ":" '!($1~/root/ || $3<=15)' /etc/passwd
8.awk示例
awk '/root/' passwd.txt //匹配root的行
awk '/^root/' passwd.txt //匹配以root开头的行
awk '$3 ~ /^root/ ' passwd.txt //$3匹配root开头
awk '/^(no|so)/' passwd.txt //匹配no或者so开头的行
awk '{print $3,$2} ' passwd.txt //打印第三列和第二列 awk '{print $0}' passwd.txt //打印整行
awk '{print "Number of fields" NF}' passwd.txt //打印每一行的字段数
awk '/root/{print $3,$2}' file //匹配root的行并打印$3和$2两列
awk '/E/' passwd.txt //匹配E的行 awk '/^[ns]/{print $1}' datafile //匹配以n或s开头的行并打印$1
awk '$5 ~ /\.[7-9]+' datafile //$5匹配.开头在跟一个7-9出现一次或多次
awk awk '$4 ~ /China$/{print $8}' datafile //$4匹配china结尾的并打印$8
awk '/Tj/{print $0}' datafile //匹配Tj的行并打印
awk '{print $1}' /etc/passwd
awk -F ":" '{print $1}' /etc/passwd
awk -F ":" '{print "Number of felds: "NF}' /etc/passwd
awk -F"[ :]" '{print NF}' /etc/passwd //指定多个分隔符,空格或者冒号都进行分隔
awk -F"[ :]+" '{print NF}' /etc/passwd //空格或者分隔符出现一次或多次
awk '$7 == 5' datafile //$7等于5
awk '$2 == "CT"{print $1,$2}' datafile //$2等于CT的行并打印$1和$2
awk '$7 != 5' datafile //$7不等于5 awk '$7 < 5 {print $4,$7}' datafile //$7小于5打印第四列和第七列
awk '$6 > .9{print $1,$6}' datafile //$6大于0.9则打印第一列和第六列
awk '$8 <= 17 {print $8}' datafile //$8下雨等于17则打印第八列
awk '$8 > 10 && $8 <17' datafile //$8大于10并且$8小于17
综上可以使用if的方式:awk '{if($7 != 5){print $1,$2}}' datafile awk '$2 == "NW" || $1 ~ /south/ {print $1,$2}' datafile //$2等于NW或者$1匹配south的行然后打印$1和$2
awk '!($8 == 13){print $8}' datafile //如果$8不等于13就打印$8
awk '/southem/{print $5 + 10}' datafile //匹配suouthem并打印$5+10 awk '/southem/{print $8 - 10}' datafile //$8减10
awk '/southem/{print $8 / 2}' datafile //$8除于2
awk '/southem/{print $8 * 2}' datafile //$8乘2
awk '/southem/{print $8 % 2}' datafile //$8余数2 awk '$3 ~ /^Suan/ {print "Percentage:"$6 + .2 "volume: "$8}' //$3匹配Suan开头的行,打印$6+0.2并打印$8
awk '/^western/,'/^eastern/' datafile
awk '{print ($7 > 4 ? "high: "$7: "low" $7)}' datafile //如果$7大于4则打印$7否则打印$7可以使用if else实现
awk '$3 == "Chirs"{$3 = "Chiristian"; print $0}' datafile //$3等于chirs则将$3赋值chiristian 并打印$0
awk '/Derek/ {$8+=12;print $8}' datafile //$8=$8+12
awk '{$7%=3; print $7}' datafile //$7=$7 % 3
9.awk脚本编程
表达式用(),命令语句用{}
9.1.条件判断
if语句:
格式:{if(表达式){语句1,语句2}}
awk -F ":" '{if($3 == 0){print $1 "is administrator"}}' /etc/passwd //如果$3=0就打印$1是管理员
awk -F ":" '{if($3>0 && $3<1000){count++;}} END{print count}' /etc/passwd.txt //如果$3大于0并且$3大于1000那么count++也就是每当条件成立一次,count的值就会加1,最后在打印cront的值,如果想加一次都显示值则在{count++;print count}即可
ps -ef | awk '{if($1 ~ /root/ ){i++}} END{print "root用户开启的进程个数为: "i}' //打印root用户开启了多少个进程 if..else语句:
格式:{if(表达式){语句;语句;...}else{语句;语句;...}}
awk -F ":" '{if($3==0){i++} else{j++}} END{print "管理员个数: "i;print "系统用户个数: "j}' /etc/passwd //如果$3=0则i的值每次加1,否则j每次加1,
awk -F ":" '{if($3==0){i++}else{j++}} END{print "管理员个数: "i "\n系统用户个数: "j}' /etc/passwd //可以使用一个print,并使用\n进行还行 if...else if...else语句
格式:'{if(表达式1){语句;语句}else if(表达式2){语句;语句} else if(表达式3){语句;语句} else{语句}}'
awk -F":" '{if($3==0){i++} else if($3>999){j++} else{s++}} END{print i;print j;print s}' /etc/passwd
awk -F":" '{if($3==0){i++} else if($3<999){j++} else{s++}} END{print "管理员个数: "i;print "程序用户个数: "j;print "普通用户个数: "s}' /etc/passwd //如果$3=0则i的值每次都加1,如果$3小于999则j的值每次都加1,如果都不匹配则s的值每次加1,管理员的个数匹配i,程序用户个数匹配j,普通用户个数匹配s
9.2.循环
在awk中while循环和for循环的区别在于:while是将初值、累加分开写的如{i=1;while(i<=10){print $i;i++}}而for是都写在一起的,和shell中的for格式相同如{for(i=1;i<=10;i++){print $i}}
while循环
awk 'BEGIN{i=1;while(i<=10){print i; i++}}' //行前处理,先赋初值i=1,当i的值小于等于10的时候打印i的值,每次循环i的值加1,print i后面必须加分号,不然会打印两次
awk -F":" '{i=1;while(i<=NF){print $i; i++}}' passwd.txt //符初值,如果i小于等于字段个数,则打印$i列也就是第一次$1第一列,第二次$2第二列每次循环玩i的值都加1
awk -F":" '/^root/{i=1;while(i<=NF){print $i; i++}}' passwd.txt //匹配到root开头的行,然后进行循环
root1
x2
03
04
root5
/root6
/bin/bash7
awk -F ":" '/^root/{i=1;while(i<=7){print $i;i++}}' passwd.txt
awk -F '{i=1;while(i<=NF){print $i;i++}}' b.txt //分别打印每行每列
9.3.for循环
awk 'BEGIN{for(i=1;i<=10;i++){print i}}' //跟shell中的for循环一样
awk -F":" '{for(i=1;i<=NF;i++){print $i}}' passwd.txt
awk -F":" '/root/{for(i=1;i<=NF;i++){print $i}}' passwd.txt
9.4.数组
注意:遍历时,i in user是索引不是数组值,print i,state和print i;state不一样其中“,”表示在同一行显示,";"表示换行,需要增加print
格式:awk ‘{数组[索引]++} END{for(i in 数组){print i,数组[i]}}’
sort -k表示按第几列排序 -n 排序,-r表示逆序,就是降序
awk -F":" '{username[++i]=$1} END{print username[1]}' passwd.txt //定义一个数组,数组的索引是++i也就是第一次索引位1,第二次索引位2,数组的元数每次都是该行的第一列,最后打印数组
awk -F":" '{username[++i]=$1} END{print username[2]}' passwd.txt
awk -F":" '{username[i++]=$1} END{print username[0]}' passwd.txt
数组遍历:
netstat -ant | awk '{state[++i]=$NF} END{for (j in state){print j,state[j]}}' | sort -k1 -n //将最后一列作为数组的值,最后遍历索引,打印数组值,在用sort排序小,-k表示对第几列进行排序
awk -F":" '{username[++j]=$1} END{for(i in username){print i,username[i]}}' passwd.txt
练习
awk -F":" '{shells[$NF]++} END{for(i in shells){print i,shells[i]}}' /etc/passwd //统计各种登录shell出现的次数,这里使用shells[$NF]++而不是shells[++i]=$NF是因为我们要统计这一列出现的次数,将每一行的这一列都做成索引
统计网站访问状态
netstat -n | awk '/^tcp/{state[$NF]++} END{for(i in state){print i,state[i]}}' //导出系统并发数,以tcp开头的行最后一列作为数组索引,每当出现一次值就加1,最后遍历,等同于netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}',二者不同在于数组定义方面,后者是在数组名前就进行了++而前者是在索引定义好后++,效果一致。
netstat -ant | grep ":888" | awk '{state[$NF]++} END{for (i in state){print i,state[i]}}' | sort -k2 -n | head //将结果排序
ss命令实现
ss -an | grep ":888" |awk '{state[$2]++} END{for (i in state){print i,state[i]}}'
ss -an | grep ":888" |awk '{state[$2]++} END{for (i in state){print i,state[i]}}' | sort -k2 -n | head
统计访问ip的次数
netstat -ant | grep ":888" | awk -F"[ :\t]+" '{ips[$6]++} END{for (i in ips){print i,ips[i]}}'
ss -ant
ss -ant | grep ":888" | awk -F"[ :\t]+" '{ips[$6]++} END{for (i in ips){print i,ips[i]}}'
统计ip时去掉listen
ss -ant | grep ":888" |awk -F"[: \t]+" '!/LISTEN/{ips[$(NF-2)]++} END{for (i in ips){print i,ips[i]}}' | sort -k2 -nr
netstat -ant | grep ":888" | awk -F"[: \t]+" '!/LISTEN/{ips[$(NF-3)]++} END{for (i in ips){print i,ips[i]}}' | sort -k2 -nr
9.5.分析nginx、Apache日志
统计一天内访问量
grep '08/Mar/2020' access.log|wc -l
统计日志中ip的访问次数
日志输出一般为下图
192.168.81.43 - - [08/Mar/2020:16:56:50 +0800] “GET /favicon.ico HTTP/1.1” 404 570 “http://192.168.81.250:888/know_system/” “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36”
awk ‘{ips[$1]++} END{for (i in ips){print i,ips[i]}}’
解释:由于我们要统计整个文件中每一行$1列的内容出现的次数,每出现一次,值就加一,因此我们在定义数组时,就把$1的内容作为索引,每出现一次就加1,ips[$1]++,最后在遍历这个数组,打印索引后面跟着索引的值,索引就是$1的内容,值就是$1出现了多少次
实现思路:将需要统计的内容(某一字段)作为数组索引,每次加1
如果需要判断出现的次数,也看结合之前学过的if进行判断,但要写在遍历完数组的部分,例如{if(ips[i]>100){print i,ips[i]}} 1.使用grep实现
grep '08/Mar/2020' access.log | awk '{ips[$1]++} END{for (i in ips){print i,ips[i]}}' | sort -k2 -nr
192.168.81.5 25
192.168.81.210 87
192.168.81.134 987
192.168.81.14 765
192.168.81.32 19
192.168.81.99 17
192.168.81.172 176
192.168.81.43 78
192.168.81.1 346
192.1.32.8 1790
192.168.81.2 99 2.awk实现
awk '/08\/Mar\/2020/{ips[$1]++} END{for (i in ips){print i,ips[i]}}' access.log | sort -k2 -nr
192.1.32.8 1790
192.168.81.134 987
192.168.81.14 765
192.168.81.1 346
192.168.81.172 176
192.168.81.2 99
192.168.81.210 87
192.168.81.43 78
192.168.81.5 25
192.168.81.32 19 3.只输出日志中访问次数最多ip的前五个
awk '/08\/Mar\/2020/{ips[$1]++} END{for (i in ips){print i,ips[i]}}' access.log | sort -k2 -nr | head -5
192.1.32.8 1790
192.168.81.134 987
192.168.81.14 765
192.168.81.1 346
192.168.81.172 176 4.只输出日志中访问次数超过100的ip
awk '/08\/Mar\/2020/{ips[$1]++} END{for(i in ips){if(ips[i]>100){print i,ips[i]}}}' access.log | sort -k2 -nr
92.1.32.8 1790
192.168.81.134 987
192.168.81.14 765
192.168.81.1 346
192.168.81.172 176
awk '/08\/Mar\/2020/{ips[$1]++} END{for(i in ips){print i,ips[i]}}' access.log | awk '$2>100' | sort -k2 -nr
192.1.32.8 1790
192.168.81.134 987
192.168.81.14 765
192.168.81.1 346
192.168.81.172 176
9.6…awk函数
统计用户名为4个字符的用户
awk -F":" '$1~/^....$/{i++;print $1} END{print "count is "i}' /etc/passwd //利用正则4个.表示四个任意子,最后打印
awk -F":" '{if($1~/^....$/){i++;print $1}} END{print "count is "i}' /etc/passwd
length函数实现
awk -F":" 'length($1)==4{i++;print $1} END{print "count is "i}' /etc/passwd
awk -F":" '{if(length($1)==4){i++;print $1}} END{print "count is "i}' /etc/passwd
9.7.awk引入外部变量
首先定义外部变量:var=bash
gsub是全局替换,sub是单个替换
注意:不能使用单引号,gsub/sub后面要有括号
何时用不同的引号:在函数中尽量使用双引号,在函数外面可用使用单引号,'''$i'''
方法一:在双引号情况下使用
var=bash
echo "unix scripts" | awk "gsub(/unix/,\"$var\")" //全局替换
bash scripts
echo "unix scripts unix unix" | awk "sub(/unix/,\"$var\")" //只替换一次
bash scripts unix unix
echo "unix scripts unix unix" | awk "gsub(/unix/,\"$var\")"
bash scripts bash bash 方法二:使用单引号的情况
可以使用两个双引号然后里面套入单引号
var=bash
echo "unix scripts unix unix" | awk 'gsub(/unix/,"'"$var"'")'
函数外使用单引号
[root@localhost d11_awk_wbclgjsz]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 47G 7.6G 40G 17% /
devtmpfs devtmpfs 894M 0 894M 0% /dev
tmpfs tmpfs 910M 0 910M 0% /dev/shm
tmpfs tmpfs 910M 11M 900M 2% /run
tmpfs tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/sr0 iso9660 4.3G 4.3G 0 100% /media
/dev/sdb1 xfs 100G 39M 100G 1% /my_scripts
/dev/sda1 xfs 1014M 180M 835M 18% /boot
tmpfs tmpfs 182M 0 182M 0% /run/user/0
tmpfs tmpfs 182M 12K 182M 1% /run/user/42
[root@localhost d11_awk_wbclgjsz]# df -h | awk '{if($(NF-1)>10){print $NF":"$(NF-1)}}'
挂载点:已用%
/:17%
/run:2%
/media:100%
/boot:18%
显然结果是不对的,因为倒数第二列有百分号,因此不能计算,我们可以使用int函数,将函数部分引起来int($5)>10
[root@localhost d11_awk_wbclgjsz]# df -h | awk '{if (int($(NF-1))>10){print $NF":"$(NF-1)}}'
下面开始进入正题,引入外部变量
i=10
df -h |awk '{if(int($5)>'''$i'''){print $6":"$5}}' 方法三:使用awk参数-v将外部变量引入
使用这种方法不需要在使用引号和$符号
echo "unix scripts unix aaa" | awk -v "var=bash" 'gsub(/unix/,var)'
awk -v "user=root" -F":" '{if($1==user){print $0}}' /etc/passwd
10.awk企业真实实例
10.1过滤出网卡中的所有ip,不包含ipv6的地址
思路:首先ip在inet的行,正好是第二列,因此不必使用grep,直接使用awk '/inet/'即可匹配到包含inet的行,我们不要ipv6的地址,因此可以使用正则匹配,也就是$2第二列的值要匹配192.168.81.250这样的值也就是$2~/[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}/如果匹配成功就打印第二列
ifconfig | awk '/inet/{if($2~/([0-9]{1,3}.){3}[0-9]{1,3}/){print $2}}'
192.168.81.250
127.0.0.1
192.168.122.1
ifconfig |awk '/inet/{if($2~/[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}/){print $2}}'
192.168.81.250
127.0.0.1
192.168.122.1
因为包含ipv4的行时inet看开头的,inet6是ipv6的因此使用词首词尾定界符即可
ifconfig | awk '/\<inet\>/{print $2}'
10.2获取内存使用情况,如果超过80就提示error,否则就提示ok
思路:free -m查出来的结果第三列是使用的,第二列是总大小,使用的除以总大小乘以100就是磁盘使用情况,一定要主要是Mem开头的,因为我们要差的是内存,最后如果大于等于80就报错,否则就正常
free -m | awk '/^Mem/{if($3 / $2 *100 >= 80){print "free is error"} else{print "free is ok"}}'
free is ok
free -m | awk '/^Mem/{if($3 / $2 *100 >= 10){print "free is error"} else{print "free is ok"}}'
free is error
10.3获取磁盘使用情况
思路:定义一个外部变量,只打印使用超过10%的,由于第第五列包含%因此我们使用int函数只比较数值
df -h | awk -v "used=10" '{if(int($5)>used){print $6":"$5}}'
/:17%
/media:100%
/boot:18%
10.4清空本机arp缓存
arp -n //查看arp缓存
Address HWtype HWaddress Flags Mask Iface
192.168.81.2 ether 00:50:56:fb:50:ed C ens33
192.168.81.1 ether 00:50:56:c0:00:08 C ens33 arp -n | awk '/^[0-9]/{print "arp -d "$1}' //只是把清arp缓存的命令打印出来
arp -d 192.168.81.2
arp -d 192.168.81.1 arp -n | awk '/^[0-9]/{print "arp -d "$1}' | bash //也可以将打印结果交给bash来处理,相当于在bash执行输出的结果 arp -n | awk '/^[0-9]/{print $1}' | xargs -I {} arp -d {} //也可以只打印$1然后将输出的结果通过xargs -I保存到{}中,然后使用arp -d {}获取{}中的东西然后清理掉,xargs -I {}中的{}相当于接收在传给arp -d {} xargs -I {} 同样适用于导出线程
ps aux | grep 'java' | grep -v 'grep'| awk '{print $2}' | xargs -I {} jstack -l {}
10.5打印出/etc/hostswe你按中最后一个字段
awk '{print $NF}' /etc/hosts
10.6打印目录下面文件夹的名称
ll /my_scripts/ | awk '/^d/{print $NF}'
[转帖]Linux-文本处理三剑客awk详解+企业真实案例(变量、正则、条件判断、循环、数组、分析日志)的更多相关文章
- Linux文本编译工具VIM详解
Linux文本编译工具VIM详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.VIM概述 1>.vim简介 >.vi: 全称Visual editor,即文本编辑 ...
- Linux 文本对比 diff 命令详解(整理)
diff 命令详解 1.概述 windows系统下面就有不错的文本对比工具可以使用,例如常用的Beyond Compare,WinMerge都是图形界面的比较工具而且使用非常方便,如果你仅仅是在win ...
- linux脚本Shell之awk详解
一.基本介绍1.awk: awk是一个强大的文本分析工具,在对文本文件的处理以及生成报表,awk是无可替代的.awk认为文本文件都是结构化的,它将每一个输入行定义为一个记录,行中的每个字符串定义为一个 ...
- linux脚本Shell之awk详解(二)
三.printf的使用 print format 生成报表 %d 十进制有符号整数 %u 十进制无符号整数 %f 浮点数 %s 字符串 %c ...
- Linux文本处理三剑客之grep及正则表达式详解
Linux文本处理三剑客之grep及正则表达式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux文本处理三剑客概述 grep: 全称:"Global se ...
- 三剑客基础详解(grep、sed、awk)
目录 三剑客基础详解 三剑客之grep详解 1.通配符 2.基础正则 3.grep 讲解 4.拓展正则 5.POSIX字符类 三剑客之sed讲解 1.sed的执行流程 2.语法格式 三剑客之Awk 1 ...
- 关于Linux文本处理“三剑客”的一些小操作。
Linux文本处理“三剑客”,即grep.sed.awk,这是Linux中最核心 的3个命令. 一.首先做个简单的介绍: 1.awk:linux三剑客老大,过滤,输出内容,一门语言.NR代表行号. 2 ...
- Linux文本处理三剑客之——grep
一Linux文本处理三剑客之——grep Linux文本处理三剑客都支持正则表达式 grep :文本过滤( 模式:pattern) 工具,包括grep, egrep, fgrep (不支持正则表达式) ...
- Linux 文本处理三剑客之grep
文本处理都要使用正则表达式,正则表达式有: 基本正则表达式:grep或者egrep -G 扩展正则表达式:egreo或者grep -E Linux 文本处理三剑客: sed:stream editor ...
- 【linux】linux命令grep + awk 详解
linux命令grep + awk 详解 grep:https://www.cnblogs.com/flyor/p/6411140.html awk:https://www.cnblogs.com ...
随机推荐
- 伯克利:serverless是下一代计算范式
摘要:Serverless技术正是云厂商的基于规模经济的一个选择. 引子 刚过去的HC2020,华为面向多样化算力的时代,发布了DC分布式计算的三个开发套件,其中一个是元戎组件.元戎是基于函数计算的分 ...
- 数据库面试要点:关于MySQL数据库千万级数据查询和存储
摘要:百万级.千万级数据处理,核心关键在于数据存储方案设计,存储方案设计的是否合理,直接影响到数据CRUD操作.总体设计可以考虑一下几个方面进行设计考虑: 数据存储结构设计:索引设计:数据主键设计:查 ...
- MindSpore实践:对篮球运动员目标的检测
摘要:本文讲述的是MindSpore对篮球运动员目标的检测应用,通过AI技术辅助对篮球赛场进行分析. 本文分享自华为云社区<MindSpore大V博文系列:AI对篮球运动员目标的检测>,原 ...
- Java程序员都要懂得知识点:原始数据类型
摘要:Java原始数据类型有short.byte.int.long.boolean.char.float.double.原始数据是未处理的或简化的数据,它构成了物理存在的数据,原始数据具有多种存在形式 ...
- 在云南,我用华为云AI开发出千万级用户的应用
摘要:创造无限,当"燃"是开发者,华为云1024程序员节,陶新乐和大家分享独立开发者的自由之路. 本文分享自华为云社区<在云南,我用华为云AI开发出千万级用户的应用>, ...
- 华为云GaussDB(for Influx)揭秘第五期:最佳实践之子查询
摘要: GaussDB(for influx)提供灵活的子查询能力,满足海量数据场景下的高性能查询需求. 本文分享自华为云社区<华为云GaussDB(for Influx)揭秘第五期:最佳实践之 ...
- WebKit三件套(2):WebKit之JavaScriptCore/V8
WebKit作为一个浏览器引擎,其中Javascript实现包括JavaScriptCore和V8,为了能更全面的了解WebKit,我们需要深入的了解Javascript实现的基本原理.其在WebKi ...
- vue2升级vue3:webpack vue-loader 打包配置
如果没有啥特别的需求还是推荐vue-cli! vite vue3 TSX项目 虽然vite 很香,但是vite rollup 动态加载,多页面 等问题比较难搞 vite的缺点 wepback _ ...
- Nacos 1.2.1 集群搭建(一)环境准备
虚机准备.Nacos 文件准备.MySQL 5.7 安装 https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html 根据官网要求,至少3个节点 ...
- RocketMQ事务消息在订单创建和库存扣减的使用
前言 下单的过程包括订单创建,还有库存的扣减,为提高系统的性能,将库存放在redis扣减,则会涉及到Mysql和redis之间的数据同步,其中,这个过程还涉及到,必须是订单创建成功才进行库存的扣减操作 ...