有赞 Flink 实时任务资源优化探索与实践
简介: 目前有赞实时计算平台对于 Flink 任务资源优化探索已经走出第一步。
随着 Flink K8s 化以及实时集群迁移完成,有赞越来越多的 Flink 实时任务运行在 K8s 集群上,Flink K8s 化提升了实时集群在大促时弹性扩缩容能力,更好的降低大促期间机器扩缩容的成本。同时,由于 K8s 在公司内部有专门的团队进行维护, Flink K8s 化也能够更好的减低公司的运维成本。
不过当前 Flink K8s 任务资源是用户在实时平台端进行配置,用户本身对于实时任务具体配置多少资源经验较少,所以存在用户资源配置较多,但实际使用不到的情形。比如一个 Flink 任务实际上 4 个并发能够满足业务处理需求,结果用户配置了 16 个并发,这种情况会导致实时计算资源的浪费,从而对于实时集群资源水位以及底层机器成本,都有一定影响。基于这样的背景,本文从 Flink 任务内存以及消息能力处理方面,对 Flink 任务资源优化进行探索与实践。
一、Flink 计算资源类型与优化思路
1.1 Flink 计算资源类型
一个 Flink 任务的运行,所需要的资源我认为能够分为 5 类:
- 内存资源
- 本地磁盘(或云盘)存储
- 依赖的外部存储资源。比如 HDFS、S3 等(任务状态/数据),HBase、MySQL、Redis 等(数据)
- CPU 资源
- 网卡资源
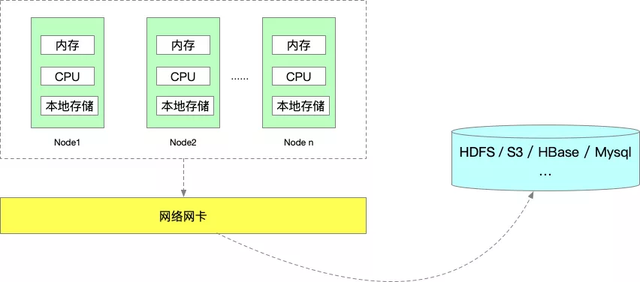
目前 Flink 任务使用最主要的还是内存和 CPU 资源,本地磁盘、依赖的外部存储资源以及网卡资源一般都不会是瓶颈,所以本文我们是从 Flink 任务的内存和 CPU 资源,两个方面来对 Flink 实时任务资源进行优化。
1.2 Flink 实时任务资源优化思路
对于 Flink 实时任务资源分析思路,我们认为主要包含两点:
- 一是从任务内存视角,从堆内存方面对实时任务进行分析。
- 另一方面则是从实时任务消息处理能力入手,保证满足业务方数据处理需求的同时,尽可能合理使用 CPU 资源。
之后再结合实时任务内存分析所得相关指标、实时任务并发度的合理性,得出一个实时任务资源预设值,在和业务方充分沟通后,调整实时任务资源,最终达到实时任务资源配置合理化的目的,从而更好的降低机器使用成本。
■ 1.2.1 任务内存视角
那么如何分析 Flink 任务的堆内存呢?这里我们是结合 Flink 任务 GC 日志来进行分析。GC 日志包含了每次 GC 堆内不同区域内存的变化和使用情况。同时根据 GC 日志,也能够获取到一个 Taskmanager 每次 Full GC 后,老年代剩余空间大小。可以说,获取实时任务的 GC 日志,使我们进行实时任务内存分析的前提。
GC 日志内容分析,这里我们借助开源的 GC Viewer 工具来进行具体分析,每次分析完,我们能够获取到 GC 相关指标,下面是通过 GC Viewer 分析一次 GC 日志的部分结果:
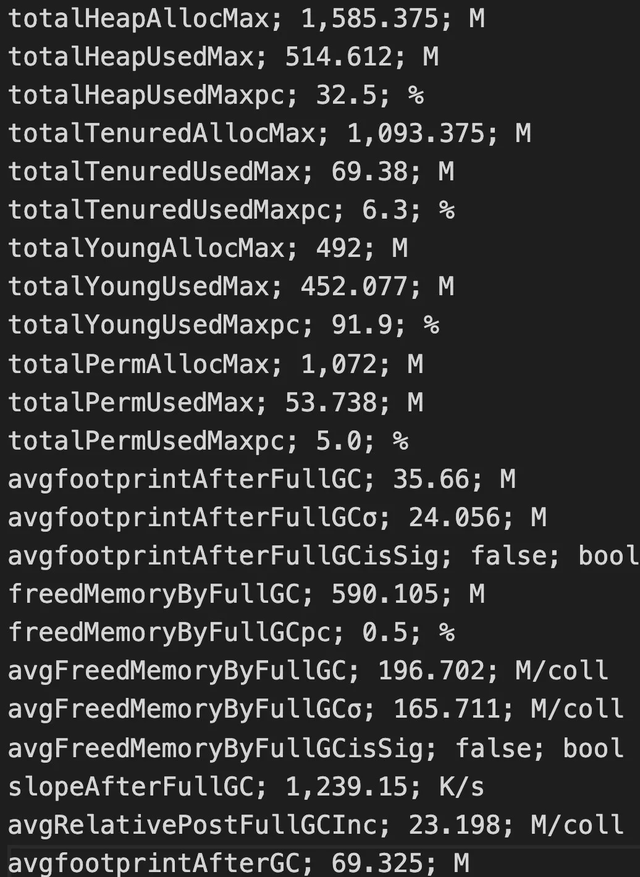
上面通过 GC 日志分析出单个 Flink Taskmanager 堆总大小、年轻代、老年代分配的内存空间、Full GC 后老年代剩余大小等,当然还有很多其他指标,相关指标定义可以去 Github 具体查看。
这里最重要的还是Full GC 后老年代剩余大小这个指标,按照《Java 性能优化权威指南》这本书 Java 堆大小计算法则,设 Full GC 后老年代剩余大小空间为 M,那么堆的大小建议 3 ~ 4倍 M,新生代为 1 ~ 1.5 倍 M,老年代应为 2 ~ 3 倍 M,当然,真实对内存配置,你可以按照实际情况,将相应比例再调大些,用以防止流量暴涨情形。
所以通过 Flink 任务的 GC 日志,我们可以计算出实时任务推荐的堆内存总大小,当发现推荐的堆内存和实际实时任务的堆内存大小相差过大时,我们就认为能够去降低业务方实时任务的内存配置,从而降低机器内存资源的使用。
■ 1.2.2 任务消息处理能力视角
对于 Flink 任务消息处理能力分析,我们主要是看实时任务消费的数据源单位时间的输入,和实时任务各个 Operator / Task 消息处理能力是否匹配。Operator 是 Flink 任务的一个算子,Task 则是一个或者多个算子 Chain 起来后,一起执行的物理载体。
数据源我们内部一般使用 Kafka,Kafka Topic 的单位时间输入可以通过调用 Kafka Broker JMX 指标接口进行获取,当然你也可以调用 Flink Rest Monitoring 相关 API 获取实时任务所有 Kafka Source Task 单位时间输入,然后相加即可。不过由于反压可能会对 Source 端的输入有影响,这里我们是直接使用 Kafka Broker 指标 JMX 接口获取 Kafka Topic 单位时间输入。
在获取到实时任务 Kafka Topic 单位时间输入后,下面就是判断实时任务的消息处理能力是否与数据源输入匹配。一个实时任务整体的消息处理能力,会受到处理最慢的 Operator / Task 的影响。打个比方,Flink 任务消费的 Kafka Topic 输入为 20000 Record / S,但是有一个 Map 算子,其并发度为 10 ,Map 算子中业务方调用了 Dubbo,一个 Dubbo 接口从请求到返回为 10 ms,那么 Map 算子处理能力 1000 Record / S (1000 ms / 10 ms * 10 ),从而实时任务处理能力会下降为 1000 Record / S。
由于一条消息记录的处理会在一个 Task 内部流转,所以我们试图找出一个实时任务中,处理最慢的 Task 逻辑。如果 Source 端到 Sink 端全部 Chain 起来的话,我们则是会找出处理最慢的 Operator 的逻辑。在源码层,我们针对 Flink Task 以及 Operator 增加了单条记录处理时间的自定义 Metric,之后该 Metric 可以通过 Flink Rest API 获取。我们会遍历一个 Flink 任务中所有的 Task , 查询处理最慢的 Task 所在的 JobVertex(JobGraph 的点),然后获取到该 JobVertex 所有 Task 的总输出,最终会和 Kafka Topic 单位时间输入进行比对,判断实时任务消息处理能力是否合理。
设实时任务 Kafka Topic 单位时间的输入为 S,处理最慢的 Task 代表的 JobVertex 的并发度为 P,处理最慢的 Task 所在的 JobVertex 单位时间输出为 O,处理最慢的 Task 的最大消息处理时间为 T,那么通过下面逻辑进行分析:
- 当 O 约等于 S,且 1 second / T * P 远大于 S 时,会考虑减小任务并发度。
- 当 O 约等于 S,且 1 second / T * P 约等于 S 时,不考虑调整任务并发度。
- 当 O 远小于 S,且 1 second / T * P 远小于 S 时,会考虑增加任务并发度。
目前主要是 1 这种情况在 CPU 使用方面不合理,当然,由于不同时间段,实时任务的流量不同,所以我们会有一个周期性检测的的任务,如果检测到某个实时任务连续多次都符合 1 这种情况时,会自动报警提示平台管理员进行资源优化调整。
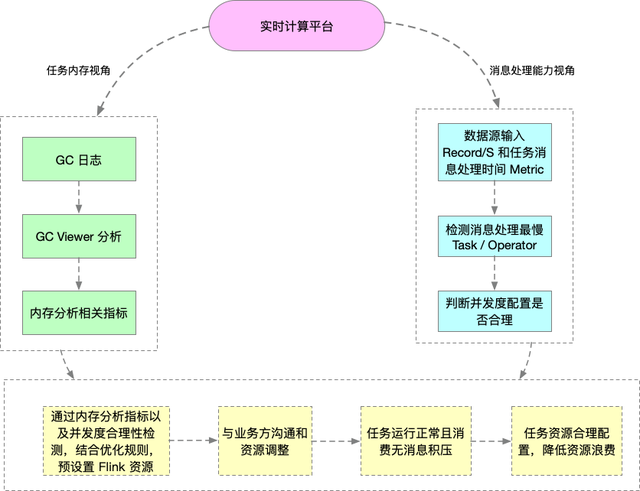
下图是从 Flink 任务的内存以及消息处理能力两个视角分析资源逻辑图:
二、从内存视角对 Flink 分析实践
2.1 Flink 任务垃圾回收器选择
Flink 任务本质还是一个 Java 任务,所以也就会涉及到垃圾回收器的选择。选择垃圾回收器一般需要从两个角度进行参考:
- 吞吐量,即单位时间内,任务执行时间 / (任务执行时间 + 垃圾回收时间),当然并不是说降低 GC 停顿时间就能提升吞吐量,因为降低 GC 停顿时间,你的 GC 次数也会上升。
- 延迟。如果你的 Java 程序涉及到与外部交互,延迟会影响外部的请求使用体验。
Flink 任务我认为还是偏重吞吐量的一类 Java 任务,所以会从吞吐量角度进行更多的考量。当然并不是说完全不考虑延迟,毕竟 JobManager、TaskManager、ResourceManager 之间存在心跳,延迟过大,可能会有心跳超时的可能性。
目前我们 JDK 版本为内部 JDK 1.8 版本,新生代垃圾回收器使用 Parallel Scavenge,那么老年代垃圾回收器只能从 Serial Old 或者 Parallel Old 中选择。由于我们 Flink k8s 任务每个 Pod 的 CPU 限制为 0.6 - 1 core ,最大也只能使用 1 个 core,所以老年代的垃圾回收器我们使用的是 Serial Old ,多线程垃圾回收在单 Core 之间,可能会有线程切换的消耗。
2.2 实时任务 GC 日志获取
设置完垃圾回收器后,下一步就是获取 Flink 任务的 GC 日志。Flink 任务构成一般是单个 JobManager + 多个 TaskManger ,这里需要获取到 TaskManager 的 GC 日志进行分析。那是不是要对所有 TaskManager 进行获取呢。这里我们按照 TaskManager 的 Young GC 次数,按照次数大小进行排序,取排名前 16 的 TaskManager 进行分析。YoungGC 次数可以通过 Flink Rest API 进行获取。
Flink on Yarn 实时任务的 GC 日志,直接点开 TaskManager 的日志链接就能够看到,然后通过 HTTP 访问,就能下载到本地。Flink On k8s 任务的 GC 日志,会先写到 Pod 所挂载的云盘,基于 k8s hostpath volume 进行挂载。我们内部使用 Filebeat 进行日志文件变更监听和采集,最终输出到下游的 Kafka Topic。我们内部会有自定义日志服务端,它会消费 Kafka 的日志记录,自动进行落盘和管理,同时向外提供日志下载接口。通过日志下载的接口,便能够下载到需要分析的 TaskManager 的 GC 日志。
2.3 基于 GC Viewer 分析 Flink 任务内存
GC Viewer 是一个开源的 GC 日志分析工具。使用 GC Viewer 之前,需要先把 GC Viewer 项目代码 clone 到本地,然后进行编译打包,就可以使用其功能。
在对一个实时任务堆内存进行分析时,先把 Flink TaskManager 的日志下载到本地,然后通过 GC Viewer 对日志进行。如果你觉得多个 Taskmanager GC 日志分析较慢时,可以使用多线程。上面所有这些操作,可以将其代码化,自动化产出分析结果。下面是通过 GC Viewer 分析的命令行:
java -jar gcviewer-1.37-SNAPSHOT.jar gc.log summary.csv
上面参数 gc.log 表示一个 Taskmanager 的 GC 日志文件名称,summary.csv 表示日志分析的结果。下面是我们平台对于某个实时任务内存分析的结果:
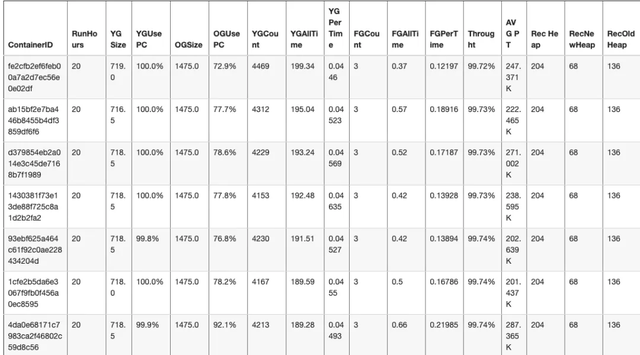
下面是上面截图中,部分参数说明:
- RunHours,Flink 任务运行小时数
- YGSize,一个 TaskManager 新生代堆内存最大分配量,单位兆
- YGUsePC,一个 TaskManager 新生代堆最大使用率
- OGSize,一个 TaskManager 老年代堆内存最大分配量,单位兆
- OGUsePC,一个 TaskManager 老生代堆最大使用率
- YGCoun,一个 TaskMnager Young GC 次数
- YGPerTime,一个 TaskMnager Young GC 每次停顿时间,单位秒
- FGCount,一个 TaskMnager Full GC 次数
- FGAllTime,一个 TaskMnager Full GC 总时间,单位秒
- Throught,Task Manager 吞吐量
- AVG PT(分析结果 avgPromotion 参数),平均每次 Young GC 晋升到老年代的对象大小
- Rec Heap,推荐的堆大小
- RecNewHeap,推荐的新生代堆大小
- RecOldHeap,推荐的老年代堆大小
上述大部分内存分析结果,通过 GC Viewer 分析都能得到,不过推荐堆大小、推荐新生代堆大小、推荐老年代堆大小则是根据 1.2.1 小节的内存优化规则来设置。
三、从消息处理视角对 Flink 分析实践
3.1 实时任务 Kafka Topic 单位时间输入获取
想要对 Flink 任务的消息处理能力进行分析,第一步便是获取该实时任务的 Kafka 数据源 Topic,目前如果数据源不是 Kafka 的话,我们不会进行分析。Flink 任务总体分为两类:Flink Jar 任务和 Flink SQL 任务。Flink SQL 任务获取 Kafka 数据源比较简单,直接解析 Flink SQL 代码,然后获取到 With 后面的参数,在过滤掉 Sink 表之后,如果 SQLCreateTable 的 Conector 类型为 Kafka,就能够通过 SQLCreateTable with 后的参数,拿到具体 Kafka Topic。
Flink Jar 任务的 Kafka Topic 数据源获取相对繁琐一些,我们内部有一个实时任务血缘解析服务,通过对 Flink Jar 任务自动构建其 PackagedProgram,PackagedProgram 是 Flink 内部的一个类,然后通过 PackagedProgram ,我们可以获取一个 Flink Jar 任务的 StreamGraph,StreamGraph 里面有 Source 和 Sink 的所有 StreamNode,通过反射,我们可以获取 StreamNode 里面具体的 Source Function,如果是 Kafka Source Sunction,我们就会获取其 Kafka Topic。下面是 StreamGraph 类截图:
获取到 Flink 任务的 Kafka Topic 数据源之后,下一步便是获取该 Topic 单位时间输入的消息记录数,这里可以通过 Kafka Broker JMX Metric 接口获取,我们则是通过内部 Kafka 管理平台提供的外部接口进行获取。
3.2 自动化检测 Flink 消息处理最慢 Task
首先,我们在源码层增加了 Flink Task 单条记录处理时间的 Metric,这个 Metric 可以通过 Flink Rest API 获取。接下来就是借助 Flink Rest API,遍历要分析的 Flink 任务的所有的 Task。Flink Rest Api 有这样一个接口:
base_flink_web_ui_url/jobs/:jobid这个接口能够获取一个任务的所有 Vertexs,一个 Vertex 可以简单理解为 Flink 任务 JobGraph 里面的一个 JobVertex。JobVertex 代表着实时任务中一段执行逻辑。
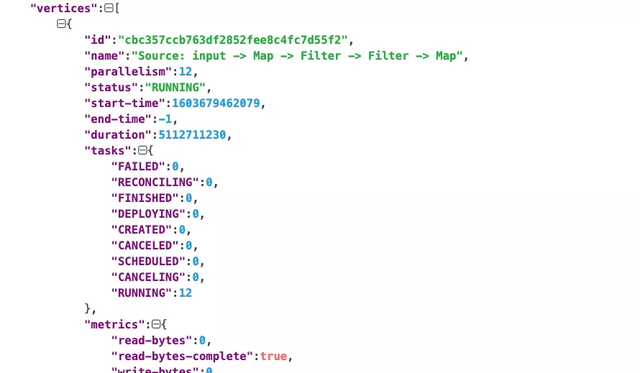
获取完 Flink 任务所有的 Vertex 之后,接下来就是获取每个 Vertex 具体 Task 处理单条记录的 metric,可以使用下面的接口:

需要在上述 Rest API 链接 metrics 之后添加 ?get=(具体meitric ),比如:metrics?get=0.Filter.numRecordsOut,0 表示该 Vertex Task 的 id,Filter.numRecordsOut 则表示具体的指标名称。我们内部使用 taskOneRecordDealTime 表示Task 处理单条记录时间 Metric,然后用 0.taskOneRecordDealTime 去获取某个 Task 的单条记录处理时间的指标。上面接口支持多个指标查询,即 get 后面使用逗号隔开即可。
最终自动化检测 Flink 消息处理最慢 Task 整体步骤如下:
- 获取一个实时任务所有的 Vertexs
- 遍历每个 Vertex,然后获取这个 Vertex 所有并发度 Task 的 taskOneRecordDealTime,并且记录其最大值
- 所有 Vertex 单条记录处理 Metric 最大值进行对比,找出处理时间最慢的 Vertex。
下面是我们实时平台对于一个 Flink 实时任务分析的结果:

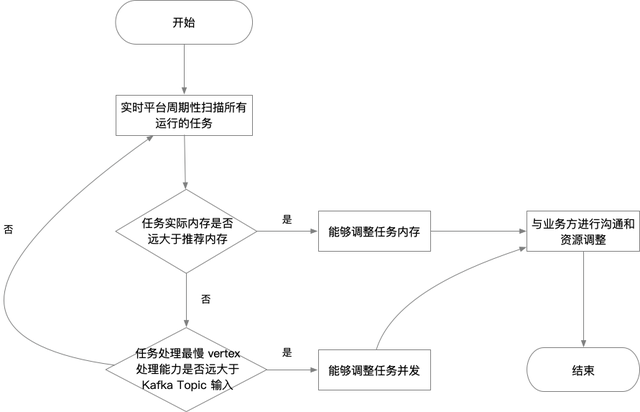
四、有赞 Flink 实时任务资源优化实践
既然 Flink 任务的内存以及消息处理能力分析的方式已经有了,那接下来就是在实时平台端进行具体实践。我们实时平台每天会定时扫描所有正在运行的 Flink 任务,在任务内存方面,我们能够结合 实时任务 GC 日志,同时根据内存优化规则,计算出 Flink 任务推荐的堆内存大小,并与实际分配的 Flink 任务的堆内存进行比较,如果两者相差的倍数过大时,我们认为 Flink 任务的内存配置存在浪费的情况,接下来我们会报警提示到平台管理员进行优化。
平台管理员再收到报警提示后,同时也会判定实时任务消息能力是否合理,如果消息处理最慢的 Vertex (某段实时逻辑),其所有 Task 单位时间处理消息记录数的总和约等于实时任务消费的 Kafka Topic 单位时间的输入,但通过 Vertex 的并发度,以及单条消息处理 Metric ,算出该 Vertex 单位时间处理的消息记录数远大于 Kafka Topic 的单位输入时,则认为 Flink 任务可以适当调小并发度。具体调整多少,会和业务方沟通之后,在进行调整。整体 Flink 任务资源优化操作流程如下:
五、总结
目前有赞实时计算平台对于 Flink 任务资源优化探索已经走出第一步。通过自动化发现能够优化的实时任务,然后平台管理员介入分析,最终判断是否能够调整 Flink 任务的资源。在整个实时任务资源优化的链路中,目前还是不够自动化,因为在后半段还需要人为因素。未来我们计划 Flink 任务资源的优化全部自动化,会结合实时任务历史不同时段的资源使用情况,自动化推测和调整实时任务的资源配置,从而达到提升整个实时集群资源利用率的目的。
同时未来也会和元数据平台的同学进行合作,一起从更多方面来分析实时任务是否存在资源优化的可能性,他们在原来离线任务资源方面积攒了很多优化经验,未来也可以参考和借鉴,应用到实时任务资源的优化中。
当然,最理想化就是实时任务的资源使用能够自己自动弹性扩缩容,之前听到过社区同学有这方面的声音,同时也欢迎你能够和我一起探讨。
作者:沈磊
本文为阿里云原创内容,未经允许不得转载
有赞 Flink 实时任务资源优化探索与实践的更多相关文章
- 【转】Android应用开发之PNG、IconFont、SVG图标资源优化详解
1 背景 最近因为一些个人私事导致好久没写博客了,多事之年总算要过去了,突然没了动力,所以赶紧先拿个最近项目中重构的一个小知识点充下数,老题重谈. 在我们App开发中大家可能都会有过如下痛疾(程序员和 ...
- 3、flink架构,资源和资源组
一.flink架构 1.1.集群模型和角色 如上图所示:当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager.由 Client 提交任务给 JobMa ...
- 【FPGA】【代码】资源优化,结构优化
资源优化 原始资源 定义时初始化和复位电路初始化都起作用,删除定义的初值后 将always块描述的组合逻辑变为时序逻辑后
- 【原创】构建高性能ASP.NET站点 第七章 如何解决内存的问题(前中篇)—托管资源优化—监测CLR性能
原文:[原创]构建高性能ASP.NET站点 第七章 如何解决内存的问题(前中篇)-托管资源优化-监测CLR性能 构建高性能ASP.NET站点 第七章 如何解决内存的问题(前中篇)—托管资源优化—监测C ...
- Xilinx资源优化问题
资源优化问题:Xilinx ise 出现资源不够的问题(ERROR:Cpld:868 - Cannot fit the design into any of the specified devices ...
- k8s pod节点调度及k8s资源优化
一.k8s pod 在节点间调度控制 k8s起pod时,会通过调度器scheduler选择某个节点完成调度,选择在某个节点上完成pod创建.当需要在指定pod运行在某个节点上时,可以通过以下几种方式: ...
- 怎么确定一个Flink job的资源
怎么确定一个Flink job的资源 Slots && parallelism 一个算子的parallelism 是5 ,那么这个算子就需要5个slot, 公式 :一个算子的paral ...
- kubernetes资源优化
kubernetes资源优化方向 系统参数限制 设置系统内核参数: vm.overcommit_memory = 0 vm.swappiness = 0 sysctl -p #生效 内核参数overc ...
- Flink实时计算pv、uv的几种方法
本文首发于:Java大数据与数据仓库,Flink实时计算pv.uv的几种方法 实时统计pv.uv是再常见不过的大数据统计需求了,前面出过一篇SparkStreaming实时统计pv,uv的案例,这里用 ...
- 5.Flink实时项目之业务数据准备
1. 流程介绍 在上一篇文章中,我们已经把客户端的页面日志,启动日志,曝光日志分别发送到kafka对应的主题中.在本文中,我们将把业务数据也发送到对应的kafka主题中. 通过maxwell采集业务数 ...
随机推荐
- 记一次由于linux buff cache引发的问题
简介 在前一段时间,在帮一个朋友处理一个问题是时,遇到这么一个问题.功能做的是一个vue分片式上传,在测试定位问题时,我就发现,分片上传14次,其中有那么一两次是上传失败,导致文件上传不完整.报了以下 ...
- Spring Boot学习日记6
@SpringBootConfiguration:SpringBoot的配置 @Configuration: spring配置类 @Component:说明这也是一个spring的组件 @Enable ...
- python高级技术(线程)
一 线程理论 1 有了进程为什么要有线程 进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率.很多人就不理解了,既然进程这么优秀,为什么还要线程 ...
- 08.Android之View事件问题
目录介绍 8.0.0.1 简述Android的事件分发机制?dispatchTouchEvent方法的作用是什么?说下View和ViewGroup分发事件? 8.0.0.2 onInterceptTo ...
- JS原生2048小游戏源码分享
最近在学习算法方面的知识,看到了一个由算法主导的小游戏,这里给大家分享下代码: 效果: 代码: <head> <meta charset="UTF-8"> ...
- mysql数据库锁MDL锁的解释
1.背景 在我们系统中有一张表它的查询概率非常高.最近有个需求,需要对这个表增加一个字段,然而在增加字段的时候发现系统中有多个业务出现了超时操作,那么这个是什么原因导致的呢?经过查阅资料发现是数据库的 ...
- 关于Dockerfile部署nginx,访问静态资源403Forbidden问题
今天项目遇到一个问题,服务器部署的nginx,在访问静态图片返回403 Forbidden. 容器是采用Dockerfile部署的,代码如下: FROM nginx:latest MAINTAINER ...
- 【已解决】git reset命令误删本地文件怎么恢复
执行 git reflog 命令可以看到曾经执行过的操作,还有版本序号. 执行 git reset --hard HEAD@{[填那个序号]} 就可以恢复本地删除的文件了!
- 【Java面试题】Spring
八.Spring 57)什么是 Spring 的依赖注入 IOC( Inversion of Control )的⼀个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象. 其中依赖注入(DI ...
- HTTP与WebSocket/WebDAV
WebSocket WebDAV