Hashtable,HashMap实现原理
http://blog.csdn.net/czh0766/article/details/5260360
昨天看了算法导论对散列表的介绍,今天看了一下Hashtable, HashMap这两个类的源代码,并参考了网上的一些观点,对它们的实现有了大概的理解。原来hashtable里的key-value还是用数组存储的,数组元素是Entry<K,V>类型,同一数组索引下储存的实质是一个Entry链表,Entry中的next值指向下一个Entry.当把key-value放进hashtable时,会根据key的hashcode值来计算应储存的数组索引,根据这一索引寻找Entry链表中是否存在相同key值的entry, 如果有就把该entry里的value代替,否则生成新的entry存储key-value, 并把它放置在链表头。若果entry的数量超出hashtable的容量,hashtable会生成新的更大容量的数组并重新计算原有的entry的位置。
Hashtable和HashMap的主要区别在于Hashtable对数据的操作是线程安全的,但会有一定的额外开销;它们根据key的hashcode计算方法也不同;HashMap的key可以是null, 存储在内部数组的第一个位置里。
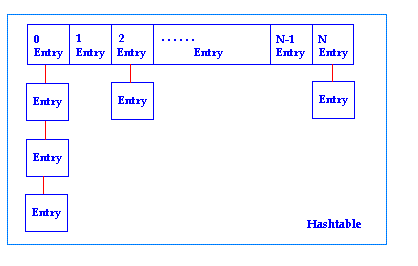
从上面的结构图可以看出,Hashtable的实质就是一个数组+链表。图中的Entry就是链表的实现,Entry的结构中包含了对自己的另一个实例的引用next,用以指向另外一个Entry。而图中标有数字的部分是一个Entry数组,数字就是这个Entry数组的index。那么往 Hashtable增加键值对的时候,index会根据键的hashcode、Entry数组的长度共同决定,从而决定键值对存放在Entry数组的哪个位置。从这种意义来说,当键一定,Entry数组的长度一定的情况下,所得到的index肯定是相同的,也就是说插入顺序应该不会影响输出的顺序才对。然而,还有一个重要的因素没有考虑,就是计算index出现相同值的情况。譬如代码中 "sichuan" 和 "anhui",所得到的index是相同的,在这个时候,Entry的链表功能就发挥作用了:put方法通过Entry的next属性获得对另外一个 Entry的引用,然后将后来者放入其中。根据debug得出的结果,"sichuan", "anhui"的index同为2,"hunan"的index为6,"beijing"的index为1,在输出的时候,会以index递减的方式获得键值对。很明显,会改变的输出顺序只有"sichuan"和"anhui"了,也就是说输出只有两种可能:"hunan" - "sichuan" - "anhui" - "beijing"和"hunan" - "anhui" - "sichuan" - "beijing"。以下是运行了示例代码之后,Hashtable的结果:

在Hashtable的实现代码中,有一个名为rehash的方法用于扩充Hashtable的容量。很明显,当rehash方法被调用以后,每一个键值对相应的index也会改变,也就等于将键值对重新排序了。这也是往不同容量的Hashtable放入相同的键值对会输出不同的键值对序列的原因。在Java中,触发rehash方法的条件很简单:hahtable中的键值对超过某一阀值。默认情况下,该阀值等于hashtable中Entry数组的长度×0.75。 (注意entry 数组里存值了,而传统hash 链表链地址法里没有存值)
自 Java 2 平台 v1.2 以来,此类已经改进为可以实现 Map,因此它变成了 Java Collections Framework 的一部分。与新集合的实现不同,Hashtable 是同步的。
由迭代器返回的 Iterator 和由所有 Hashtable 的“collection 视图方法”返回的 Collection 的 listIterator 方法都是快速失败 的:在创建 Iterator 之后,如果从结构上对 Hashtable 进行修改,除非通过 Iterator 自身的移除或添加方法,否则在任何时间以任何方式对其进行修改,Iterator 都将抛出 ConcurrentModificationException。因此,面对并发的修改,Iterator 很快就会完全失败,而不冒在将来某个不确定的时间发生任意不确定行为的风险。由 Hashtable 的键和值方法返回的 Enumeration 不 是快速失败的。
注意,迭代器的快速失败行为无法得到保证,因为一般来说,不可能对是否出现不同步并发修改做出任何硬性保证。快速失败迭代器会尽最大努力抛出 ConcurrentModificationException。因此,为提高这类迭代器的正确性而编写一个依赖于此异常的程序是错误做法:迭代器的快速失败行为应该仅用于检测程序错误。
直接看HashTable.java
解决哈希表的冲突-开放地址法和链地址法
在实际应用中,无论如何构造哈希函数,冲突是无法完全避免的。
1 开放地址法 (顾名思义,可以占用本来应该其他数据占用的地址)
这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。这个过程可用下式描述:
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,…… , k ( k ≤ m – 1))
其中: H ( key ) 为关键字 key 的直接哈希地址, m 为哈希表的长度, di 为每次再探测时的地址增量。
采用这种方法时,首先计算出元素的直接哈希地址 H ( key ) ,如果该存储单元已被其他元素占用,则继续查看地址为 H ( key ) + d 2 的存储单元,如此重复直至找到某个存储单元为空时,将关键字为 key 的数据元素存放到该单元。
增量 d 可以有不同的取法,并根据其取法有不同的称呼:
( 1 ) d i = 1 , 2 , 3 , …… 线性探测再散列;
( 2 ) d i = 1^2 ,- 1^2 , 2^2 ,- 2^2 , k^2, -k^2…… 二次探测再散列;
( 3 ) d i = 伪随机序列 伪随机再散列;
例1设有哈希函数 H ( key ) = key mod 7 ,哈希表的地址空间为 0 ~ 6 ,对关键字序列( 32 , 13 , 49 , 55 , 22 , 38 , 21 )按线性探测再散列和二次探测再散列的方法分别构造哈希表。
解:
( 1 )线性探测再散列:
32 % 7 = 4 ; 13 % 7 = 6 ; 49 % 7 = 0 ;
55 % 7 = 6 发生冲突,下一个存储地址( 6 + 1 )% 7 = 0 ,仍然发生冲突,再下一个存储地址:( 6 + 2 )% 7 = 1 未发生冲突,可以存入。
22 % 7 = 1 发生冲突,下一个存储地址是:( 1 + 1 )% 7 = 2 未发生冲突;
38 % 7 = 3 ;
21 % 7 = 0 发生冲突,按照上面方法继续探测直至空间 5 ,不发生冲突,所得到的哈希表对应存储位置:
下标: 0 1 2 3 4 5 6
49 55 22 38 32 21 13
( 2 )二次探测再散列:
下标: 0 1 2 3 4 5 6
49 22 21 38 32 55 13
注意:对于利用开放地址法处理冲突所产生的哈希表中删除一个元素时需要谨慎,不能直接地删除,因为这样将会截断其他具有相同哈希地址的元素的查找地址,所以,通常采用设定一个特殊的标志以示该元素已被删除。
2 链地址法
链地址法解决冲突的做法是:如果哈希表空间为 0 ~ m - 1 ,设置一个由 m 个指针分量组成的一维数组 ST[ m ], 凡哈希地址为 i 的数据元素都插入到头指针为 ST[ i ] 的链表中。这种方法有点近似于邻接表的基本思想,且这种方法适合于冲突比较严重的情况。
例 2 设有 8 个元素 { a,b,c,d,e,f,g,h } ,采用某种哈希函数得到的地址分别为: {0 , 2 , 4 , 1 , 0 , 8 , 7 , 2} ,当哈希表长度为 10 时,采用链地址法解决冲突的哈希表如下图所示。 
在hashtable和hashmap是java里面常见的容器类,
是Java.uitl包下面的类,
那么Hashtable和Hashmap是怎么实现hash键值对配对的呢,我们看看jdk里面的源码,分析下Hashtable的构造方法,put(K, V)加入方法和get(Object)方法就大概明白了。
一、Hashtable的构造方法:Hashtable(int initialCapacity, float loadFactor)
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)(initialCapacity * loadFactor);
}
这个里面米内有什么好说的,要注意的是table一个是实体数组,输入的initialCapacity表示这个数组的大小,而threshold 是一个int值,其中loadFactor默认是0.75,就是说明,当table里面的值到75%的阀值后,快要填满数组了,就会自动双倍扩大数字容 量。
而Entry<K,V> 来自与
private static class Entry<K,V> implements Map.Entry<K,V> {
int hash;
K key;
V value;
Entry<K,V> next;
是一个单项链表,

上图就是Hashtable的表,
二、put(K, V)加入方法
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V ld = e.value;
e.value = value;
return old;
}
}modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}// Creates the new entry.
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
count++;
return null;
}
这个看看起来很长,只要注意三点就可以了,
1.index,index是键值的hashcode和0x7FFFFFFF的&运算,然后根据数组长度求余值。这样可以定出所在队列名称,
2、
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V ld = e.value;
e.value = value;
return old;
}
}
for语句里面是让e在tab某个队列名为index单项链表里面遍历,第几个单项链表的定义由index定义,看看该队列是否已经有同样的值,如果有,就返回该值。
3、如果没有,则加入
Entry<K,V> e = tab[index];
tab[index] = new Entry<K,V>(hash, key, value, e);
三、get(Object),获得
public synchronized V get(Object key) {
Entry tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
这个就很好理解了 int index = (hash & 0x7FFFFFFF) % tab.length;
获得队列名称,
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
在该队里面遍历,根据hash值获得具体值。
总结下,一个是根据index确定队列,在由hash值获得具体元素值。
看完了hashtable, 我们在来看看hashMap
hashMap可以算作是hashtable的升级版本, 最早从1.2开始有的.
但是, 两者之间最主要的不同有两点.
1. hashMap的读写是unsynchronized, 在多线程的环境中要注意使用
而hashtable是synchronized
这两者的不同是通过在读写方法上加synchronized关键字来实现的.
第二个不同是hashMap可以放空值, 而hashtable就会报错.
Hashtable,HashMap实现原理的更多相关文章
- HashTable & HashMap & ConcurrentHashMap 原理与区别
一.三者的区别 HashTable HashMap ConcurrentHashMap 底层数据结构 数组+链表 数组+链表 数组+链表 key可为空 否 是 否 value可为空 否 是 否 ...
- JVM里面hashtable和hashmap实现原理
JVM里面hashtable和hashmap实现原理 文章分类:Java编程 转载 在hashtable和hashmap是java里面常见的容器类, 是Java.uitl包下面的类, 那么Hash ...
- Hashmap与Hashtable的区别及Hashmap的原理
Hashtable和HashMap有几个主要的不同:线程安全以及速度.仅在你需要完全的线程安全的时候使用Hashtable,而如果你使用Java 5或以上的话,请使用ConcurrentHashMap ...
- 集合 HashMap 的原理,与 Hashtable、ConcurrentHashMap 的区别
一.HashMap 的原理 1.HashMap简介 简单来讲,HashMap底层是由数组+链表的形式实现,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表 ...
- hashmap实现原理浅析
看了下JAVA里面有HashMap.Hashtable.HashSet三种hash集合的实现源码,这里总结下,理解错误的地方还望指正 HashMap和Hashtable的区别 HashSet和Hash ...
- java该HashTable,HashMap和HashSet
同一时候我们也对HashSet和HashMap的核心方法hashcode进行了具体解释,见<探索equals()和hashCode()方法>. 万事俱备,那么以下我们就对基于hash算法的 ...
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- HashMap 实现原理
深入Java集合学习系列:HashMap的实现原理 参考文献 引用文献:深入Java集合学习系列:HashMap的实现原理,大部分参考这篇博客,只对其中进行稍微修改 自己曾经写过的:Hashmap ...
- 【JAVA】HashMap的原理及多线程下死循环的原因
再次翻到以前工作中遇到的一个问题,HashMap在多线程下会出现死循环的问题,以前只是知道会死循环,导致CPU100%把机器拖跨,今天来彻底看看 首先来看下,HashMap的原理:HashMap是一个 ...
随机推荐
- MySQL5.6监控表之INNODB_METRICS
http://blog.chinaunix.net/uid-10661836-id-4278807.html 在MySQL5.6的Information_Schema引入新的INNODB_METRIC ...
- MYSQL 学习笔记1 -----mysqladmin -uroot -p status|extended-status
root@server1 ~]# mysqladmin -uroot -p status -i -r extended-status|grep Handler_commit Enter passwor ...
- GCC内嵌汇编
http://blog.csdn.net/mydo/article/details/8279924
- Windows下Memcached在.Net程序中的实际运用(从Memcached客户端Enyim的库的编译到实际项目运用)
1.一点基础概念 2.获取EnyimMemcached客户端的源代码并编译出动态库 3.Memcached的服务器安装(windows server) 4.在web项目中实战 一.基础概念 memca ...
- 分分钟解决iOS开发中App启动广告的功能
前不久有朋友需要一个启动广告的功能,我说网上有挺多的,他说,看的不是很理想.想让我写一个,于是乎,抽空写了一个,代码通俗易懂,简单的封装了一下,各种事件用block回调的,有俩种样式的广告,一种是全屏 ...
- iOS开发大神必备的Xcode插件
写在前面 工欲善其事,必先利其器,iOS开发中不仅要学会Xcode的基本操作,而且还得学会一些Xcode的使用技巧,如掌握常用的快捷键等,还有就是今天要说到的Xcode插件,下面我就为大家介绍几款开发 ...
- 蓝灯官网下载,蓝灯最新版下载,Lantern(蓝灯)
蓝灯官网下载,蓝灯最新版下载,Lantern(蓝灯)下载 >>>>>>>>>>>>>>>>>> ...
- 程序员带你十天快速入门Python,玩转电脑软件开发(二)
关注今日头条-做全栈攻城狮,学代码也要读书,爱全栈,更爱生活.提供程序员技术及生活指导干货. 如果你真想学习,请评论学过的每篇文章,记录学习的痕迹. 请把所有教程文章中所提及的代码,最少敲写三遍,达到 ...
- 用Eclipse+xdebug调试PHP总是在首行自动断点解决方法
问题描述: 使用Eclipse+PDT+xdebug调试PHP程序时,总是在程序的第一行(首行)自动断点,不方便调试. 解决方法: 分别在下面3个位置配置,取消 Break at First Line ...
- php strtotime函数服务器和本地不相同
遇到过一种情况strtotime 在本地和服务器不相同 服务器返回的是-1 strtotime($sa_sagyo_ymd."23:59:59") 如果这样用不了,就只能换一种写法 ...