PVT:特征金字塔在Vision Transormer的首次应用,又快又好 | ICCV 2021
论文设计了用于密集预测任务的纯Transformer主干网络PVT,包含渐进收缩的特征金字塔结构和spatial-reduction attention层,能够在有限的计算资源和内存资源下获得高分辨率和多尺度的特征图。从物体检测和语义分割的实验可以看到,PVT在相同的参数数量下比CNN主干网络更强大
来源:晓飞的算法工程笔记 公众号
论文: Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions

Introduction
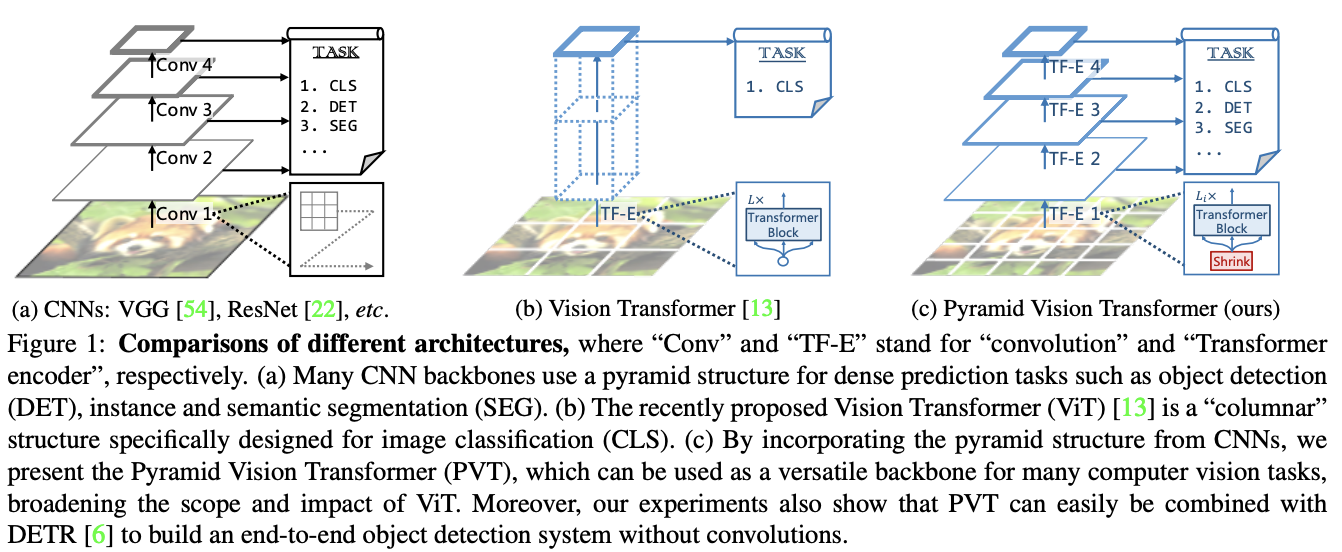
ViT用无卷积的纯Transformer模型替换CNN主干网络,在图像分类任务上取得了不错的结果。虽然ViT适用于图像分类,但直接将其用于像素级密集预测(如对象检测和分割)具有一定难度,主要原因有两点:
- ViT输出的特征图是单尺度且低分辨率的。
- 即便是常见的输入图像尺寸,ViT的计算和内存成本都相对较高。
为了解决上述问题,论文提出了一个纯Transformer主干网络Pyramid Vision Transformer(PVT),能够在许多下游任务中作为CNN的替代品,包括图像级预测以及像素级密集预测。如图1c所示,PVT通过以下几点来达成目的:
- 将更细粒度图像块(4×4像素)作为输入来学习高分辨率特征,这对密集预测任务来说至关重要。
- 引入渐进式收缩的特征金字塔,随着网络的加深而减少Transformer的序列长度,显著降低计算成本。
- 引入spatial-reduction attention(SRA)层,进一步降低学习高分辨率特征时的资源消耗。
总体而言,论文提出的的PVT具有以下优点:
- 与传统的CNN主干网络随网络深度增加而变大的局部感受野相比,PVT始终产生全局感受野,更适合检测和分割。
- 与ViT相比,特征金字塔的结构使得PVT可以更容易地嵌入到许多代表性的密集预测框架中,例如RetinaNet和Mask R-CNN。
- 可以通过将PVT与其他用于特定任务的Transformer解码器相结合来构建一个无卷积的框架,例如用于对象检测的PVT+DETR,这是第一个完全无卷积的目标检测框架。
论文的主要贡献如下:
- 提出了Pyramid Vision Transformer(PVT),这是第一个专为各种像素级密集预测任务设计的纯Transformer主干网络。将PVT和DETR结合可以构建一个端到端的目标检测框架,无需卷积、anchors和非最大抑制 (NMS)等手工设计的组件。
- 在将Transformer移植到密集预测任务时,PVT通过渐进式收缩的特征金字塔和spatial-reduction attention (SRA) 层显著减少资源消耗,使PVT能够灵活地学习多尺度和高分辨率的特征。
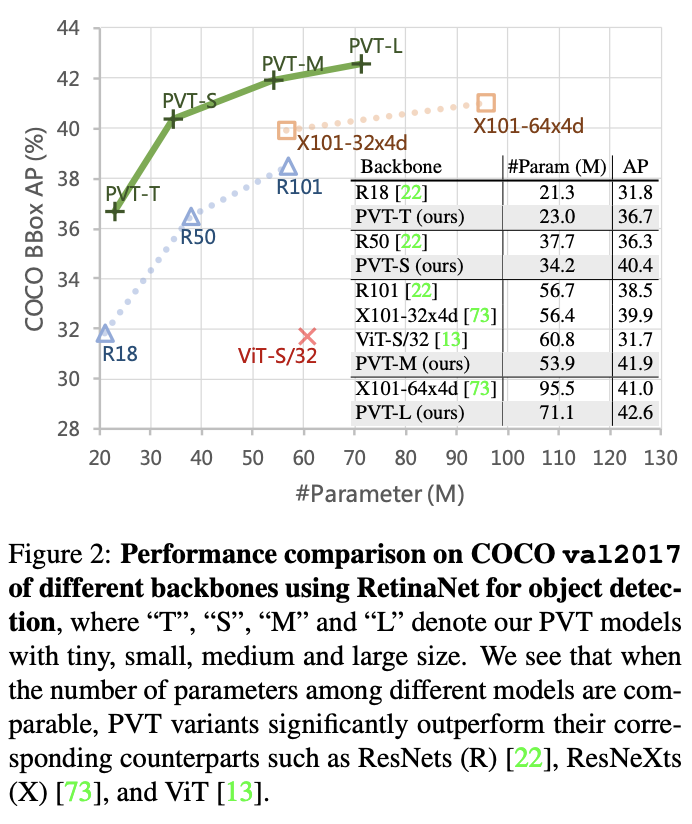
- 在包括图像分类、对象检测、实例和语义分割的几个不同的任务上测试PVT,并将其与流行的ResNets和 ResNeXts进行比较。如图2所示,与现有模型相比,不同参数和尺度的PVT可以始终达到优异的性能。
Pyramid Vision Transformer (PVT)
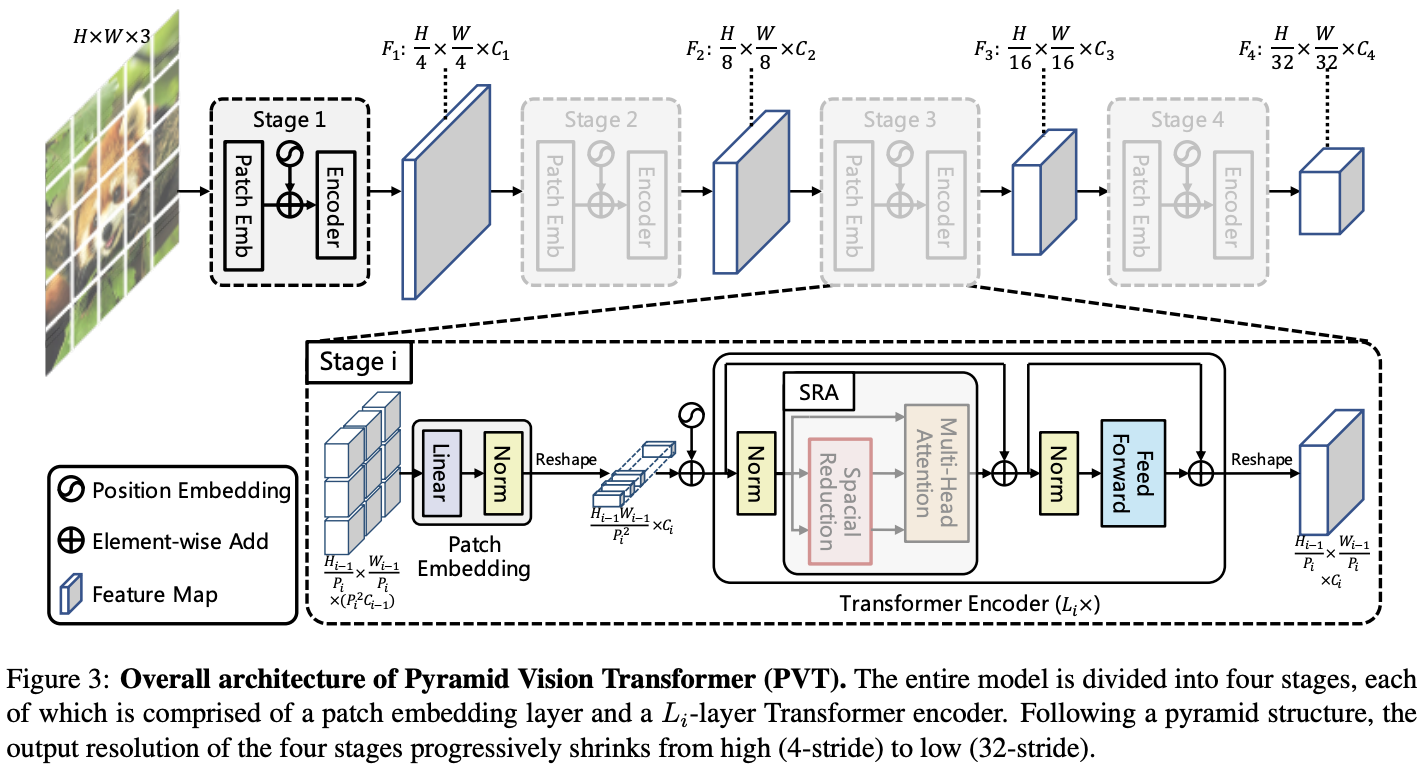
Overall Architecture
论文的核心是将特征金字塔结构加入到Transformer框架中,以便在密集预测任务中生成多尺度特征图。PVT的整体结构如图3所示,与CNN主干网络类似,包含四个生成不同尺寸特征图的Stage。所有Stage都具有类似的结构,由Patch Embedding层和\(L_i\)个Transformer encdoer层组成。
在Stage 1,给定\(H\times W\times 3\)的输入图像,先将其划分为\(\frac{HW}{4^2}\)个大小为\(4\times 4\times 3\)的图像块,将其输入到Patch Embedding层后展开为\(\frac{HW}{4^2}\times C_1\)的特征序列。然后将特征序列和Position embedding相加输入到\(L_i\)层的Transformer encdoer,最终输出大小为\(\frac{H}{4}\times \frac{W}{4}\times C_1\)的特征图\(F_1\)。
后续的Stage将前一阶段的特征输出作为输入进行同样的操作,分别输出特征图:\(F_2\)、\(F_3\)和\(F_4\),相对于输入图像的缩小比例为8、16和32倍。通过特征金字塔{\(F_1\),\(F_2\),\(F_3\),\(F_4\)},PVT可以很容易地应用于大多数下游任务,包括图像分类、目标检测和语义分割。
Feature Pyramid for Transformer
与使用不同步长卷积构造多尺度特征图的CNN主干网络不同,PVT使用渐进收缩的策略,由Patch Embedding层控制特征图的尺寸。
设定Stage \(i\)的单个特征块的大小为\(P_i\)。在Stage开始时,将输入特征图\(F_{i-1}\in \mathbb{R}^{H_{i-1}\times W_{i-1}\times C_{i-1}}\)平均划分为\(\frac{H_{i-1}W_{i-1}}{P^2_i}\)个特征块。按特征块线性映射成\(C_i\)维并展平成特征序列,经过Transofrmer encdoer处理后reshape为\(\frac{H_{i−1}}{P_i}\times \frac{W_{i−1}}{P_i}\times C_i\)的特征图,其中高度和宽度是输入的\(\frac{1}{P_i}\)倍。
这样,每个Stage都可以通过调整\(P_i\)来灵活地调整特征图的比例,从而为Transformer构建一个特征金字塔。
Transformer Encoder
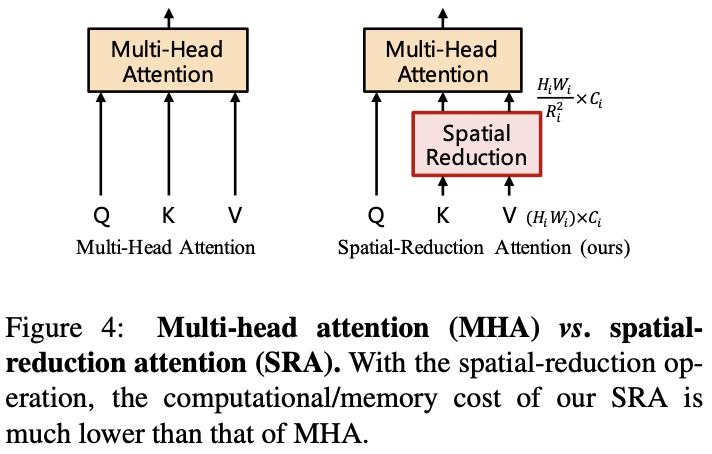
Stage \(i\)中的Transformer encoder具有\(L_i\)个encoder层,每层由一个attention层和feed-forward层组成。由于PVT需要处理高分辨率的特征图,论文提出了spatial-reduction attention(SRA)层来取代encoder中的multi-head attention(MHA)层。
SRA与MHA一样接收query Q、key K和value V作为输入,不同之处在于SRA在attention操作之前降低了K和V的特征维度,这可以在很大程度上减少计算和内存的开销。Stage \(i\)的SRA可公式化为:
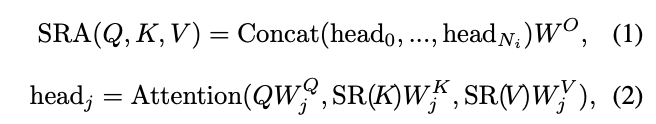
其中,\(Concat(\cdot)\)是特征拼接操作。\(W^Q_j\in \mathbb{R}^{C_i\times d_{head}}\),\(W^K_j\in \mathbb{R}^{C_i\times d_{head}}\),\(W^V_j\in \mathbb{R}^{C_i\times d_{head}}\)和\(W^O\in \mathbb{R}^{C_i\times d_{head}}\)是线性变换的参数,\(N_i\)是attention层的head数量。因此,每个head的特征维度等于\(\frac{C_i}{N_i}\)。
\(SR(\cdot)\)是用于降低输入特征序列(即K或V)的特征维度的操作,公式为:

\(x\in \mathbb{R}^{(H_i W_i)\times C_i}\)表示输入特征序列,\(R_i\)表示Stage \(i\)中attention层的缩减比例。\(Reshape(x, R_i)\)用于将输入序列\(x\) reshape成大小为\(\frac{H_i W_i}{R^2_i}\times(R^2_i C_i)\)的序列。\(W_S\in \mathbb{R}^{(R^2_i C_i)\times C_i}\)为线性映射参数,将reshape后的输入序列的维度降至\(C_i\)。\(Norm(\cdot)\)为层归一化。attention操作\(Attention(\cdot)\)与原始Transformer一样,计算公式如下:
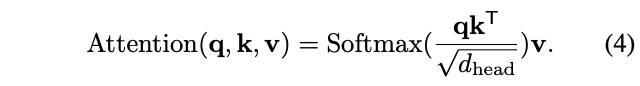
通过这些公式可以看到,SRA的计算和内存成本比MHA低\(R^2_i\)倍,可以用有限的资源处理较大的输入特征图或特征序列。
Model Details
总体而言,PVT的超参数如下所示:
- \(P_i\):Stage \(i\)的特征块大小
- \(C_i\):Stage \(i\)输出特征的通道数
- \(L_i\):Stage \(i\) encoder的层数
- \(R_i\):Stage \(i\) SRA的缩减比例
- \(N_i\):Stage \(i\) SRA的Head数量
- \(E_i\):Stage \(i\) feed-forward的expansion比例
根据ResNet的设计规则,PVT在浅层使用较小输出通道数,在中间层集中主要计算资源。
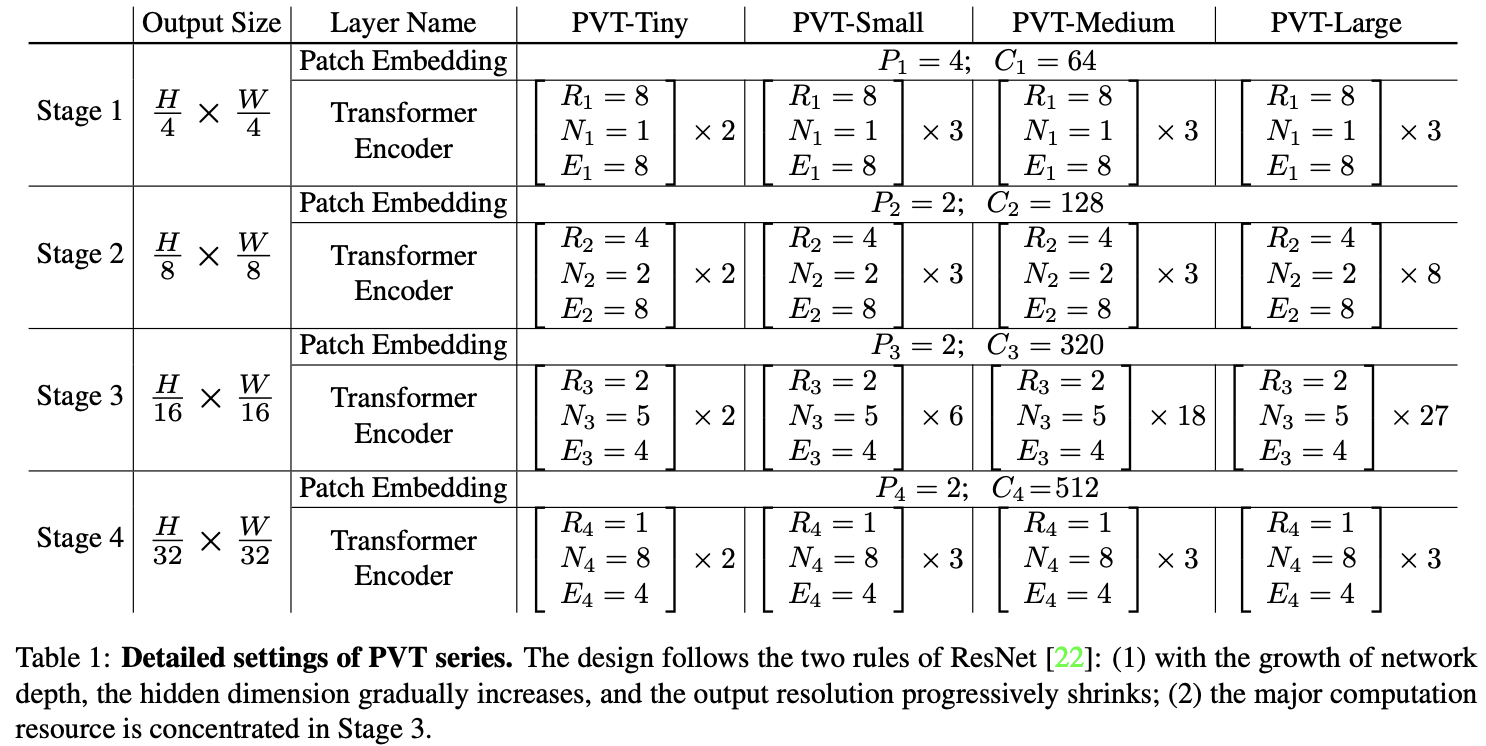
如表1所示,为了方便对比,论文设计了一系列不同尺度的PVT模型PVT Tiny、Small、Medium和Large,参数量分别对标ResNet18、50、101和152。
Discussion
ViT是与PVT最相关的研究,论文特意对它们之间的关系和区别进行了说明:
- PVT和ViT都是无卷积的纯Transformer模型,主要区别是特征金字塔结构。ViT与传统Transformer一样,输出序列的长度与输入相同,这意味着ViT的仅输出单尺度特征。
- 由于资源有限,ViT的输入都是粗粒度的(图像块大小为16或32像素),其输出分辨率相对较低(16步长或32步长)。因此,很难将ViT直接应用于需要高分辨率或多尺度特征图的密集预测任务。
PVT加入了渐进收缩的特征金字塔,可以像传统的CNN主干网络一样生成多尺度特征图。此外,PVT还加入了一种简单但高效的attention层SRA,能够处理高分辨率特征地图并减少计算/内存消耗。得益于上述设计,PVT与ViT相比具有以下优点:
- 更灵活,可以在不同阶段生成不同比例/通道的特征图。
- 更通用,可以很轻松地嵌入大多数下游任务模型中发挥作用。
- 对计算/内存更友好,可以处理更高分辨率的特征图或更长的特征序列。
Application to Downstream Tasks
Image-Level Prediction
图像分类是图像级预测中最经典的任务,论文设计了一系列不同尺度的PVT模型PVT Tiny、Small、Medium和Large,其参数量分别对标ResNet18、50、101和152。
在进行图像分类时,遵循ViT和DeiT的做法将可学习的分类token附加到最后的阶段的输入,然后使用FC层对token对应的输出进行分类。
Pixel-Level Dense Prediction
在下游任务中,经常需要在特征图上执行像素级分类或回归的密集预测,比如目标检测和语义分割。将PVT模型应用于三种具有代表性的密集预测方法:RetinaNet、Mask RCNN和Semantic FPN,基于这些方法来对比不同主干网络的有效性,实现细节如下:
- 与ResNet一样,使用在ImageNet上预先训练的权重初始化PVT主干网络。
- 使用PVT输出的特征金字塔{\(F_1\),\(F_2\),\(F_3\),\(F_4\)}作为FPN的输入,然后将FPN的特征图输入后续检测/分割Head。
- 在训练检测/分割模型时,PVT的所有权值都不会被冻结。
- 由于检测/分割的输入可以是任意形状,因此在ImageNet上预先训练的位置嵌入不能直接使用,需要根据输入分辨率对预训练的位置嵌入执行双线性插值。
Experiment
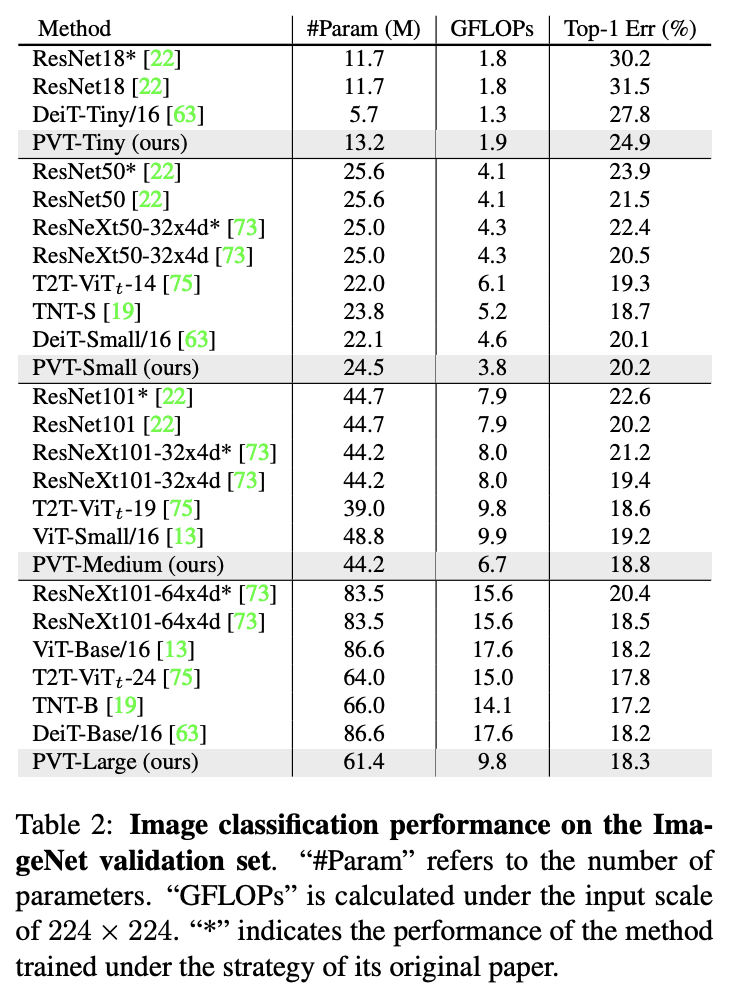
ImageNet上的性能对比。
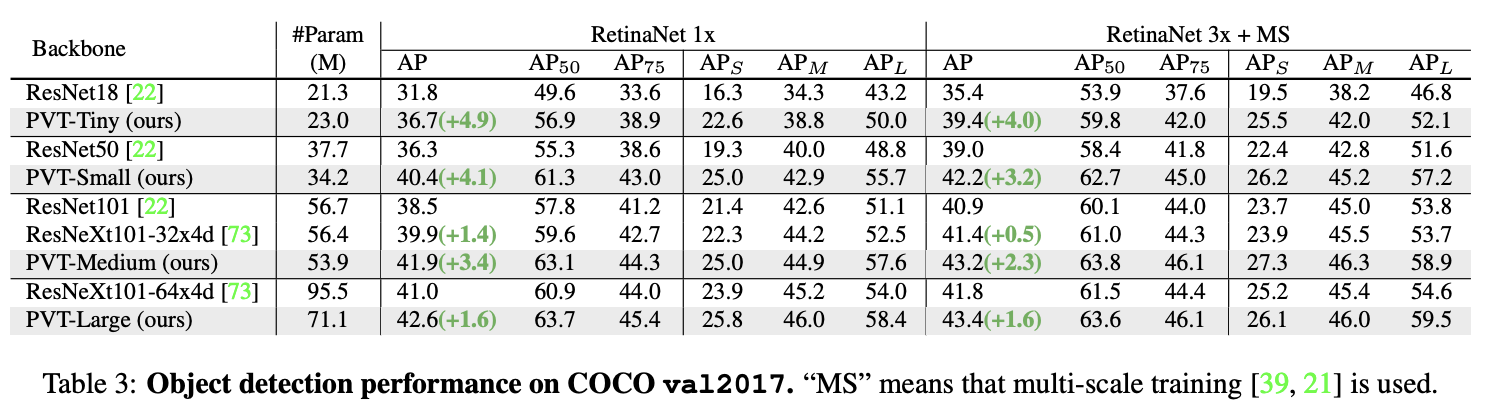
COCO val2017上的目标检测性能。
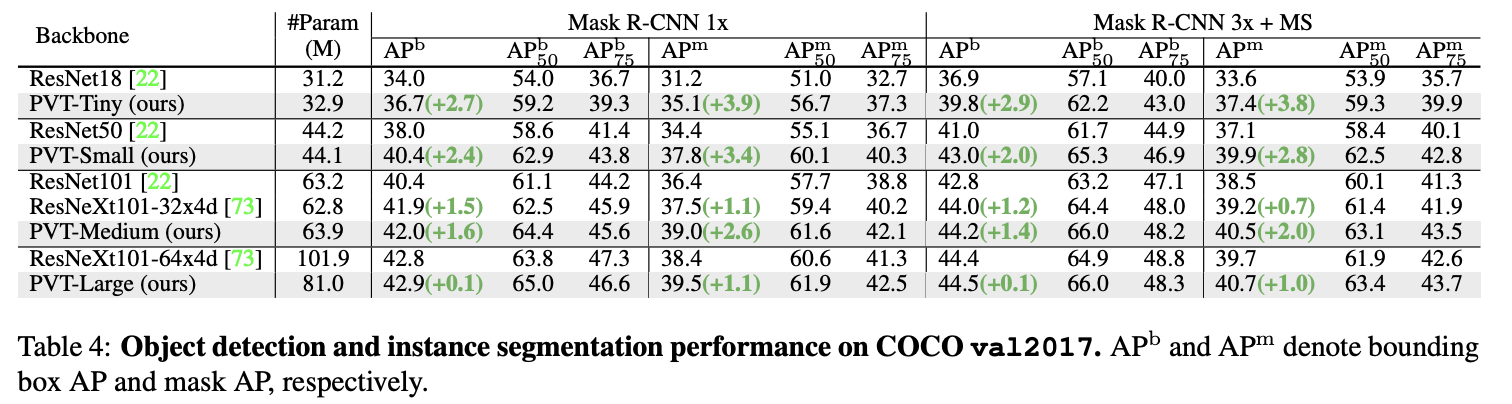
COCO val2017上的实例分割性能。
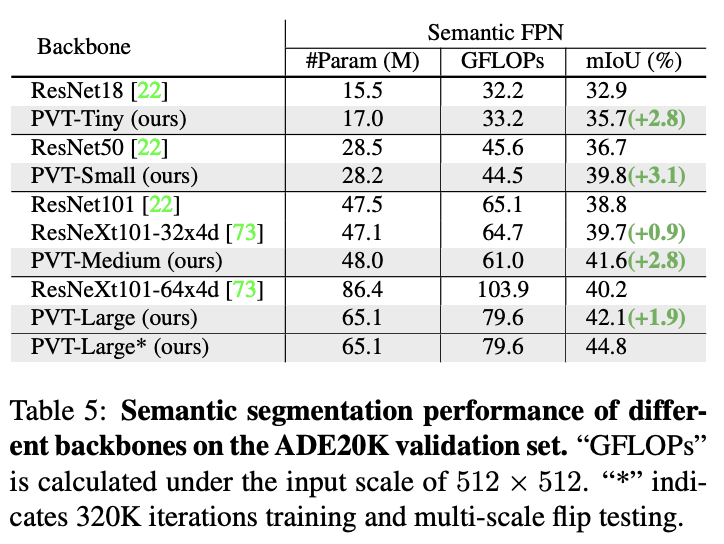
ADE20K上的语义分割性能。

与DETR结合的纯Transformer目标检测性能。
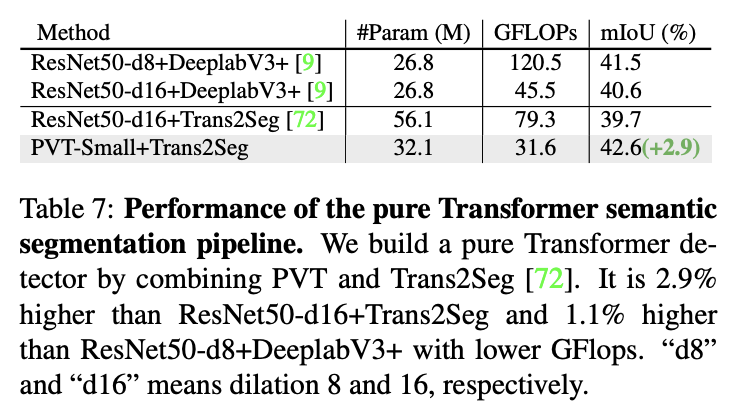
与Trans2Seg结合的纯Transformer语义分割性能。
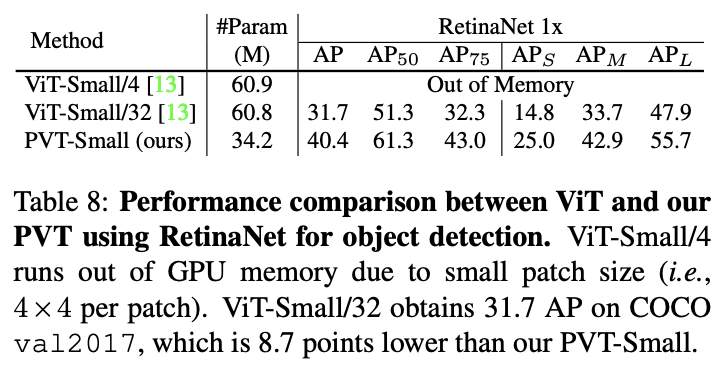
与ViT作为主干网络的目标检测性能对比。
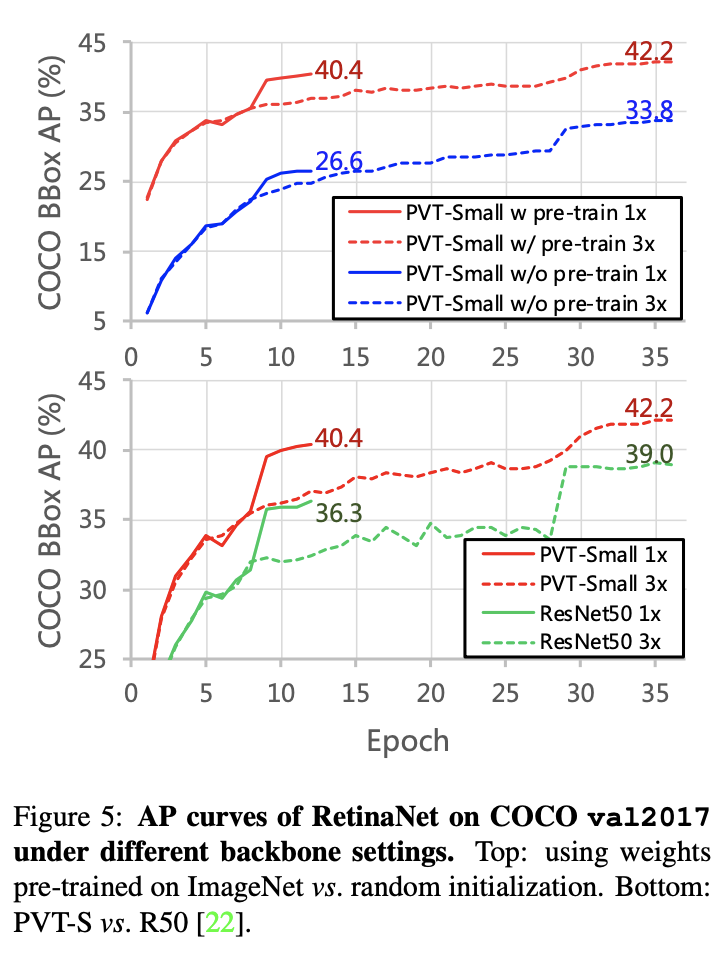
不同训练周期以及预训练对检测性能的影响
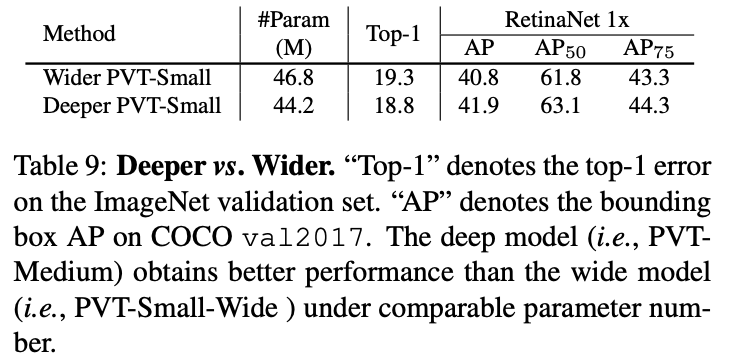
深度和参数对检测性能的影响。
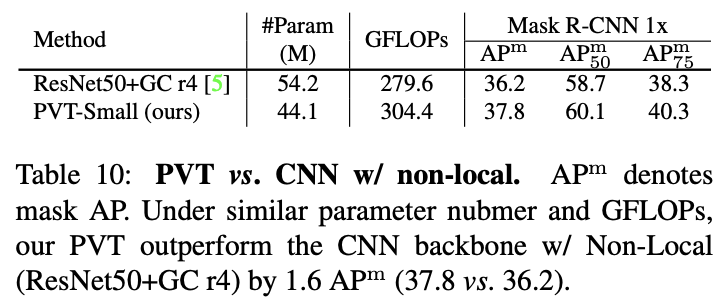
与加上non-local的CNN网络的性能对比。
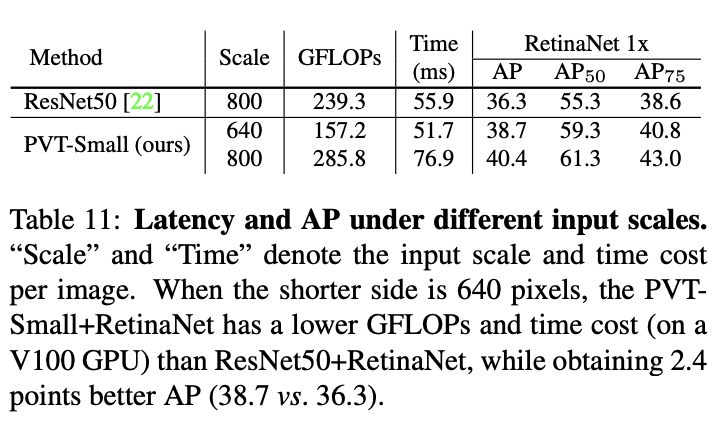
输入尺寸对性能的影响。

输入分辨率与参数量的关系。

目标检测、实例分割、语义分割的结果可视化。
Conclusion
论文设计了用于密集预测任务的纯Transformer主干网络PVT,包含渐进收缩的特征金字塔结构和spatial-reduction attention层,能够在有限的计算资源和内存资源下获得高分辨率和多尺度的特征图。从物体检测和语义分割的实验可以看到,PVT在相同的参数数量下比CNN主干网络更强大。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

PVT:特征金字塔在Vision Transormer的首次应用,又快又好 | ICCV 2021的更多相关文章
- 特征金字塔网络Feature Pyramid Networks
小目标检测很难,为什么难.想象一下,两幅图片,尺寸一样,都是拍的红绿灯,但是一副图是离得很近的拍的,一幅图是离得很远的拍的,红绿灯在图片里只占了很小的一个角落,即便是对人眼而言,后者图片中的红绿灯也更 ...
- 常见特征金字塔网络FPN及变体
好久没有写文章了(对不起我在划水),最近在看北京的租房(真真贵呀). 预告一下,最近无事,根据个人多年的证券操作策略和自己的浅显的AI时间序列的算法知识,还有自己Javascript的现学现卖,在微信 ...
- SPPNet(特征金字塔池化)学习笔记
SPPNet paper:Spatial pyramid pooling in deep convolutional networks for visual recognition code 首先介绍 ...
- 特征金字塔网络 FPN
一. 提出背景 论文:Feature Pyramid Networks for Object Detection [点击下载] 在传统的图像处理方法中,金字塔是比较常用的一种手段,像 SIFT 基于 ...
- QT5.6,5.7,5.8的新特征以及展望(Qt5.7首次正式支持Qt3D,以前都是预览版)
https://wiki.qt.io/New_Features_in_Qt_5.6 (跨平台High-DPI,改进WebEngine到45,支持WIN 10,Canvas3D,3D) https:// ...
- 目标检测论文解读13——FPN
引言 对于小目标通常需要用到多尺度检测,作者提出的FPN是一种快速且效果好的多尺度检测方法. 方法 a,b,c是之前的方法,其中a,c用到了多尺度检测的思想,但他们都存在明显的缺点. a方法:把每图片 ...
- paper 156:专家主页汇总-计算机视觉-computer vision
持续更新ing~ all *.files come from the author:http://www.cnblogs.com/findumars/p/5009003.html 1 牛人Homepa ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
- 图像分类(三)GoogLenet Inception_v3:Rethinking the Inception Architecture for Computer Vision
Inception V3网络(注意,不是module了,而是network,包含多种Inception modules)主要是在V2基础上进行的改进,特点如下: 将滤波器尺寸(Filter Size) ...
- SEPC:使用3D卷积从FPN中提取尺度不变特征,涨点神器 | CVPR 2020
论文提出PConv为对特征金字塔进行3D卷积,配合特定的iBN进行正则化,能够有效地融合尺度间的内在关系,另外,论文提出SEPC,使用可变形卷积来适应实际特征间对应的不规律性,保持尺度均衡.PConv ...
随机推荐
- 使用 Grafana 统一监控展示-对接 Zabbix
概述 在某些情况下,Metrics 监控的 2 大顶流: Zabbix: 用于非容器的虚拟机环境 Prometheus: 用于容器的云原生环境 是共存的.但是在这种情况下,统一监控展示就不太方便,本文 ...
- .Net 代码分析工具对比 visual studio 2022 current
目录 原因 背景知识 名词解释 分析器 分析器在IDE里 目标 查找思路及过程 CodeMaid Roslyn StyleCop.Analyzer StyleCop? StyleCop.Analyze ...
- 实例讲解昇腾 CANN YOLOV8 和 YOLOV9 适配
本文分享自华为云社区<昇腾 CANN YOLOV8 和 YOLOV9 适配>,作者:jackwangcumt. 1 概述 华为昇腾 CANN YOLOV8 推理示例 C++样例 , 是基于 ...
- sql 语句系列(加减乘除与平均)[八百章之第十四章]
avg的注意事项 一张t2表: select * from t2 select AVG(sal) from t2 得到的结果是: 本来我们得到的结果应该是10的.但是得到的结果确实15. 这是因为忽略 ...
- redis命令和lua实现分布式锁
Redis分布式锁关键 SETNX 语法: SETNX key value 如果key不存在,则存储(key:value)值,返回1 如果key已经不存在,则不执行操作,返回0 因为这个命令的性质,多 ...
- springboot获取七牛云空间文件列表及下载功能
原文摘自:https://www.codernav.com 第一步:新建springboot项目,引入jar包,其中hutool-all是工具类,用来写文件下载,可以随意更换. <!--工具类- ...
- 如何在ubuntu上安装QQ音乐
最简单易懂的安装QQ音乐教程,亲测可用!教程如下: 点击下方网址,进入QQ音乐下载页网址: https://y.qq.com/download/download.html 页面 点击Linux下方的下 ...
- 【Oracle】在PL/SQL中使用sql实现插入排序
[Oracle]在PL/SQL中使用sql实现插入排序 一般来说,SQL要排序的话直接使用order by即可 不一般来说,就是瞎搞,正好也可以巩固自己的数据结构基础,主要也发现没有人用SQL去实现这 ...
- 为了让你在“口袋奇兵”聊遍全球,Serverless 做了什么?
简介: 江娱互动是一家新兴的游戏企业,自 2018 年成立伊始,江娱互动就面向广阔的全球游戏市场,通过创造有趣的游戏体验,在竞争激烈的游戏市场占得一席之地.仅仅 2 年的时间,江娱互动就凭借 Topw ...
- Duang,您的钉钉应用已上线!云开发5分钟快速打造钉钉会议室预定系统
简介: 5分钟可以干什么?喝一杯咖啡,回一封邮件,还是开发上线一个钉钉应用.云开发平台联合钉钉开发平台推出0门槛打造你的第一个钉钉应用的活动,完成相应任务后,即可领取精美奖品.春暖花开,领个背包去踏春 ...