面试必问之kafka
问题1:消息队列的作用
1、 解耦
快递小哥手上有很多快递需要送,他每次都需要先电话一一确认收货人是否有空、哪个时间段有空,然后再确定好送货的方案。这样完全依赖收货人了!如果快递一多,快递小哥估计的忙疯了……如果有了便利店,快递小哥只需要将同一个小区的快递放在同一个便利店,然后通知收货人来取货就可以了,这时候快递小哥和收货人就实现了解耦!
2、 异步
快递小哥打电话给我后需要一直在你楼下等着,直到我拿走你的快递他才能去送其他人的。快递小哥将快递放在小芳便利店后,又可以干其他的活儿去了,不需要等待你到来而一直处于等待状态。提高了工作的效率。
3、 削峰
假设双十一我买了不同店里的各种商品,而恰巧这些店发货的快递都不一样,有中通、圆通、申通、各种通等……更巧的是他们都同时到货了!中通的小哥打来电话叫我去北门取快递、圆通小哥叫我去南门、申通小哥叫我去东门。我一时手忙脚乱……
我们能看到在系统需要交互的场景中,使用消息队列中间件真的是好处多多,基于这种思路,就有了丰巢、菜鸟驿站等比小芳便利店更专业的“中间件”了。
问题2:Kafka中有哪几个组件?
主题:Kafka主题是一堆或一组消息。
生产者:在Kafka,生产者发布通信以及向Kafka主题发布消息。
消费者:Kafka消费者订阅了一个主题,并且还从主题中读取和处理消息。
经纪人:在管理主题中的消息存储时,我们使用Kafka Brokers。
问题3:简单说一下ack机制
ack:producer收到多少broker的答复才算真的发送成功
- 0表示producer无需等待leader的确认(吞吐最高、数据可靠性最差)
- 1代表需要leader确认写入它的本地log并立即确认
- -1/all 代表所有的ISR都完成后确认(吞吐最低、数据可靠性最高)
问题4:Kafka 如何判断节点是否存活
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每个节点的连
接
(2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久
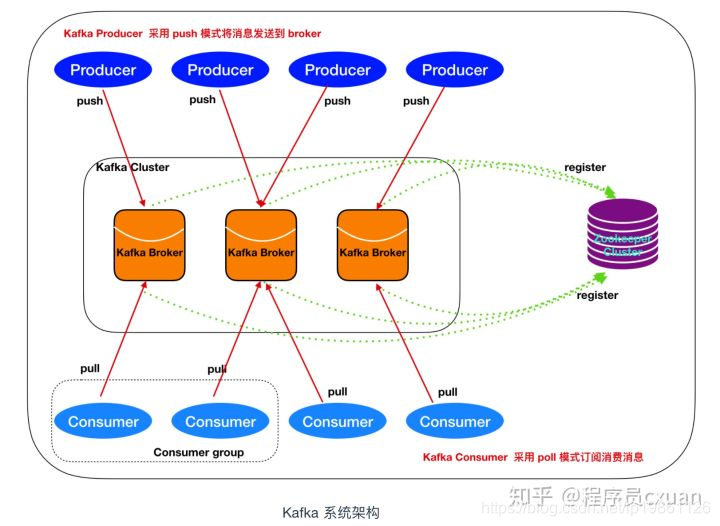
问题5:Kafka 消息是采用 Pull 模式,还是 Push 模式
Kafka 最初考虑的问题是,customer 应该从 brokes 拉取消息还是 brokers 将消息推送到
consumer,也就是 pull 还 push。在这方面,Kafka 遵循了一种大部分消息系统共同的传统
的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息
一些消息系统比如 Scribe 和 Apache Flume 采用了 push 模式,将消息推送到下游的
consumer。这样做有好处也有坏处:由 broker 决定消息推送的速率,对于不同消费速率的
consumer 就不太好处理了。消息系统都致力于让 consumer 以最大的速率最快速的消费消
息,但不幸的是,push 模式下,当 broker 推送的速率远大于 consumer 消费的速率时,
consumer 恐怕就要崩溃了。最终 Kafka 还是选取了传统的 pull 模式
Pull 模式的另外一个好处是 consumer 可以自主决定是否批量的从 broker 拉取数据。Push
模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条消息还
是缓存之后批量推送。如果为了避免 consumer 崩溃而采用较低的推送速率,将可能导致一
次只推送较少的消息而造成浪费。Pull 模式下,consumer 就可以根据自己的消费能力去决
定这些策略
Pull 有个缺点是,如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,
直到新消息到 t 达。为了避免这点,Kafka 有个参数可以让 consumer 阻塞知道新消息到达
(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发)
问题6 能说一下leader选举过程吗
我们知道Zookeeper集群中也有选举机制,是通过Paxos算法,通过不同节点向其他节点发送信息来投票选举出leader,但是Kafka的leader的选举就没有这么复杂了。
Kafka的Leader选举是通过在zookeeper上创建/controller临时节点来实现leader选举,并在该节点中写入当前broker的信息
{“version”:1,”brokerid”:1,”timestamp”:”1512018424988”}
利用Zookeeper的强一致性特性,一个节点只能被一个客户端创建成功,创建成功的broker即为leader,即先到先得原则,leader也就是集群中的controller,负责集群中所有大小事务。
当leader和zookeeper失去连接时,临时节点会删除,而其他broker会监听该节点的变化,当节点删除时,其他broker会收到事件通知,重新发起leader选举。
问题7: kafka什么情况下会rebalance
rebalance 的触发条件有五个。
- 条件1:有新的consumer加入
- 条件2:旧的consumer挂了
- 条件3:coordinator挂了,集群选举出新的coordinator
- 条件4:topic的partition新加
- 条件5:consumer调用unsubscrible(),取消topic的订阅
rebalance 发生时,Group 下所有 consumer 实例都会协调在一起共同参与,kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 consumer group 会造成比较严重的影响。在 Rebalance 的过程中 consumer group 下的所有消费者实例都会停止工作,等待 Rebalance 过程完成。
问题7.1: 能简单说一下rebalance过程吗?
主要的流程如下:
- 发送GCR请求寻找Coordinator:这个过程主要会向集群中负载最小的broker发起请求,等待成功返回后,那么该Broker将作为Coordinator,尝试连接该Coordinator
- 发送JGR请求加入该组:当成功找到Coordinator后,那么就要发起加入group的请求,表示该consumer是该组的成员,Coordinator会接收到该请求,会给集群分配一个Leader(通常是第一个),让其负责partition的分配
- 发送SGR请求:JGR请求成功后,如果发现当前Consumer是leader,那么会进行partition的分配,并发起SGR请求将分配结果发送给Coordinator;如果不是leader,那么也会发起SGR请求,不过分配结果为空
问题7.2: Rebalance有什么影响
Rebalance本身是Kafka集群的一个保护设定,用于剔除掉无法消费或者过慢的消费者,然后由于我们的数据量较大,同时后续消费后的数据写入需要走网络IO,很有可能存在依赖的第三方服务存在慢的情况而导致我们超时。
Rebalance对我们数据的影响主要有以下几点:
- 数据重复消费: 消费过的数据由于提交offset任务也会失败,在partition被分配给其他消费者的时候,会造成重复消费,数据重复且增加集群压力
- Rebalance扩散到整个ConsumerGroup的所有消费者,因为一个消费者的退出,导致整个Group进行了Rebalance,并在一个比较慢的时间内达到稳定状态,影响面较大
- 频繁的Rebalance反而降低了消息的消费速度,大部分时间都在重复消费和Rebalance
- 数据不能及时消费,会累积lag,在Kafka的TTL之后会丢弃数据
上面的影响对于我们系统来说,都是致命的。
问题7.3:怎么解决rebalance中遇到的问题呢?
要避免 Rebalance,还是要从 Rebalance 发生的时机入手。我们在前面说过,Rebalance 主要发生的时机有三个:
- 组成员数量发生变化
- 订阅主题数量发生变化
- 订阅主题的分区数发生变化
后两个我们大可以人为的避免,发生rebalance最常见的原因是消费组成员的变化。
消费者成员正常的添加和停掉导致rebalance,这种情况无法避免,但是时在某些情况下,Consumer 实例会被 Coordinator 错误地认为 “已停止” 从而被“踢出”Group。从而导致rebalance。
当 Consumer Group 完成 Rebalance 之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经 “死” 了,从而将其从 Group 中移除,然后开启新一轮 Rebalance。这个时间可以通过Consumer 端的参数 session.timeout.ms进行配置。默认值是 10 秒。
除了这个参数,Consumer 还提供了一个控制发送心跳请求频率的参数,就是 heartbeat.interval.ms。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启 Rebalance,因为,目前 Coordinator 通知各个 Consumer 实例开启 Rebalance 的方法,就是将 REBALANCE_NEEDED 标志封装进心跳请求的响应体中。
除了以上两个参数,Consumer 端还有一个参数,用于控制 Consumer 实际消费能力对 Rebalance 的影响,即 max.poll.interval.ms 参数。它限定了 Consumer 端应用程序两次调用 poll 方法的最大时间间隔。它的默认值是 5 分钟,表示你的 Consumer 程序如果在 5 分钟之内无法消费完 poll 方法返回的消息,那么 Consumer 会主动发起 “离开组” 的请求,Coordinator 也会开启新一轮 Rebalance。
通过上面的分析,我们可以看一下那些rebalance是可以避免的:
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被 “踢出”Group 而引发的。这种情况下我们可以设置 session.timeout.ms 和 heartbeat.interval.ms 的值,来尽量避免rebalance的出现。(以下的配置是在网上找到的最佳实践,暂时还没测试过)
设置 session.timeout.ms = 6s。
设置 heartbeat.interval.ms = 2s。
要保证 Consumer 实例在被判定为 “dead” 之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
将 session.timeout.ms 设置成 6s 主要是为了让 Coordinator 能够更快地定位已经挂掉的 Consumer,早日把它们踢出 Group。
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。
总之,要为业务处理逻辑留下充足的时间。这样,Consumer 就不会因为处理这些消息的时间太长而引发 Rebalance 。
问题7.4:kafka一次reblance大概要多久
1个Topic,10个partition,3个consumer
测试结果
经过几轮测试发现每次rebalance所消耗的时间大概在 80ms~100ms平均耗时在87ms左右。
问题8:如何保证kafka顺序消费
这个在我看来是一个伪命题,如果要保证顺序消费为啥要用kafka呢,只是需要做到异步或者解耦?
如果一定要做到顺序消费,肯定是可以的,但是这个浪费资源,因为kafka就是针对高并发大吞吐量而生,下面说一下顺序消费方案:
1、一个topic、一个partition、一个线程
2、一个topic、n个partition、n个线程,这里生产时需要根据需求将需要排序的数据发送到指定的message key
问题9:kafka为何这么快
Kafka 实现了零拷贝原理来快速移动数据,避免了内核之间的切换。Kafka 可以将数据记录分批发送,从生产者到文件系统(Kafka 主题日志)到消费者,可以端到端的查看这些批次的数据。批处理能够进行更有效的数据压缩并减少 I/O 延迟,Kafka 采取顺序写入磁盘的方式,避免了随机磁盘寻址的浪费,更多关于磁盘寻址的了解,请参阅 程序员需要了解的硬核知识之磁盘 。
总结一下其实就是四个要点
- 顺序读写
- 零拷贝
- 消息压缩
- 分批发送
面试必问之kafka的更多相关文章
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
- 【面试必问】python实例方法、类方法@classmethod、静态方法@staticmethod和属性方法@property区别
[面试必问]python实例方法.类方法@classmethod.静态方法@staticmethod和属性方法@property区别 1.#类方法@classmethod,只能访问类变量,不能访问实例 ...
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
- 面试必问:JVM类加载机制详细解析
前言 在Java面试中,简历上有写JVM(Java虚拟机)相关的东西,JVM的类加载机制基本是面试必问的知识点. 类的加载和卸载 JVM是虚拟机的一种,它的指令集语言是字节码,字节码构成的文件是cla ...
- 一线大厂Java面试必问的2大类Tomcat调优
一.前言 最近整理了 Tomcat 调优这块,基本上面试必问,于是就花了点时间去搜集一下 Tomcat 调优都调了些什么,先记录一下调优手段,更多详细的原理和实现以后用到时候再来补充记录,下面就来介绍 ...
- python笔记39-unittest框架如何将上个接口的返回结果给下个接口适用(面试必问)
前言 面试必问:如何将上个接口的返回结果,作为下个接口的请求入参?使用unittest框架写用例时,如何将用例a的结果,给用例b使用. unittest框架的每个用例都是独立的,测试数据共享的话,需设 ...
- 高级测试工程师面试必问面试基础整理——python基础(一)(首发公众号:子安之路)
现在深圳市场行情,高级测试工程师因为都需要对编程语言有较高的要求,但是大部分又没有python笔试机试题,所以面试必问python基础,这里我整理一下python基本概念,陆续收集到面试中python ...
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
随机推荐
- socket 端口复用 SO_REUSEPORT 与 SO_REUSEADDR
背景 在学习 SO_REUSEADDR 地址复用的时候,看到有人提到了 SO_REUSEPORT .于是也了解了一下. SO_REUSEPORT 概述 SO_REUSEPOR这个socket选项可以让 ...
- uniapp+thinkphp5实现微信扫码支付(APP支付)
前言 统一支付是JSAPI/NATIVE/APP各种支付场景下生成支付订单,返回预支付订单号的接口,目前微信支付所有场景均使用这一接口.下面介绍的是其中APP的支付的配置与实现流程 配置 1.首先登录 ...
- TI AM64x工业核心板规格书(双核ARM Cortex-A53 + 单/四核Cortex-R5F + 单核Cortex-M4F,主频1GHz)
1 核心板简介 创龙科技SOM-TL64x是一款基于TI Sitara系列AM64x双核ARM Cortex-A53 + 单/四核Cortex-R5F + 单核Cortex-M4F设计的多核工业级核心 ...
- mysql语句大全-工作中常用整理(欢迎大家在评论区继续补充)
1.NOT EXISTS 和 NOT IN SELECT COUNT(ca.aaa) FROM xx ca WHERE NOT EXISTS( SELECT label.* FROM xxx labe ...
- ubuntu16.04 安装 eclips c/c++
前言 最近需要在ubuntu16上使用eclips编译c,尝试了apt安装和官网最新包安装甚至应用商店安装,效果都不太理想,现在把我的安装方法记录一下. 正文 !!!前提,已经自己配置好了java8的 ...
- C#winform软件移植上linux的秘密,用GTK开发System.Windows.Forms
国产系统大势所趋,如果你公司的winform界面软件需要在linux上运行,如果软件是用C#开发的,现在我有一个好的快速解决方案. 世界第一的微软的Microsoft Visual Studio,确实 ...
- 【Redis】BigKey问题
面试题 海量数据里查询某一固定前缀的key 生产上如何限制 keys * / flushdb / flushall 等危险命令以防止误删误用? MEMORY USAGE 命令用过吗? BigKey问题 ...
- Linux Shell 常用命令 - 01篇
系列文章: Linux Shell 常用命令 - 02篇 0. 在线使用 Linux Shell 参考 https://www.sohu.com/a/343421845_298038 JS/UIX - ...
- java 类的执行顺序
java代码 package net.cybclass.sp; public class Test01 { public static void main(String[] args) { new c ...
- SpringBoot+Mybatis整合出现org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)的解决
在搭建自己的后台管理,遇到一个比较小问题,顺便记录了一下. 启动SpringBoot后台时,前端访问后台执行Mybatis时,出现了这样的报错: org.apache.ibatis.binding.B ...