算法笔记_python
算法
概念
一个计算过程,解决问题的方法。
“程序” = 数据 + 算法
"算法" = 数据结构 + 控制流程
时间复杂度
时间复杂度是用来估计算法运行时间的一个式子(单位)。
一般来说,时间复杂度高的算法比复杂度低的算法慢。
常见的时间复杂度(按效率排序):
O(1) < O(logn) < O(n) < O(nlogn) < O(n²) < O(n²logn) < O(n³)
复杂问题的时间复杂度:
O(n!) O(2^n). O(n^n)
# O(1)
print('hello world')
# O(n)
for i in range(n):
print('hello world')
# O(n²)
for i in range(n):
for j in range(n):
print('hello world')
# O(n³)
for i in range(n):
for i in range(n):
for i in range(n):
print('hello world')
# O(logn)
while n > 1:
print(n)
n = n // 2
"""
n的输出为: ==> 2⁶ = 64
64 log₂64 = 6
32
16
8
4 所以时间复杂度记为:O(log₂n)或O(logn)
2 ps: 当算法过程中出现循环折半的时候,复杂度式子中会出现logn
"""
上面的代码我们可以用时间复杂度来表示对应的运行效率
分别表示为:O(1) O(n) O(n²) O(n³) O(log₂n)
如何快速判断算法复杂度
确认问题规模n
循环减半过程--> logn
k层关于n的循环 --> n^k
空间复杂度
空间复杂度:用来评估算法内存占用大小的式子
空间复杂度的表示方式与时间复杂度完全一样
算法使用了几个变量:O(1)
算法使用了长度为n的一维列表:O(n)
算法使用了m行n列的二维列表:O(mn)
空间换时间
递归原理
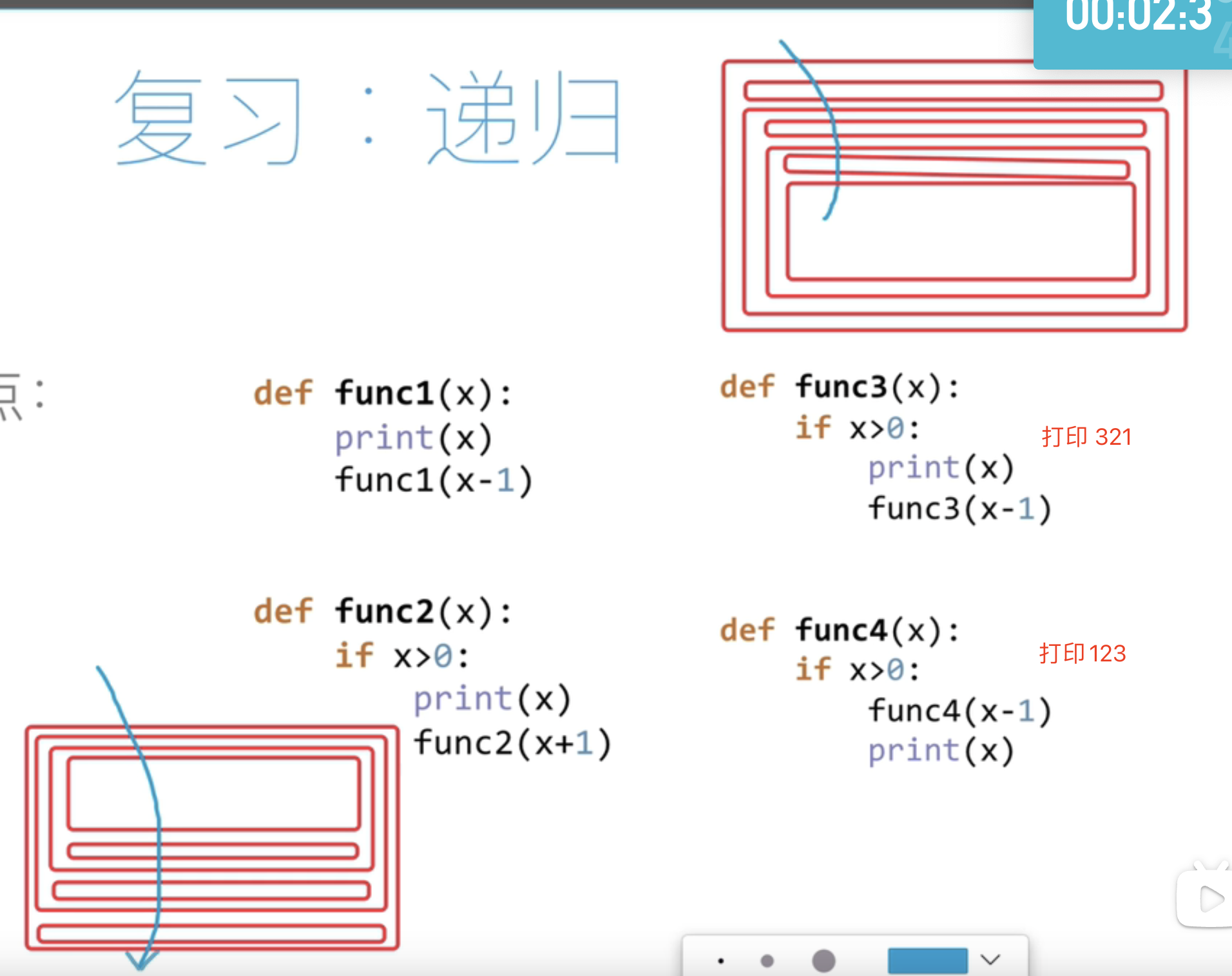
func3先打印在执行函数,func4先执行函数在打印
汉诺塔问题

# 使用递归解决
"""
思路:
将汉诺塔想象为上下两部分,上面部分的就是n-1个,下面部分就剩最后一个
经过3步最后将汉诺塔从a柱子移动到了c柱子
"""
def hanoi(n, a, b, c):
"""
n 表示汉诺塔的层数
a b c 的含义表示:从a经过b移动到了c(只是针对这三个对应的位置)
"""
if n > 0:
hanoi(n-1, a, c, b) # 第一步:将上面部分 从a经过c移ang动到了b
print('moving from %s to %s' % (a, c)) # 第二步:将下面部分 从a移动到了c
hanoi(n-1, b, a, c) # 第三步:将上面部分从b经过a移动到了c
hanoi(3, 'A', 'B', 'C')
"""
moving from A to C
moving from A to B
moving from C to B
moving from A to C
moving from B to A
moving from B to C
moving from A to C
"""

顺序查找
顺序查找,也叫线性查找,从列表的第一个元素开始,顺序进行搜索,直到找到元素或搜素到列表最后一个元素为止。
时间复杂度:O(n)
def liner_search(lst, val):
for i, v in enumerate(lst):
if v == val:
return i
return None
a = liner_search([1, 2, 3, 4, 5, 6, 7, 8], 3)
print(a)
二分查找
二分查找:又叫折半查找,从有序列表的初始候选区
li[0:n]开始,通过对待查找的值与候选区中间值的比较,可以使候选区减少一半。列表是有序的
时间复杂度:O(logn)
def binary_search(lst, val):
"""
left right 指的都是lst中元素的索引, mid 指的中间值
"""
left = 0
right = len(lst) - 1
while left <= right: # 候选区有值
mid = (left + right) // 2
if lst[mid] == val:
return mid
elif lst[mid] > val: # 待查找值在mid的左侧
right = mid - 1
else: # 待查找值在mid的右侧
left = mid + 1
else:
return None
a = binary_search([1, 2, 3, 4, 5, 6, 7, 8], 3)
print(a)
列表排序
排序:将一组“无序”的记录序列调整为“有序”的记录序列。
列表排序:将无序列表变为有序列表
升序和降序
内置排序函数:sort()
常见的排序算法
- 排序LowB三人组
- 冒泡排序
- 选择排序
- 插入排序
- 排序NB三人组
- 快速排序
- 堆排序
- 归并排序
- 其他排序
- 希尔排序
- 计数排序
- 基数排序
LowB 三人组
冒泡排序
列表每两个相邻的数,如果前面比后面大,则交换这两个数
一趟排序完成后,则无序区减少一个数,有序区增加一个数
时间复杂度:O(n²)

import random
def bubble_sort(lst):
for i in range(len(lst) - 1): # i:第几趟 len(lst) - 1: 循环的趟数
for j in range(len(lst) - i - 1): # j: 指针 len(lst) -i - 1: 循环一趟指针经过的次数
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
lst = [random.randint(0, 10000) for i in range(1000)]
bubble_sort(lst)
print(lst)
优化:
# 如果前面几次已经排好序了,则后面就不需要在循环
import random
def bubble_sort(lst):
for i in range(len(lst) - 1): # i:第几趟 len(lst) - 1: 循环的趟数
exchange = False
for j in range(len(lst) - i - 1): # j: 指针 len(lst) -i - 1: 循环一趟指针经过的次数
if lst[j] > lst[j + 1]:
lst[j], lst[j + 1] = lst[j + 1], lst[j]
exchange = True
if not exchange:
return
lst = [random.randint(0, 10000) for i in range(1000)]
bubble_sort(lst)
print(lst)
选择排序
一趟排序记录最小的数,放到第一个位置
再一趟排序记录列表无序区最小的数,放到第二个位置
算法关键点:有序区和无序区,无序区最小数的位置
时间复杂度:O(n²)
# 不推荐
def select_sort_simple(lst):
lst_new = []
for i in range(len(lst)):
min_val = min(lst)
lst_new.append(min_val)
lst.remove(min_val)
return lst_new
"""
时间复杂度:O(n²)
但是生成了新的列表,相当于多占用了一份内存
"""
# 推荐
def select_sort(lst):
for i in range(len(lst) - 1):
min_index = i # 先认为无序区的第一个值就是最小值
for j in range(i + 1, len(lst)):
if lst[j] < lst[min_index]:
min_index = j
if min_index != i:
lst[i], lst[min_index] = lst[min_index], lst[i]
"""
时间复杂度:O(n²)
"""
插入排序
初始时手里(有序区)只有一张牌
每次(从无序区)摸一张牌,插入到手里已有牌的正确位置
时间复杂度:O(n²)
def insert_sort(lst):
for i in range(1, len(lst)):
tmp = lst[i]
j = i - 1
"""
i: 拿取的牌的索引
tmp: 拿取的牌
j: 手中牌的索引
解析:
原列表 [5, 3, 2, 1, 4] = > 5 [3, 2, 1, 4]
我们可以把lst分为两部分,左边5就是我们拿在手里的牌,右边就是待拿取的牌
"""
while j >= 0 and tmp < lst[j]: # lst[j] 手中的牌
lst[j + 1] = lst[j] # lst[j] 小于新拿的牌,所以lst[j]向右移动
j = j - 1
lst[j + 1] = tmp
return lst
lst = [5, 3, 2, 1, 4]
print(insert_sort(lst))
NB三人组
快速排序
取一个元素p(第一个元素),使元素p归位
列表被p分成两部分,左边都比p小,右边都比p大
递归完成排序
时间复杂度:O(nlogn)
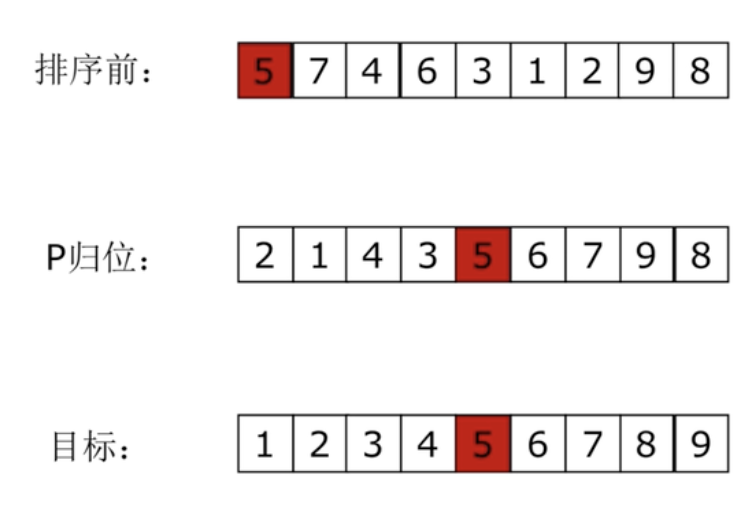
# 修改递归的深度
import sys
sys.setrecursionlimit(10000)
def partition(lst, left, right):
"""
tmp:找出的中间的那个数
left最左边的数
right最右边的数
目标:找出比tem小的放到左边,比tmp大的放到右边
"""
tmp = lst[left]
while left < right:
while left < right and lst[right] >= tmp: # 从右边找比tem小的数
right -= 1
lst[left] = lst[right] # 把右边的值放到左边的空位上
while left < right and lst[left] <= tmp:
left += 1
lst[right] = lst[left] # 把左边的值放到右边的空位上
lst[left] = tmp
return left # 返回mid的值
def quick_sort(lst, left, right):
if left < right: # 至少两个元素
mid = partition(lst, left, right) # 第一次执行partition将列表分为左右两部分
quick_sort(lst, left, mid - 1)
quick_sort(lst, mid + 1, right)
lst = [5, 7, 4, 6, 3, 1, 2, 9, 8]
quick_sort(lst, 0, len(lst) - 1)
print(lst)
堆排序
堆排序前传-树
树是一种数据结构 比如:目录结构
树是一种可以递归定义的数据结构
树是由n个节点组成的集合:
如果n=0,那这是一颗空树
如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一颗树
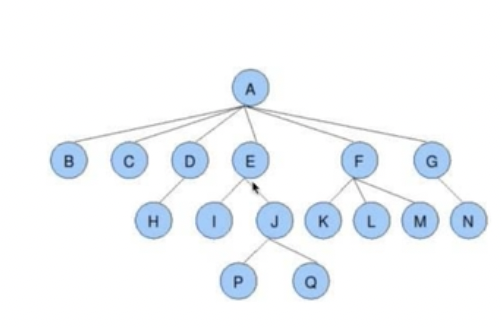
一些概念:(参考下图)
- 根节点、叶子节点 :a就是根节点,bchipqklmn可以理解为叶子节点
- 树的深度:下图中树的深度为4
- 树的度:下图中为6,可以理解为叉最多的那个节点的字节点数
- 孩子节点/父节点:比如E叫做I的父节点,I叫做E的孩子节点
- 子树:比如这里的E IJP如果单独拿出来就形成了一个子树
时间复杂度:O(nlogn)
堆排序前传-二叉树
二叉树:度不超过2的树
每个节点最多有两个孩子节点
两个孩子节点被区分为左孩子节点和右孩子节点
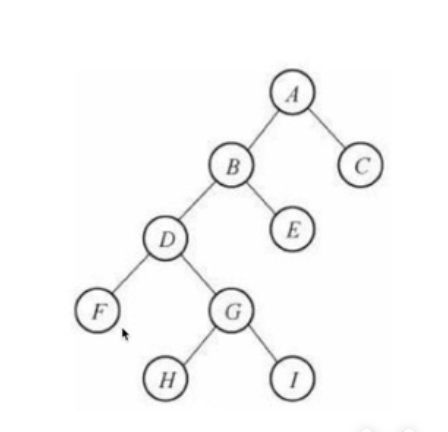
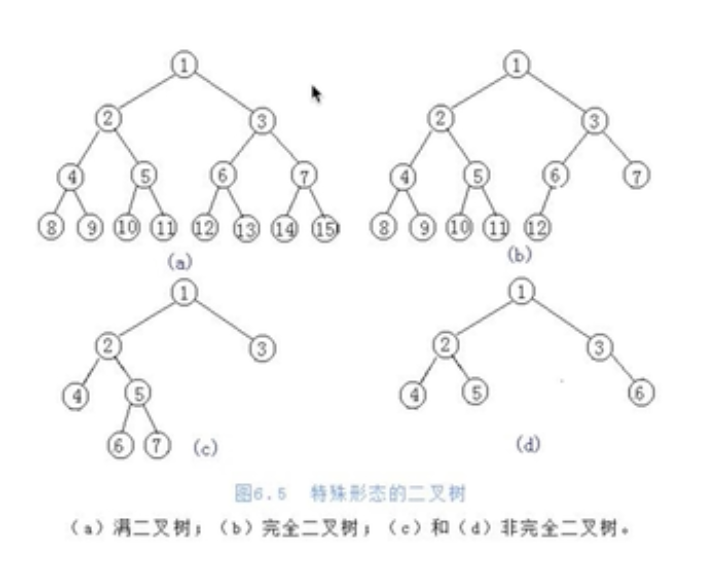
堆排序前传-完全二叉树
满二叉树:一个二叉树,如果每一层的节点数都达到最大值,则这个二叉树就是满二叉树。
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的节点都集中在该层最左边的若干位置的二叉树。
堆排序前传-二叉树的存储方式
链式存储方式
顺序存储方式
顺序存储方式

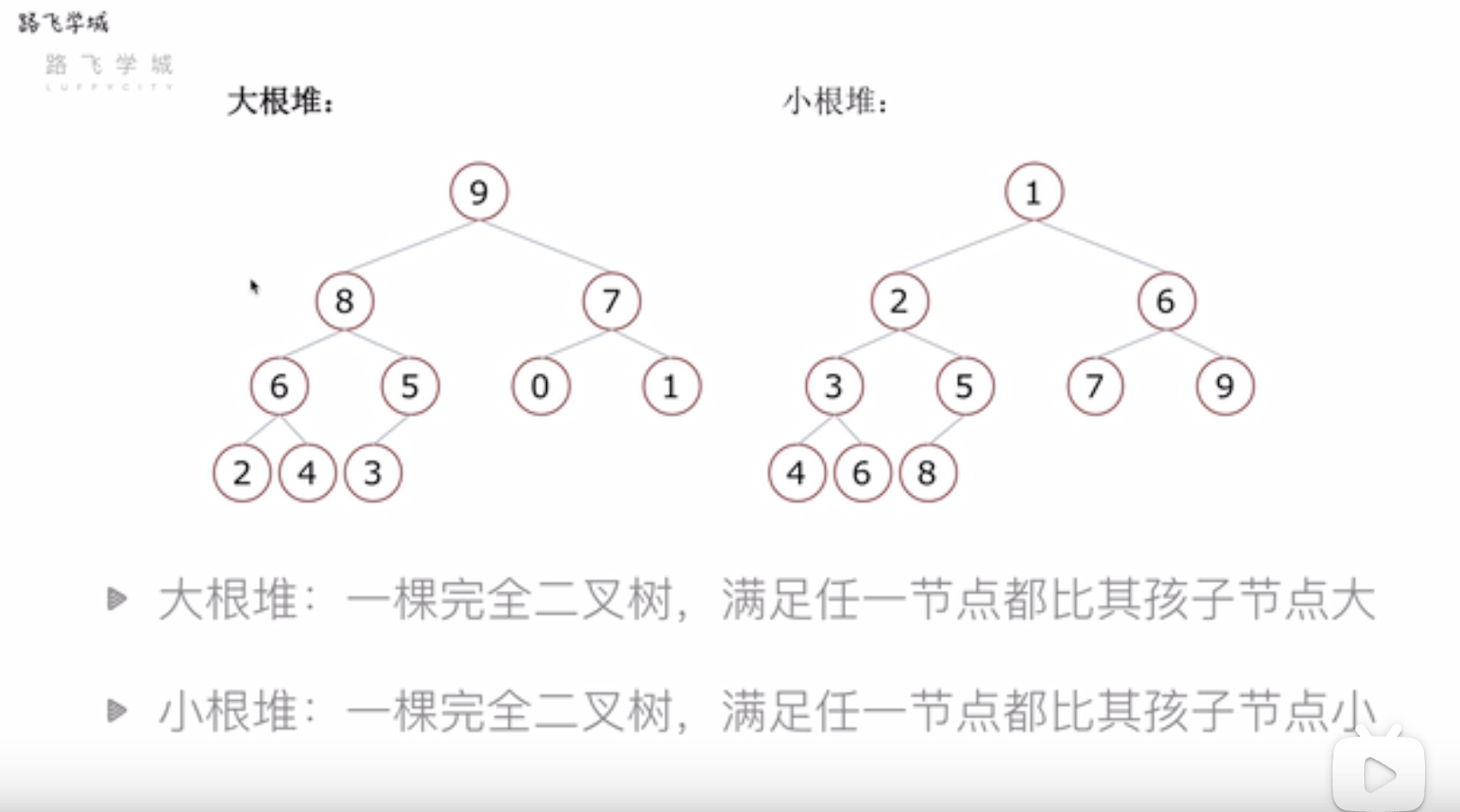
堆排序-什么是堆
堆:一种特殊的完全二叉树结构
- 大根堆:一颗完全二叉树,满足任一节点都比其孩子节点大
- 小根堆:一颗完全二叉树,满足任一节点都比其孩子节点小
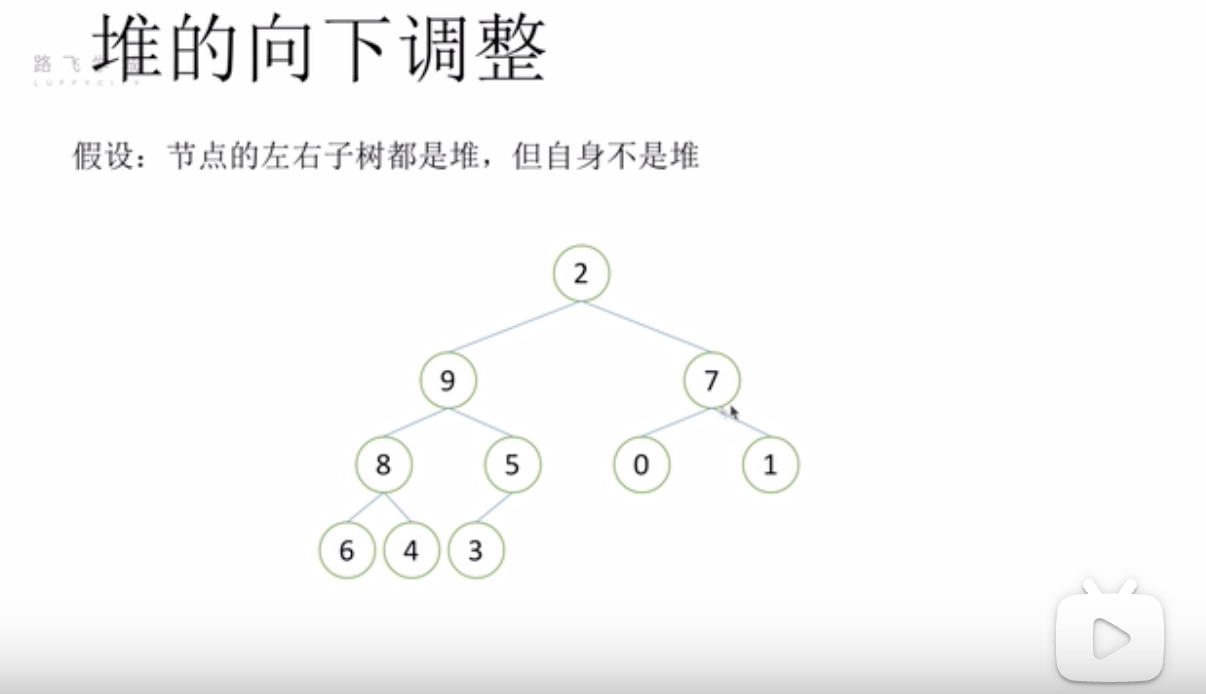
堆排序-堆的向下调整
图1中根节点比子节点要小,不满足一个堆的特点,所以对2这个节点进行向下调整,逐渐向下找合适的数放到合适的节点,形成一个堆(图2)
图1
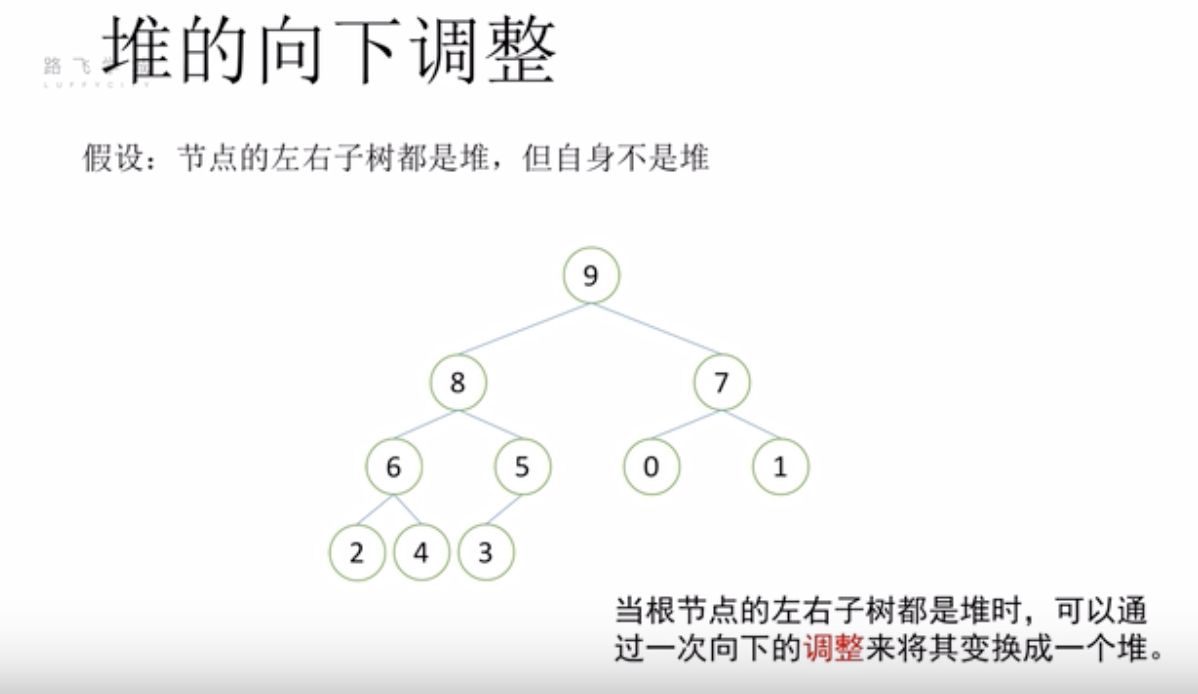
图2
# 堆的向下调整
def sift(lst, low, height):
"""
:param lst: 列表
:param low: 堆的根节点位置
:param height: 堆的最后一个元素的位置
:return: 调整好的一个堆(完全二叉树)
"""
i = low # i最开始指向根节点的位置
j = 2 * i + 1 # j开始指向的是i的左孩子节点的位置
tmp = lst[low]
while j <= height: # 如果左孩子的位置<= 最后一个元素的位置
if j + 1 <= height and lst[j + 1] > lst[j]: # 如果有右孩子且比左孩子大
j = j + 1 # j指向了右孩子
if lst[j] > tmp: # 如果左孩子大于堆顶元素
lst[i] = lst[j]
i = j
j = 2 * i + 1
else:
lst[i] = tmp
else:
lst[i] = tmp
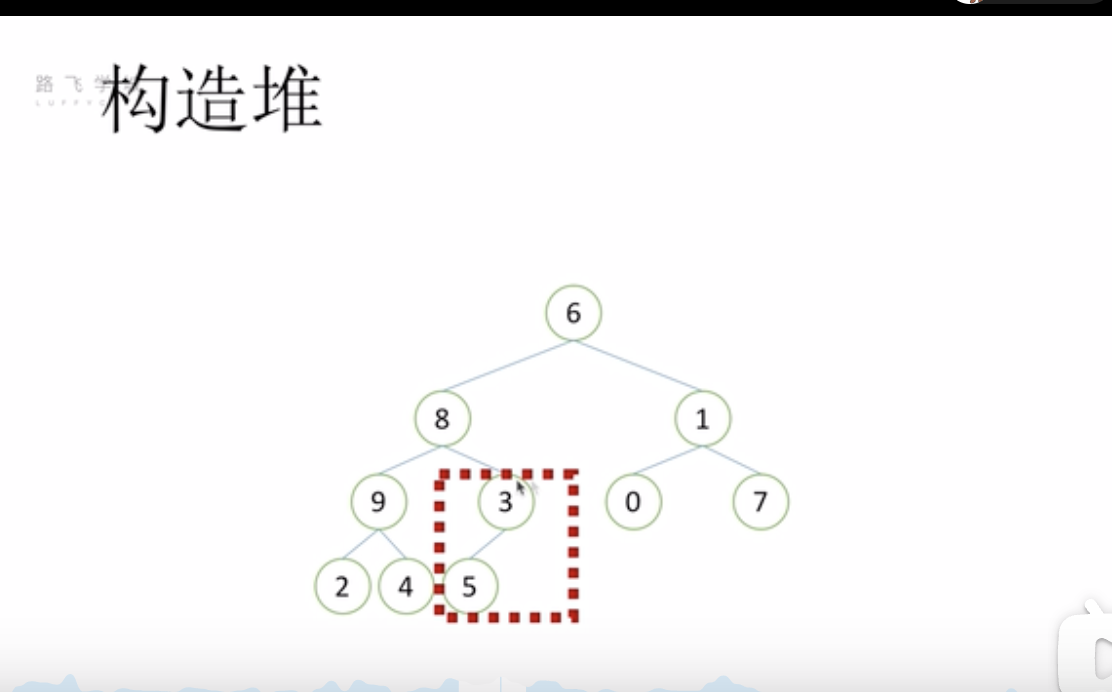
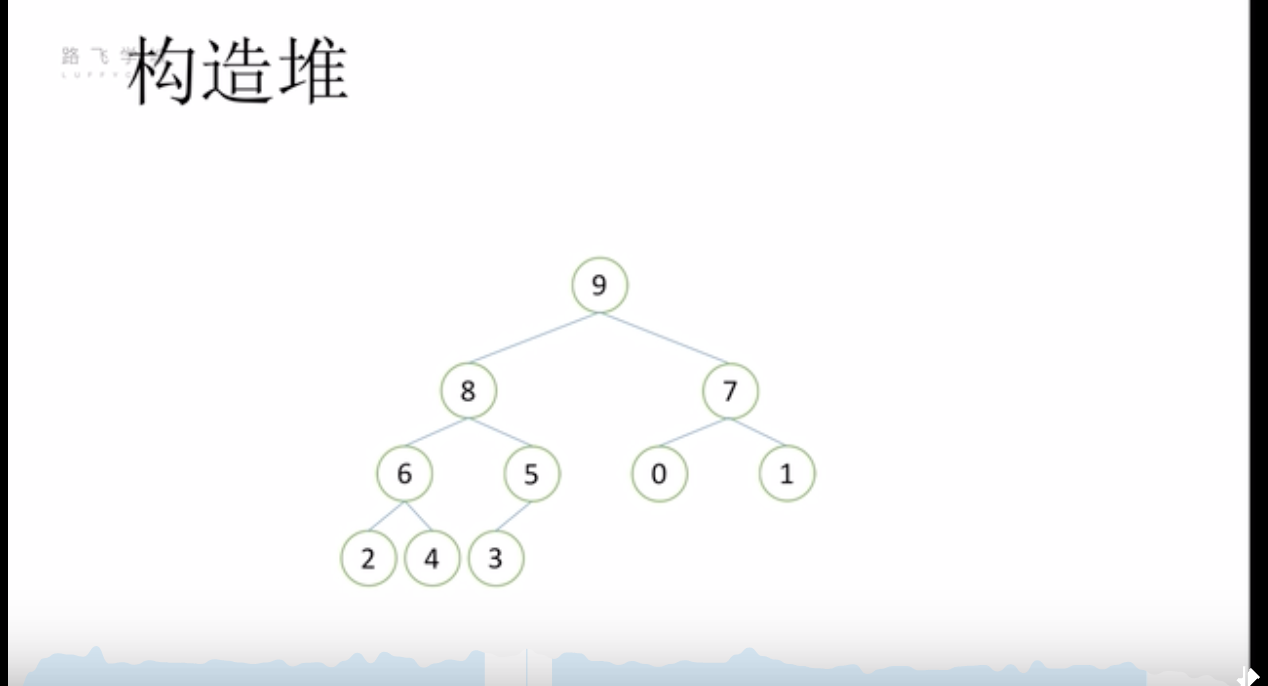
堆排序- 构造堆
- 先找到最后一个非叶子节点(图中的3)
- 按堆的结构进行调整(3和5交换)
- 然后依次向上找(找到节点1,然后调整1和7的位置)
构造后
# 构造堆
def heap_sort(lst):
pass
"""
如果最后一个节点的位置是i,那么父亲节点的位置就是 (i - 1) // 2
在这里list中最后一个数的位置是i - 1, 所以父节点的位置就是 (i - 2) // 2
"""
n = len(lst)
for i in range((n-2)//2, -1, -1): # i代表建堆的时候调整的位置的根的下标(比如第一次就是图1中的3)
sift(lst, i, n - 1)
# 建堆完成
堆排序的过程
- 建立堆(通过向下调整)
- 得到堆顶元素,为最大元素
- 去掉堆顶,将堆最后一个元素放到堆顶,此时可通过一次向下调整使堆重新有序
- 堆顶元素为第二个元素
- 重复步骤3,直到堆变空
# 1.构造堆
def heap_sort(lst):
"""
如果最后一个节点的位置是i,那么父亲节点的位置就是 (i - 1) // 2
在这里list中最后一个数的位置是i - 1, 所以父节点的位置就是 (i - 2) // 2
"""
# 2. 向下调整
n = len(lst)
for i in range((n-2)//2, -1, -1): # i代表建堆的时候调整的位置的根的下标(比如第一次就是图1中的3)
sift(lst, i, n - 1)
# 建堆完成
# 3.挨个出数
for i in range(n - 1, -1, -1): # i指的是当前堆的最后一个元素
lst[0], lst[i] = lst[i], lst[0]
sift(lst, 0, i - 1)
import random
lst = [i for i in range(11)]
random.shuffle(lst)
print(lst)
heap_sort(lst)
print(lst)
其他:python内置模块
import heapq
heapq.heapify(lst) # 建堆,建立的是小根堆
heapq.heappop(lst) # 取出最小的那个数
堆排序-topk问题
现在有n个数,设计算法得到前k大的数。(k<n)
解决思路:
- 排序后切片 O(nlogn)
- 排序LowB三人组(若采用冒泡排序,只取前面k个数, 时间复杂度O(kn))
- 堆排序思路 O(klogn)
- 取列表前k个元素建立一个小根堆,堆顶就是目前第k大的数
- 依次向后遍历原列表,对于列表中的元素,如果小于堆顶,则忽略该元素,如果大于堆顶,则将堆顶更换为该元素,并且对堆进行一次调整
- 遍历列表所有元素后,倒序弹出堆顶
使用堆排序实现
将列表中前五个数取出组成一个小根堆,然后...
# 基于建立小根堆的原理修改一下sift函数
def sift(lst, low, high):
"""
:param lst: 列表
:param low: 堆的根节点位置
:param high: 堆的最后一个元素的位置
:return: 调整好的一个堆(完全二叉树)
"""
i = low # i最开始指向根节点的位置
j = 2 * i + 1 # j开始指向的是i的左孩子节点的位置
tmp = lst[low]
while j <= high: # 如果左孩子的位置<= 最后一个元素的位置
if j + 1 <= high and lst[j + 1] < lst[j]: # 如果有右孩子且比左孩子大
j = j + 1 # j指向了右孩子
if lst[j] < tmp: # 如果左孩子大于堆顶元素
lst[i] = lst[j]
i = j
j = 2 * i + 1
else:
lst[i] = tmp
break
else:
lst[i] = tmp
def topk(lst, k):
heap = lst[0: k]
# 建堆
for i in range((k-2)//2, -1, -1):
sift(heap, i, k - 1)
# 2. 遍历
for i in range(k, len(lst)-1):
if lst[i] > heap[0]: # 如果这个数大于堆顶的数,就替换
heap[0] = lst[i]
sift(heap, 0, k - 1) # 在对前k个数组成的堆排序
# 3. 挨个出书
for i in range(k-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
sift(heap, 0, i - 1)
return heap
import random
lst = [i for i in range(11)]
random.shuffle(lst)
print(lst)
print(topk(lst, 5))
归并排序
归并

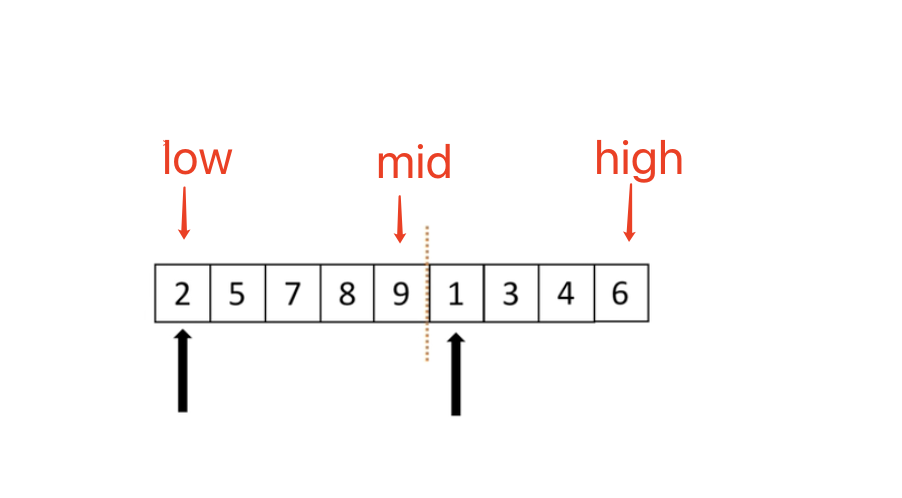
比较左右两个列表的数,然后将小的数取出来
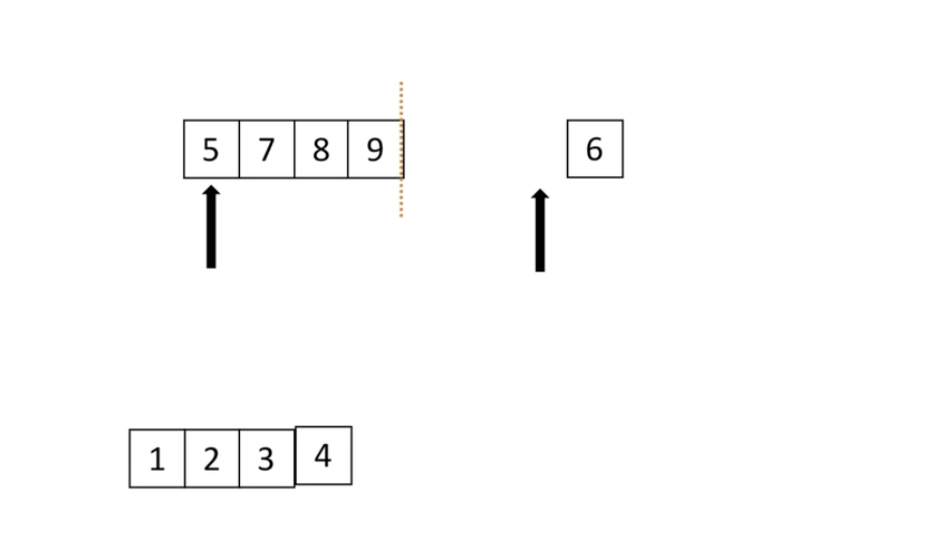
# 假设左右两边都是有序的
def merge(lst, low, mid, high):
i = low
j = mid + 1
tmp = []
while i <= mid and j <= high: # 只要左右两边都有数
if lst[i] < lst[j]:
tmp.append(lst[i])
i += 1
else:
tmp.append(lst[j])
j += 1
# 上一个while执行完,可以左边或者右边没有数了
while i <= mid: # 如果左边有数
tmp.append(lst[i])
while j <= high:
tmp.append(lst[j]) # 如果右边有数
lst[low: high + 1] = tmp
使用归并
分解:将列表越分越小,直至分成一个元素
终止条件:一个元素是有序的
合并:将两个有序列表归并,列表越来越大
时间复杂度:O(nlogn)
空间复杂度:O(n)
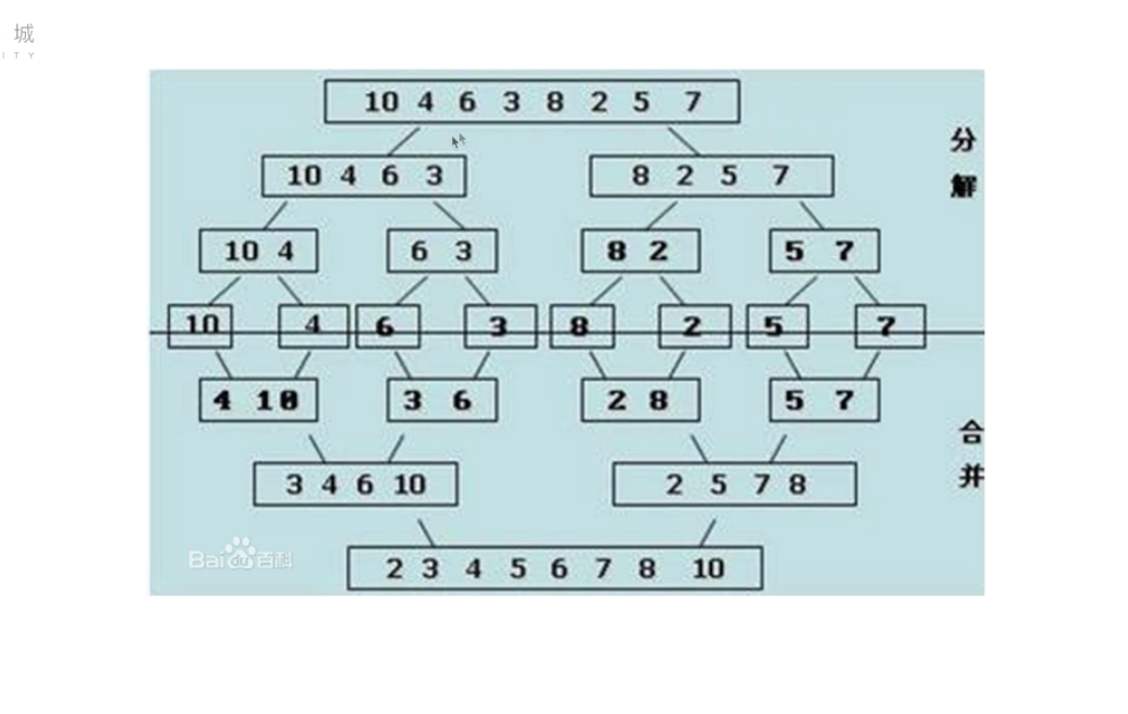
def merge_sort(lst, low, high):
if low < high:
mid = (low + high) // 2
merge_sort(lst, low, mid)
merge_sort(lst, mid + 1, high)
merge(lst, low, mid, high)
NB三人组小结
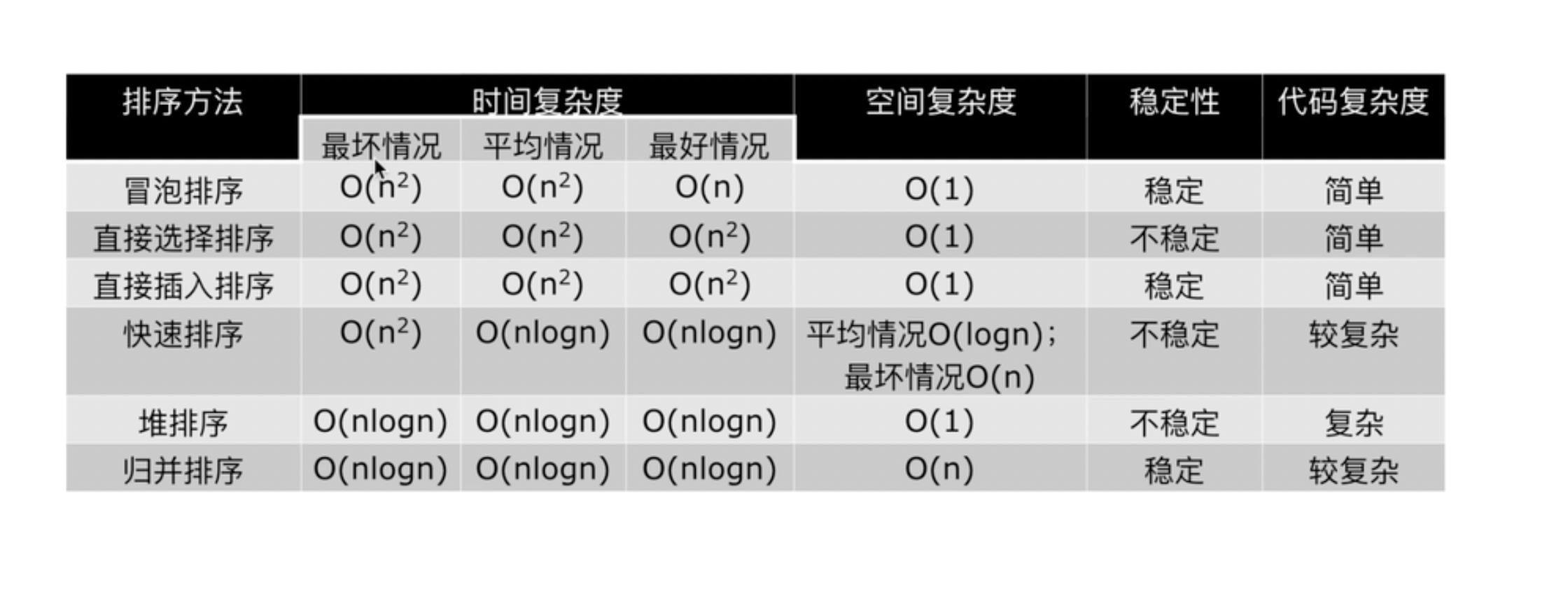
三种排序算法的时间复杂度都是O(nlogn)
一般情况而言,就运行时间而言:
- 快速排序 < 归并排序 < 堆排序
三种排序算法的缺点:
- 快速排序:极端情况下排序效率低
- 归并排序:需要额外的内存开销
- 堆排序:在快的排序算法中相对较慢
总结
其他排序
希尔排序
分组

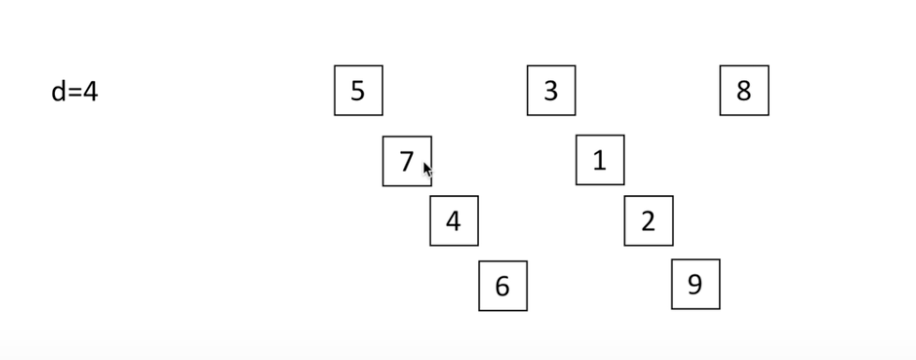
def insert_sort_gap(lst, gap):
for i in range(gap, len(lst)):
tmp = lst[i]
j = i - gap
while j >=0 and lst[j] > tmp:
lst[j+gap] = lst[j]
j -= gap
lst[j + gap] = tmp
def shell_sort(lst):
d = len(lst) // 2
while d >= 1:
insert_sort_gap(lst, d)
d //= 2
计数排序
对列表进行排序,已知列表中的数范围都在0-100之内。
时间复杂度:O(n)
def count_sort(lst, max_count=100):
# 约束条件:需要知道列表中最大的数是多少
count = [0 for _ in range(max_count + 1)]
for val in lst:
count[val] += 1
lst.clear()
for index, val in enumerate(count):
for i in range(val):
lst.append(index)
import random
lst = [random.randint(0, 100) for _ in range(1000)]
count_sort(lst)
print(lst)
桶排序


# 条件,知道列表中的最大值
def bucket_sort(lst, n=100, max_num=10000):
buckets = [[] for _ in range(n)] # 创建n个桶
for var in lst: # 判断桶应该放到哪个桶里
i = min(var // (max_num // n), n - 1) # i 表示var放到几号桶里
buckets[i].append(var)
for j in range(len(buckets[i]) - 1, 0, -1): # 对桶内的数排序
if buckets[i][j] < buckets[i][j - 1]:
buckets[i][j], buckets[i][j-1] = buckets[i][j-1], buckets[i][j],
else:
break
# 输出桶中的元素
sorted_lst = []
for buc in buckets:
sorted_lst.extend(buc)
return sorted_lst
基数排序
时间复杂度:O(kn)
空间复杂度:O(k+n)
k表示数字位数

import random
def radix_sort(lst):
max_num = max(lst) # 最大数 99 ->2, 888 -> 3, 10000 -> 5
it = 0 # 记录要循环多少次
while 10 ** it <= max_num:
buckets = [[] for _ in range(10)]
for var in lst:
digit = (var//10**it) % 10
buckets[digit].append(var)
lst.clear()
for buc in buckets:
lst.extend(buc)
it += 1
print(lst)
lst = list(range(1000))
random.shuffle(lst)
radix_sort(lst)
算法笔记_python的更多相关文章
- 学习Java 以及对几大基本排序算法(对算法笔记书的研究)的一些学习总结(Java对算法的实现持续更新中)
Java排序一,冒泡排序! 刚刚开始学习Java,但是比较有兴趣研究算法.最近看了一本算法笔记,刚开始只是打算随便看看,但是发现这本书非常不错,尤其是对排序算法,以及哈希函数的一些解释,让我非常的感兴 ...
- 算法笔记--数位dp
算法笔记 这个博客写的不错:http://blog.csdn.net/wust_zzwh/article/details/52100392 数位dp的精髓是不同情况下sta变量的设置. 模板: ]; ...
- 算法笔记--lca倍增算法
算法笔记 模板: vector<int>g[N]; vector<int>edge[N]; ][N]; int deep[N]; int h[N]; void dfs(int ...
- 算法笔记--STL中的各种遍历及查找(待增)
算法笔记 map: map<string,int> m; map<string,int>::iterator it;//auto it it = m.begin(); whil ...
- 算法笔记--priority_queue
算法笔记 priority_queue<int>que;//默认大顶堆 或者写作:priority_queue<int,vector<int>,less<int&g ...
- 算法笔记--sg函数详解及其模板
算法笔记 参考资料:https://wenku.baidu.com/view/25540742a8956bec0975e3a8.html sg函数大神详解:http://blog.csdn.net/l ...
- 算法笔记——C/C++语言基础篇(已完结)
开始系统学习算法,希望自己能够坚持下去,期间会把常用到的算法写进此博客,便于以后复习,同时希望能够给初学者提供一定的帮助,手敲难免存在错误,欢迎评论指正,共同学习.博客也可能会引用别人写的代码,如有引 ...
- 算法笔记_067:蓝桥杯练习 算法训练 安慰奶牛(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 Farmer John变得非常懒,他不想再继续维护供奶牛之间供通行的道路.道路被用来连接N个牧场,牧场被连续地编号为1到N.每一个牧场都是 ...
- 算法笔记(c++)--回文
算法笔记(c++)--回文 #include<iostream> #include<algorithm> #include<vector> using namesp ...
- 算法笔记(c++)--完全背包问题
算法笔记(c++)--完全背包和多重背包问题 完全背包 完全背包不同于01背包-完全背包里面的东西数量无限 假设现在有5种物品重量为5,4,3,2,1 价值为1,2,3,4,5 背包容量为10 # ...
随机推荐
- 探索JS中this的最终指向
js 中的this 指向 一直是前端开发人员的一个痛点难点,项目中有很多bug往往是因为this指向不明确(this指向在函数定义时无法确定,只有在函数被调用时,才确定该this的指向为最终调用它的对 ...
- kali系统安装redis步骤
环境: 攻击机:Kali 5.16.0-kali7-amd64 192.168.13.78 靶机: Kali 5.16.0-kali7-amd64 192.168.13.94 安装 ...
- defcon-quals 2023 crackme.tscript.dso wp
队友找到的引擎TorqueGameEngines/Torque3D (github.com) 将dso文件放到data/ExampleModule目录下,编辑ExampleModule.tscript ...
- 2023-06-06:给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列。 对位于 (row, col) 的每个结点而言, 其左右子结点分别位于 (row + 1, col -
2023-06-06:给你二叉树的根结点 root ,请你设计算法计算二叉树的 垂序遍历 序列. 对位于 (row, col) 的每个结点而言, 其左右子结点分别位于 (row + 1, col - ...
- Python自学指南-第一章-安装运行
1.1 [环境]快速安装 Python 与PyCharm "工欲善其事,必先利其器",为了自学之路的顺利顺利进行.首先需要搭建项目的开发环境. 1. 下载解释器 进入 Python ...
- Java并发(十一)----线程五种状态与六种状态
1.五种状态 这是从 操作系统 层面来描述的 [初始状态]仅是在语言层面创建了线程对象,还未与操作系统线程关联 [可运行状态](就绪状态)指该线程已经被创建(与操作系统线程关联),可以由 CPU 调度 ...
- Elastaticsearch 集群部署
系统Ubuntu 16.04 Elastaticsearch 5.6.9 Kibana 5.6.9 官网地址 https://www.elastic.co/products/elasticsearch ...
- 微信小程序脚手架火爆来袭,集成 Taro、uniapp 第三方模版,支持小程序 CI 上传,预览,发布
微信小程序脚手架 @wechat-mp/cli 微信小程序脚手架,集成 Taro.uniapp 第三方模版,支持小程序 CI 上传,预览,发布 注意事项 需要在微信公众平台开发管理-开发设置-IP白名 ...
- MAMP VirtualHost 无效 配置踩坑
目录 Mac系统 MAMP Apache 多虚拟主机配置无效 最终解决: 注意事项: Mac系统 MAMP Apache 多虚拟主机配置无效 和在linux.windows类似,起初添加了一个 < ...
- Sentieon | 每周文献-Genetic Disease-第二期
遗传病系列文章-1 标题(英文):Answer ALS, a large-scale resource for sporadic and familial ALS combining clinical ...