【转】Derivation of the Normal Equation for linear regression
I was going through the Coursera "Machine Learning" course, and in the section on multivariate linear regression something caught my eye. Andrew Ng presented the Normal Equation as an analytical solution to the linear regression problem with a least-squares cost function. He mentioned that in some cases (such as for small feature sets) using it is more effective than applying gradient descent; unfortunately, he left its derivation out.
Here I want to show how the normal equation is derived.
First, some terminology. The following symbols are compatible with the machine learning course, not with the exposition of the normal equation on Wikipedia and other sites - semantically it's all the same, just the symbols are different.
Given the hypothesis function:
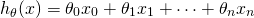
We'd like to minimize the least-squares cost:
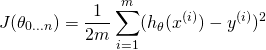
Where 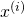 is the i-th sample (from a set of m samples) and
is the i-th sample (from a set of m samples) and 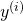 is the i-th expected result.
is the i-th expected result.
To proceed, we'll represent the problem in matrix notation; this is natural, since we essentially have a system of linear equations here. The regression coefficients 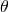 we're looking for are the vector:
we're looking for are the vector:
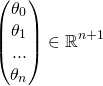
Each of the m input samples is similarly a column vector with n+1 rows, 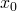 being 1 for convenience. So we can now rewrite the hypothesis function as:
being 1 for convenience. So we can now rewrite the hypothesis function as:
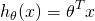
When this is summed over all samples, we can dip further into matrix notation. We'll define the "design matrix" X (uppercase X) as a matrix of m rows, in which each row is the i-th sample (the vector ). With this, we can rewrite the least-squares cost as following, replacing the explicit sum by matrix multiplication:
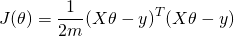
Now, using some matrix transpose identities, we can simplify this a bit. I'll throw the 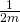 part away since we're going to compare a derivative to zero anyway:
part away since we're going to compare a derivative to zero anyway:
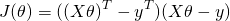
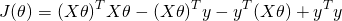
Note that 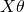 is a vector, and so is y. So when we multiply one by another, it doesn't matter what the order is (as long as the dimensions work out). So we can further simplify:
is a vector, and so is y. So when we multiply one by another, it doesn't matter what the order is (as long as the dimensions work out). So we can further simplify:
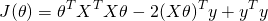
Recall that here is our unknown. To find where the above function has a minimum, we will derive by and compare to 0. Deriving by a vector may feel uncomfortable, but there's nothing to worry about. Recall that here we only use matrix notation to conveniently represent a system of linear formulae. So we derive by each component of the vector, and then combine the resulting derivatives into a vector again. The result is:
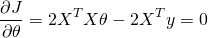
Or:
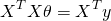
[Update 27-May-2015: I've written another post that explains in more detail how these derivatives are computed.]
Now, assuming that the matrix 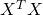 is invertible, we can multiply both sides by
is invertible, we can multiply both sides by 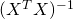 and get:
and get:
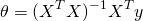
Which is the normal equation.
【转】Derivation of the Normal Equation for linear regression的更多相关文章
- (三)用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- CS229 3.用Normal Equation拟合Liner Regression模型
继续考虑Liner Regression的问题,把它写成如下的矩阵形式,然后即可得到θ的Normal Equation. Normal Equation: θ=(XTX)-1XTy 当X可逆时,(XT ...
- Linear regression with multiple variables(多特征的线型回归)算法实例_梯度下降解法(Gradient DesentMulti)以及正规方程解法(Normal Equation)
,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, ,, , ...
- machine learning (7)---normal equation相对于gradient descent而言求解linear regression问题的另一种方式
Normal equation: 一种用来linear regression问题的求解Θ的方法,另一种可以是gradient descent 仅适用于linear regression问题的求解,对其 ...
- 机器学习入门:Linear Regression与Normal Equation -2017年8月23日22:11:50
本文会讲到: (1)另一种线性回归方法:Normal Equation: (2)Gradient Descent与Normal Equation的优缺点: 前面我们通过Gradient Desce ...
- 5种方法推导Normal Equation
引言: Normal Equation 是最基础的最小二乘方法.在Andrew Ng的课程中给出了矩阵推到形式,本文将重点提供几种推导方式以便于全方位帮助Machine Learning用户学习. N ...
- Normal Equation Algorithm
和梯度下降法一样,Normal Equation(正规方程法)算法也是一种线性回归算法(Linear Regression Algorithm).与梯度下降法通过一步步计算来逐步靠近最佳θ值不同,No ...
- coursera机器学习笔记-多元线性回归,normal equation
#对coursera上Andrew Ng老师开的机器学习课程的笔记和心得: #注:此笔记是我自己认为本节课里比较重要.难理解或容易忘记的内容并做了些补充,并非是课堂详细笔记和要点: #标记为<补 ...
- Normal Equation
一.Normal Equation 我们知道梯度下降在求解最优参数\(\theta\)过程中需要合适的\(\alpha\),并且需要进行多次迭代,那么有没有经过简单的数学计算就得到参数\(\theta ...
随机推荐
- Android缓存技术
android应用程序中 1. 尽可能的把文件缓存到本地.可以是 memory,cache dir,甚至是放进 SD 卡中(比如大的图片和音视频). 可以设置双重缓冲,较大的图片或者音频放到SD ...
- 3.AOP入门1
1.定义1.1基本概念2. 1.定义 1.1基本概念 AOP:aspect object programing面向切面编程 aop编程的要点在于关注点和切入点 关注点:指的是代码中的重复部分,每次实现 ...
- 解决tomcat占用8080端口问题
在dos下,输入 netstat -ano|findstr 8080 //说明:查看占用8080端口的进程 显示占用端口的进程 askkill /pid 44464 /f //说明,运 ...
- Java面试——基础
1,作用域,Java只有public,protect,private,默认是default相当于friendly 作用域 当前类 同一package 子类 其它 ...
- 【USACO 1.5.1】数字金字塔
[题目描述] 观察下面的数字金字塔. 写一个程序来查找从最高点到底部任意处结束的路径,使路径经过数字的和最大.每一步可以走到左下方的点也可以到达右下方的点. 7 3 8 8 1 0 2 7 4 4 4 ...
- AutoIt3初探(1)
AutoIt3可实现系统操作,键盘鼠标模拟,是自动化测试的一个好工具. 这个是在线帮助文档,http://www.jb51.net/shouce/autoit/ 需要先下载一个autoIt安装,然后将 ...
- Linux小知识点汇总
1.crontab (1)crontab每10秒执行一次 * * * * * /bin/date >>/tmp/date.txt * * * * * sleep 10; ...
- Java学习----对象的状态和行为
1.什么是对象 对象是已知的事物 对象会执行动作 类是对象的蓝图 2.对象的属性和状态 使用变量来描述 private String name; private int age; private St ...
- Java学习-----单例模式
一.问题引入 偶然想想到的如果把Java的构造方法弄成private,那里面的成员属性是不是只有通过static来访问呢:如果构造方法是private的话,那么有什么好处呢:如果构造方法是privat ...
- text-overflow:ellipsis 的应用(转载)
关键字: text-overflow:ellipsis 语法:text-overflow : clip | ellipsis 取值: clip :默认值 .不显示省略标记(...),而是简单的裁切. ...