CoST: 时间序列预测中分离季节趋势特征的对比学习《CoST: CONTRASTIVE LEARNING OF DISENTANGLED SEASONAL-TREND REPRESENTATIONS FOR TIME SERIES FORECASTING》(时序预测、表征学习、对比学习、因果关系、分离趋势季节特征)
2022/6/18 11:32,简单记录一下随笔(因为不写点东西,根本注意力不集中,看5分钟可能要摸鱼10分钟,还是要写点,突然发现,草稿箱里最早的一篇没写完的博客是去年的7月2日,救命啊,我拖了一年了,还没写完)。
GitHub:https://github.com/salesforce/CoST
ICLR2022的论文。
当前主流范式基于神经网络体系结构的端到端训练,从经典的LSTM/RNN到较新的TCN和Transformer。
受到计算机视觉和自然语言处理中表征学习最近取得的成功推动,作者们认为时间序列预测的一个更有前景的范式是:
首先学习分离的特征表征,然后是一个简单的回归微调步骤-从因果角度证明了这种范式的合理性。
根据这一原则,提出了一个新的长序列时间序列预测的时间序列表征学习框架,称为CoST。
该框架应用对比学习方法来学习分离的季节趋势表征。CoST包括时域和频域对比损失,分别用于学习区分性趋势和季节表征。
在真实数据集上进行实验,效果很好。
它还对各种主干编码器的选择以及下游回归器具有鲁棒性。
(下面的内容里,表示 表征 傻傻分不清楚...)
1. 绪论
时间序列已广泛应用于各个领域。最近,将深度学习应用于预测的研究很多,由于数据可用性和计算资源的增加,这些方法在预测文献中提供了优于传统方法的良好性能。
与传统方法相比,这些方法通过叠加一系列非线性层来执行特征提取,然后是一个专注于预测的回归层,从而联合学习特征表示和预测函数。
然而,从观测数据端到端地联合学习这些层可能会导致模型过度拟合,并捕获观测数据中包含的不可预测噪声的虚假相关性。当学习到的表征相互纠缠时,情况会更加恶化——当特征表示的一个维度对来自数据生成过程的多个本地独立模块的信息进行编码时——而一个本地独立模块经历了分布转移。图1就是这种情况的一个示例,其中观测到的时间序列由季节模块和非线性趋势模块生成。
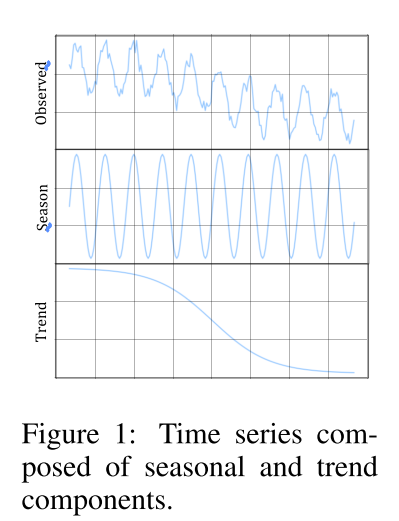
如果我们知道季节模块经历了分布偏移,我们仍然可以基于不变趋势模块进行合理的预测。
然而, 如果我们从观察到数据中学习纠缠的特征表示,那么学习到的模型将很难处理这种分布偏移,即使它只发生在数据生成过程的局部部分。总之,当数据从非平稳环境中生成时,从端到端训练方法中学习到的表示和预测关联无法很好地传递或概括,这是时间序列分析中非常常见的情况。因此,在这项工作中,我们后退一步,旨在学习对时间序列预测更有用的分离的季节趋势表征。
(个人理解:就是从纠缠混合的数据中,学习这里面独立的季节趋势表征,就比如季节趋势表征是毛线A,非线性趋势表征是毛线B,现在的数据是毛线A和毛线B缠在一起的情况,我们应该是从这一团毛线中学习出来毛线A的特征表示,就好比是把毛线团解开,解出来毛线A,解开的这个操作,就是CoST这个框架实现的。个人理解ヽ(ー_ー)ノ )
为了实现解开毛线团的操作,利用结构时间序列模型的思想,将时间序列表示为趋势、季节和误差变量的总和,并利用这些先验知识学习时间序列表征。
首先提出了通过因果透镜(这是啥翻译?)学习非纠缠季节趋势表征的必要性(不就是学习分离的季节趋势表征嘛...),并证明这种表征对误差变量的干预具有鲁棒性。然后受到大神的启发(论文里有,懒得写),建议通过数据扩充模拟对误差变量的干预,并通过对比学习学习解开的季节趋势表征。
基于上述动机,提出了一种新的对比学习框架,用于学习长序列时间序列预测(LSTF)任务的分离(非纠缠)季节趋势表征。具体而言,CoST利用模型体系结构中的归纳偏差来学习分离的季节趋势表征。经济高效地学习趋势表征,通过引入混合自回归专家来缓解回溯窗口的选择问题。它还通过利用可学习的傅里叶层来学习更强大的季节表征,该层支持频率内交互。趋势和季节表征都是通过对比损失函数学习的。趋势表征是在时域中学习的。而季节表征是通过一种新的频域对比损失学习的,这种损失鼓励区分季节表征,并回避了确定数据中存在的季节模式周期的问题。(个人理解:这种损失能够学习到有区分的季节表征,比如季节都能学习到,并且在此基础上还能学习到春夏秋冬有区别性的季节表征,个人理解,不知道对不对...)。
作者们的工作贡献如下:
1.从因果关系的角度展示了通过对比学习学习时间序列预测的分离季节趋势表征的好处。
2.提出了CoST模型,这是一种时间序列表征学习方法,利用模型体系结构中的归纳偏差来学习分离的季节和趋势表示,并结合了一种新的频域对比损失来鼓励区别性的季节表示。
3.与真实世界的基准相比,CoST比现有的最先进的方法高出了相当大的幅度,还分析了每个提出的模块的好处,并通过消融实验研究确定,对于主干编码器和下游回归器的各种选择,CoST都是有很好的鲁棒性。
2. 时间序列的季节趋势表征
(呜呜呜,不想打公式,直接截图好了,虽然很丑,但是我懒...)
问题公式: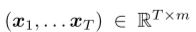 是一个时间序列,其中m是观测信号的维数。给定回溯窗口h,我们的目标是预测接下来的k步。
是一个时间序列,其中m是观测信号的维数。给定回溯窗口h,我们的目标是预测接下来的k步。
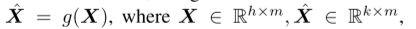 并且g(·)表示预测映射函数,
并且g(·)表示预测映射函数,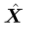 预测X的下一个k时间步。
预测X的下一个k时间步。
在这项工作中,我们不是通过g(·)联合学习表征和预测关联,而是从观察数据中学习特征表示,目的是提高预测性能。形式上,我们的目标是学习非线性特征嵌入函数(a nonlinear feature embedding function):
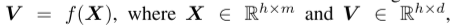 将m维原始信号映射到每个时间戳的d维潜在空间中。随后,最终时间戳Vh的学习表征被用作预测任务的下游回归器的输入。
将m维原始信号映射到每个时间戳的d维潜在空间中。随后,最终时间戳Vh的学习表征被用作预测任务的下游回归器的输入。
分离的季节趋势表征学习及其因果解释 正如B大神(论文里有全名)所述,复杂数据来自多个数据源的丰富交互作用——良好的表征应该能够理清各种解释源,使其对复杂和丰富的结构变化具有鲁棒性。否则,可能会导致捕获非i.i.d数据分发设置下的转移不好的虚假特征(这句话没懂啥意思...)。
为了实现这一目标,有必要为时间序列引入结构先验。在这里,借鉴了贝叶斯结构时间序列模型的思想(S...等人)。如图2因果图所示,我们假设观测到的时间序列数据X由误差变量E和无误差的潜变量X*生成,X*反过来,由趋势变量T和季节变量S生成。由于E是不可预测的,如果我们能够揭示X*,那么可以实现最佳预测,这就取决于T和S。
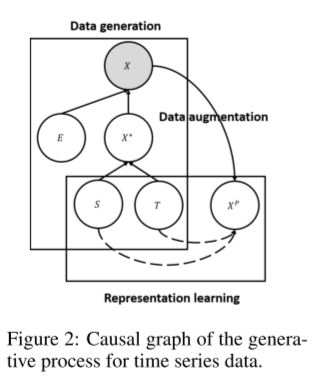 (表征学习和数据增强)
(表征学习和数据增强)首先,我们强调。现有的工作使用端到端的深度预测方法直接建模时间滞后关系和观测数据X的多元(多变量)相互作用。因此,每个X都包含不可预测的噪声E,这可能导致捕获虚假的相关性。因此,我们的目标是学习无误差的潜变量X*。
其次,通过独立机制假设(P...等人),我们可以看到季节和趋势模块不会相互影响或通知(emnn,通知是啥意思?)。因此,即使一种机制因分布转移而改变,另一种机制也保持不变。分离季节性和趋势的设计可以在非平稳环境中更好地转移或推广。此外,可以独立学习独立的季节和趋势机制,并灵活地重复使用和重新定位。
我们可以看到,对E的干预不会影响条件分布 ,比如,对于E域中的任何
,比如,对于E域中的任何 ,
,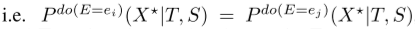 (就是,E的变化,不影响条件分布)。因此,S和T在E的变化下是保持不变的。S和T的学习表征允许我们就各种类型的错误而言,找到与最优预测稳定的关联(关于X*)。因为目标X*是未知的,受M...等人的启发,构建了一个代理对比学习任务。具体来说,我们使用数据扩充作为误差E的干预,并通过对比学习学习T和S的不变表示。由于不可能产生所有可能的误差变化,我们选择了三种典型的增强:缩放、移位和抖动,他们可以模拟大量不同的误差,有利于学习更好的表示。
(就是,E的变化,不影响条件分布)。因此,S和T在E的变化下是保持不变的。S和T的学习表征允许我们就各种类型的错误而言,找到与最优预测稳定的关联(关于X*)。因为目标X*是未知的,受M...等人的启发,构建了一个代理对比学习任务。具体来说,我们使用数据扩充作为误差E的干预,并通过对比学习学习T和S的不变表示。由于不可能产生所有可能的误差变化,我们选择了三种典型的增强:缩放、移位和抖动,他们可以模拟大量不同的误差,有利于学习更好的表示。
3. 季节趋势对比学习框架
在本节中,将介绍提出的CoST框架来学习分解的季节趋势表征。我们的目标是学习表征,以便对于每个时间步,我们都有季节和趋势分量的分离表征。
即: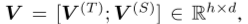 在这之中,
在这之中, ,因此d=dt+ds。
,因此d=dt+ds。
图三的a说明了整体框架。首先,我们使用编码器主干 fb :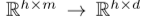 将观测值映射到潜在空间。然后,我们从这些中间表征构建趋势和季节表征。具体而言,趋势特征分离器(TFD),
将观测值映射到潜在空间。然后,我们从这些中间表征构建趋势和季节表征。具体而言,趋势特征分离器(TFD),
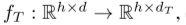 通过混合自回归专家提取趋势表征,并通过时域对比损失
通过混合自回归专家提取趋势表征,并通过时域对比损失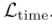 学习。季节特征分离器(SFD),
学习。季节特征分离器(SFD),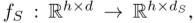 通过可学习的傅里叶层提取季节表征,并通过频域对比损失学习,该频域对比损失包括振幅分量
通过可学习的傅里叶层提取季节表征,并通过频域对比损失学习,该频域对比损失包括振幅分量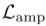 和相位分量
和相位分量 。我们将在下一节中详细描述这两个组件。
。我们将在下一节中详细描述这两个组件。
模型以端到端的方式学习,总体损失函数为: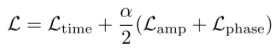 ,其中,α是一个超参数,用于平衡趋势和季节因素之间的权衡。最后,我们将趋势和季节特征分离器的输出连接起来,以获得最终的输出表示。
,其中,α是一个超参数,用于平衡趋势和季节因素之间的权衡。最后,我们将趋势和季节特征分离器的输出连接起来,以获得最终的输出表示。
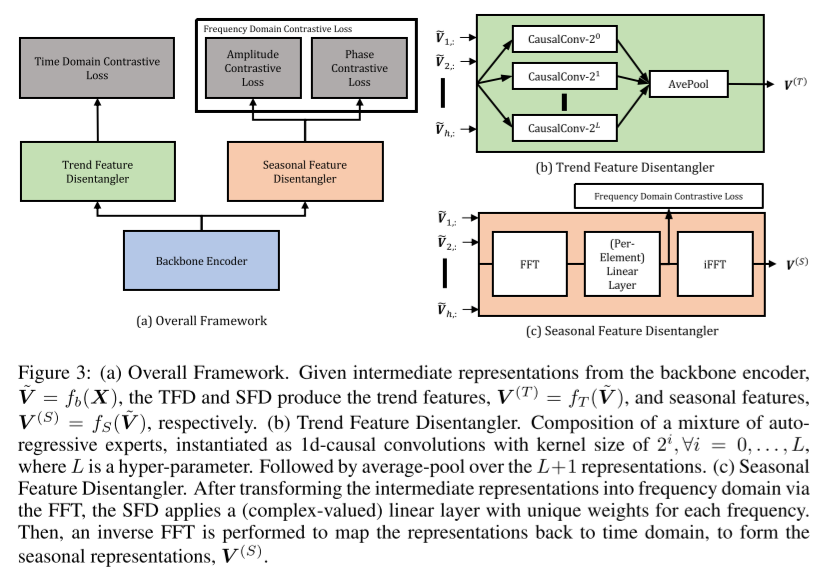
 ,TFD和SFD分别生成趋势特征
,TFD和SFD分别生成趋势特征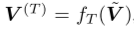 和季节特征
和季节特征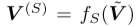 。
。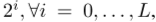 其中L是一个超参数。然后是L+1表示的平均池。(救命啊,又是拖了很久才继续看论文,继续写。 x<)
其中L是一个超参数。然后是L+1表示的平均池。(救命啊,又是拖了很久才继续看论文,继续写。 x<)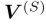 。
。3.1 趋势特征表示
提取潜在趋势对于时间序列建模至关重要。自回归滤波是一种广泛使用的方法,因为它能够从过去的观测中捕获时间滞后的因果关系。一个具有挑战性的问题是选择适当的回溯窗口-较小的窗口会导致拟合不足,而较大的模型会导致拟合过度和参数化过度。一个简单的解决方案是通过对训练或验证损失进行网格搜索来优化该超参数(H大佬.提出的...),但是这种方法的计算成本太高。因此,建议使用混合自回归专家,可以自适应的选择适当的回溯窗口。
趋势特征分解器(TFD)如图3b所示,TFD是L+1自回归专家的混合,其中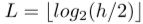 ,每个专家被实现为具有d个输入通道和
,每个专家被实现为具有d个输入通道和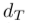 个输出通道的1d因果卷积,其中第i个专家的核大小为
个输出通道的1d因果卷积,其中第i个专家的核大小为 。每个专家输出一个矩阵
。每个专家输出一个矩阵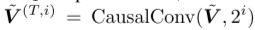 。最后,对输出执行平均池化操作,以获得最终的趋势表示,
。最后,对输出执行平均池化操作,以获得最终的趋势表示,
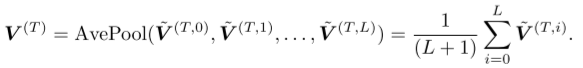
时域对比损失我们利用时域中的对比损失来学习有区别的趋势表征。具体而言,应用了对比学习的MoMo(He等人...)变体,该变体利用动量编码器获得正对的表示,并使用带有队列的动态词典获得负对的表示。在附录A中进一步阐述了对比学习的细节。然后,给定N个样本和K个负样本,时域对比损失为
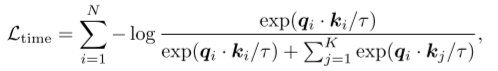
在给定样本 的情况下,我们首先为对比损耗选择一个随机时间步长T,并应用一个投影头(projection head),它是一个单层MLP来获得q,k分别是动量编码器/动态字典中相应样本的增强版本。
的情况下,我们首先为对比损耗选择一个随机时间步长T,并应用一个投影头(projection head),它是一个单层MLP来获得q,k分别是动量编码器/动态字典中相应样本的增强版本。
3.2 季节性特征表示
频域频谱分析已广泛用于季节性检测(S大佬等...)。因此,我们转向频域来处理季节表示的学习。为此,目标是解决两个问题:i)如何支持频域内交互(特征维度之间),使表征更容易编码周期性信息;ii)学习能够区分不同季节性模式的表征需要什么样的学习信号?标准主干架构无法轻松捕获频率级交互,因此,引入了SFD,它利用了可学习的傅里叶层。然后,为了在没有周期性先验知识的情况下学习这些季节性特征,对每个频域进入频域对比损耗。
季节性特征分离器(SFD)如图3c所示,SFD主要由离散傅里叶变换(DFT)组成,以将中间特征映射到频域,然后是可学习的傅里叶层。我们在附录B中提供了DFT的进一步详细信息和定义。DFT沿时间维度应用,并将时域表示映射到频域 是频域数。接下来,可学习的傅里叶层通过perelement线性层实现,该层支持频域交互。它在每个频域上应用仿射变换,每个频率都有一组唯一的复数参数,因为不希望该层具有平移不变性(为什么???不懂什么意思?)。最后,使用逆DFT操作将表示转换回时域。
是频域数。接下来,可学习的傅里叶层通过perelement线性层实现,该层支持频域交互。它在每个频域上应用仿射变换,每个频率都有一组唯一的复数参数,因为不希望该层具有平移不变性(为什么???不懂什么意思?)。最后,使用逆DFT操作将表示转换回时域。
该层的最终输出矩阵为季节表征,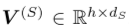 。可以表示输出的第i,k个元素为
。可以表示输出的第i,k个元素为
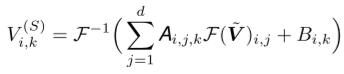
其中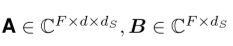 ,是每元素线性层的参数。
,是每元素线性层的参数。
频域对比损耗如图3c所示,频域损耗函数的输入是前iFFT表示,记为 。这些是频域中的复数表示。为了学习能够区分不同季节模式的表示,我们引入了频域损失函数。由于我们的数据增加可以解释为对误差变量的干预,季节信息不会改变。因此,频域中的对比损失对应于在给定频率的不同周期模式之间进行区分。为了克服用复数表示法构造损失函数的问题,每个频率可以用其振幅和相位表示法
。这些是频域中的复数表示。为了学习能够区分不同季节模式的表示,我们引入了频域损失函数。由于我们的数据增加可以解释为对误差变量的干预,季节信息不会改变。因此,频域中的对比损失对应于在给定频率的不同周期模式之间进行区分。为了克服用复数表示法构造损失函数的问题,每个频率可以用其振幅和相位表示法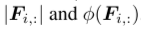 唯一地表示。然后损耗函数表示为,
唯一地表示。然后损耗函数表示为,
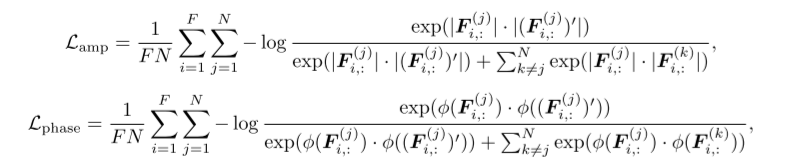
其中,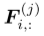 是小批量中的第j个样本,
是小批量中的第j个样本,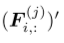 是样本的扩充版本。
是样本的扩充版本。
4. 实验
在本节中,报告了详细的CoST实证分析结果,并将其与一组不同的时间序列表示学习方法进行比较,以及与端到端监督预测方法进行比较。附录F包含运行时分析的进一步结果。
4.1 实验设置
数据集在五个真实世界的公共基准数据集上进行了广泛的实验。第一个数据集是ETT(电力变压器温度)(Zhou等人由两个小时级数据集(ETTh)和一个15分钟级数据集(ETTm)组成,测量六个电力负荷特征和“油温”,即单变量预测的选定目标值。第二个数据集是电力测量了321个客户的用电量,根据流行的基准,将数据集转换为小时水平测量值,并将“MT 320”设置为单变量预测的目标值。第三个数据集是天气,是一个每小时一次的数据集,包含美国近1600个地区的11个气候特征,将“湿球计温计”作为单变量预测的目标值。最后还将M5数据集(M大佬等)包含在附录J中。
评估设置在之前的工作之后,我们在设置上进行了实验-多变量和单变量预测。考虑到数据集的所有维度,多变量设置涉及多变量输入和输出。单变量设置涉及单变量输入和输出,它们是上述目标值。我们使用MSE和MAE作为评估指标,并执行60/20/20划分训练/验证/测试集。输入为零均值归一化,并在不同预测长度上进行评估。继(Yue等人)之后,首先在序列分割上训练自监督学习方法,并在学习的表示上训练岭回归模型,以直接预测整个预测长度。验证集用于选择合适的岭回归正则化项α,探索空间为{0.1, 0.2, 0.5, 1, 2, 5, 10, 20, 50, 100, 200, 500, 1000}。在测试集上报告评估结果。
实施细则对于CoST和所有其他表示学习方法,使用的主干编码器是时间卷积网络(遵循TS2Vec中的类似实践(Yue等人)),除非该方法包括或是架构修改(更多细节见附录E)。使用的所有方法的表示维度均为320,。我们在所有数据集上使用标准的超参数设置-批量大小为256,学习率为1E-3,动量为0.9,重量衰减为1E-4使用SGD优化器和余弦退火。时域对比损耗的MoCo实现使用256的队列大小、0.999的动量和0.07的温度。为少于100,000个样本的数据集训练200次迭代,否则训练600次迭代。有关CoST中使用的数据扩充的详细信息,请参见附录C。
4.2 结果
在基线中,在主要结果中报告了表征学习技术的性能,包括TS2Vec、TNC和MoCo的时间序列调整。由于篇幅有限,附录H中可以找到基于特征的预测方法的更广泛基准。有关基线的更多详细信息,请参见附录E。包括监督预测方法——两种基于Transformer的模型,Informer(Zhou等人)和LogTrans(Li等人),以及直接就端到端预测损耗训练的主干TCN。附录I对端到端预测方法进行了比较。
表1总结了CoST的结果和多变量设置的最佳性能基线的结果,表7(由于空间限制,在附录G中)总结了单变量设置的结果。对于端到端预测方法,TCN通常优于基于Transformer的方法Informer和LogTrans。同时,表征学习方法优于端到端预测方法,但确实存在一些情况,例如在单变量设置的某些数据集中,端到端TCN表现出奇地好。而Transformer已作为NLP等其他领域的强大模型,这表明TCN模型仍然是一个强大的基线模型,仍然应该考虑用于时间序列。

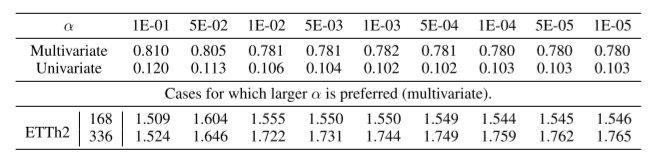
α控制总体损失函数中季节性成分的权重,
 。我们对该超参数(表2)进行了敏感性分析,并表明可以选择最佳值,并且在各种设置下都很稳健。我们选择α = 5E-04,因为它在多变量和单变量设置下都表现良好。我们注意到,α的小值源于频域对比损失,通常比时域对比损失大三个数量级,而不是季节性成分的重要性低于趋势成分的指标。此外,我们强调,总体而言,虽然选择较小的α值可以在大多数数据集上获得更好的性能,但在某些情况下,可能会首选较大的α,如表2的下半部分所示。
。我们对该超参数(表2)进行了敏感性分析,并表明可以选择最佳值,并且在各种设置下都很稳健。我们选择α = 5E-04,因为它在多变量和单变量设置下都表现良好。我们注意到,α的小值源于频域对比损失,通常比时域对比损失大三个数量级,而不是季节性成分的重要性低于趋势成分的指标。此外,我们强调,总体而言,虽然选择较小的α值可以在大多数数据集上获得更好的性能,但在某些情况下,可能会首选较大的α,如表2的下半部分所示。
4.4 消融研究
表3:ETT数据集CoST各组成部分的消融研究).TFD:趋势特征分离器,MARE:自回归专家的混合(没有MARE的TFD是指具有单个AR专家的TFD模块,具有内核大小 ),SFD:季节特征分离器,LFL:可学习傅里叶层,FDCL:频域对比损耗。†表示经过端到端训练的模型,具有监督预测损失表示†有额外对比损失。
),SFD:季节特征分离器,LFL:可学习傅里叶层,FDCL:频域对比损耗。†表示经过端到端训练的模型,具有监督预测损失表示†有额外对比损失。
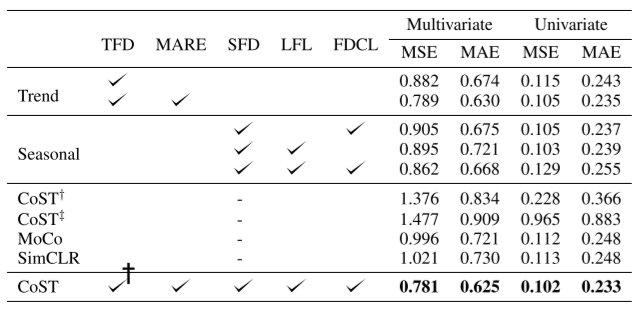


CoST的组成我们首先进行消融研究,以了解CoST中各组成部分带来的性能优势。表3显示了所有预测水平设置下ETT数据集的平均结果(表4和表5类似)。表明,趋势和季节分量都比基线(SimCLR好热MoCo)提高了性能,此外,趋势和季节分量的组合导致了最佳性能。我们进一步验证了使用有监督的预测损失端到端训练我们提出的模型架构会导致性能下降。
主干网接下来,我们验证了提出的趋势和季节性分量以及对比损耗(时域和频域)对各种主干编码器具有鲁棒性。TCN是所有其他实验中使用的默认主干编码器,我们给出了等效参数大小的LSTM和Transformer,但我们表明,我们的方法在所有三种设置上都优于竞争方法。
回归系数最后,我们证明了成本对用于预测的各种回归系数也是稳健的。除了岭回归模型外,我们还对线性回归模型和带RBF核的核岭回归模型进行了实验。如表5所示,我们还证明,在所有三种设置下,CoST都优于竞争基线。
4.5 案例研究
我们将学习到的表示形式可视化到一个包含季节和趋势成分简单合成时间序列上, 并表明CoST能够学习能够区分各种季节和趋势模式的表示形式。合成数据集是通过定义两种趋势和三种季节模式,并采用交叉积形成六个时间序列(详见附录D)生成的。在合成数据集上训练编码器后,我们可以通过T-SNE算法将其可视化(Van等人)。图4显示,我们的方法能够从数据集中学习趋势和季节模式,学习的表征具有很高的聚类性,而TS2Vec无法区分各种季节模式
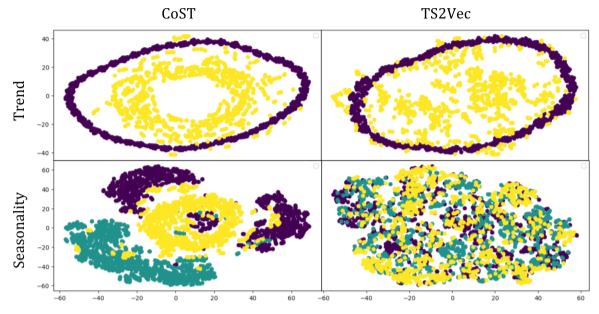
图4:CoST和TS2Vec学习表示的T-SNE可视化。(顶部)在选择单个季节性后通过可视化表示生成。颜色代表两种截然不同的趋势。(底部)选择单个趋势后通过可视化表示生成。颜色代表三种不同的季节模式。
5. 相关工作
深度预测通常被视为端到端监督学习任务,早期工作考虑使用基于RNN的模型(Lai等人)作为建模时间序列数据的自然方法。最近的工作还考虑将基于Transformer的模型用于时间序列预测(Li等人),特别侧重于解决Transforme模型的二次空间复杂性。Ore等人提出了一个单变量深度预测模型,并表明深度模型优于经典的时间序列预测技术。
虽然时间序列表征学习的近期工作侧重于表征学习的各个方面。如如何对对比进行取样(Fran等人),采用基于变换的方法(Ze等人),探索复杂的对比学习任务(El等人),除了构建时间层次表征(Yue等人),没人涉及由趋势和季节特征组成的学习表征。尽管现有的研究仅专注于时间序列分类任务,但Yue等人首先表名,通过对比学习学习的时间序列表示在深度预测基准上建立了一种新的最先进的表现。
经典时间序列分解技术(Hy等人)已被用于将时间序列分解为季节和趋势分量。以实现可解释性。最近在开发更稳健、更高效的分解方法方面展开了一些工作(Wen等人)。这些方法侧重于将原始时间序列分解为趋势和季节成分,这些成分仍然在原始输入空间中被解释为时间序列,而不是学习表征。Godf等人首次尝试使用神经网络对时间序列数据中的周期性和非周期性成分进行建模,利用周期激活函数对周期性成分进行建模。与我们的工作不同,这种方法只能为每个模型建模单个时间序列,而不能在给定回溯窗口的情况下生成分解的季节趋势表示。
6.结论
我们的工作表明,与时间序列预测的标准端到端监督训练方法相比,将表征学习和下游预测任务分离是一种更具前景的范式。我们以实证的方式证明了这一点,并从因果关系的角度对其进行了解释。根据这一原则,我们提出了CoST,这是一个对比学习框架,用于学习时间序列预测任务的分离趋势表征。大量的实证分析表明,CoST比以前最先进的方法高出了相当大的幅度,并且对各种主干编码器和回归器的选择具有鲁棒性。未来的工作将扩展我们的框架,用于其他时间序列智能任务。
啊啊啊啊啊啊啊啊啊啊啊啊啊,现在是2022/6/30 22:02,我终于在6月份水完了一篇博客。
暂时先这样,附录部分7月份见。
收拾收拾准备从实验室滚回寝室了─=≡Σ(((つ•̀ω•́)つ.
CoST: 时间序列预测中分离季节趋势特征的对比学习《CoST: CONTRASTIVE LEARNING OF DISENTANGLED SEASONAL-TREND REPRESENTATIONS FOR TIME SERIES FORECASTING》(时序预测、表征学习、对比学习、因果关系、分离趋势季节特征)的更多相关文章
- 白话贝叶斯理论及在足球比赛结果预测中的应用和C#实现
离去年“马尔可夫链进行彩票预测”已经一年了,同时我也计划了一个彩票数据框架的搭建,分析和预测的框架,会在今年逐步发表,拟定了一个目录,大家有什么样的意见和和问题,可以看看,留言我会在后面的文章中逐步改 ...
- Mol Cell Proteomics. | Prediction of LC-MS/MS properties of peptides from sequence by deep learning (通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征) (解读人:梅占龙)
通过深度学习技术根据肽段序列预测其LC-MS/MS谱特征 解读人:梅占龙 质谱平台 文献名:Prediction of LC-MS/MS properties of peptides from se ...
- 读论文《BP改进算法在哮喘症状-证型分类预测中的应用》
总结: 一.研究内容 本文研究了CAL-BP(基于隐层的竞争学习与学习率的自适应的改进BP算法)在症状证型分类预测中的应用. 二.算法思想 1.隐层计算完各节点的误差后,对有最大误差的节点的权值进行正 ...
- 卡尔曼滤波(Kalman Filter)在目标边框预测中的应用
1.卡尔曼滤波的导论 卡尔曼滤波器(Kalman Filter),是由匈牙利数学家Rudolf Emil Kalman发明,并以其名字命名.卡尔曼出生于1930年匈牙利首都布达佩斯.1953,1954 ...
- 在Node中使用ES7新特征——async、await
async与await两个关键字是在ES7中添加的新特征,旨在更加直观的书写异步函数,避免出现callback hell. callback hell是什么? readFileContents(&qu ...
- Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测 2017年12月13日 17:39:11 机器之心V 阅读数:5931 近日,Artur Suilin 等人发布了 Kaggl ...
- 教程 | Kaggle网站流量预测任务第一名解决方案:从模型到代码详解时序预测
https://mp.weixin.qq.com/s/JwRXBNmXBaQM2GK6BDRqMw 选自GitHub 作者:Artur Suilin 机器之心编译 参与:蒋思源.路雪.黄小天 近日,A ...
- 基于Streamlit_prophet玩转Prophet时序预测
既然是玩转,就得easy,在通俗搞懂核心原理的基础上,重在实践. 本文首先介绍Prophet模型基本使用,再介绍一个开箱即用的开源项目--Streamlit_prophet,进一步降低Prophet使 ...
- 作为深度学习最强框架的TensorFlow如何进行时序预测!(转)
作为深度学习最强框架的TensorFlow如何进行时序预测! BigQuant 2 个月前 摘要: 2017年深度学习框架关注度排名tensorflow以绝对的优势占领榜首,本文通过一个小例子介绍了T ...
- 强化学习中的经验回放(The Experience Replay in Reinforcement Learning)
一.Play it again: reactivation of waking experience and memory(Trends in Neurosciences 2010) SWR发放模式不 ...
随机推荐
- 动手学Avalonia:基于硅基流动构建一个文生图应用(一)
文生图 文生图,全称"文字生成图像"(Text-to-Image),是一种AI技术,能够根据给定的文本描述生成相应的图像.这种技术利用深度学习模型,如生成对抗网络(GANs)或变换 ...
- move语义和完美转发
move语义 值类别(value category)如下: lvalue:左值,在内存中有地址,可被程序员访问,可以放在赋值运算符左侧,也可以放在赋值运算符右侧,常见的左值有普通变量.字符串字面值&q ...
- 企业级环境部署:在 Linux 服务器上如何搭建和部署 Python 环境?
在大部分企业里,自动化测试框架落地都肯定会集成到Jenkins服务器上做持续集成测试,自动构建以及发送结果到邮箱,实现真正的无人值守测试. 不过Jenkins搭建一般都会部署在公司的服务器上,不会在私 ...
- NOIP2023
坐标HA 背景 打完CSP-S后觉得自主招生稳了,就想着NOIP摆烂,所以此游记仅仅是为了凑数. 正文 Day 0 不出所料,机房统一集训,但是在CSP集训后导致的期中挂分的影响下,这一想法被家长以及 ...
- Nuxt.js 环境变量配置与使用
title: Nuxt.js 环境变量配置与使用 date: 2024/7/25 updated: 2024/7/25 author: cmdragon excerpt: 摘要:"该文探讨了 ...
- 5、SpringMVC之域对象共享数据
5.1.域对象简介 请求域(request):一次请求范围内有效 会话域(session):一次会话范围内有效 应用域(application):整个应用范围内有效 5.2.环境搭建 5.2.1.右击 ...
- 【DataBase】XueSQL Training
地址: http://xuesql.cn/ Lesson0 -- 认识SQL -- [初体验]这是第一题,请你先将左侧的输入框里的内容清空,然后请输入下面的SQL,您将看到所有电影标题: SELECT ...
- 通用人工智能的基石 —— 人工智能“新基建、关键基础设施”—— 3D游戏引擎
相关: https://www.unrealengine.com/zh-CN/uses/simulation https://www.epicgames.com/site/zh-CN/careers/ ...
- 第7期(大连站)—— OpenHarmony城市技术论坛:边缘智能
PS. 为了进一步的推动国产信息化,国内的各个高校也是踊跃参与呢.
- [CEOI 2013] 千岛之国 / Adritic 题解
前言 题目链接:洛谷. 题意简述 你被困在一个被划分为 \(2500 \times 2500\) 的二维平面内!平面上有 \(n\)(\(n \leq 250000\))个岛屿你可以停留,你可以在这些 ...